k8s集群
1.k8s用途
kubernetes的本质是一组服务器集群,它可以在集群的每个节点上运行特定的程序,来对节点中的容器 进行管理。目的是实现资源管理的自动化,主要提供了如下的主要功能:
自我修复:一旦某一个容器崩溃,能够在1秒中左右迅速启动新的容器
弹性伸缩:可以根据需要,自动对集群中正在运行的容器数量进行调整
服务发现:服务可以通过自动发现的形式找到它所依赖的服务
负载均衡:如果一个服务起动了多个容器,能够自动实现请求的负载均衡
版本回退:如果发现新发布的程序版本有问题,可以立即回退到原来的版本
存储编排:可以根据容器自身的需求自动创建存储
2.k8s节点
一个kubernetes集群主要是由控制节点(master)、工作节点(node)构成,每个节点上都会安装不同的组件
1.master:集群的控制平面,负责集群的决策
ApiServer : 资源操作的唯一入口,接收用户输入的命令,提供认证、授权、API注册和发现等机制 Scheduler : 负责集群资源调度,按照预定的调度策略将Pod调度到相应的node节点上 ControllerManager : 负责维护集群的状态,比如程序部署安排、故障检测、自动扩展、滚动更新 等
Etcd :负责存储集群中各种资源对象的信息
2.node:集群的数据平面,负责为容器提供运行环境
kubelet:负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理
Container runtime:负责镜像管理以及Pod和容器的真正运行(CRI)
kube-proxy:负责为Service提供cluster内部的服务发现和负载均衡
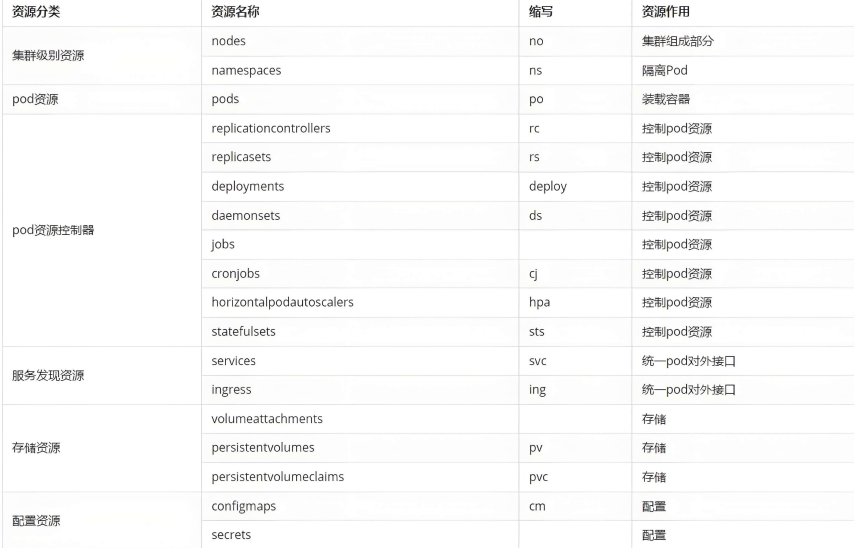
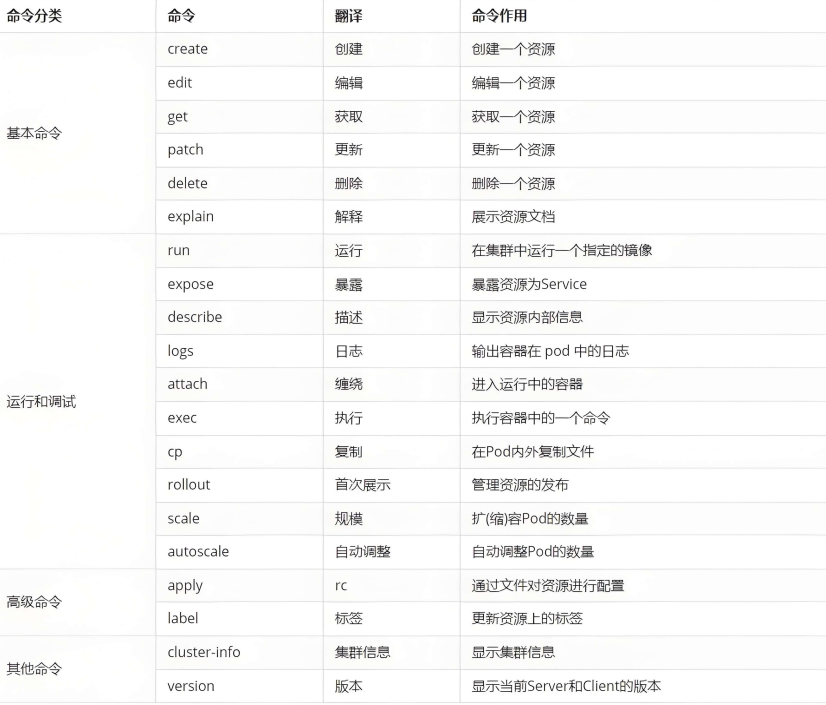
3.K8S 的 常用名词感念

4.k8s环境部署
k8s有多种部署方式,主流的有kubeadm minikube 二进制包
① minikube:一个用于快速搭建单节点的kubernetes工具。
●② kubeadm:一个用于快速搭建kubernetes集群的工具。
●③ 二进制包:从官网上下载每个组件的二进制包,依次去安装,此方式对于理解kubernetes组件更加有效。
本次环境搭建需要三台CentOS服务器(一主二从),然后在每台服务器中分别安装Docker(18.06.3)、kubeadm(1.18.0)、kubectl(1.18.0)和kubelet(1.18.0)。
master 192.168.83.201 node1 192.168.83.170 node2 192.168.83.180
4.1环境初始化
1.cat /etc/redhat-release #检查操作系统的版本 要求操作系统版本必须在7.5以上
所有节点都需要执行的操作:
2.#关闭火墙和关闭火墙开机启动
systemctl stop firewalld
systemctl disable firewalld
3.#做地址解析
cat /etc/hosts
192.168.83.201 master
192.168.83.170 node1
192.168.83.180 node2
4.#做时间同步
vi /etc/chorny.conf
server 192.168.83.201 iburst
server 192.168.83.170 iburst
server 192.168.83.180 iburst
5.#关闭selinux
getenforce #查看是否开启
setenforce 0 #临时关闭
sed -i 's/^SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config #永久关闭但是需要reboot
6.#禁用swap分区
systemctl mask swap.target
swapoff -a #临时关闭swap分区
sed -ri 's/.*swap.*/#&/' /etc/fstab #永久关闭分区 但是需要重启
7.将桥接的IPv4流量传递到iptables的链(每个节点都得进行)
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
vm.swappiness = 0
EOF
# 加载br_netfilter模块
modprobe br_netfilter
# 生效 sysctl --system
8.开启ipvs
在kubernetes中service有两种代理模型,一种是基于iptables,另一种是基于ipvs的。ipvs的性能要高于iptables的,但是如果要使用它,需要手动载入ipvs模块。
●在每个节点安装ipset和ipvsadm:
yum -y install ipset ipvsadm
在所有节点执行如下脚本:
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
授权、运行、检查是否加载:
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4
检查是否加载:
lsmod | grep -e ipvs -e nf_conntrack_ipv4
9.每个节点安装Docker、kubeadm、kubelet和kubectl
安装Docker:
wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo
yum -y install docker-ce-18.06.3.ce-3.el7
systemctl enable docker && systemctl start docker
docker version #查看docker版本
然后可以在/etc/docker/daemon.json 配置docker镜像加速器 方便拉取镜像
sudo systemctl daemon-reload
sudo systemctl restart docker
添加阿里云的YUM软件源
由于kubernetes的镜像源在国外,非常慢,这里切换成国内的阿里云镜像源
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
安装kubeadm、kubelet和kubectl
yum install -y kubelet-1.18.0 kubeadm-1.18.0 kubectl-1.18.0
为了实现Docker使用的cgroup drvier和kubelet使用的cgroup drver一致,建议修改"/etc/sysconfig/kubelet"文件的内容:
vim /etc/sysconfig/kubelet
# 修改 KUBELET_EXTRA_ARGS="--cgroup-driver=systemd"
KUBE_PROXY_MODE="ipvs"
systemctl enable kubelet # 设置开机自启动
部署master节点
# 由于默认拉取镜像地址k8s.gcr.io国内无法访问,这里需要指定阿里云镜像仓库地址
kubeadm init \
--apiserver-advertise-address=192.168.18.100 \ #master节点 ip
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.18.0 \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=10.244.0.0/16
根据提示消息,在Master节点上使用kubectl工具:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
部署k8s的Node节点
根据提示,在node节点服务器添加类似如下信息:
kubeadm join 192.168.18.100:6443 --token jv039y.bh8yetcpo6zeqfyj \
--discovery-token-ca-cert-hash sha256:3c81e535fd4f8ff1752617d7a2d56c3b23779cf9545e530828c0ff6b507e0e26
# 在master 节点执行生成 token 加入节点
kubeadm token create --print-join-command
10部署网络CNI插件
据提示,在Master节点上使用kubectl工具查看节点状态:
kubectl get nodes
kubernetes支持多种网络插件,比如flannel、calico、canal等,
我这是是提前下载好的flannel.yaml文件
直接执行 kubectl apply -f flannel.yaml
kubectl命令自动补全设置
yum install -y bash-completion
source /usr/share/bash-completion/bash_completion
source <(kubectl completion bash)
echo “source <(kubectl completion bash)” >> ~/.bashrc
vim /root/.bashrc
source /usr/share/bash-completion/bash_completion
source <(kubectl completion bash)
5.k8s资源管理
在Kubernetes中,所有的内容都抽象为资源,用户需要通过操作资源来管理Kubernetes。
Kubernetes的本质就是一个集群系统,用户可以在集群中部署各种服务。所谓的部署服务,其实就是在Kubernetes集群中运行一个个的容器,并将指定的程序跑在容器中。
●Kubernetes的最小管理单元是Pod而不是容器,所以只能将容器放在Pod中,而Kubernetes一般也不会直接管理Pod,而是通过Pod控制器来管理Pod的。
●Pod提供服务之后,就需要考虑如何访问Pod中的服务,Kubernetes提供了Service资源实现这个功能。
●当然,如果Pod中程序的数据需要持久化,Kubernetes还提供了各种存储系统
5.1资源管理方式
k8s资源管理方式有三种:
命令式对象管理:直接使用命令去操作kubernetes的资源。
kubectl run nginx-pod --image=nginx:1.17.1 --port=80 #直接创建一个pod并指定运行nginx容器
命令式对象配置:通过命令配置和配置文件去操作kubernetes的资源。
kubectl create/patch -f nginx-pod.yaml
声明式对象配置:通过apply命令和配置文件去操作kubernetes的资源。
kubectl apply -f nginx-pod.yaml
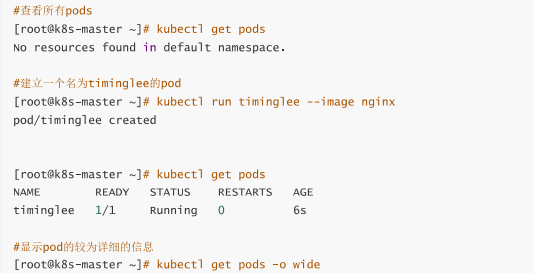
5.2基本命令式例
kubectl version #显示集群版本信息

kubectl cluster-info #显示集群信息

kubectl create deployment web --image=nginx:latest #创建一个web控制器
更高k8s版本可以通过 --replicas 2 来指定控制器中的pod数量
kubectl get deployments.apps #查看控制器信息
kubectl explanin deployment # 查看资源帮助
kubectl explain deployment.spec #查看控制器参数帮助

kubectl edit deployments.apps web -o yaml 以yaml的形式输出deployment的信息
kubectl edit deployment.apps web 修改yaml
#端口暴露:先启动pod 然后再暴露端口
kubectl run testpod --image reg.timinglee.org/pod/nginx
kubectl expose pod testpod --port 80 --target-port 80 通过暴露端口可以实现对外访问
kubectl logs pods/testpod 查看这个端口的日志
kubectl run -it testpod --image busybox #运行交互pod
kubectl run nginx --image nginx # 运行非交互pod
kubectl attach pods/testpod -it # 进入已经运行的容器 且容器有交互环境
5.3高级命令示例
使用命令生成yaml 模板文件
kubectl create deploment --image nginx webcluster --dry-run=client -o yaml > webcluster.yaml

kubcectl apply -f webcluster.yaml
kubectl delete -f webcluster.yaml
###控制器会通过pod的标签去弹性伸缩pod数量

如图pod labels为web
kubectl label pods web-6ddfddb795-62jn6 app=lee --overwrite #改一个pod标签为
由于指定了replicas此时deploment控制器会发现 少一个副本数量

于是会添加一个pods服务于web

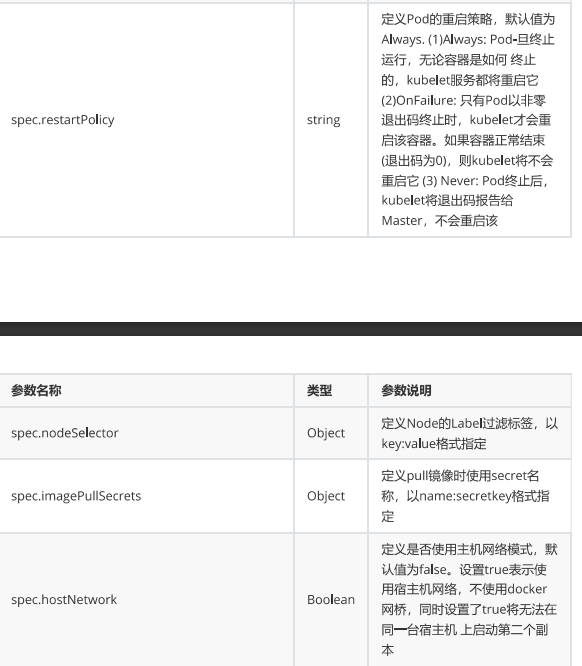
6.k8s中的pod
k8s最小控制单元pod
一个pod代表着集群中运行的一个进程,每一个pod都有唯一的一个ip
一个pod类似一个豌豆荚,包含一个或多个容器
多个容器共享ipc,Network和UTC namesoace
6.1创建自主式pod(不推荐)
6.2利用控制器管理pod(推荐)

6.2.1 扩缩容
kubectl create deploment web ---image nginx

#给web扩容
kubectl scale deployment web --replicas 2

给web缩容

6.2.2应用版本更新

6.3利用yaml文件部署应用
kubectl explain pod.spec.containers #查看资源帮助
6.4 pod的生命周期
Init容器: 主要功能在启动pod前先执行init容器 作为一个判断条件 当条件满足时候才能启动pod
或者作为运行pod环境里需要的一些东西
(通俗易懂的讲就是说initpod执行起来才会执行pod容器

init容器的功能
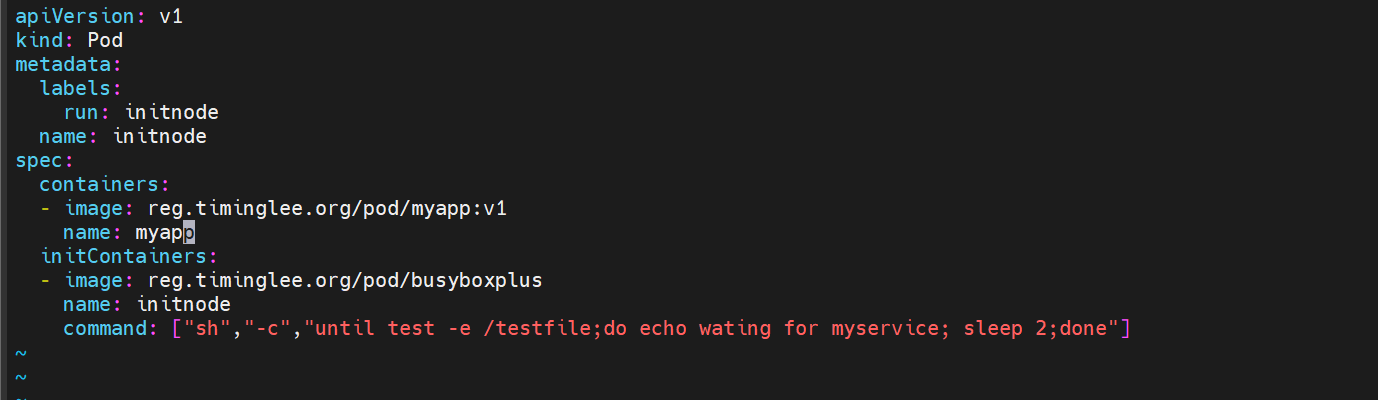 执行该pod先执行initContainers 等该模块符合条件了 才会执行containers启动这个pod
执行该pod先执行initContainers 等该模块符合条件了 才会执行containers启动这个pod
6.5pod的探针
检测pod运行情况是怎么样的



7.k8s中控制器
控制器也是管理pod的一种手段
-
自主式pod:pod退出或意外关闭后不会被重新创建
-
控制器管理的 Pod:在控制器的生命周期里,始终要维持 Pod 的副本数目
Pod控制器是管理pod的中间层,使用Pod控制器之后,只需要告诉Pod控制器,想要多少个什么样的Pod就可以了,它会创建出满足条件的Pod并确保每一个Pod资源处于用户期望的目标状态。如果Pod资源在运行中出现故障,它会基于指定策略重新编排Pod
当建立控制器后,会把期望值写入etcd,k8s中的apiserver检索etcd中我们保存的期望状态,并对比pod的当前状态,如果出现差异代码自驱动立即恢复
| 控制器名称 | 控制器用途 |
|---|---|
| Replication Controller | 比较原始的pod控制器,已经被废弃,由ReplicaSet替代 |
| ReplicaSet | ReplicaSet 确保任何时间都有指定数量的 Pod 副本在运行 |
| Deployment | 一个 Deployment 为 Pod 和 ReplicaSet 提供声明式的更新能力 |
| DaemonSet | DaemonSet 确保全指定节点上运行一个 Pod 的副本 |
| StatefulSet | StatefulSet 是用来管理有状态应用的工作负载 API 对象。 |
| Job | 执行批处理任务,仅执行一次任务,保证任务的一个或多个Pod成功结束 |
| CronJob | Cron Job 创建基于时间调度的 Jobs。 |
| HPA全称Horizontal Pod Autoscaler | 根据资源利用率自动调整service中Pod数量,实现Pod水平自动缩放 |
无状态pod 每重启一次 都换一个id
有状态pod 被记录着 始终是保持一个id
7.1replicaset控制器
-
ReplicaSet 是下一代的 Replication Controller,官方推荐使用ReplicaSet
-
ReplicaSet和Replication Controller的唯一区别是选择器的支持,ReplicaSet支持新的基于集合的选择器需求
-
ReplicaSet 确保任何时间都有指定数量的 Pod 副本在运行
-
虽然 ReplicaSets 可以独立使用,但今天它主要被Deployments 用作协调 Pod 创建、删除和更新的机制
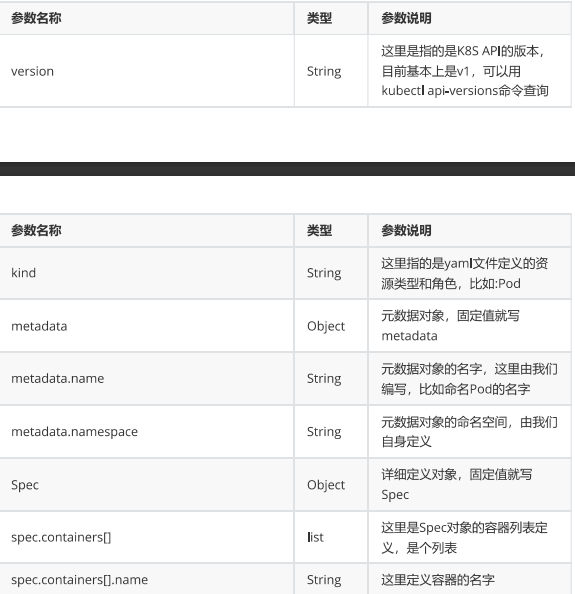
| 参数名称 | 字段类型 | 参数说明 |
|---|---|---|
| spec | Object | 详细定义对象,固定值就写Spec |
| spec.replicas | integer | 指定维护pod数量 |
| spec.selector | Object | Selector是对pod的标签查询,与pod数量匹配 |
| spec.selector.matchLabels | string | 指定Selector查询标签的名称和值,以key:value方式指定 |
| spec.template | Object | 指定对pod的描述信息,比如lab标签,运行容器的信息等 |
| spec.template.metadata | Object | 指定pod属性 |
| spec.template.metadata.labels | string | 指定pod标签 |
| spec.template.spec | Object | 详细定义对象 |
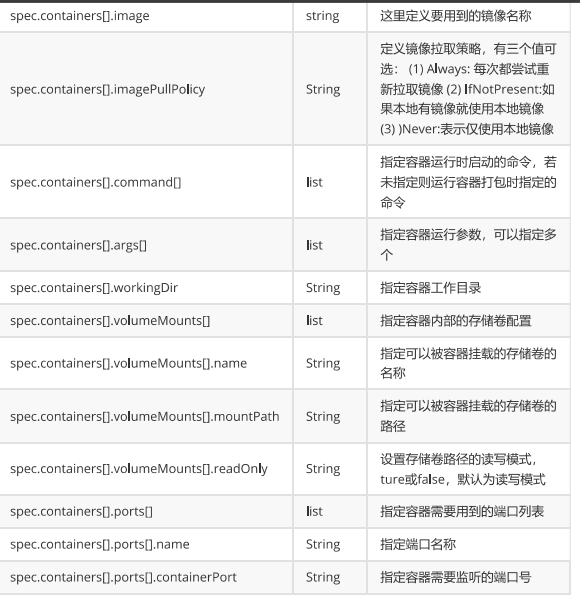
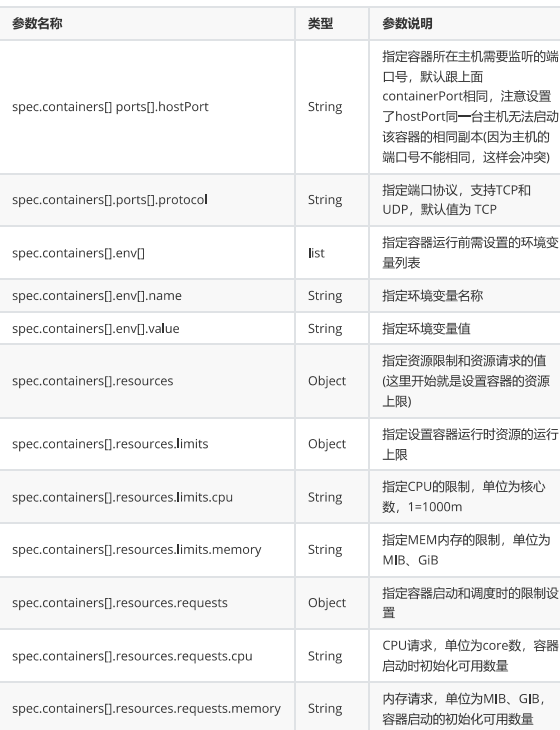
| spec.template.spec.containers | list | Spec对象的容器列表定义 |
| spec.template.spec.containers.name | string | 指定容器名称 |
| spec.template.spec.containers.image | string | 指定容器镜像 |
replicaset 时刻保持pod按照replicas在运行
实质是deployment 的一个分支版本 是通过labels去控制pod数量
#生成yml文件
[root@k8s-master ~]# kubectl create deployment replicaset --image myapp:v1 --dry-run=client -o yaml > replicaset.yml
[root@k8s-master ~]# vim replicaset.yml
apiVersion: apps/v1
kind: ReplicaSet #yaml文件创建出来要更改此处类型
metadata:
name: replicaset #指定pod名称,一定小写,如果出现大写报错
spec:
replicas: 2 #指定维护pod数量为2
selector: #指定检测匹配方式
matchLabels: #指定匹配方式为匹配标签
app: myapp #指定匹配的标签为app=myapp
template: #模板,当副本数量不足时,会根据下面的模板创建pod副本
metadata:
labels:
app: myapp
spec:
containers:
- image: myapp:v1
name: myapp
[root@k8s-master ~]# kubectl apply -f replicaset.yml
replicaset.apps/replicaset created
#replicaset是通过标签匹配pod
[root@k8s-master ~]# kubectl label pod replicaset-l4xnr app=timinglee --overwrite
pod/replicaset-l4xnr labeled
[root@k8s-master ~]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
replicaset-gd5fh 1/1 Running 0 2s app=myapp #新开启的pod
replicaset-l4xnr 1/1 Running 0 3m19s app=timinglee
replicaset-t2s5p 1/1 Running 0 3m19s app=myapp
#恢复标签后
[root@k8s2 pod]# kubectl label pod replicaset-example-q2sq9 app-
[root@k8s2 pod]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
replicaset-example-q2sq9 1/1 Running 0 3m14s app=nginx
replicaset-example-th24v 1/1 Running 0 3m14s app=nginx
replicaset-example-w7zpw 1/1 Running 0 3m14s app=nginx
7.2deploment控制器
-
为了更好的解决服务编排的问题,kubernetes在V1.2版本开始,引入了Deployment控制器。
-
Deployment控制器并不直接管理pod,而是通过管理ReplicaSet来间接管理Pod
-
Deployment管理ReplicaSet,ReplicaSet管理Pod
-
Deployment 为 Pod 和 ReplicaSet 提供了一个申明式的定义方法
-
在Deployment中ReplicaSet相当于一个版本
-
典型的应用场景:
-
用来创建Pod和ReplicaSet
-
滚动更新和回滚
-
扩容和缩容
-
暂停与恢复
例子:
7.2.1版本更新
[root@k8s-master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deployment-5d886954d4-2ckqw 1/1 Running 0 2m40s 10.244.2.14 k8s-node2 <none> <none>
deployment-5d886954d4-m8gpd 1/1 Running 0 2m40s 10.244.1.17 k8s-node1 <none> <none>
deployment-5d886954d4-s7pws 1/1 Running 0 2m40s 10.244.1.16 k8s-node1 <none> <none>
deployment-5d886954d4-wqnvv 1/1 Running 0 2m40s 10.244.2.15 k8s-node2 <none> <none>
#pod运行容器版本为v1
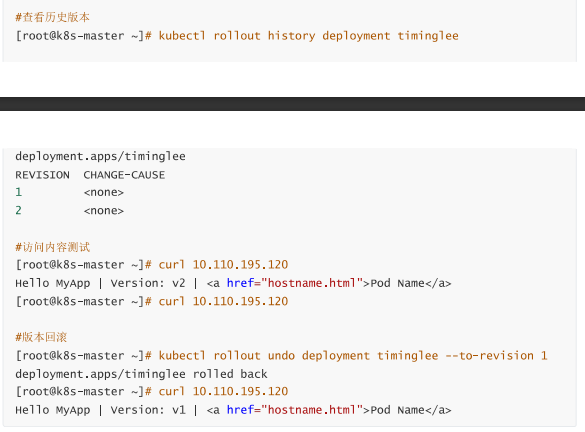
[root@k8s-master ~]# curl 10.244.2.14
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
[root@k8s-master ~]# kubectl describe deployments.apps deployment
Name: deployment
Namespace: default
CreationTimestamp: Sun, 01 Sep 2024 23:19:10 +0800
Labels: <none>
Annotations: deployment.kubernetes.io/revision: 1
Selector: app=myapp
Replicas: 4 desired | 4 updated | 4 total | 4 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge #默认每次更新25%
#更新容器运行版本
[root@k8s-master ~]# vim deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment
spec:
replicas: 4
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- image: myapp:v2 #更新为版本2
name: myapp
[root@k8s2 pod]# kubectl apply -f deployment-example.yaml
#更新过程
[root@k8s-master ~]# kubectl get pods -w
NAME READY STATUS RESTARTS AGE
deployment-5d886954d4-8kb28 1/1 Running 0 48s
deployment-5d886954d4-8s4h8 1/1 Running 0 49s
deployment-5d886954d4-rclkp 1/1 Running 0 50s
deployment-5d886954d4-tt2hz 1/1 Running 0 50s
deployment-7f4786db9c-g796x 0/1 Pending 0 0s
deployment-7f4786db9c-g796x 0/1 Pending 0 0s
deployment-5d886954d4-rclkp 1/1 Terminating 0 64s
deployment-7f4786db9c-mk6ts 0/1 Pending 0 0s
deployment-7f4786db9c-g796x 0/1 ContainerCreating 0 0s
deployment-7f4786db9c-mk6ts 0/1 Pending 0 0s
deployment-7f4786db9c-mk6ts 0/1 ContainerCreating 0 0s
deployment-5d886954d4-rclkp 0/1 Terminating 0 65s
deployment-7f4786db9c-mk6ts 1/1 Running 0 2s
deployment-5d886954d4-tt2hz 1/1 Terminating 0 66s
deployment-7f4786db9c-585dg 0/1 Pending 0 0s
deployment-7f4786db9c-585dg 0/1 Pending 0 0s
deployment-7f4786db9c-585dg 0/1 ContainerCreating 0 0s
deployment-7f4786db9c-g796x 1/1 Running 0 2s
deployment-5d886954d4-8s4h8 1/1 Terminating 0 65s
deployment-7f4786db9c-wxsdc 0/1 Pending 0 0s
deployment-5d886954d4-rclkp 0/1 Terminating 0 66s
deployment-7f4786db9c-wxsdc 0/1 Pending 0 0s
deployment-5d886954d4-rclkp 0/1 Terminating 0 66s
deployment-7f4786db9c-wxsdc 0/1 ContainerCreating 0 0s
deployment-5d886954d4-rclkp 0/1 Terminating 0 66s
deployment-5d886954d4-tt2hz 0/1 Terminating 0 66s
deployment-5d886954d4-8s4h8 0/1 Terminating 0 65s
deployment-7f4786db9c-wxsdc 1/1 Running 0 1s
deployment-5d886954d4-8kb28 1/1 Terminating 0 65s
deployment-5d886954d4-tt2hz 0/1 Terminating 0 67s
deployment-5d886954d4-tt2hz 0/1 Terminating 0 67s
deployment-5d886954d4-tt2hz 0/1 Terminating 0 67s
deployment-5d886954d4-8s4h8 0/1 Terminating 0 66s
deployment-5d886954d4-8s4h8 0/1 Terminating 0 66s
deployment-5d886954d4-8s4h8 0/1 Terminating 0 66s
deployment-7f4786db9c-585dg 1/1 Running 0 1s
deployment-5d886954d4-8kb28 0/1 Terminating 0 65s
deployment-5d886954d4-8kb28 0/1 Terminating 0 66s
deployment-5d886954d4-8kb28 0/1 Terminating 0 66s
deployment-5d886954d4-8kb28 0/1 Terminating 0 66s
#测试更新效果
[root@k8s-master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deployment-7f4786db9c-967fk 1/1 Running 0 10s 10.244.1.26 k8s-node1 <none> <none>
deployment-7f4786db9c-cvb9k 1/1 Running 0 10s 10.244.2.24 k8s-node2 <none> <none>
deployment-7f4786db9c-kgss4 1/1 Running 0 9s 10.244.1.27 k8s-node1 <none> <none>
deployment-7f4786db9c-qts8c 1/1 Running 0 9s 10.244.2.25 k8s-node2 <none> <none>
[root@k8s-master ~]# curl 10.244.1.26
Hello MyApp | Version: v2 | <a href="hostname.html">Pod Name</a>
7.2.2版本回滚
[root@k8s-master ~]# vim deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment
spec:
replicas: 4
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- image: myapp:v1 #回滚到之前版本
name: myapp
[root@k8s-master ~]# kubectl apply -f deployment.yml
deployment.apps/deployment configured
#测试回滚效果
[root@k8s-master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deployment-5d886954d4-dr74h 1/1 Running 0 8s 10.244.2.26 k8s-node2 <none> <none>
deployment-5d886954d4-thpf9 1/1 Running 0 7s 10.244.1.29 k8s-node1 <none> <none>
deployment-5d886954d4-vmwl9 1/1 Running 0 8s 10.244.1.28 k8s-node1 <none> <none>
deployment-5d886954d4-wprpd 1/1 Running 0 6s 10.244.2.27 k8s-node2 <none> <none>
[root@k8s-master ~]# curl 10.244.2.26
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
7.2.3滚动更新策略
[root@k8s-master ~]# vim deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment
spec:
minReadySeconds: 5 #最小就绪时间,指定pod每隔多久更新一次
replicas: 4
strategy: #指定更新策略
rollingUpdate:
maxSurge: 1 #允许比定义的pod多一个pod 多一个pod更新一个pod 直至更新完毕
maxUnavailable: 0 #定义了四个pod 更新的时候4个pod必须同时running中
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- image: myapp:v1
name: myapp
[root@k8s2 pod]# kubectl apply -f deployment-example.yaml
7.2.4暂停及恢复
在实际生产环境中我们做的变更可能不止一处,当修改了一处后,如果执行变更就直接触发了
我们期望的触发时当我们把所有修改都搞定后一次触发
暂停,避免触发不必要的线上更新
kubectl rollout pause deployment deployment-example #暂停更新
kubectl rollout resume deployment deployment-example #恢复更新后触发更新的内容
kubectl rollout history deployment deployment-example #查看更新的历史
7.3daemonsent控制器
DaemonSet 确保全部(或者某些)节点上运行一个 Pod 的副本。当有节点加入集群时, 也会为他们新增一个 Pod ,当有节点从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod
DaemonSet 的典型用法:
-
在每个节点上运行集群存储 DaemonSet,例如 glusterd、ceph。
-
在每个节点上运行日志收集 DaemonSet,例如 fluentd、logstash。
-
在每个节点上运行监控 DaemonSet,例如 Prometheus Node Exporter、zabbix agent等
-
一个简单的用法是在所有的节点上都启动一个 DaemonSet,将被作为每种类型的 daemon 使用
-
一个稍微复杂的用法是单独对每种 daemon 类型使用多个 DaemonSet,但具有不同的标志, 并且对不同硬件类型具有不同的内存、CPU 要求
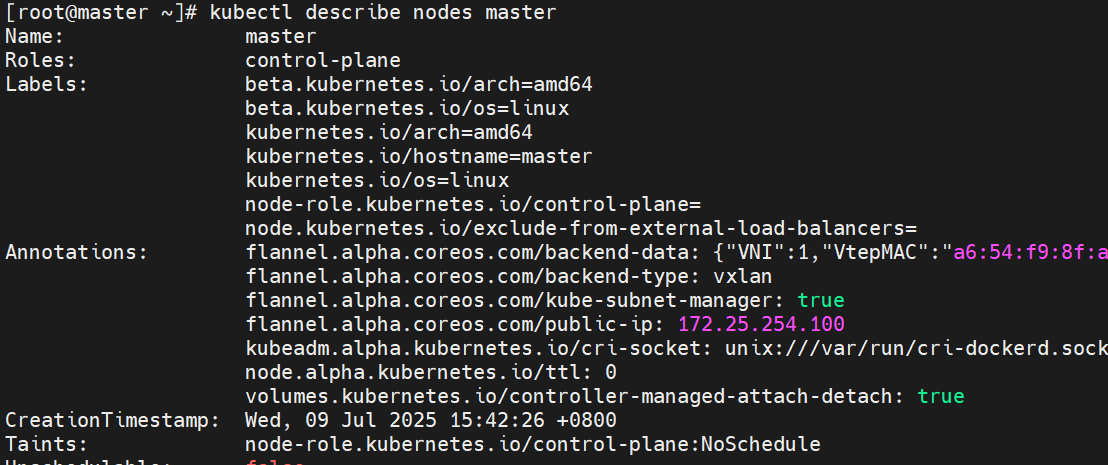
查看master节点信息 他有污点是NoSchedule 所以不给他调度服务
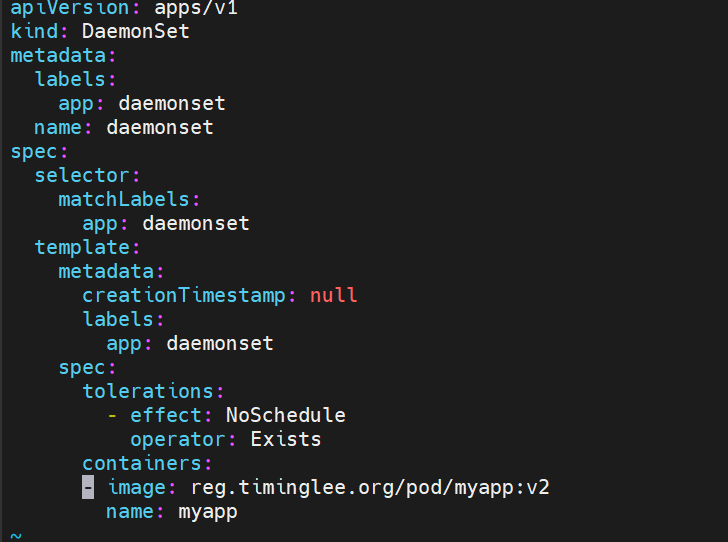
spec:
tolerations: #对于污点节点的容忍
- effect: NoSchedule
operator: Exists #强容忍 有没有污点都能容忍
通过添加 template下的spec模块下的tolerations模块 能实现污点的容忍 所以 能给master节点调度到pod

7.4job控制器
Job,主要用于负责批量处理(一次要处理指定数量任务)短暂的一次性(每个任务仅运行一次就结束)任务
Job特点如下:
-
当Job创建的pod执行成功结束时,Job将记录成功结束的pod数量
-
当成功结束的pod达到指定的数量时,Job将完成执行
kubectl create job t-job --images perl:5.34.0 --dry-run=client -o yaml > job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
completions: 6 #一共完成任务数为6
parallelism: 2 #每次并行完成2个
template:
spec:
containers:
- name: pi
image: perl:5.34.0
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"] 计算Π的后2000位
restartPolicy: Never #关闭后不自动重启
backoffLimit: 4 #运行失败后尝试4重新运行
关于重启策略设置的说明:
-
如果指定为OnFailure,则job会在pod出现故障时重启容器
而不是创建pod,failed次数不变
-
如果指定为Never,则job会在pod出现故障时创建新的pod
并且故障pod不会消失,也不会重启,failed次数加1
-
如果指定为Always的话,就意味着一直重启,意味着job任务会重复去执行了
[root@k8s2 pod]# kubectl apply -f job.yml
7.5cronjob控制器
-
Cron Job 创建基于时间调度的 Jobs。
-
CronJob控制器以Job控制器资源为其管控对象,并借助它管理pod资源对象,
-
CronJob可以以类似于Linux操作系统的周期性任务作业计划的方式控制其运行时间点及重复运行的方式。
-
CronJob可以在特定的时间点(反复的)去运行job任务
kubectl create cronjob cronjob --image reg.timinglee.org/pod/busyboxplus --schedule "*/1 * * * *" --dry-run=client -o yaml > cronjob.yaml
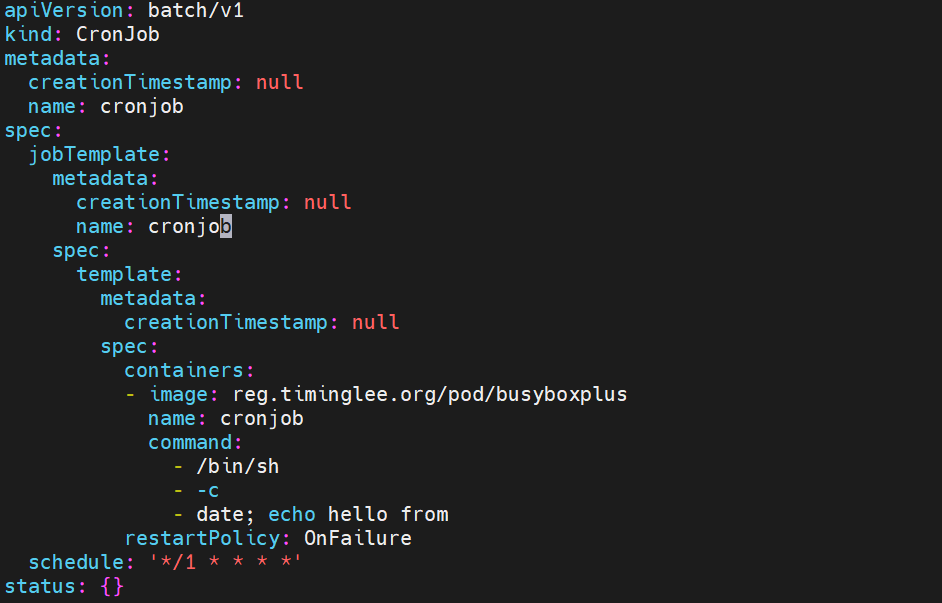
command 为动作 通过查看日志可以看到执行是否成功

8.k8s中的微服务
service是由kube-proxy组件和iptables共同实现的 但是宿主机有大量的pod的话 需要有很多iptables规则去不断的刷新 造成cpu资源的浪费 所以在这里 我们需要设置IPVS模式
1.ipvs配置方式:
所有节点 yum install ipvsadm -y
2.master节点:
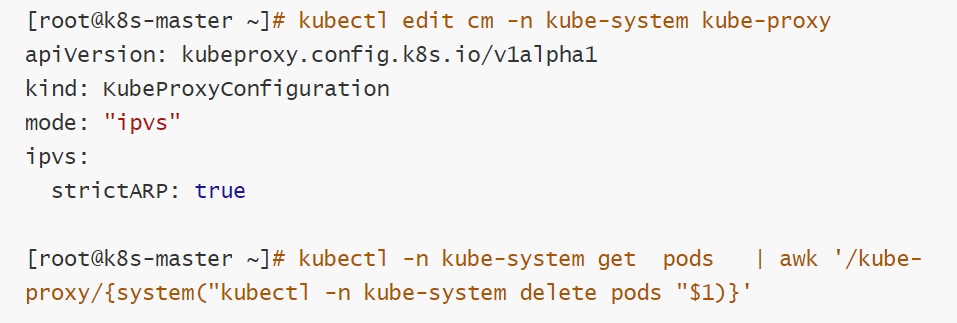
[root@k8s-master ~]# kubectl -n kube-system edit cm kube-proxy
metricsBindAddress: ""
mode: "ipvs" #设置kube-proxy使用ipvs模式
nftables:
3.重启pod,在pod运行时配置文件中采用默认配置,当改变配置文件后已经运行的pod状态不会变化,所以要重启pod
[root@k8s-master ~]# kubectl -n kube-system get pods | awk '/kube-proxy/{system("kubectl -n kube-system delete pods "$1)}'
用控制器来完成集群的工作负载,那么应用如何暴漏出去?需要通过微服务暴漏出去后才能被访问
-
Service是一组提供相同服务的Pod对外开放的接口。
-
借助Service,应用可以实现服务发现和负载均衡。
-
service默认只支持4层负载均衡能力,没有7层功能。(可以通过Ingress实现)
| 微服务类型 | 作用描述 |
|---|---|
| ClusterIP | 默认值,k8s系统给service自动分配的虚拟IP,只能在集群内部访问 |
| NodePort | 将Service通过指定的Node上的端口暴露给外部,访问任意一个NodeIP:nodePort都将路由到ClusterIP |
| LoadBalancer | 在NodePort的基础上,借助cloud provider创建一个外部的负载均衡器,并将请求转发到 NodeIP:NodePort,此模式只能在云服务器上使用 |
| ExternalName | 将服务通过 DNS CNAME 记录方式转发到指定的域名(通过 spec.externlName 设定 |
8.1 clusterip
想要访问pod里的服务的时候 先访问的是service的域名 然后通过ipvs策略转发到后面的pod
系统默认分配的虚拟ip 只允许在集群内部访问

访问成功
特殊模式headless无头服务:
直接去访问pod 不经过访问svc 直接访问pod ip
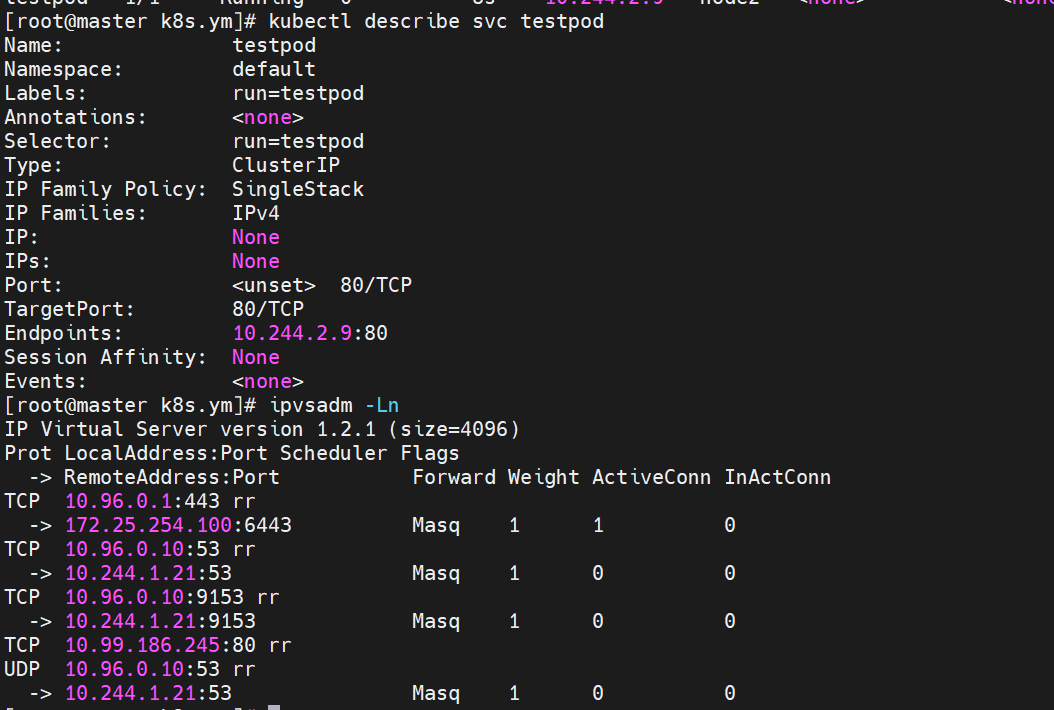
8.2 NodePort
nodeport 本质 通过ipvs暴露端口 给开启的pod里的服务提供一个对外访问的端口
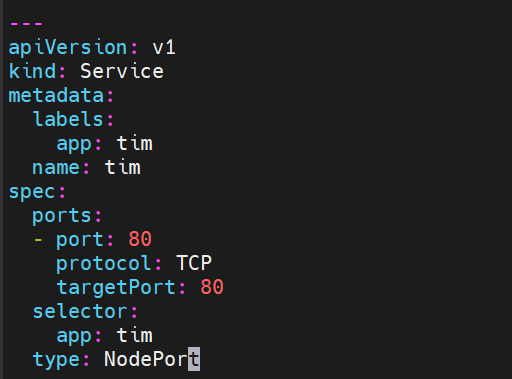
修改spec 下的type

利用别的服务器进行访问测试
harbor服务器:
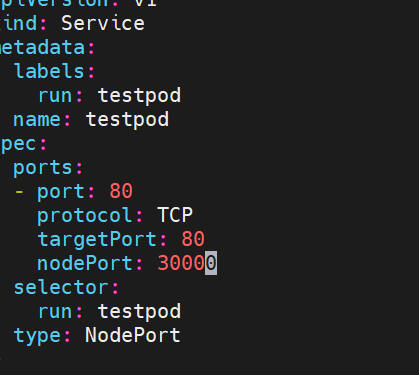
也可以通过修改指定端口 进行访问

访问成功
nodeport默认端口是30000-32767,超出会报错 (如果要范围以外的 需要更改配置文件中的特殊设定)
vim /etc/kubernetes/manifests/kube-apiserver.yaml
- --service-node-port-range=30000-40000
添加“--service-node-port-range=“ 参数,端口范围可以自定义
修改后api-server会自动重启,等apiserver正常启动后才能操作集群
集群重启自动完成在修改完参数后全程不需要人为干预
8.3LoadBalancer (metalLB)
云平台会为我们分配vip并实现访问,如果是裸金属主机那么需要metallb来实现ip的分配
访问方式:

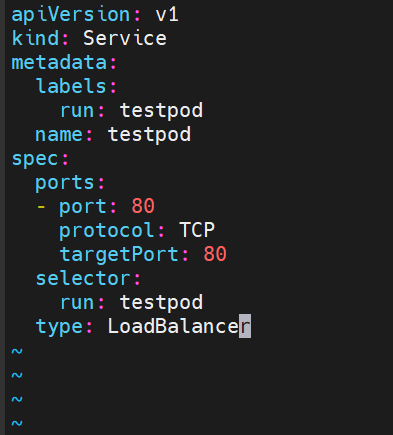
metalLB可以为 LoadBalancer 分配vip
服务器部署metalLB :
首先将master设置为ipvs模式
2.下载部署文件
wget https://raw.githubusercontent.com/metallb/metallb/v0.13.12/config/manifests/metallb-native.yaml
3.将下载下来的镜像 打上标签push到本地k8sharbor仓库


4. 修改metallb-native.yaml中的image 指定镜像位置


kubectl apply -f metallb-native.yaml #部署服务
vi configmap.yaml #设置地址池
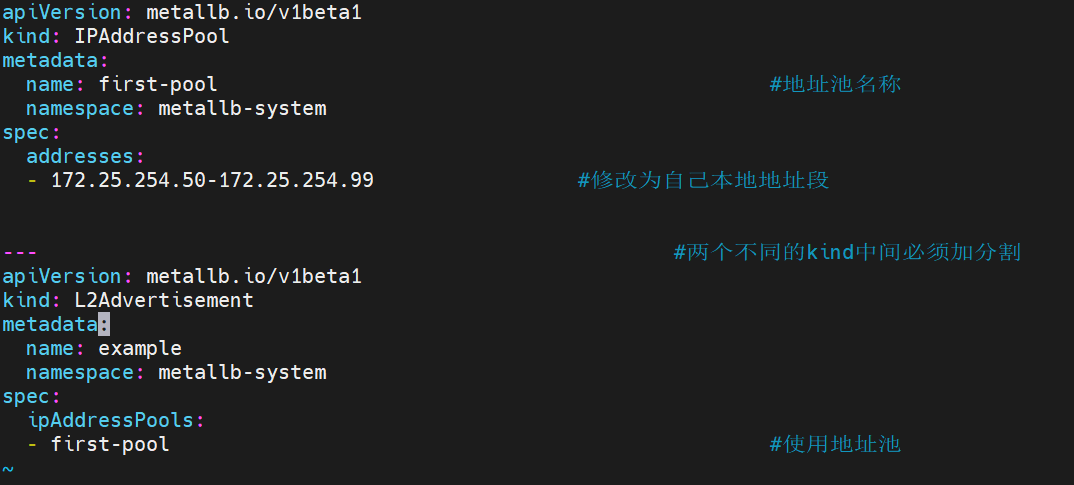

查看服务loadbalancer 已经有metalLB分配的ip 外部可以通过访问这个ip 访问pod内部容器

访问成功
8.4ExternalName
将服务通过DNS CNAME记录方式转发到指定的域名
-
开启services后,不会被分配IP,而是用dns解析CNAME固定域名来解决ip变化问题
-
一般应用于外部业务和pod沟通或外部业务迁移到pod内时
-
在应用向集群迁移过程中,externalname在过度阶段就可以起作用了。
-
集群外的资源迁移到集群时,在迁移的过程中ip可能会变化,但是域名+dns解析能完美解决此问题
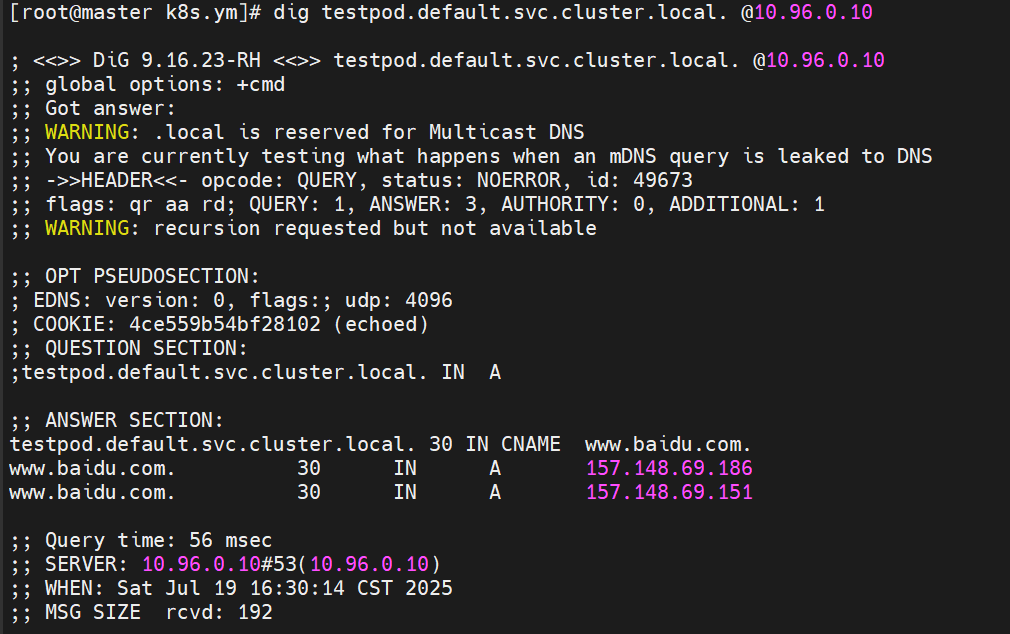
#首先查看k8s集群dns为10.96.0.10

修改yaml文件指定service类型 已经访问的域名
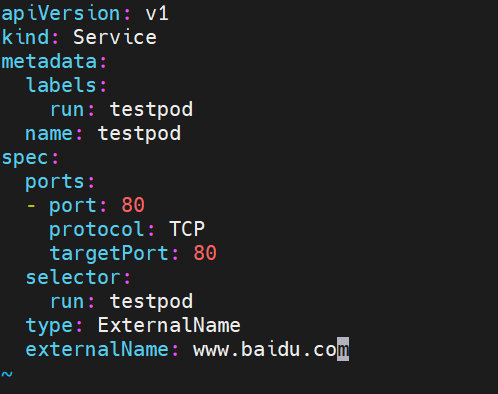
如下图为通过dns解析指向www.baidu.com
8.5 ingress
-
一种全局的、为了代理不同后端 Service 而设置的负载均衡服务,支持7层
-
Ingress由两部分组成:Ingress controller和Ingress服务
-
Ingress Controller 会根据你定义的 Ingress 对象,提供对应的代理能力。
-
业界常用的各种反向代理项目,比如 Nginx、HAProxy、Envoy、Traefik 等,都已经为Kubernetes 专门维护了对应的 Ingress Controller。
ingress相当于一个调度器 把请求调度到合适的service 或pod
ingress部署:
1.用yaml文件的方式部署 首先在ingress官网下载deploy.yaml到本地服务器
2.

将这俩个镜像打上标签 上传到本地的harbor仓库
3上传完成后 修改 deploy.yaml 指定拉取位置本地harbor仓库



4.kubectl apply -f deploy.ment

查看状态已经部署完成.
8.5.1 基于访问路径的发布
首先创建俩个服务不同的pod
kubectl create deployment myappv1 --image reg.timinglee.org/pod/myapp:v1 --dry-run=client -o yaml > myappv1.yaml
kubectl create deployment myappv2 --image reg.timinglee.org/pod/myapp:v2 --dry-run=client -o yaml > myappv2.yaml
kubectl expose deployment myappv1 --port 80 --target-port 80 --dry-run=client -o yaml >> myappv1.yaml
kubectl expose deployemnt myappv2 --port 80 --target-port 80 --dry-run=client -o yaml >> myappv2.yaml

service 已开启
然后开始简历ingress的yaml
kubectl create ingress myappv1 --class nginx --rule='/=myappv1:80' --dry-run=client -o yaml > ingress1.yaml
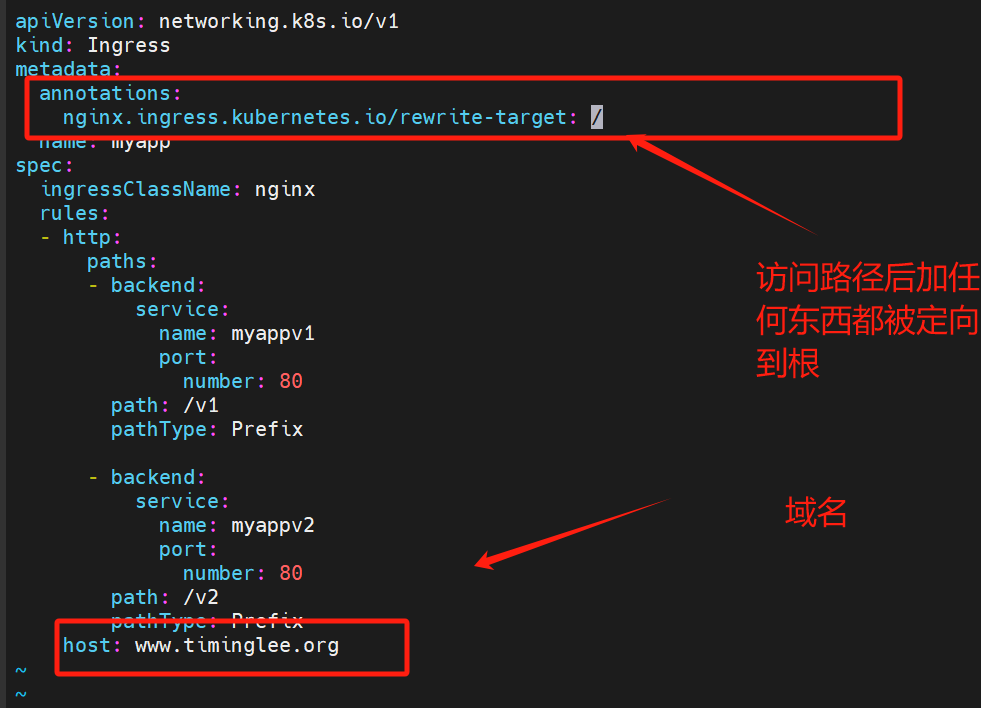
查看ingress svc的模式为loadbalance metallb分配的IP为 172.25.254.50
kubectl -n ingress-nginx edit svc ingress-nginx-controller(修改微服务的方式
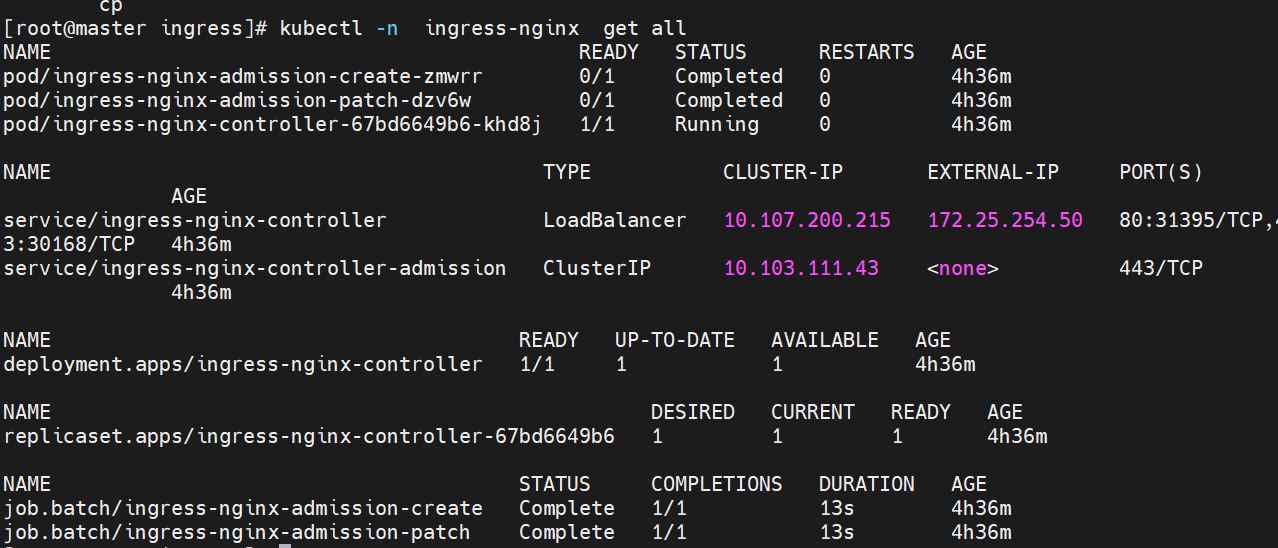
然后测试一下 在/etc/hosts下
echo 172.25.254.50 www.timinglee.org >> /etc/hosts
[root@reg ~]# curl www.timinglee.org/v1
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
[root@reg ~]# curl www.timinglee.org/v2
Hello MyApp | Version: v2 | <a href="hostname.html">Pod Name</a>
#nginx.ingress.kubernetes.io/rewrite-target: / 的功能实现
[root@reg ~]# curl www.timinglee.org/v2/aaaa
Hello MyApp | Version: v2 | <a href="hostname.html">Pod Name</a>
成功访问
8.5.2 基于域名的访问
cat ingress3.yaml
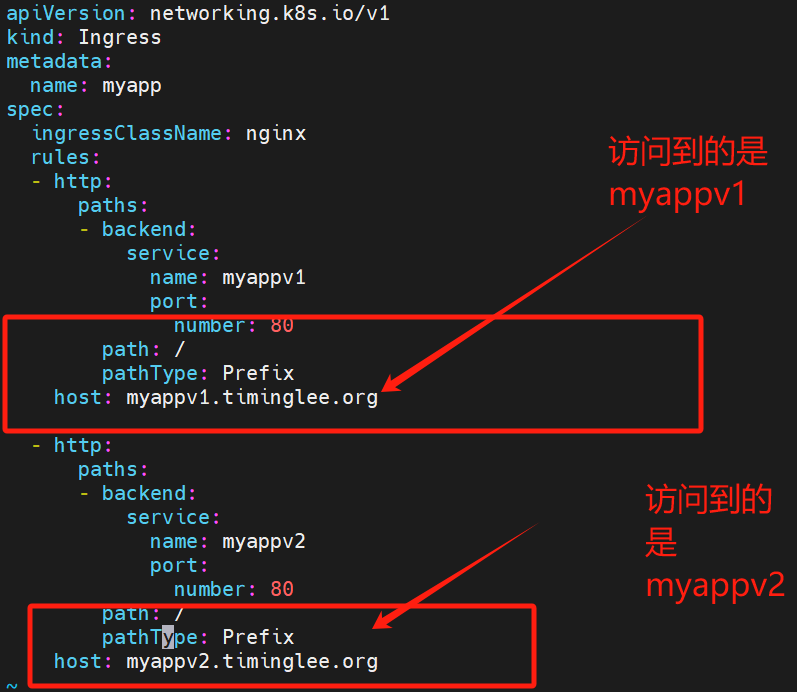
在/etc/hosts下做本地解析
172.25.254.50 myappv1.timinglee.org myappv2.timinglee.org
然后查看信息进行访问验证
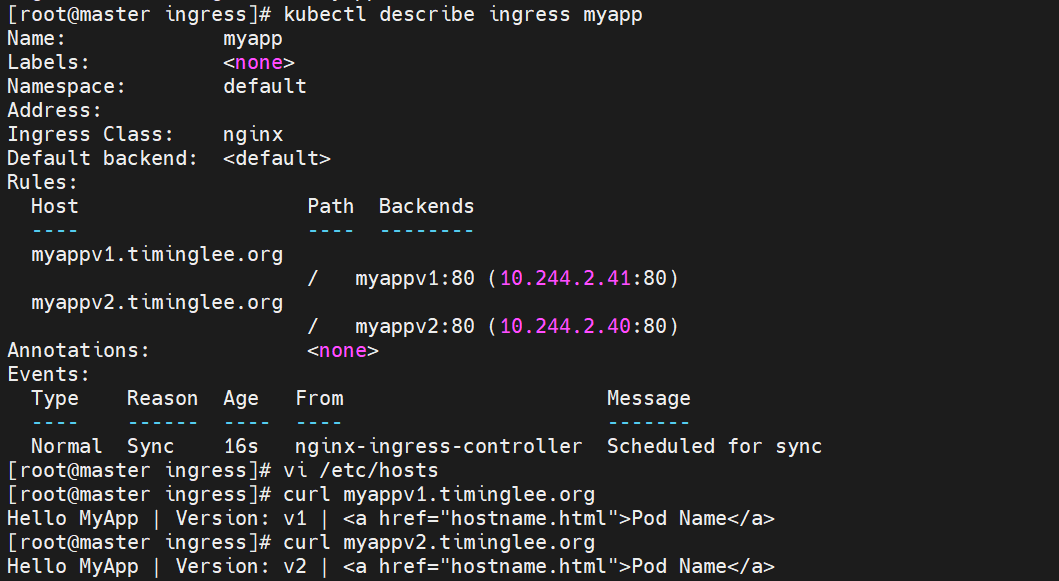
8.5.3简历tls认证(基于https进行访问控制)
1.生成证书和key
openssl req -newkey rsa:2048 -nodes -keyout tls.key -x509 -days 365 -subj "/CN=nginxsvc/O=nginxsvc" -out tls.crt
#建立加密资源类型secret
[root@k8s-master app]# kubectl create secret tls web-tls-secret --key tls.key --cert tls.crt
secret/web-tls-secret created
[root@k8s-master app]# kubectl get secrets
NAME TYPE DATA AGE
web-tls-secret kubernetes.io/tls 2 6s
vi ingress.yaml
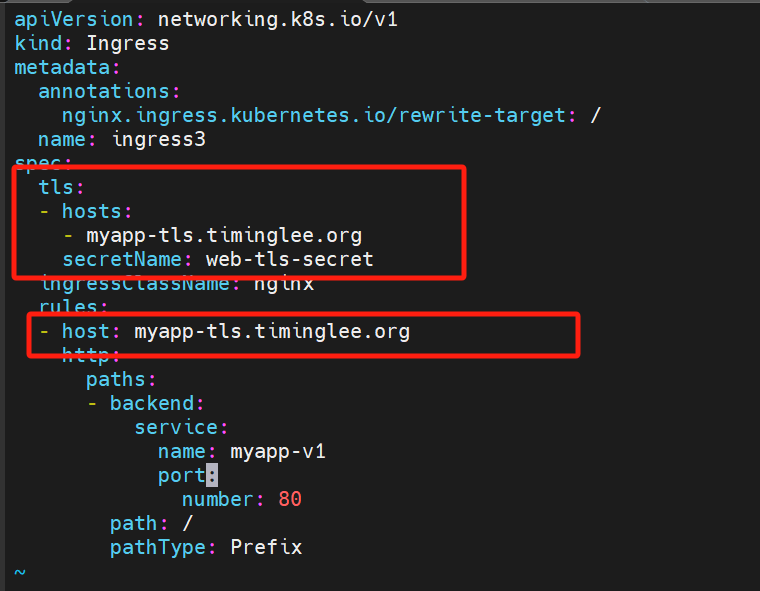
然后再/etc/hosts
172.25.254.50 myapp-tls.timinglee.org
访问成功

8.5.4 auth认证(基于https访问的时候需要密码验证)
[root@k8s-master app]# dnf install httpd-tools -y
[root@k8s-master app]# htpasswd -cm auth lee
New password:
Re-type new password:
Adding password for user lee
[root@k8s-master app]# cat auth
lee:$apr1$BohBRkkI$hZzRDfpdtNzue98bFgcU10
kubectl create secret generic auth-web --from-file auth #建立认证类型资源
root@k8s-master app]# kubectl describe secrets auth-web
Name: auth-web
Namespace: default
Labels: <none>
Annotations: <none>
Type: Opaque
Data
====
auth: 42 bytes
#建立ingress4基于用户认证的yaml文件
[root@k8s-master app]# vim ingress4.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
nginx.ingress.kubernetes.io/auth-type: basic
nginx.ingress.kubernetes.io/auth-secret: auth-web
nginx.ingress.kubernetes.io/auth-realm: "Please input username and password"
name: ingress4
spec:
tls:
- hosts:
- myapp-tls.timinglee.org
secretName: web-tls-secret
ingressClassName: nginx
rules:
- host: myapp-tls.timinglee.org
http:
paths:
- backend:
service:
name: myapp-v1
port:
number: 80
path: /
pathType: Prefix
#建立ingress4
[root@k8s-master app]# kubectl apply -f ingress4.yml
ingress.networking.k8s.io/ingress4 created
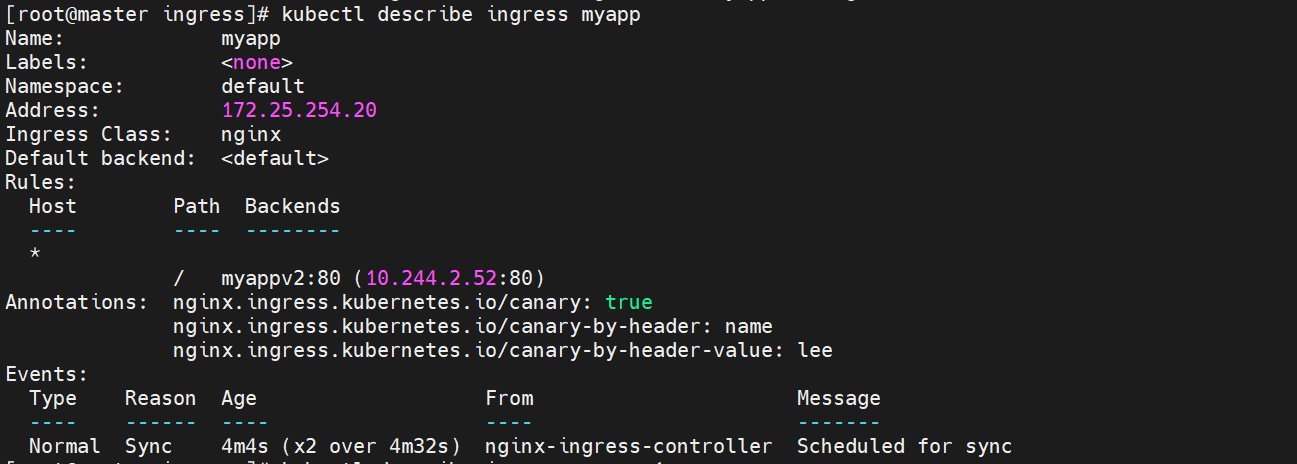
[root@k8s-master app]# kubectl describe ingress ingress4
Name: ingress4
Labels: <none>
Namespace: default
Address:
Ingress Class: nginx
Default backend: <default>
TLS:
web-tls-secret terminates myapp-tls.timinglee.org
Rules:
Host Path Backends
---- ---- --------
myapp-tls.timinglee.org
/ myapp-v1:80 (10.244.2.31:80)
Annotations: nginx.ingress.kubernetes.io/auth-realm: Please input username and password
nginx.ingress.kubernetes.io/auth-secret: auth-web
nginx.ingress.kubernetes.io/auth-type: basic
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Sync 14s nginx-ingress-controller Scheduled for sync
#测试:
[root@reg ~]# curl -k https://myapp-tls.timinglee.org
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
[root@reg ~]# vim /etc/hosts ^C
[root@reg ~]# curl -k https://myapp-tls.timinglee.org
<html>
<head><title>401 Authorization Required</title></head>
<body>
<center><h1>401 Authorization Required</h1></center>
<hr><center>nginx</center>
</body>
</html>
8.5.5rewrite重定向
8.6金丝雀发布
金丝雀发布(Canary Release)也称为灰度发布,是一种软件发布策略。
主要目的是在将新版本的软件全面推广到生产环境之前,先在一小部分用户或服务器上进行测试和验证,以降低因新版本引入重大问题而对整个系统造成的影响。
是一种Pod的发布方式。金丝雀发布采取先添加、再删除的方式,保证Pod的总量不低于期望值。并且在更新部分Pod后,暂停更新,当确认新Pod版本运行正常后再进行其他版本的Pod的更新。
三种发布方式 :header cookie weight
8.6.1基于包头(header)的:按照键值去访问
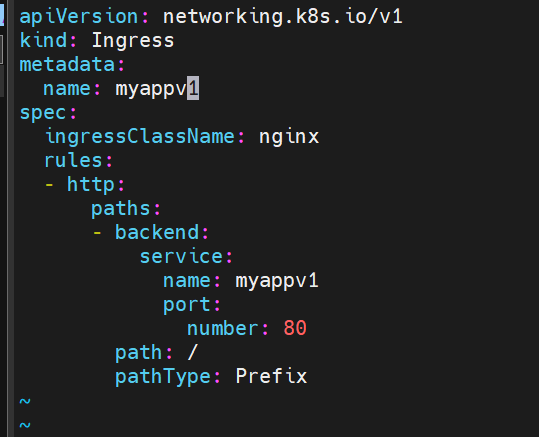
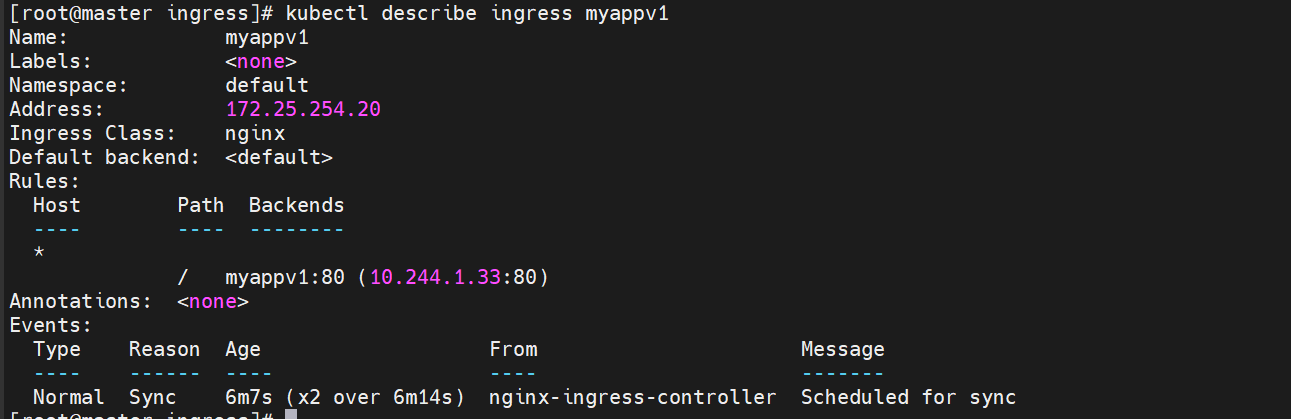
效果 :首先我们创建俩个ingress 分别用作不同的版本
v1:
v2(基于header的ingress)
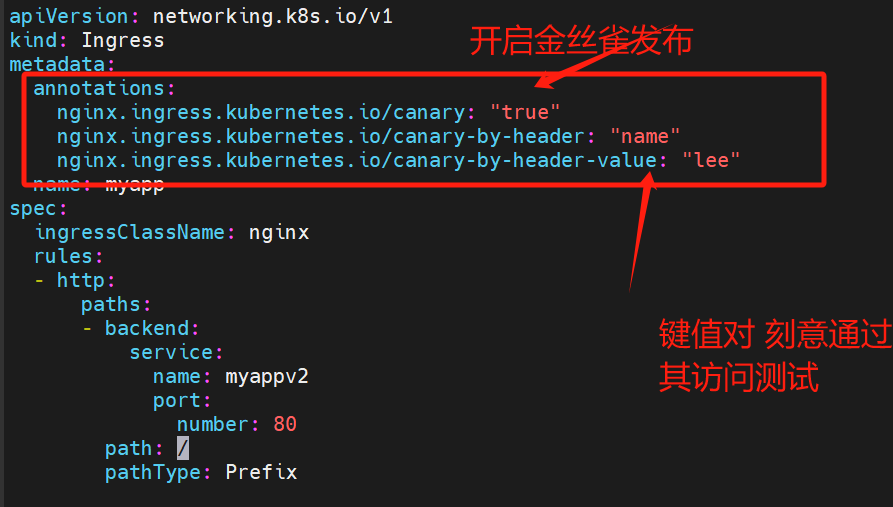

带header的就是更新过的版本
8.6.2基于权重的灰度发布
-
通过Annotaion拓展
-
创建灰度ingress,配置灰度权重以及总权重
-
灰度流量验证完毕后,切换正式ingress到新版本
[root@k8s-master app]# vim ingress8.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
nginx.ingress.kubernetes.io/canary: "true"
nginx.ingress.kubernetes.io/canary-weight: "10" #更改权重值
nginx.ingress.kubernetes.io/canary-weight-total: "100"
name: myapp-v2-ingress
spec:
ingressClassName: nginx
rules:
- host: myapp.timinglee.org
http:
paths:
- backend:
service:
name: myapp-v2
port:
number: 80
path: /
pathType: Prefix
[root@k8s-master app]# kubectl apply -f ingress8.yml
ingress.networking.k8s.io/myapp-v2-ingress created
#测试:
[root@reg ~]# vim check_ingress.sh
#!/bin/bash
v1=0
v2=0
for (( i=0; i<100; i++))
do
response=`curl -s myapp.timinglee.org |grep -c v1`
v1=`expr $v1 + $response`
v2=`expr $v2 + 1 - $response`
done
echo "v1:$v1, v2:$v2"
[root@reg ~]# sh check_ingress.sh
v1:90, v2:10
#更改完毕权重后继续测试可观察变化
9.k8s中的存储
9.1configmap
pod中的镜像不一定在每个生产环境都适用 如果通过docker build -t构建的话也不一定能够适用 所以引入 configmap
功能:
-
configMap用于保存配置数据,以键值对形式存储。
-
configMap 资源提供了向 Pod 注入配置数据的方法。
-
镜像和配置文件解耦,以便实现镜像的可移植性和可复用性。
-
etcd限制了文件大小不能超过1M
使用场景:
-
填充环境变量的值
-
设置容器内的命令行参数
-
填充卷的配置文件
四种创建方式:
1.通过字面值创建
kubectl create configmap userlist --from-literal name=lee --from-literal age=20
2.通过文件创建
kubectl create cm host --from-file /etc/resolv.conf
3.通过目录创建
kubectl create cm host1 --from-file /root/configmap/test/
4.通过yaml创建
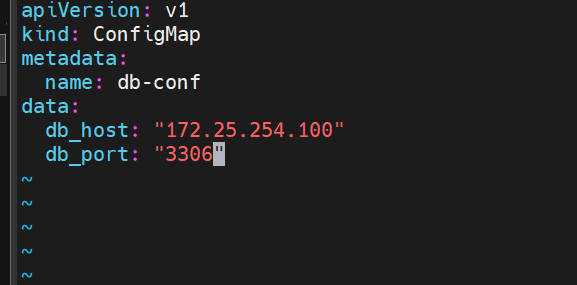
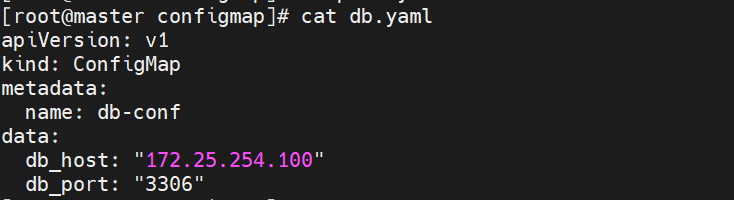
kubectl apply -f db.yaml
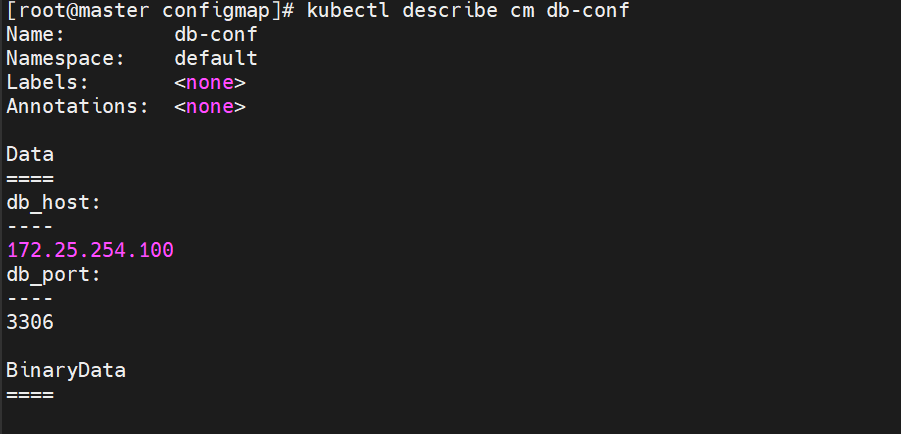
9.2configmap使用方式
-
通过环境变量的方式直接传递给pod
-
通过pod的 命令行运行方式
-
作为volume的方式挂载到pod内
9.2.1使用configmap填充环境变量
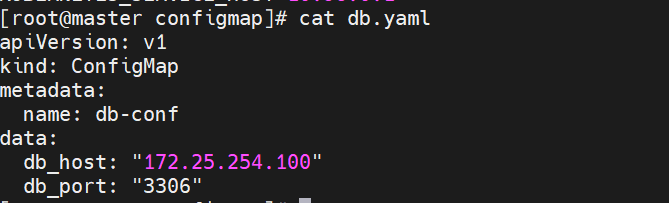
kubectl apply -f db.yaml
vi pod1.yaml
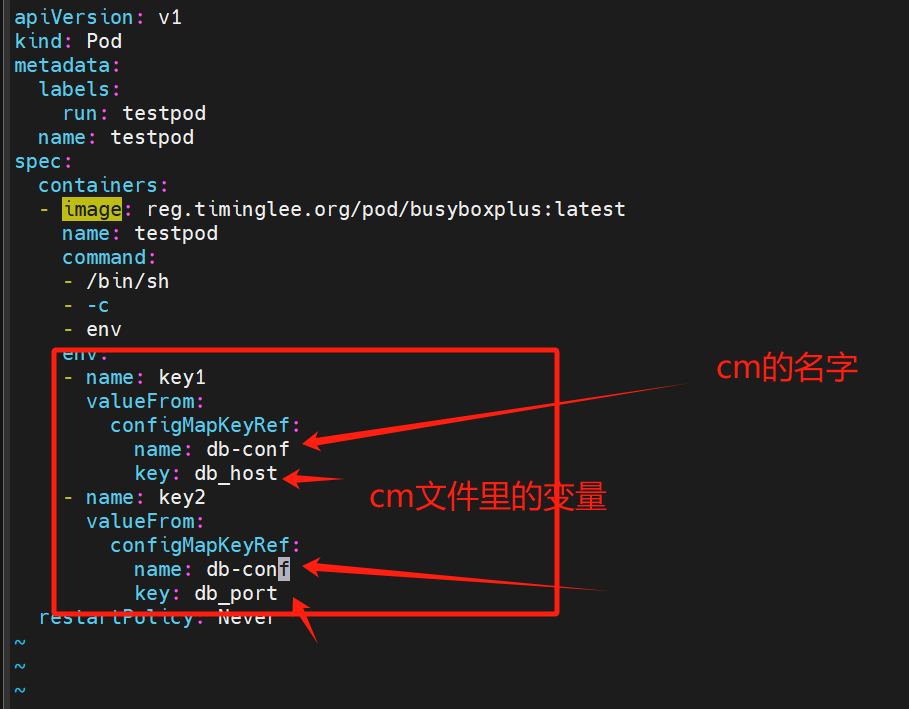
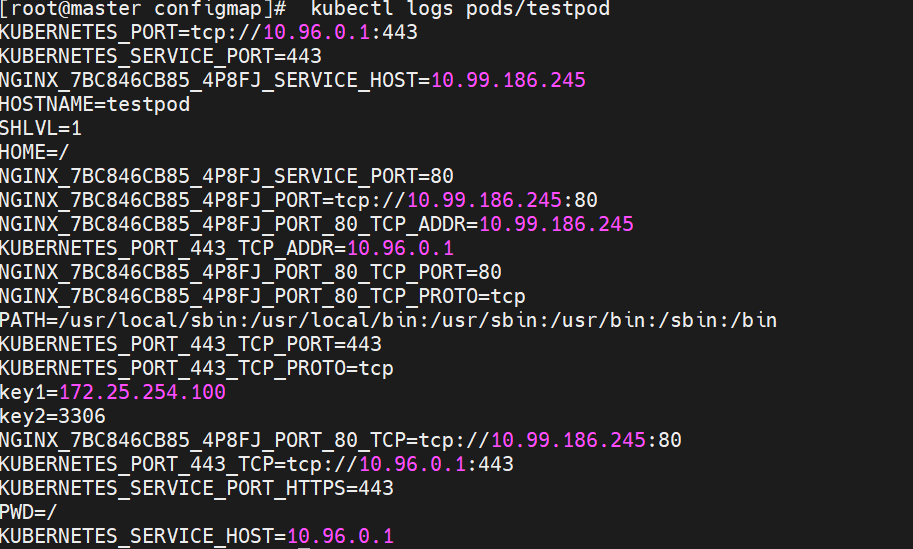
kubectl logs pods/testpod
查看一下 充当环境变量
在pod命令行中使用变量:
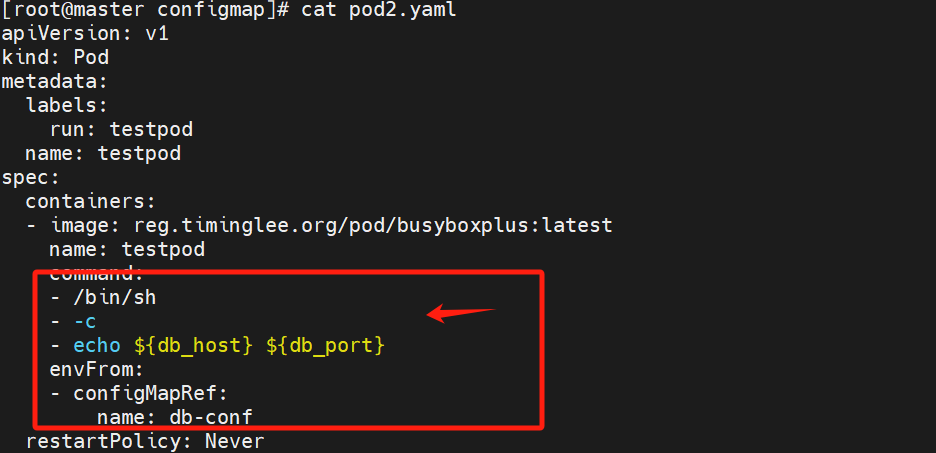

pod参数restartPolicy设置了执行以此就ok

查看日志确实执行了该变量
9.2.2通过数据卷使用configmap
9.2.3通过configmap 充当pod的配置文件
建立模板配置文件:
[root@k8s-master ~]# vim nginx.conf
server {
listen 8080;
server_name _;
root /usr/share/nginx/html;
index index.html;
}
#利用模板生成cm
root@k8s-master ~]# kubectl create cm nginx-conf --from-file nginx.conf
configmap/nginx-conf created
[root@k8s-master ~]# kubectl describe cm nginx-conf
Name: nginx-conf
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
nginx.conf:
----
server {
listen 8000;
server_name _;
root /usr/share/nginx/html;
index index.html;
}
BinaryData
====
Events: <none>
#建立nginx控制器文件
[root@k8s-master ~]# kubectl create deployment nginx --image nginx:latest --replicas 1 --dry-run=client -o yaml > nginx.yml
[root@k8s-master ~]# cat nginx.yml
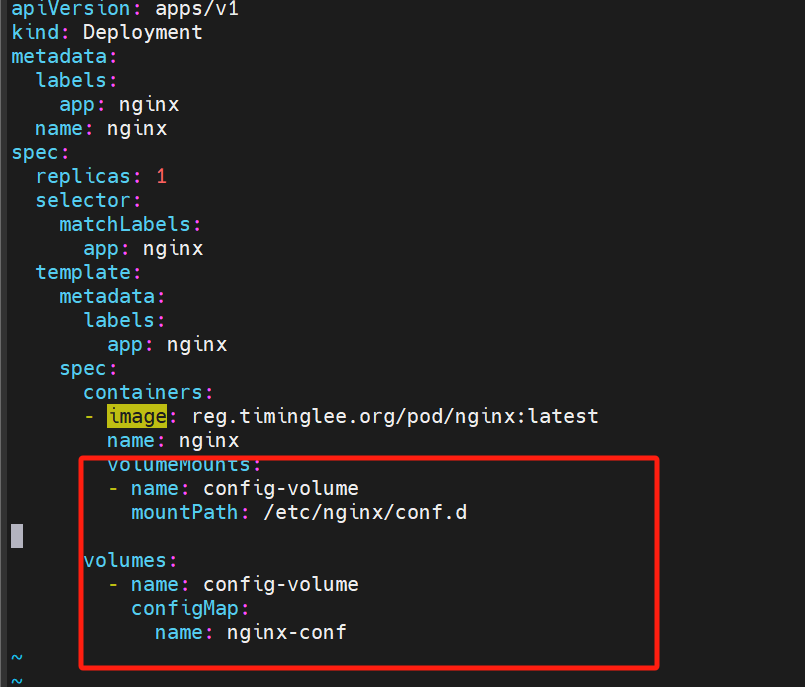
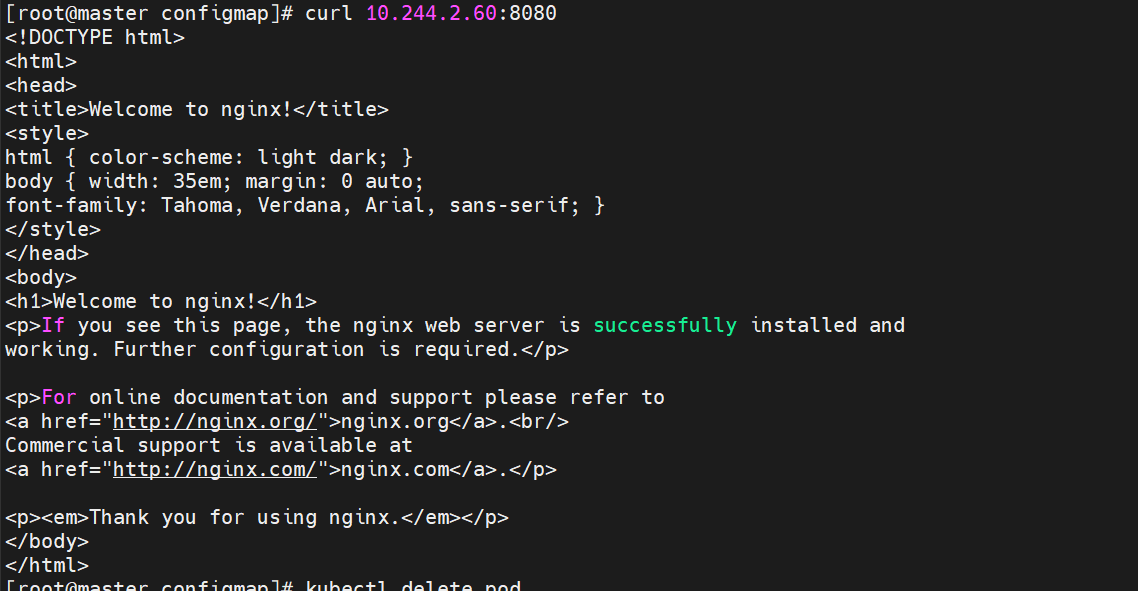
指定的8080端口去访问成功
kubectl edit cm nginx-conf #更改 cm 里的 nginx pod访问端口为80
直接更改完成后 可以删除pod deployment 会重启一个pod然后80端口生效
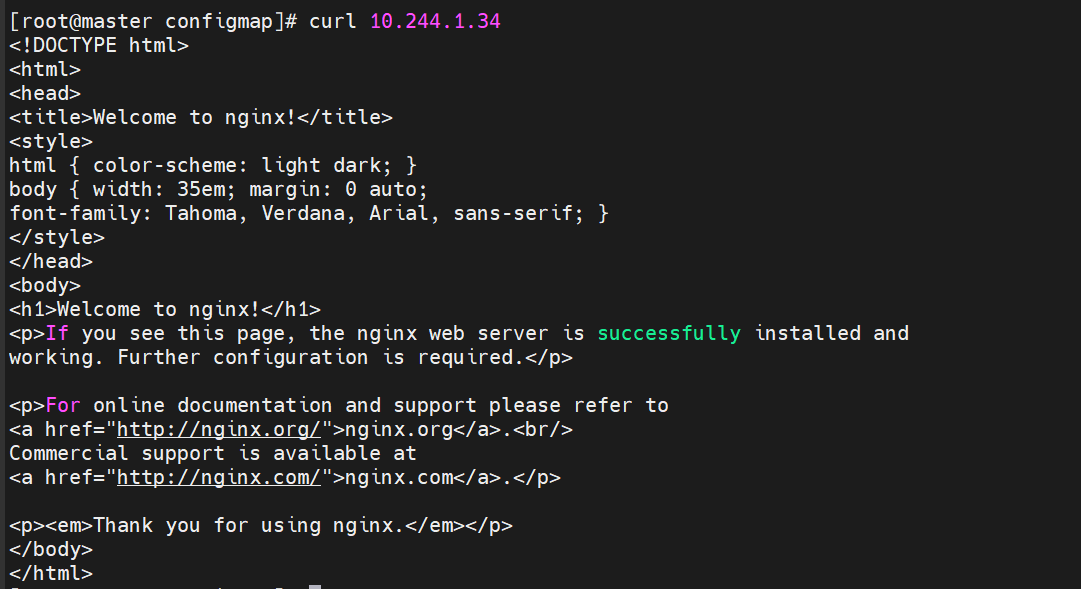
访问成功
9.3secrets配置管理
-
secret 对象类型用来保存敏感信息,例如密码、OAuth 令牌和 ssh key。
-
敏感信息放在 secret 中比放在 Pod 的定义或者容器镜像中来说更加安全和灵活
-
Pod 可以用两种方式使用 secret:
-
作为 volume 中的文件被挂载到 pod 中的一个或者多个容器里。
-
当 kubelet 为 pod 拉取镜像时使用。
-
-
Secret的类型:
-
Service Account:Kubernetes 自动创建包含访问 API 凭据的 secret,并自动修改 pod 以使用此类型的 secret。
-
Opaque:使用base64编码存储信息,可以通过base64 --decode解码获得原始数据,因此安全性弱。
-
kubernetes.io/dockerconfigjson:用于存储docker registry的认证信息
-
9.3.1创建方式:
1.用文件的形式进行创建:
echo -n timinglee > username.txt
echo -n lee > password.txt
kubectl create secret generic user --from-file username.txt --from-file password.txt
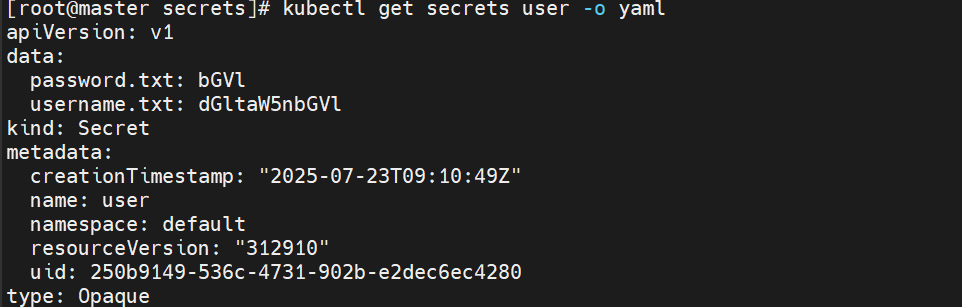
9.3.2编写yaml文件
![]() #必须使用base64进行加密
#必须使用base64进行加密
vi user.yaml
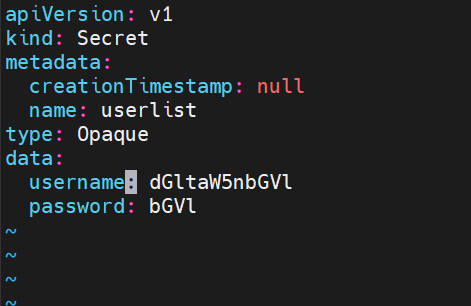
kubectl apply -f user.yaml
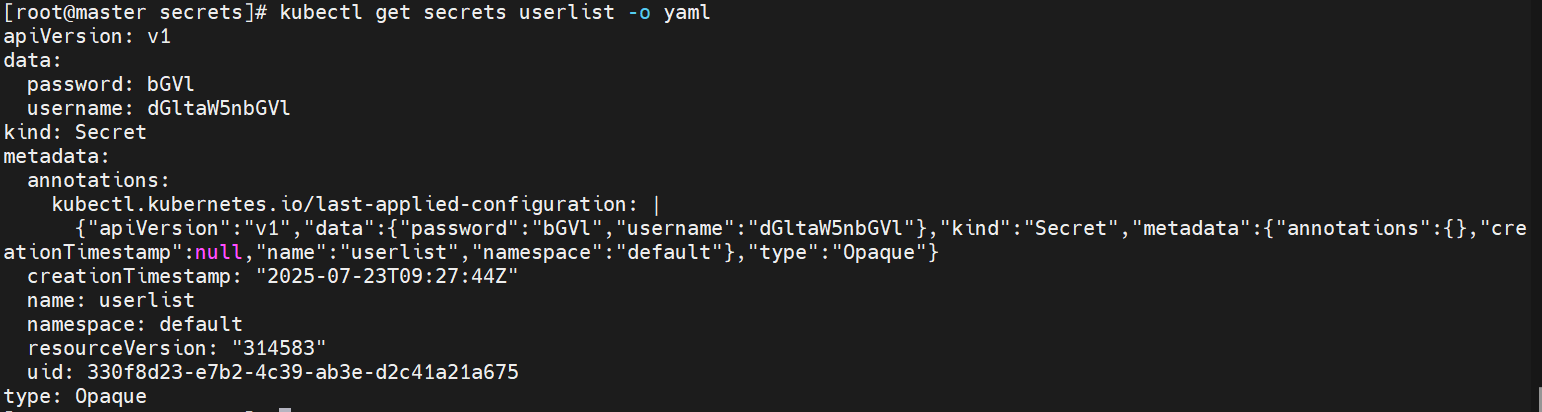 9.3.2secret使用方式
9.3.2secret使用方式
1.将secret挂载到volume目录中
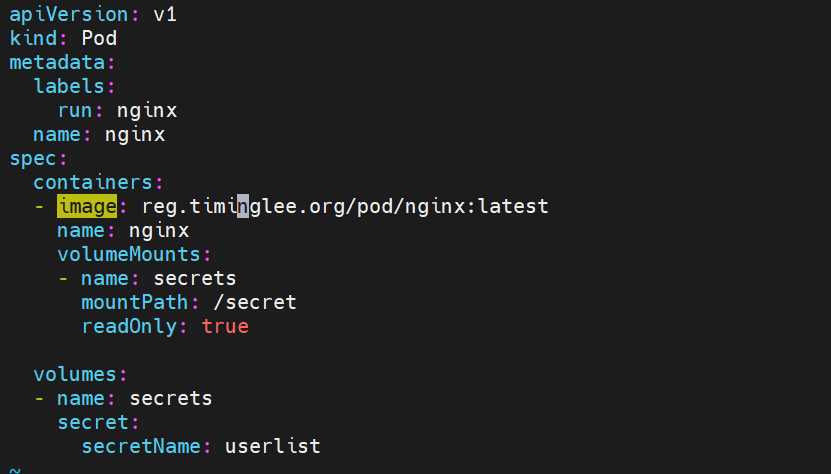
进入容器内部验证一下是否挂载上去

成功
9.3.3向指定路径映射secret密钥
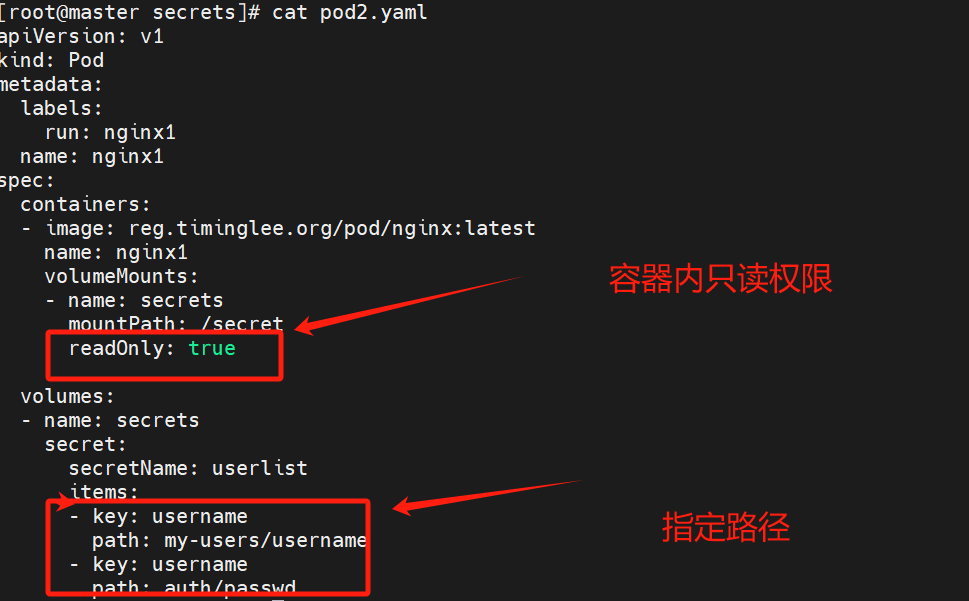
进入容器内部查看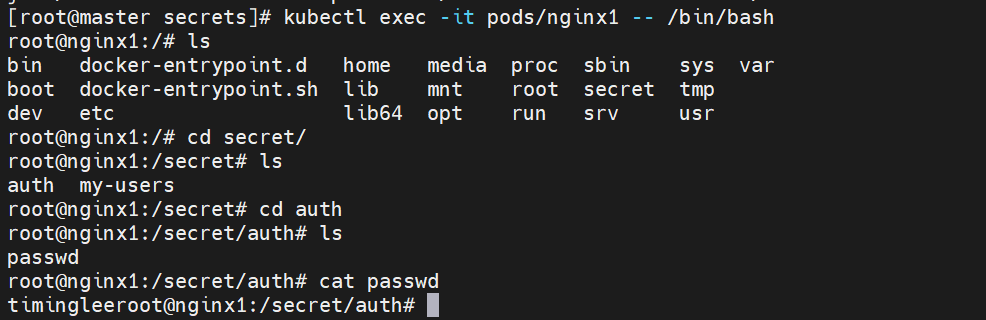
9.3.4将secret设置为环境变量
vi pod3.yaml
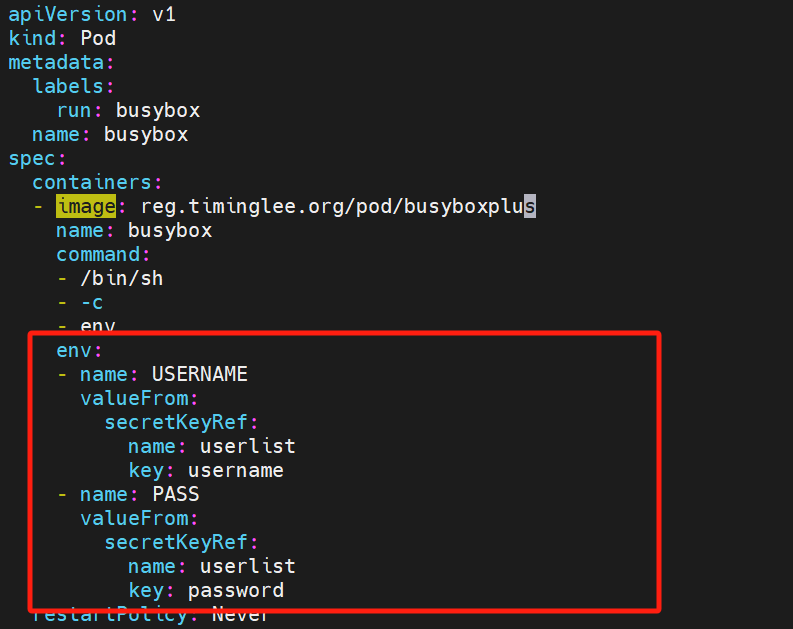
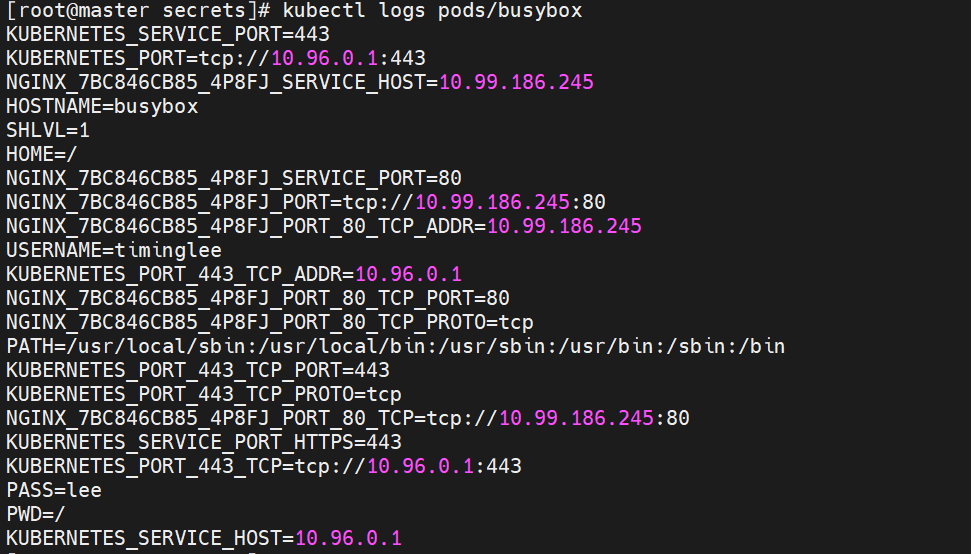
9.3.5做docker认证信息
harbor仓库中有些私有镜像必须做认证才能拉取到本地
集群中
首先 建立用于 docker 的secret

编写yaml文件
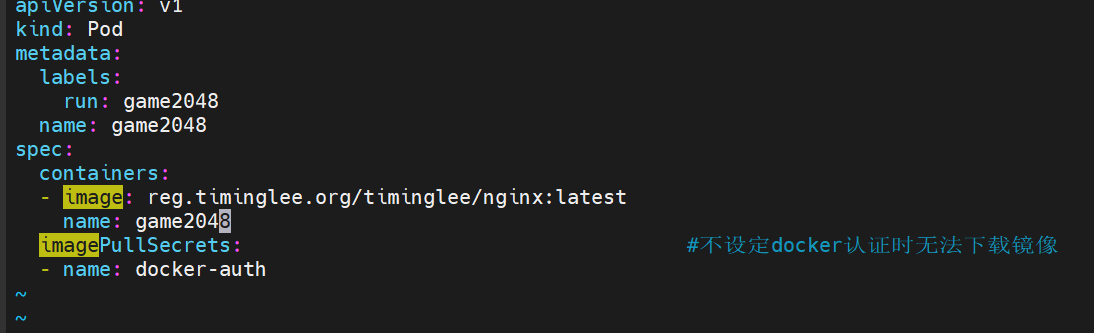
查看pod成功运行建立
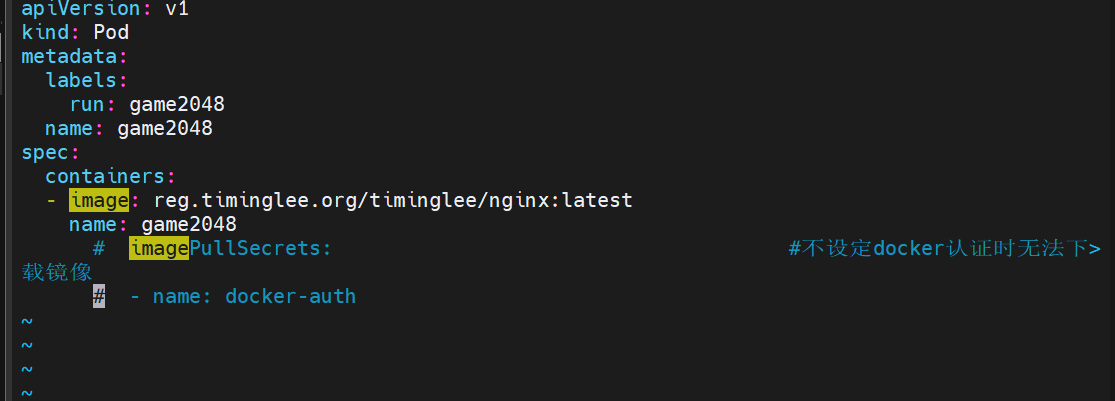
当不设定imagepullsecrets的时候 下载失败

9.4volumes配置
-
容器中文件在磁盘上是临时存放的,这给容器中运行的特殊应用程序带来一些问题
-
当容器崩溃时,kubelet将重新启动容器,容器中的文件将会丢失,因为容器会以干净的状态重建。
-
当在一个 Pod 中同时运行多个容器时,常常需要在这些容器之间共享文件。
-
Kubernetes 卷具有明确的生命周期与使用它的 Pod 相同
-
卷比 Pod 中运行的任何容器的存活期都长,在容器重新启动时数据也会得到保留
-
当一个 Pod 不再存在时,卷也将不再存在。
-
Kubernetes 可以支持许多类型的卷,Pod 也能同时使用任意数量的卷。
-
卷不能挂载到其他卷,也不能与其他卷有硬链接。 Pod 中的每个容器必须独立地指定每个卷的挂载位置
9.4.1emptyDir卷
功能:
当Pod指定到某个节点上时,首先创建的是一个emptyDir卷,并且只要 Pod 在该节点上运行,卷就一直存在。卷最初是空的。 尽管 Pod 中的容器挂载 emptyDir 卷的路径可能相同也可能不同,但是这些容器都可以读写 emptyDir 卷中相同的文件。 当 Pod 因为某些原因被从节点上删除时,emptyDir 卷中的数据也会永久删除
emptyDir 的使用场景:
-
缓存空间,例如基于磁盘的归并排序。
-
耗时较长的计算任务提供检查点,以便任务能方便地从崩溃前状态恢复执行。
-
在 Web 服务器容器服务数据时,保存内容管理器容器获取的文件
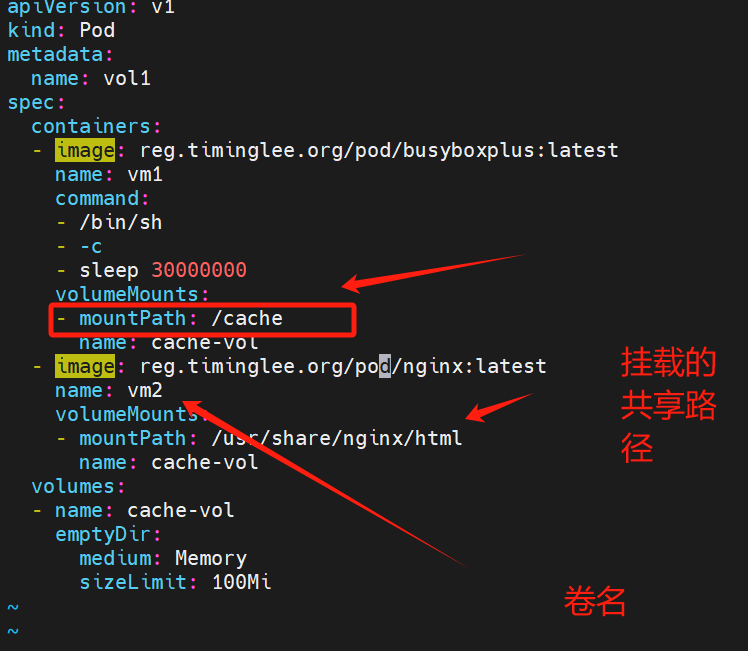
一个pod容器运行了俩个镜像 nginx和busyboxplus 共享的是同一个网络 挂载了卷 共享卷里的数据
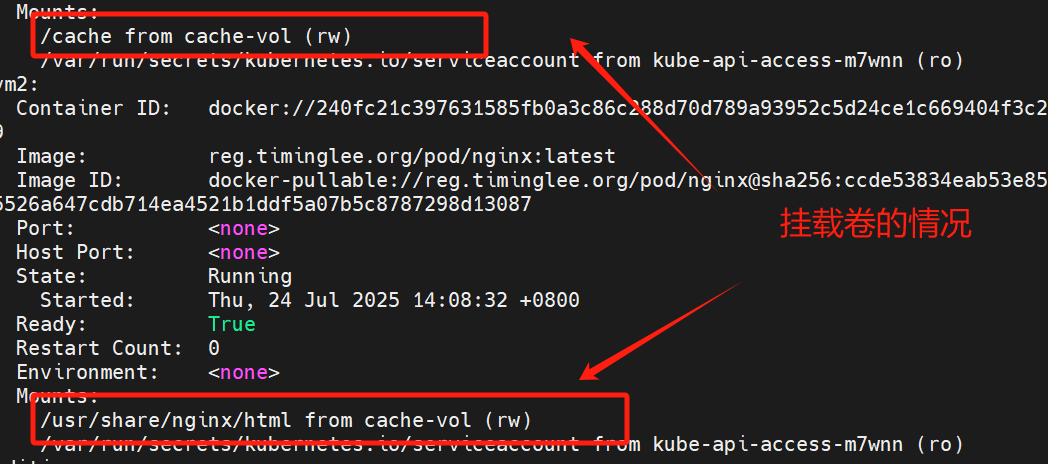
测试效果:
在busyboxplus中:
kubectl exec -it pods/voll -c vm1 -- /bin/sh
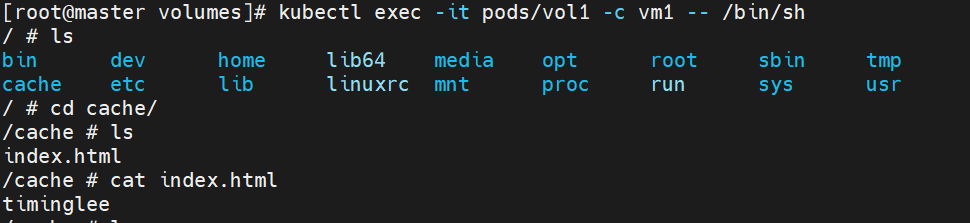
由于一个pod 里的容器共享网络栈 所以 在cache 中写入index .html文件中的 timignlee curl localhost 出的结果是nginx中默认发布目录中写入的东西 这就是挂载共享卷。
9.4.2hostpath卷
hostPath 卷能将主机节点文件系统上的文件或目录挂载到您的 Pod 中,不会因为pod关闭而被删除
-
运行一个需要访问 Docker 引擎内部机制的容器,挂载 /var/lib/docker 路径。
-
在容器中运行 cAdvisor(监控) 时,以 hostPath 方式挂载 /sys。
-
允许 Pod 指定给定的 hostPath 在运行 Pod 之前是否应该存在,是否应该创建以及应该以什么方式存在
hostPath的安全隐患
-
具有相同配置(例如从 podTemplate 创建)的多个 Pod 会由于节点上文件的不同而在不同节点上有不同的行为。
-
当 Kubernetes 按照计划添加资源感知的调度时,这类调度机制将无法考虑由 hostPath 使用的资源。
-
基础主机上创建的文件或目录只能由 root 用户写入。您需要在 特权容器 中以 root 身份运行进程,或者修改主机上的文件权限以便容器能够写入 hostPath 卷。
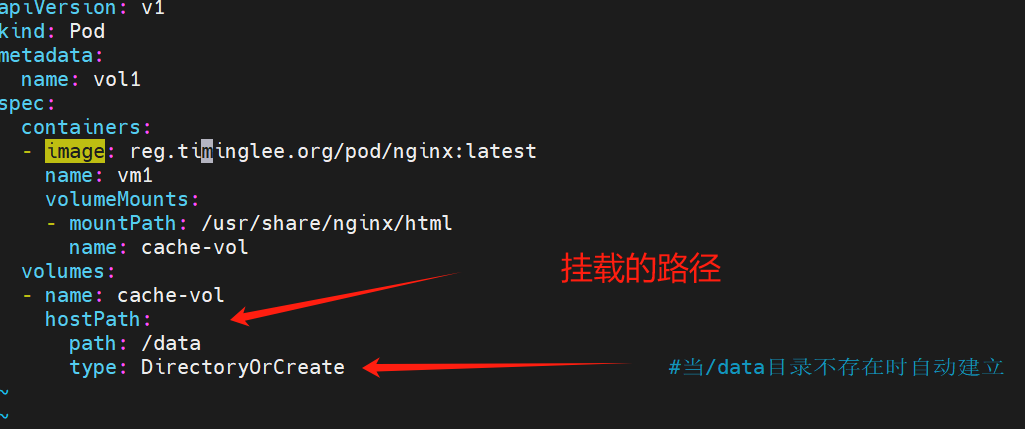

node 2 本来没有 /data/是由参数 type 指定的 没有的时候就创建
查看pod状态 pod此刻是运行起来的 并且允许在node2 所以挂载的路径为 node2 上的/data/

在node2写入内容
master访问 curl 10.244.2.71 输出的是hello 是/data/下写入的内容
删除这个pod之后 /data/下的内容 还是存在 所以实现了数据持久化存储
9.4.3nfs卷
NFS 卷允许将一个现有的 NFS 服务器上的目录挂载到 Kubernetes 中的 Pod 中。这对于在多个 Pod 之间共享数据或持久化存储数据非常有用
例如,如果有多个容器需要访问相同的数据集,或者需要将容器中的数据持久保存到外部存储,NFS 卷可以提供一种方便的解决方案。
也是实现存储隔离的方式
所以节点全部部署 一台是nfs服务器 其他i相当于nfs客户端
dnf install nfs-utils -y
systemctl enable --now nfs-server.service
vim /etc/exports
/nfsdata *(rw,sync,no_root_squash)
[root@reg ~]# f's
exporting *:/nfsdata
showmount -e 172.25.254.200 #nfs服务器
部署nfs卷
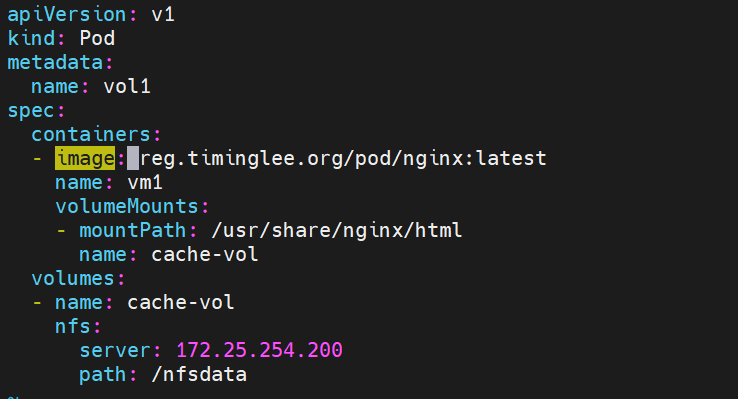
指明 nfs服务器IP地址 和共享目录 然后创建


然后在nfs 服务器
echo hello > index.html
curl 10.244.2.61
hello
运行在node2上 实际该数据就存储到了node2上 也实现了存储隔离
9.5persistentvolume持久卷
静态持久卷pv和静态持久卷声明pvc
volumes访问模式
-
ReadWriteOnce -- 该volume只能被单个节点以读写的方式映射
-
ReadOnlyMany -- 该volume可以被多个节点以只读方式映射
-
ReadWriteMany -- 该volume可以被多个节点以读写的方式映射
volumes回收策略
-
Retain:保留,需要手动回收
-
Recycle:回收,自动删除卷中数据(在当前版本中已经废弃)
-
Delete:删除,相关联的存储资产,如AWS EBS,GCE PD,Azure Disk,or OpenStack Cinder卷都会被删除
pv
-
pv是集群内由管理员提供的网络存储的一部分。
-
PV也是集群中的一种资源。是一种volume插件,
-
但是它的生命周期却是和使用它的Pod相互独立的。
-
PV这个API对象,捕获了诸如NFS、ISCSI、或其他云存储系统的实现细节
-
pv有两种提供方式:静态和动态
-
静态PV:集群管理员创建多个PV,它们携带着真实存储的详细信息,它们存在于Kubernetes API中,并可用于存储使用
-
动态PV:当管理员创建的静态PV都不匹配用户的PVC时,集群可能会尝试专门地供给volume给PVC。这种供给基于StorageClass
-
pvc
-
是用户的一种存储请求
-
它和Pod类似,Pod消耗Node资源,而PVC消耗PV资源
-
Pod能够请求特定的资源(如CPU和内存)。PVC能够请求指定的大小和访问的模式持久卷配置
-
PVC与PV的绑定是一对一的映射。没找到匹配的PV,那么PVC会无限期得处于unbound未绑定状态
pv相当于仓库 pvc相当于用户的请求 我想要用您pv多少空间 而pod 就是在配置中引用pvc 就能实际使用这个存储空间
vim pv.yaml 先创建pv空间
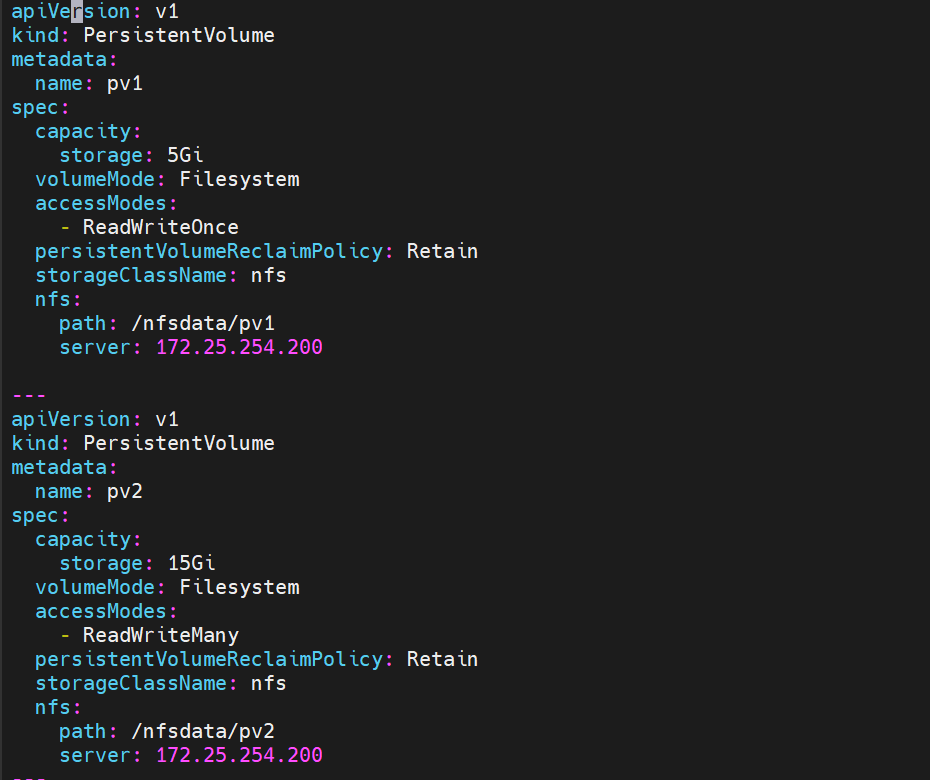
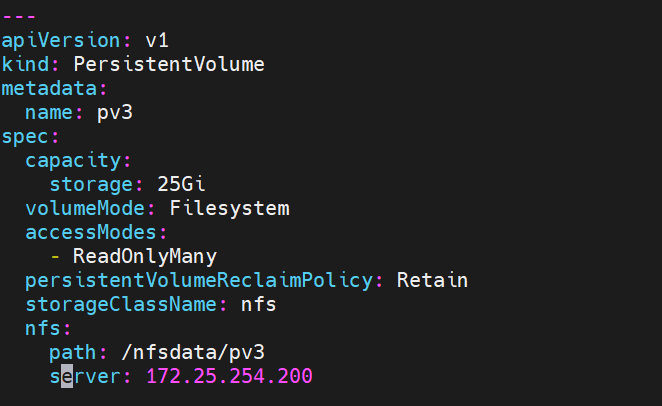
path 路径 就相当于 存储路径在172.25.254.200:/nfsdata/pv下
storage为pv卷的内存大小 volumeMode为文件系统类型
pvc: pvc1.yaml
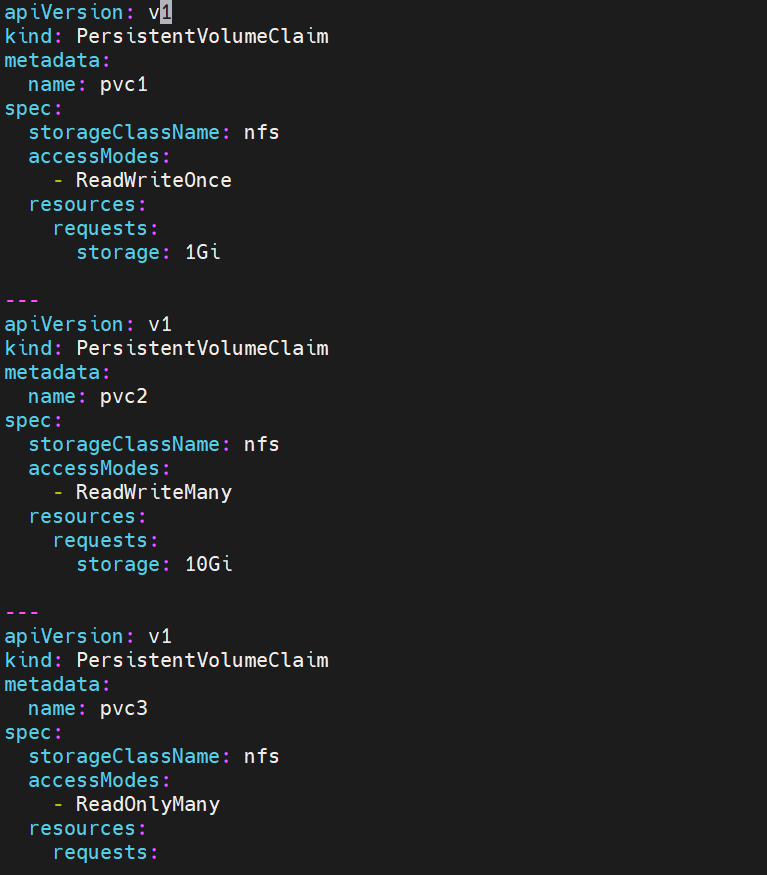
pv和pvc需要吻合 才能使用
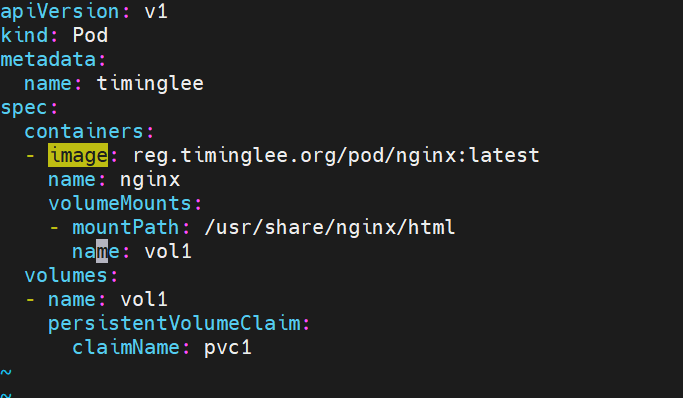
pod实例: 创建一个pod 用的是pvc1 的空间 挂载的路径

在 172.25.254.200 pv1/index.html 路径下写入内容

![]()
访问到写入内容 删除pod 后 内容还在 实现了存储持久化
9.6存储类
storageclass 动态创建 动态收缩
9.7stateful控制器
-
tatefulset是为了管理有状态服务的问提设计的
-
StatefulSet将应用状态抽象成了两种情况:
-
拓扑状态:应用实例必须按照某种顺序启动。新创建的Pod必须和原来Pod的网络标识一样
-
存储状态:应用的多个实例分别绑定了不同存储数据。
-
StatefulSet给所有的Pod进行了编号,编号规则是:$(statefulset名称)-$(序号),从0开始。
-
Pod被删除后重建,重建Pod的网络标识也不会改变,Pod的拓扑状态按照Pod的“名字+编号”的方式固定下来,并且为每个Pod提供了一个固定且唯一的访问入口,Pod对应的DNS记录。
statefulset 组成部分:
-
Headless Service:用来定义pod网络标识,生成可解析的DNS记录
-
volumeClaimTemplates:创建pvc,指定pvc名称大小,自动创建pvc且pvc由存储类供应。
-
StatefulSet:管理pod的
#建立无头服务 (cluster不自动分配ip 直接通过本地 dns解析到pod
[root@k8s-master statefulset]# vim headless.yml
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
[root@k8s-master statefulset]# kubectl apply -f headless.yml
#建立statefulset
[root@k8s-master statefulset]# vim statefulset.yml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx-svc"
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
volumeMounts:
- name: www
ku
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
storageClassName: nfs-client
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
[root@k8s-master statefulset]# kubectl apply -f statefulset.yml
statefulset.apps/web configured
root@k8s-master statefulset]# kubectl get pods
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 3m26s
web-1 1/1 Running 0 3m22s
web-2 1/1 Running 0 3m18s
[root@reg nfsdata]# ls /nfsdata/
default-test-claim-pvc-34b3d968-6c2b-42f9-bbc3-d7a7a02dcbac
default-www-web-0-pvc-0390b736-477b-4263-9373-a53d20cc8f9f
default-www-web-1-pvc-a5ff1a7b-fea5-4e77-afd4-cdccedbc278c
default-www-web-2-pvc-83eff88b-4ae1-4a8a-b042-8899677ae854
#为每个pod建立index.html文件
[root@reg nfsdata]# echo web-0 > default-www-web-0-pvc-0390b736-477b-4263-9373-a53d20cc8f9f/index.html
[root@reg nfsdata]# echo web-1 > default-www-web-1-pvc-a5ff1a7b-fea5-4e77-afd4-cdccedbc278c/index.html
[root@reg nfsdata]# echo web-2 > default-www-web-2-pvc-83eff88b-4ae1-4a8a-b042-8899677ae854/index.html
#建立测试pod访问web-0~2
[root@k8s-master statefulset]# kubectl run -it testpod --image busyboxplus
/ # curl web-0.nginx-svc
web-0
/ # curl web-1.nginx-svc
web-1
/ # curl web-2.nginx-svc
web-2
#删掉重新建立statefulset
[root@k8s-master statefulset]# kubectl delete -f statefulset.yml
statefulset.apps "web" deleted
[root@k8s-master statefulset]# kubectl apply -f statefulset.yml
statefulset.apps/web created
#访问依然不变
[root@k8s-master statefulset]# kubectl attach testpod -c testpod -i -t
If you don't see a command prompt, try pressing enter.
/ # cu
curl cut
/ # curl web-0.nginx-svc
web-0
/ # curl web-1.nginx-svc
web-1
/ # curl web-2.nginx-svc
web-2
10.k8s通信
10.1通信整体架构
1.flannel
-
k8s通过CNI接口接入其他插件来实现网络通讯。目前比较流行的插件有flannel,calico等
-
CNI插件存放位置:# cat /etc/cni/net.d/10-flannel.conflist
-
插件使用的解决方案如下
-
虚拟网桥,虚拟网卡,多个容器共用一个虚拟网卡进行通信。
-
多路复用:MacVLAN,多个容器共用一个物理网卡进行通信。
-
硬件交换:SR-LOV,一个物理网卡可以虚拟出多个接口,这个性能最好。
-
-
容器间通信:
-
同一个pod内的多个容器间的通信,通过lo即可实现pod之间的通信
-
同一节点的pod之间通过cni网桥转发数据包。
-
不同节点的pod之间的通信需要网络插件支持
-
-
pod和service通信: 通过iptables或ipvs实现通信,ipvs取代不了iptables,因为ipvs只能做负载均衡,而做不了nat转换
-
pod和外网通信:iptables的MASQUERADE
-
Service与集群外部客户端的通信;(ingress、nodeport、loadbalancer)
同一节点容器内部通信 通过本地的网络插件产生的回环地址 进行通信
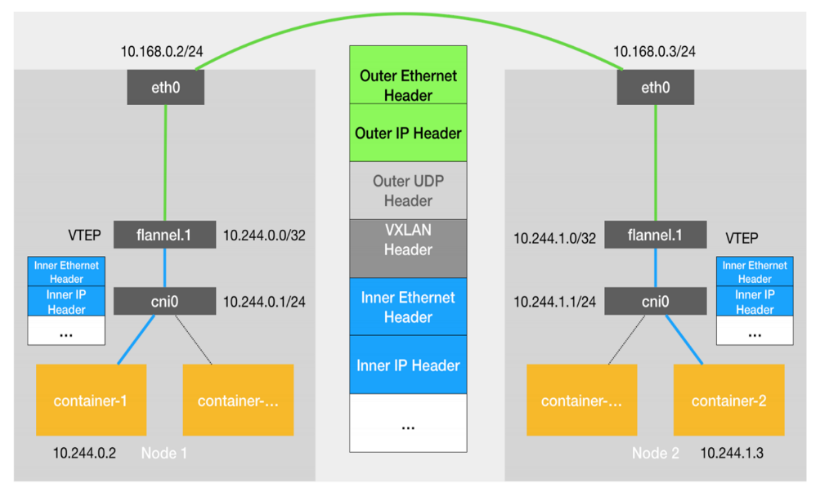
不同节点容器之间的访问:容器container找到 cni(网络接口)然后 通过CNI找到接入的网络插件 flannel flannel通过 VXLAN插件通过对端mac地址然后找到另一个节点上的flannel插件(实际是通过本地网卡eth0 通过arp广播协议 找到 另一个节点eth0到达的)eth0 找到flannel flannel插件通过CNI找到 container从而实现通信 。
2.calino
纯三层转发 中间没有任何NAT和overlay,转发效率最好
calino适配性高 依赖少
-
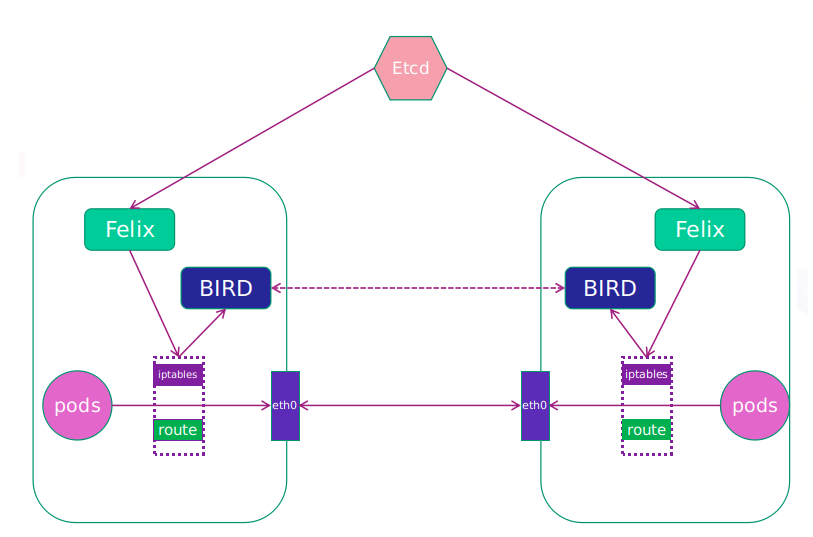
Felix:监听ECTD中心的存储获取事件,用户创建pod后,Felix负责将其网卡、IP、MAC都设置好,然后在内核的路由表里面写一条,注明这个IP应该到这张网卡。同样如果用户制定了隔离策略,Felix同样会将该策略创建到ACL中,以实现隔离。
-
BIRD:一个标准的路由程序,它会从内核里面获取哪一些IP的路由发生了变化,然后通过标准BGP的路由协议扩散到整个其他的宿主机上,让外界都知道这个IP在这里,路由的时候到这里
直接通过 eth0进行访问 本地calino插件中的 BIRD通过arp广播找到其他节点eth0 从而实现通信
calico网络插件部署:
如果提前部署了flannel插件的话需要删除
r m -rf /etc/cni/net.d/*
下载calino插件到本地 并且上传到本地镜像仓库

下载calino.yaml到本地 并且做修改:
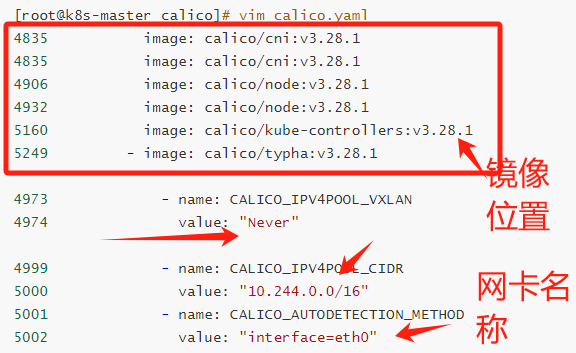
kubectl apply -f calico.yaml
查看运行状态为 running
10.2k8s的调度
-
调度是指将未调度的Pod自动分配到集群中的节点的过程
-
调度器通过 kubernetes 的 watch 机制来发现集群中新创建且尚未被调度到 Node 上的 Pod
-
调度器会将发现的每一个未调度的 Pod 调度到一个合适的 Node 上来运行
调度原理:
-
创建Pod
-
用户通过Kubernetes API创建Pod对象,并在其中指定Pod的资源需求、容器镜像等信息。
-
-
调度器监视Pod
-
Kubernetes调度器监视集群中的未调度Pod对象,并为其选择最佳的节点。
-
-
选择节点
-
调度器通过算法选择最佳的节点,并将Pod绑定到该节点上。调度器选择节点的依据包括节点的资源使用情况、Pod的资源需求、亲和性和反亲和性等。
-
-
绑定Pod到节点
-
调度器将Pod和节点之间的绑定信息保存在etcd数据库中,以便节点可以获取Pod的调度信息。
-
-
节点启动Pod
-
节点定期检查etcd数据库中的Pod调度信息,并启动相应的Pod。如果节点故障或资源不足,调度器会重新调度Pod,并将其绑定到其他节点上运行。
-
调度器种类:
-
默认调度器(Default Scheduler):
-
是Kubernetes中的默认调度器,负责对新创建的Pod进行调度,并将Pod调度到合适的节点上。
-
-
自定义调度器(Custom Scheduler):
-
是一种自定义的调度器实现,可以根据实际需求来定义调度策略和规则,以实现更灵活和多样化的调度功能。
-
-
扩展调度器(Extended Scheduler):
-
是一种支持调度器扩展器的调度器实现,可以通过调度器扩展器来添加自定义的调度规则和策略,以实现更灵活和多样化的调度功能。
-
-
kube-scheduler是kubernetes中的默认调度器,在kubernetes运行后会自动在控制节点运行
常用的调度方法:
1.nodename:
-
nodeName 是节点选择约束的最简单方法,但一般不推荐
-
如果 nodeName 在 PodSpec 中指定了,则它优先于其他的节点选择方法
-
使用 nodeName 来选择节点的一些限制
-
如果指定的节点不存在。
-
如果指定的节点没有资源来容纳 pod,则pod 调度失败。
-
云环境中的节点名称并非总是可预测或稳定的
-
#建立pod文件
[[root@k8s-master scheduler]# kubectl run testpod --image myapp:v1 --dry-run=client -o yaml > pod1.yml
#设置调度
[root@k8s-master scheduler]# vim pod1.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: testpod
name: testpod
spec:
nodeName: k8s-node2
containers:
- image: myapp:v1
name: testpod
#建立pod
[root@k8s-master scheduler]# kubectl apply -f pod1.yml
pod/testpod created
[root@k8s-master scheduler]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
testpod 1/1 Running 0 18s 10.244.169.130 k8s-node2 <none> <none>
nodeName: k8s3 #找不到节点pod会出现pending,优先级最高,其他调度方式无效5
2.Nodeselectot(通过标签控制节点)
nodeSelector 是节点选择约束的最简单推荐形式
给选择的节点添加标签:
kubectl label nodes node1 lab=lee #设置node1的label为lee
可以给多个节点设定相同标签
查看 node1label已经设置为lee

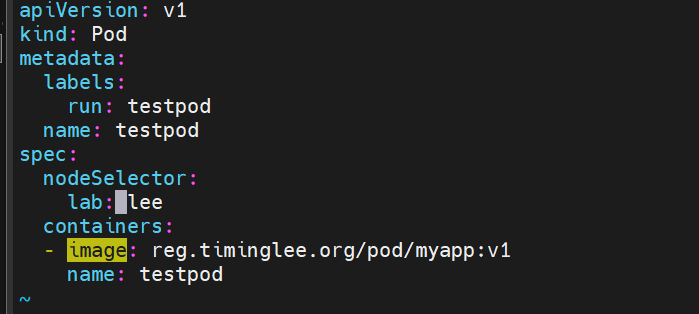 yaml中 指定nodeselector调度标签为lee 所以该pod调度到node1上
yaml中 指定nodeselector调度标签为lee 所以该pod调度到node1上

亲和性(affinity):
-
nodeSelector 提供了一种非常简单的方法来将 pod 约束到具有特定标签的节点上。亲和/反亲和功能极大地扩展了你可以表达约束的类型。
-
使用节点上的 pod 的标签来约束,而不是使用节点本身的标签,来允许哪些 pod 可以或者不可以被放置在一起。
nodeAffinity节点亲和:
-
那个节点服务指定条件就在那个节点运行
-
requiredDuringSchedulingIgnoredDuringExecution 必须满足,但不会影响已经调度(在调度 Pod 时必须满足此规则,但在 Pod 运行期间如果节点标签发生变化,不会影响 Pod 的运行)
-
preferredDuringSchedulingIgnoredDuringExecution 倾向满足,在无法满足情况下也会调度pod
-
IgnoreDuringExecution 表示如果在Pod运行期间Node的标签发生变化,导致亲和性策略不能满足,则继续运行当前的Pod。
-
-
nodeaffinity还支持多种规则匹配条件的配置如
| 匹配规则 | 功能 |
|---|---|
| ln | label 的值在列表内 |
| Notln | label 的值不在列表内 |
| Gt | label 的值大于设置的值,不支持Pod亲和性 |
| Lt | label 的值小于设置的值,不支持pod亲和性 |
| Exists | 设置的label 存在 |
| DoesNotExist | 设置的 label 不存在 |
kubectl label nodes node1 gpu=hxd #自定义键值对标签 随便设置
pod如下 :
affinity下的nodeAffinity亲和性配置
“requiredDuringSchedulingIgnoredDuringExecution”:这是一种节点亲和性规则,意思是在调度 Pod 时必须满足此规则,但在 Pod 运行期间如果节点标签发生变化,不会影响 Pod 的运行。
nodeSelectorTerms” 数组:包含节点选择器条件
“matchExpressions” 数组:具体的匹配表达式。
key为匹配的标签键为gpu
“operator: In | NotIn”:操作符为 In(表示节点标签值在给定列表中)或 NotIn(表示节点标签值不在给定列表中),注释说明这两个操作符结果相反
values” 数组:
-
“- hxd”:如果操作符是 In,意味着节点标签 disk 的值为 ssd 的节点才符合调度要求;如果是 NotIn,则表示节点标签 disk 的值不为 hxd 的节点才符合调度要求。
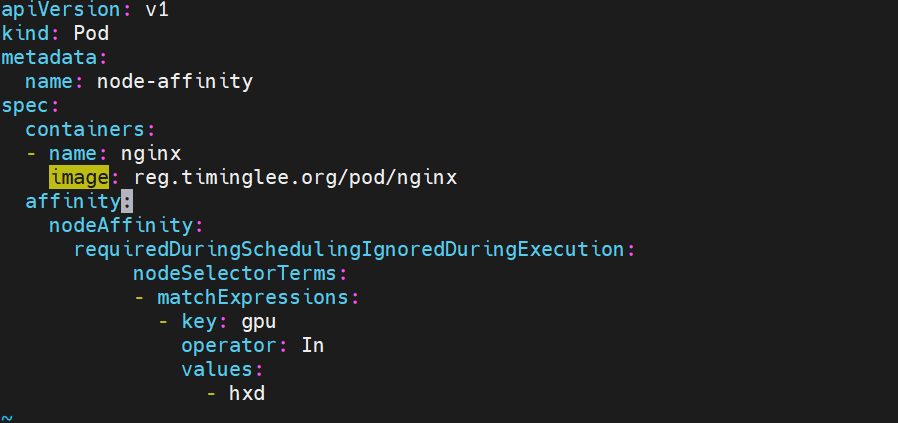

如图调度到node1上面

Podaffinity(pod)的亲和
-
那个节点有符合条件的POD就在那个节点运行
-
podAffinity 主要解决POD可以和哪些POD部署在同一个节点中的问题
-
podAntiAffinity主要解决POD不能和哪些POD部署在同一个节点中的问题。它们处理的是Kubernetes集群内部POD和POD之间的关系。
-
Pod 间亲和与反亲和在与更高级别的集合(例如 ReplicaSets,StatefulSets,Deployments 等)一起使用时,Pod 间亲和与反亲和需要大量的处理,这可能会显著减慢大规模集群中的调度。

亲和性参数为podAffinity
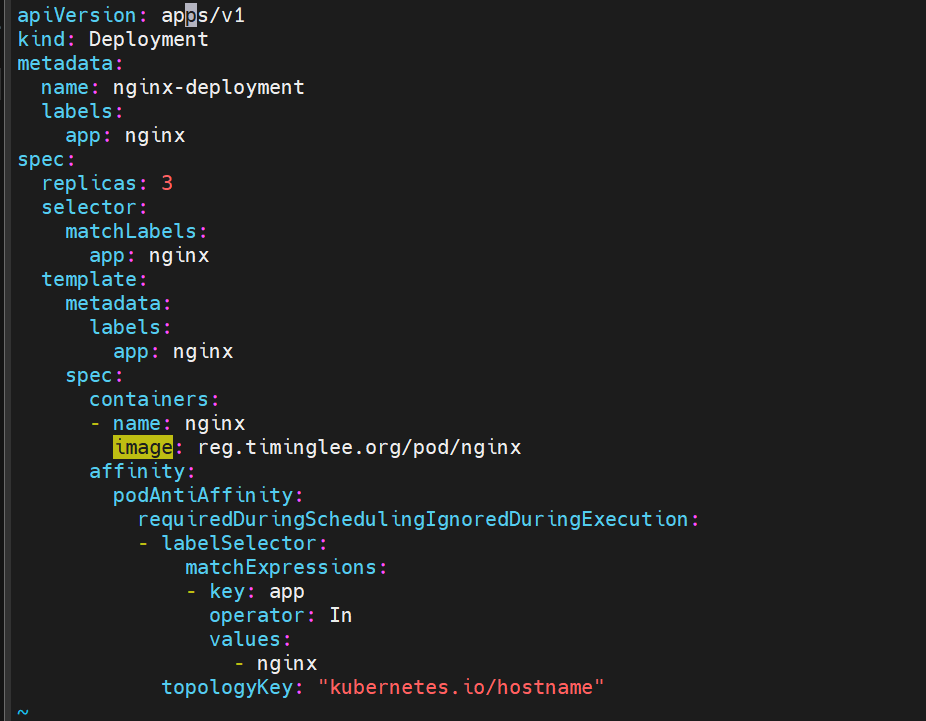
设置了节点亲和性 都在一个节点上运行 3个pod
匹配的键为
topologyKey 为拓扑标签 节点上有这个标签才能被调度过去
pod的反亲和:
podAniAffinity参数

一个节点调度到一个pod 俩个节点各有一个 多余的pod 显示pending状态。
Taints污点:
| effect值 | 解释 |
|---|---|
| NoSchedule | POD 不会被调度到标记为 taints 节点 |
| PreferNoSchedule | NoSchedule 的软策略版本,尽量不调度到此节点 |
| NoExecute | 如该节点内正在运行的 POD 没有对应 Tolerate 设置,会直接被逐出 |
给某个节点打上污点以后,该节点无法调度到pods
kubectl describe nodes node1 | grep Taints #查看某个节点是否打上污点
kubectl taint nodes node1 key=string:NoSchedule 给node1节点打上 不调度的污点‘
kubectl taint node node1 key- #删除该节点污点
kubectl get nodes k8s-node1 -o json | jq '.spec.taints' #查询多个污点
创建一个pod
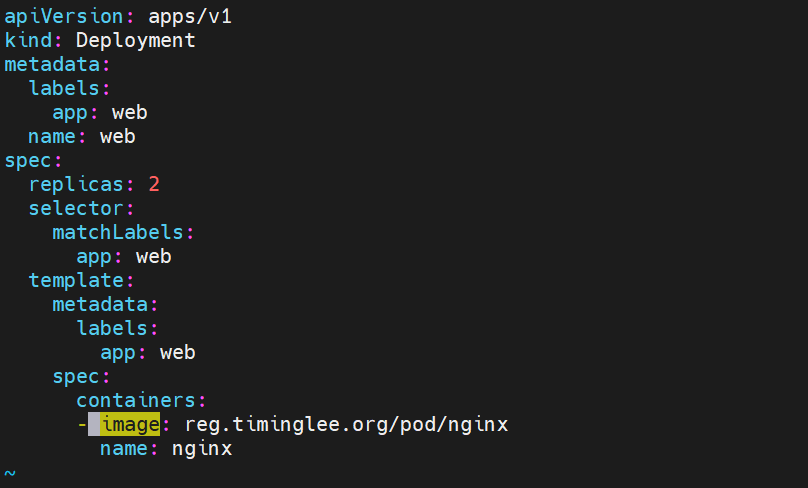

全部运行在node2上面
kubectl scale deployment web --replicas=6 增加pod数量 查看 也是全部调度到node2上 这就是node1 taints:NoSchedule的作用

污点容忍:
运行pod 定义污点容忍为
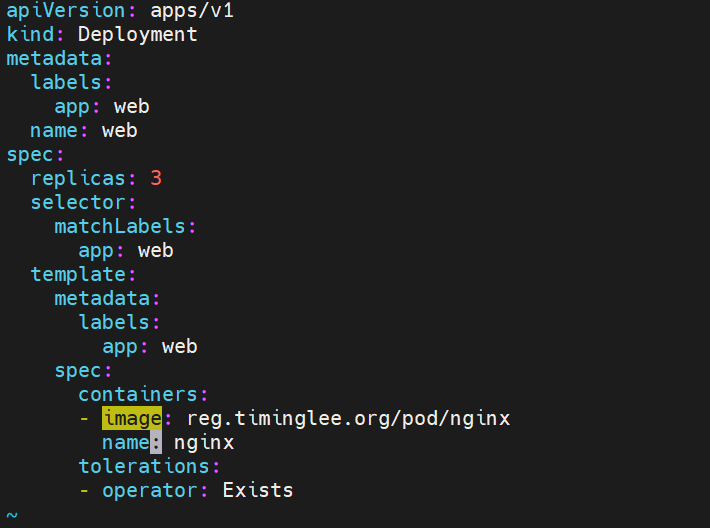

以上为容忍所有污点
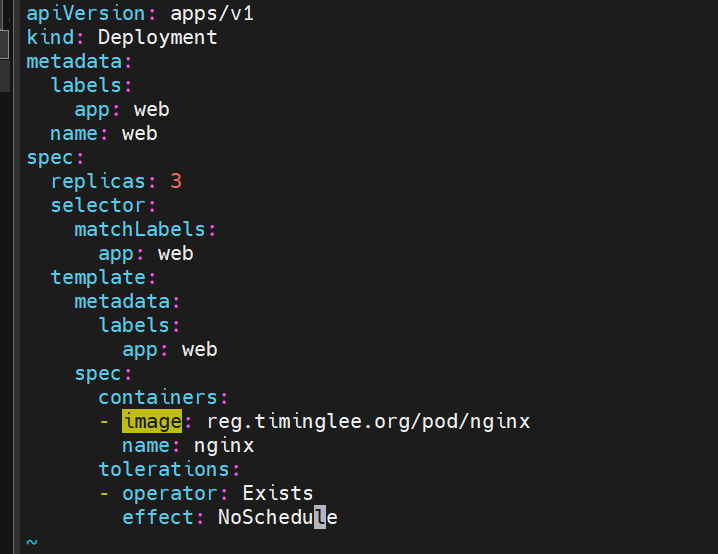
容忍 NoSchedule的污点
给 node2 添加一个污点 kubectl taint nodes node2 name=lee:PreferNoSchedule

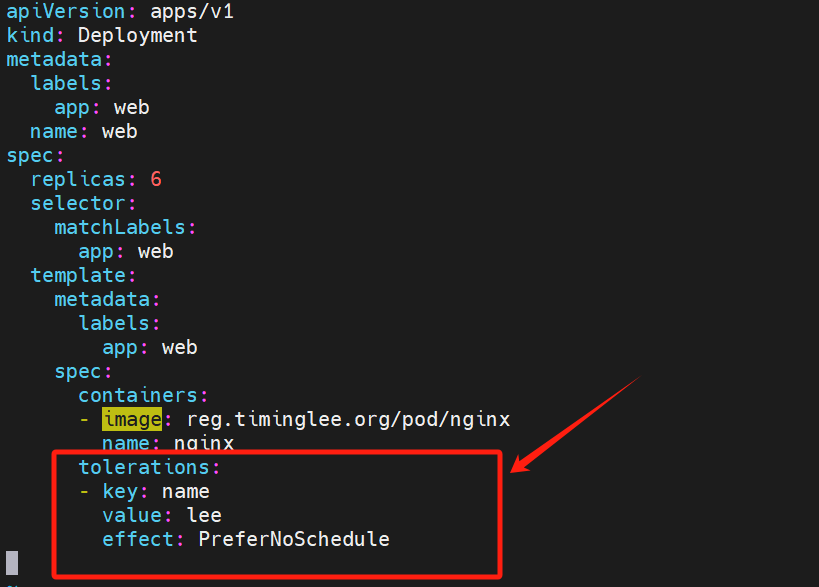
添加这个tolerations 表示 对该打上该污点的节点进行容忍
查看pod运行位置 没有node2

11.k8s中api访问控制
Authentication(认证)
-
认证方式现共有8种,可以启用一种或多种认证方式,只要有一种认证方式通过,就不再进行其它方式的认证。通常启用X509 Client Certs和Service Accout Tokens两种认证方式。
-
Kubernetes集群有两类用户:由Kubernetes管理的Service Accounts (服务账户)和(Users Accounts) 普通账户。k8s中账号的概念不是我们理解的账号,它并不真的存在,它只是形式上存在。
userAccount service accounts
12.helm包管理
helm 类似于 yum源 作为k8s中软件包的管理工具
12.0.1部署helm:
[root@k8s-master helm]# tar zxf helm-v3.15.4-linux-amd64.tar.gz
[root@k8s-master helm]# ls
helm-v3.15.4-linux-amd64.tar.gz linux-amd64
[root@k8s-master helm]# cd linux-amd64/
[root@k8s-master linux-amd64]# ls
helm LICENSE README.md
[root@k8s-master linux-amd64]# cp -p helm /usr/local/bin/
#“-p” 是一个选项参数,其作用是在复制文件时,保留源文件的属性,包括文件的所有者、所属组、权限以及修改时间等。
补齐helm命令
[root@k8s-master linux-amd64]# echo "source <(helm completion bash)" >> ~/.bashrc
[root@k8s-master linux-amd64]# source ~/.bashrc
[root@k8s-master linux-amd64]# helm version
version.BuildInfo{Version:"v3.15.4", GitCommit:"fa9efb07d9d8debbb4306d72af76a383895aa8c4", GitTreeState:"clean", GoVersion:"go1.22.6"}
| 命令 | 描述 |
|---|---|
| create | 创建一个 chart 并指定名字 |
| dependency | 管理 chart 依赖 |
| get | 下载一个 release。可用子命令:all、hooks、manifest、notes、values |
| history | 获取 release 历史 |
| install | 安装一个 chart |
| list | 列出 release |
| package | 将 chart 目录打包到 chart 存档文件中 |
| pull | 从远程仓库中下载 chart 并解压到本地 # helm pull stable/mysql -- untar |
| repo | 添加,列出,移除,更新和索引 chart 仓库。可用子命令:add、index、 list、remove、update |
| rollback | 从之前版本回滚 |
| search | 根据关键字搜索 chart。可用子命令:hub、repo |
| show | 查看 chart 详细信息。可用子命令:all、chart、readme、values |
| status | 显示已命名版本的状态 |
| template | 本地呈现模板 |
| uninstall | 卸载一个 release |
| upgrade | 更新一个 release |
| version | 查看 helm 客户端版本 |
管理第三方repo源:
-
阿里云仓库:https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
-
bitnami仓库: https://charts.bitnami.com/bitnami
-
微软仓库:Index of /kubernetes/charts/
-
官方仓库: https://hub.kubeapps.com/charts/incubator
#添加阿里云仓库
[root@k8s-master helm]# helm repo add aliyun https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
"aliyun" has been added to your repositories
#添加bitnami仓库
[root@k8s-master helm]# helm repo add bitnami https://charts.bitnami.com/bitnami
"bitnami" has been added to your repositories
#查看仓库信息
[root@k8s-master helm]# helm repo list
NAME URL
aliyun https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
bitnami https://charts.bitnami.com/bitnami
#查看仓库存储helm清单
[root@k8s-master helm]# helm search repo aliyun
NAME CHART VERSION APP VERSION DESCRIPTION
#应用名称 封装版本 软件版本 软件描述
aliyun/acs-engine-autoscaler 2.1.3 2.1.1 Scales worker nodes within agent pools
aliyun/aerospike 0.1.7 v3.14.1.2 A Helm chart for Aerospike in Kubernetes
#删除第三方存储库
[root@k8s-master helm]# helm repo list
NAME URL
aliyun https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
bitnami https://charts.bitnami.com/bitnami
[root@k8s-master helm]# helm repo remove aliyun
"aliyun" has been removed from your repositories
[root@k8s-master helm]# helm repo list
NAME URL
bitnami https://charts.bitnami.com/bitnami
12.0.2 构建简单的charts项目
helm create hxd #创建一个名为hxd的charts包
tree hxd
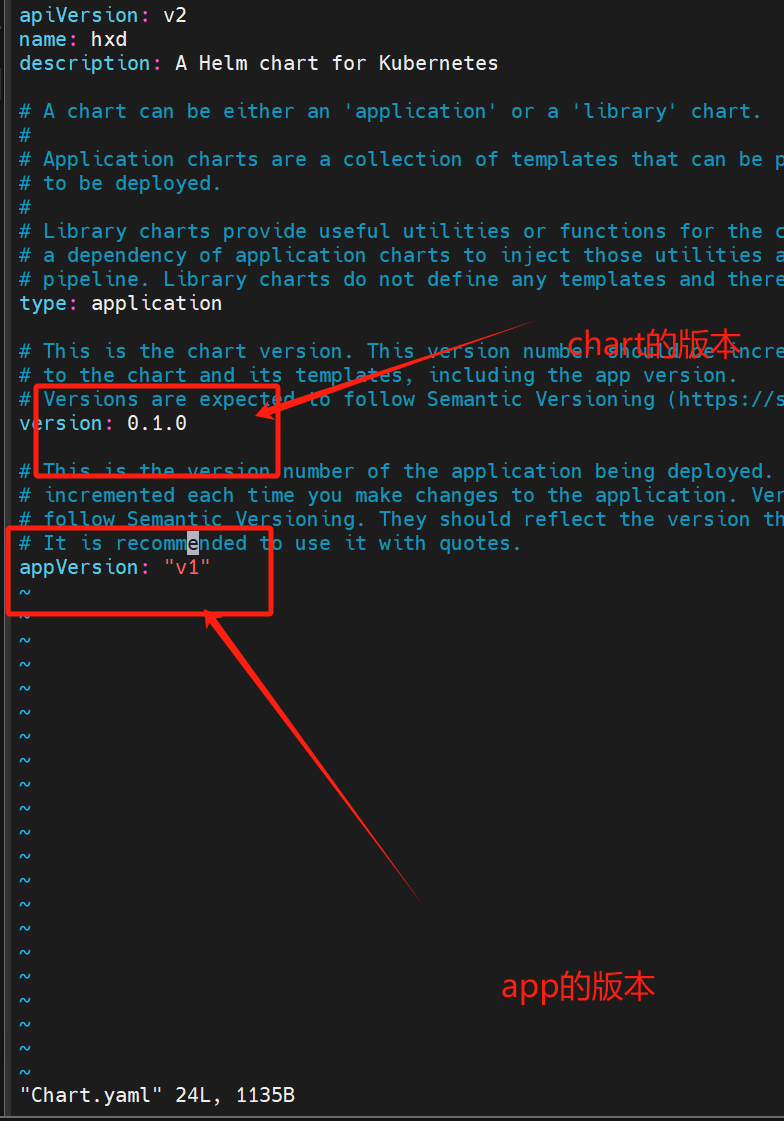
vi Charts.yaml
vi values.yaml
镜像拉取位置
服务的域名:
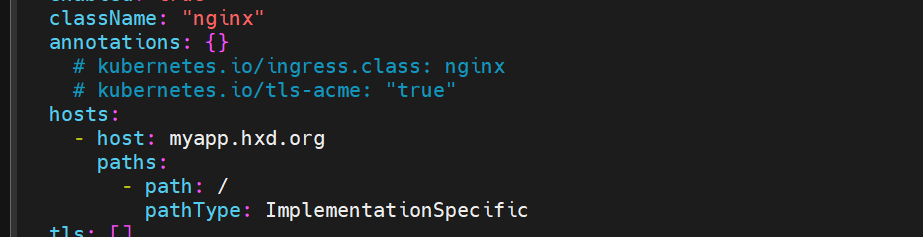
查看创建的ingress的类

需要调用才能通过ingress 实现服务的对外暴露

访问域名测试:
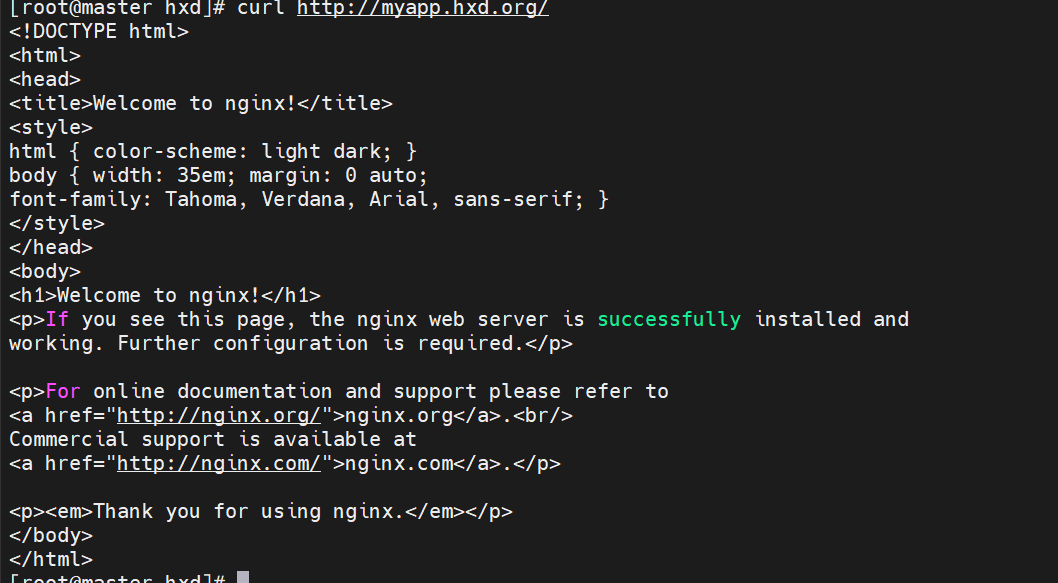
helm lint 跟路径 #检查有没有语法问题

打包# helm package hxd/
12.0.3 helm仓库
用于存放自己构建的charts项目
然后helm 本身没有上传功能 需要helm push插件支持。
在线安装一下
dnf install git -y
helm plugin install https://github.com/chartmuseum/helm-push
添加仓库:
现在harbor本地添加一个项目 项目名为 hxd
给helm 添加证书
cp /etc/docker/certs.d/certs/timinglee.org.crt /etc/pki/ca-trust/source/anchors/
update-ca-trust
添加仓库:
helm repo add hxd https://reg.timinglee.org/chartrepo/hxd

上传项目:
#命令执行格式
helm cm-push <项目名称> <仓库名称> -u admin -p lee

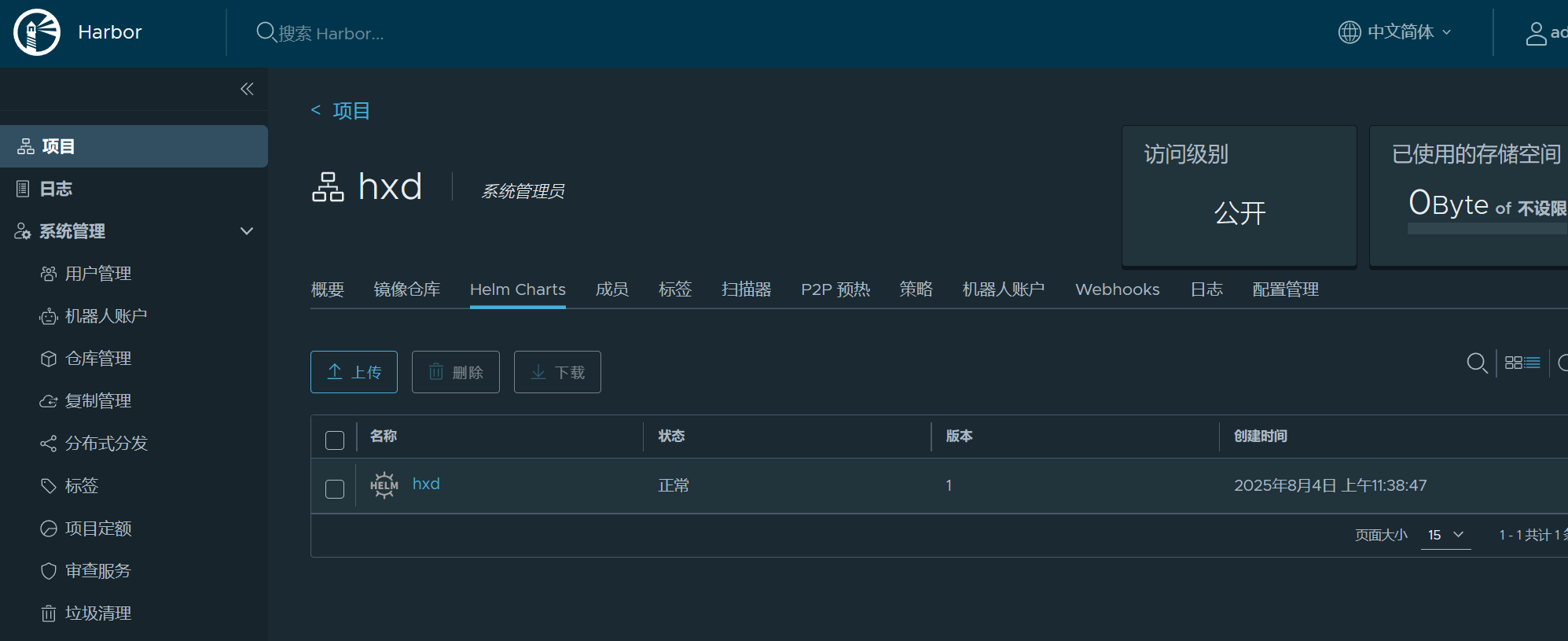
上传成功
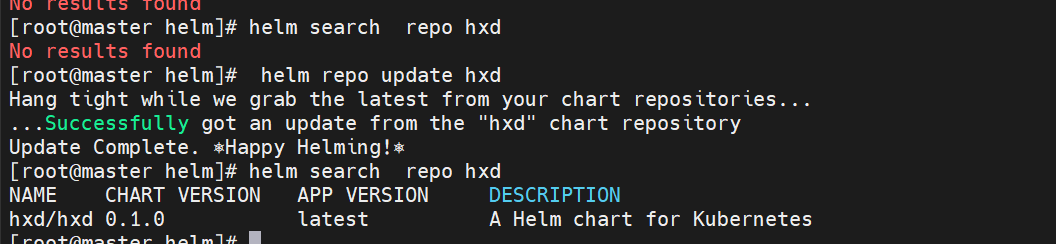
查看是否上传成功命令 需要先刷新仓库
#下载仓库里的项目
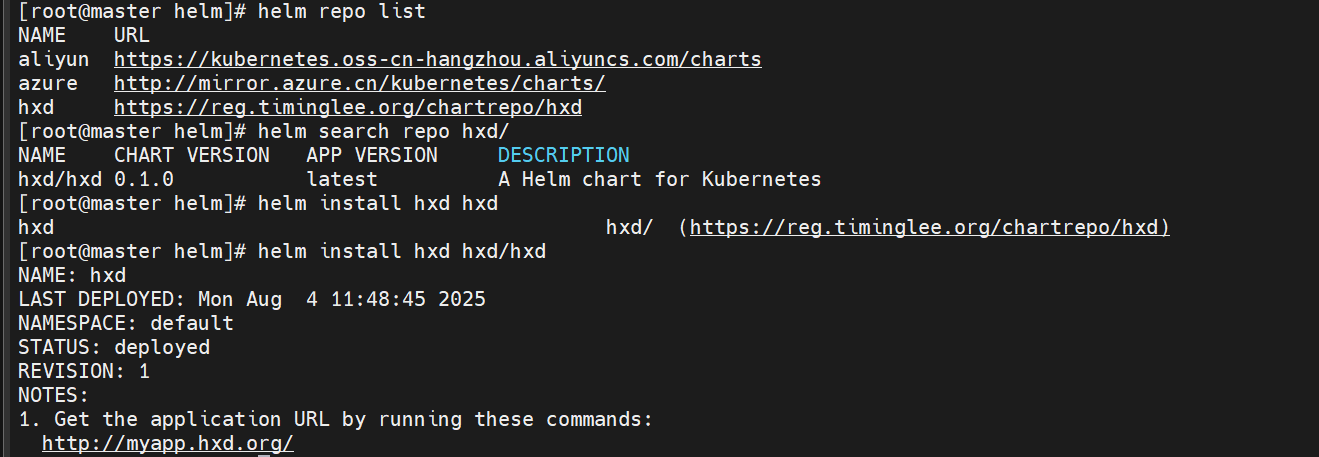
helm search repo hxd/ #查看项目
helm install 仓库名 项目名 #安装项目 可以加--version 指定版本
12.0.4 helm的版本迭代
helm search repo hxd -l #查看名为hxd的仓库中存在的charts项目
版本迭代 版本首先都需要 存在于harbor项目中

helm list -a #查看本地已经安装的软件包 #myapp版本为v1

helm upgrade myapp hxd/myapp #更新版本
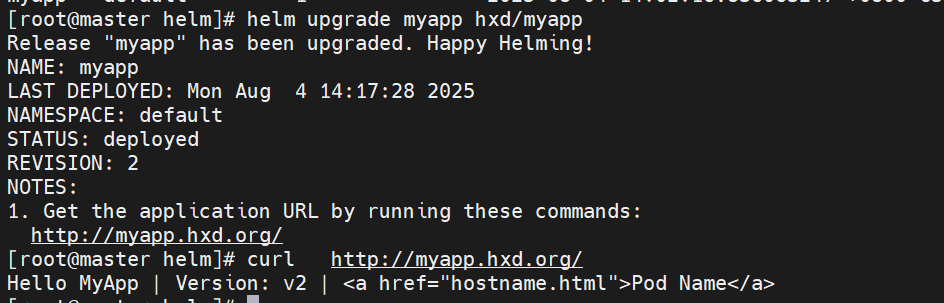
myapp已经成功更新为v2
helm rollback myapp #版本回滚
helm history myapp #查看历史版本

13.普罗米修斯
Prometheus是一个开源的服务监控系统和时序数据库
其提供了通用的数据模型和快捷数据采集、存储和查询接口
它的核心组件Prometheus服务器定期从静态配置的监控目标或者基于服务发现自动配置的目标中进行拉取数据
新拉取到啊的 数据大于配置的内存缓存区时,数据就会持久化到存储设备当中