Linux开发利器:探秘开源,构建高效——基础开发工具指南(下)【make/Makefile】

♥♥♥~~~~~~欢迎光临知星小度博客空间~~~~~~♥♥♥
♥♥♥零星地变得优秀~也能拼凑出星河~♥♥♥
♥♥♥我们一起努力成为更好的自己~♥♥♥
♥♥♥如果这一篇博客对你有帮助~别忘了点赞分享哦~♥♥♥
♥♥♥如果有什么问题可以评论区留言或者私信我哦~♥♥♥
✨✨✨✨✨✨个人主页✨✨✨✨✨✨
前面两篇博客,我们已经知道了怎么在Linux下写代码和编译代码,但是编译代码一步步来还是太麻烦了,所以这一篇博客我们来学习一个比较有趣的——Linux下的自动化编译~准备好了吗~我们发车去探索Linux的奥秘啦~🚗🚗🚗🚗🚗🚗
目录
基本概念😎
理论知识输出😉
完整编译😁
补充语法😝
1. 变量定义🤗
2.$@和$^和$<🐷
编辑
编辑
3. 自动获取文件列表😄
4. 文件替换😝
5、模式规则😀
总结❤
基本概念😎
正式开始学习之前,我们首先来看看make和makefile的概念
make:Linux系统内置的命令
makefile/Makefile:需要我们(工程师)自己建立的文件,用于管理项目的编译规则
有了它们,我们就可以实现代码的自动化编译,接下来我们来看看一个简单使用例子:
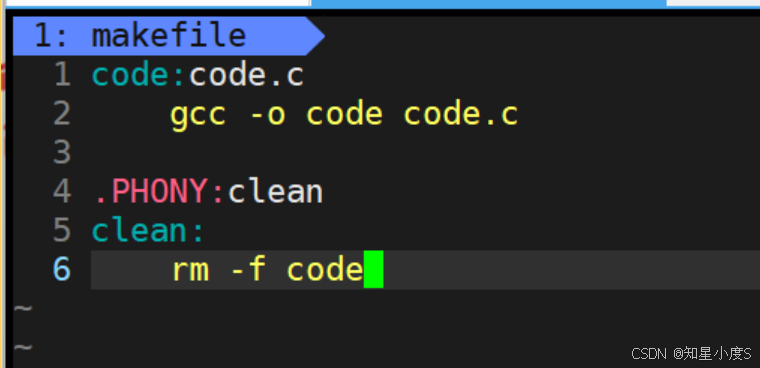
编辑makefile:
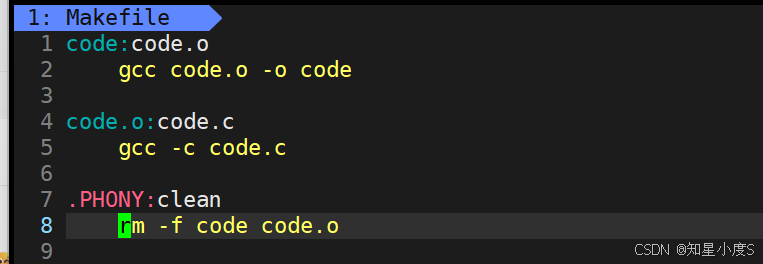
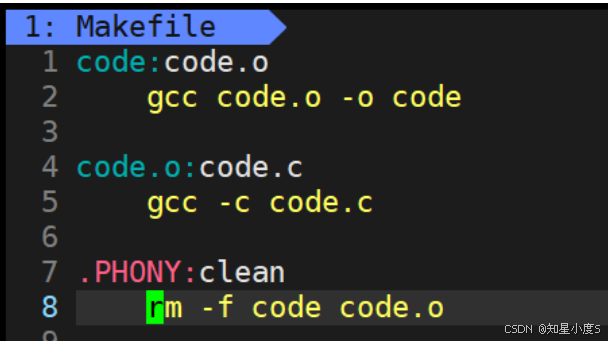
code:code.cgcc -o code code.c.PHONY:clean
clean:rm -f code 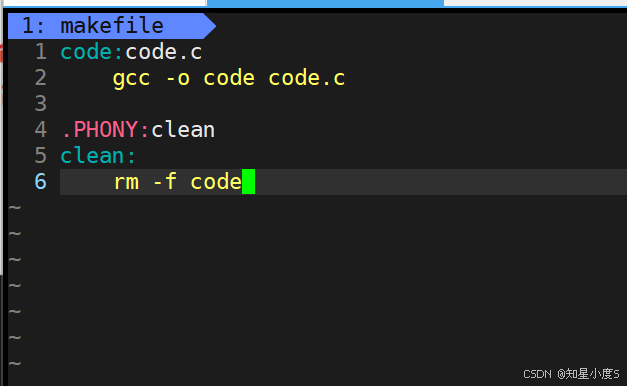
接下来,神奇的就来了,别眨眼~
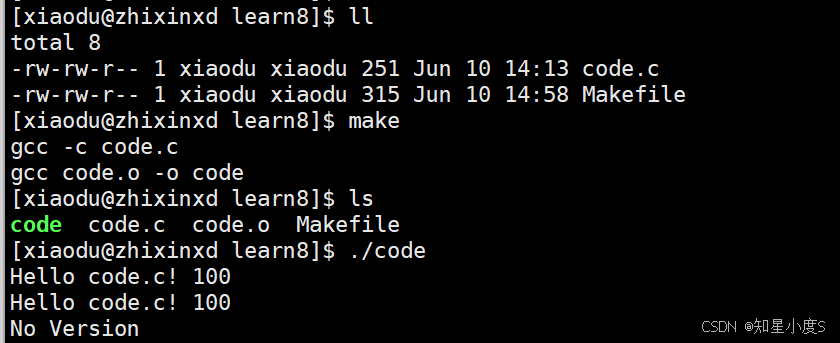
我们可以看到当命令行输入make命令的时候,代码文件 code.c 通过 gcc -o code code.c 编译生成可执行文件 code
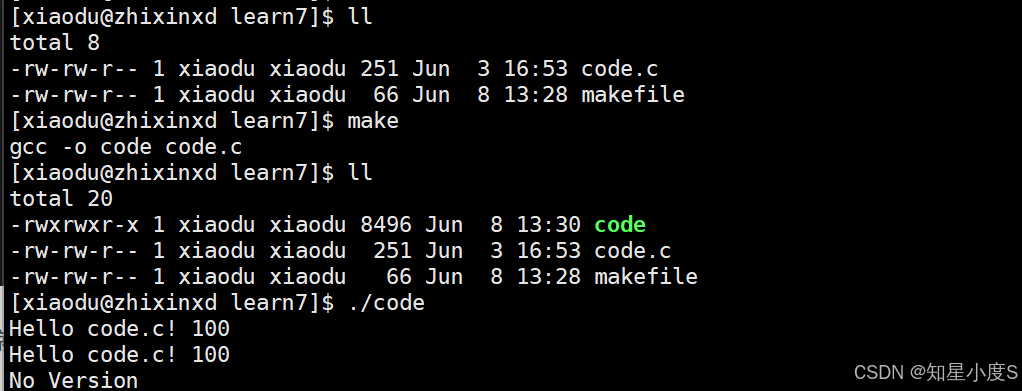
当命令行输入make clean命令的时候,通过 rm -f code 命令删除生成的可执行文件~
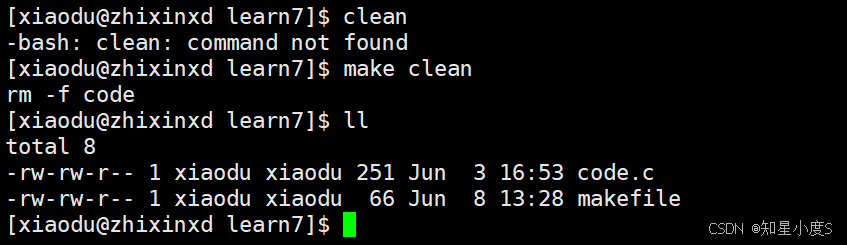
我们神奇的发现代码的编译和删除文件不需要我们手动shushuru冗余的代码了,这就是make/makefile的神奇之处,知道了它们可以达到的效果,接下来我们来输出理论知识~
理论知识输出😉
我们来仔细看看makefile中的内容:
code:code.cgcc -o code code.c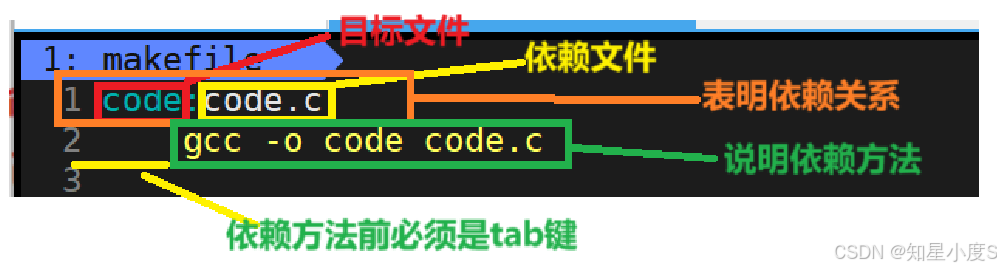
- 目标文件:编译的最终目的
- 依赖关系:目标文件依赖于源文件和其他文件
- 依赖方法:通过编译命令(如
gcc -o code code.c)将依赖文件转换为目标文件
依赖关系加上依赖方法才可以达到我们编译的目的,二者缺一不可,依赖文件可以有多个,同时依赖方法前面必须是tab键~
make在执行时,如果没有显式指定目标(如make clean),则会寻找Makefile中的第一个未被声明为伪目标(.PHONY)且不以.开头的目标,并将其作为默认目标执行~所以我们执行就是code这一个目标~
.PHONY:clean
clean:rm -f code 解释:.PHONY: clean 表示 clean 是一个伪目标,执行 make clean 会执行 rm -f code 命令
这里就有一个问题了,什么是伪目标呢?
伪目标(Phony Target) 是一种特殊类型的目标,它不对应任何实际生成的文件,而是用于执行特定的操作或命令。伪目标的核心作用是强制执行命令,即使存在同名文件,也会忽略文件的存在性,直接运行定义的规则。
这里的解释有点太官方了,这里给出伪目标特点:
伪目标特点:伪目标总是被执行的~
我们进行对比就更好理解了
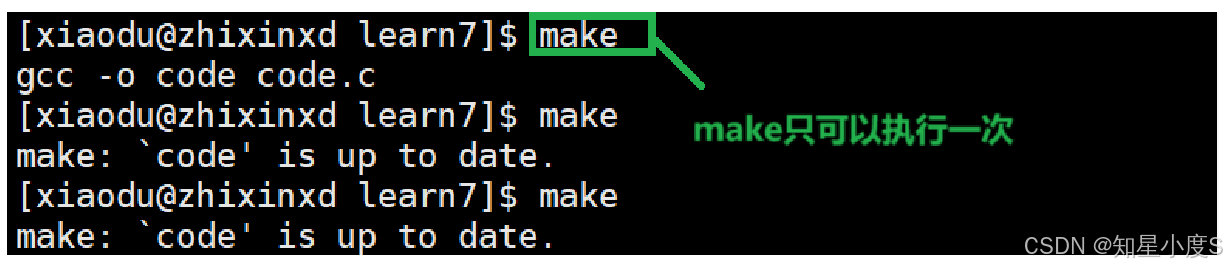
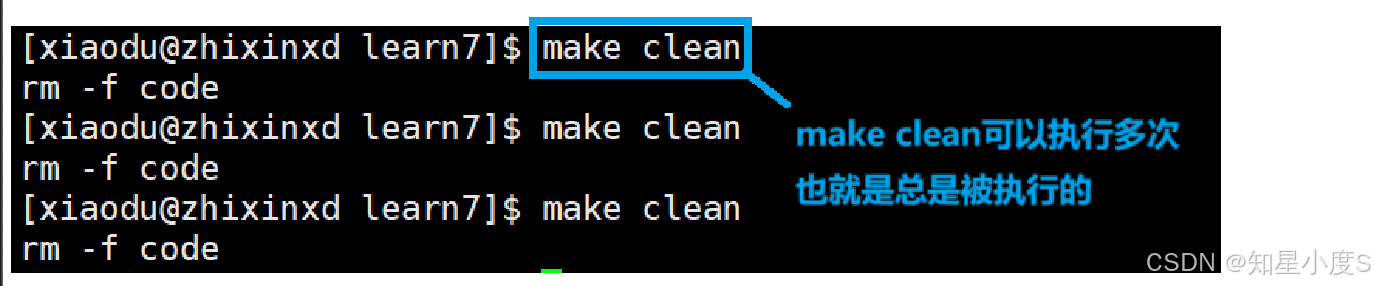
我们可以看见当code.c 文件内容没有发生任何变化的时候,make是只执行一次的,而make clean可以进行多次执行~
那么如果我们把code也设置为伪目标,那么对应的依赖方法是不是也总是被执行呢?答案是的,我们来测试一下:
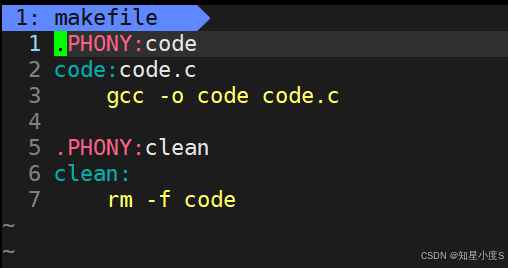
我们可以看到make每一次都可以执行,生成一个新的可执行程序~所以验证了结论:伪目标总是被执行的~
那么make/makefile是怎么知道要不要重新编译文件呢?
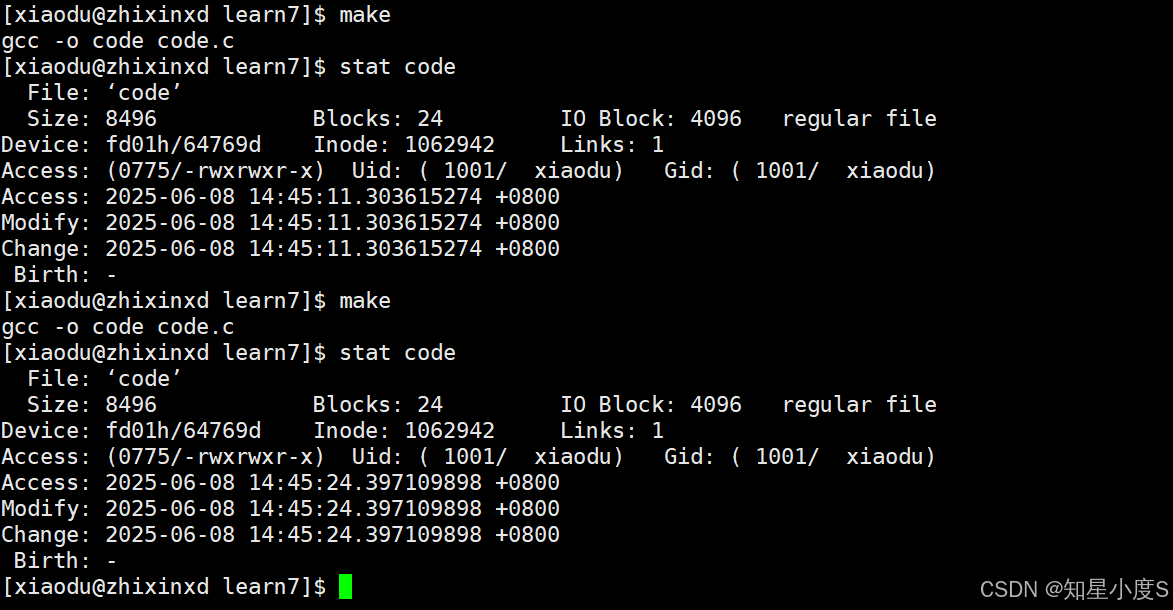
前面基础指令部分,我们知道可以通过 stat code.c 命令查看文件 code.c 的详细信息,包括文件大小、访问时间、修改时间等,make/makefile修改会对比源文件(依赖文件)和目标文件的修改时间(文件内容修改时间)决定是否需要重新编译。
stat部分详细知识可以参考这一篇博客Linux探秘:驾驭开源,解锁高效能——基础指令
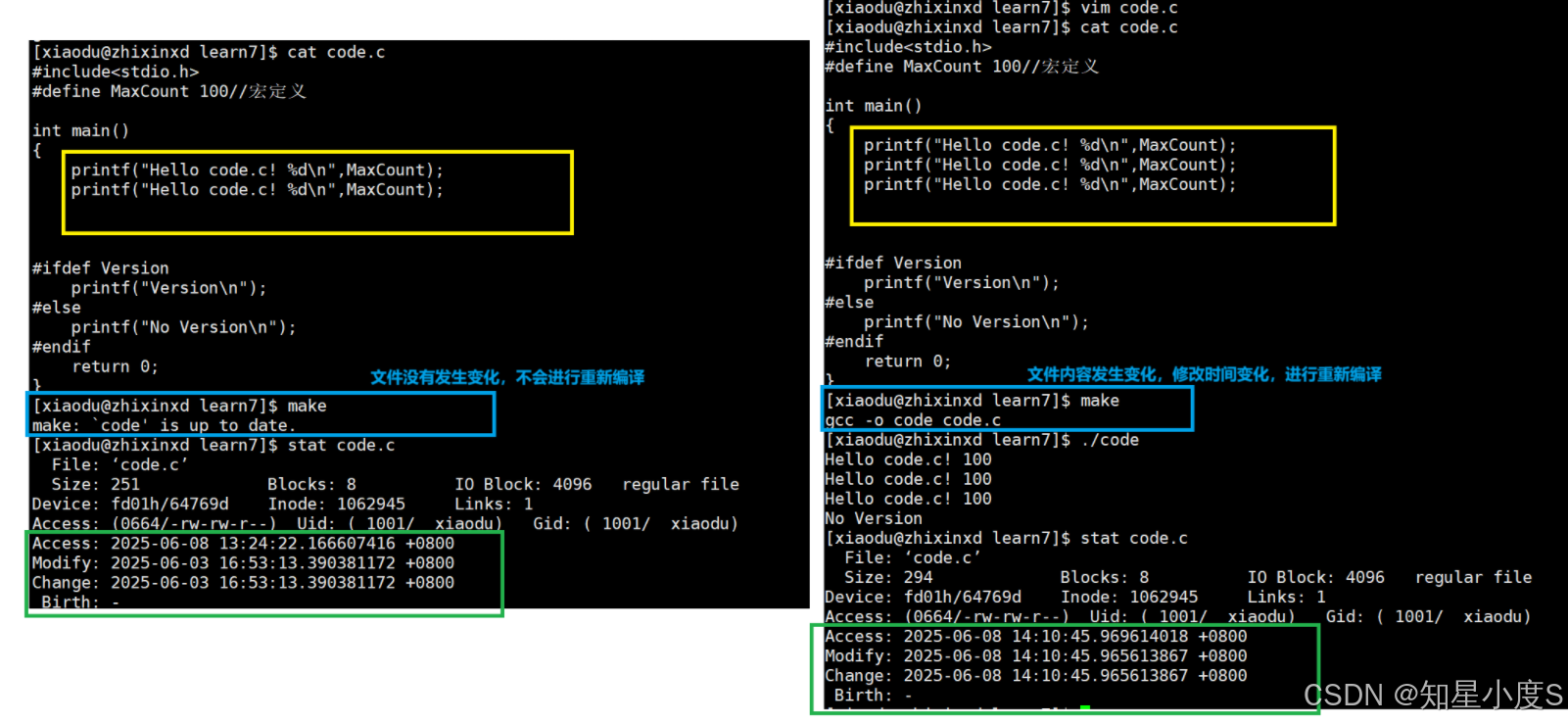
我们知道文件=文件内容+文件属性,那么属性变化会不会重新编译呢?
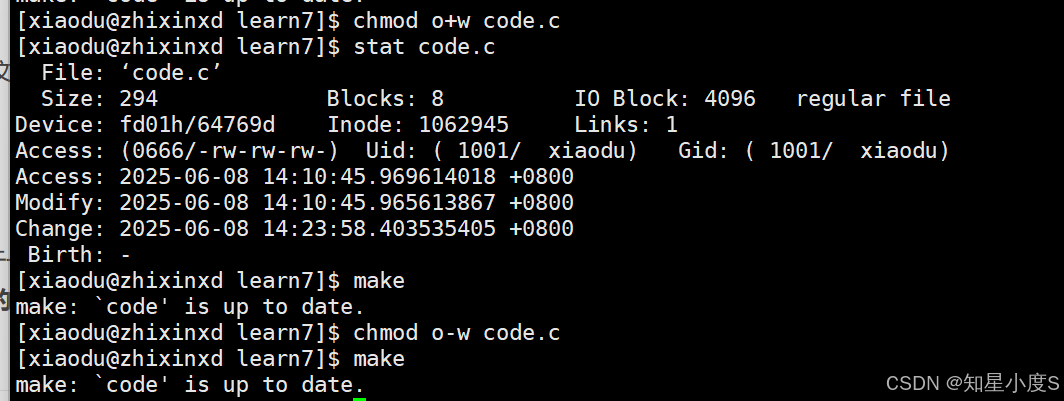
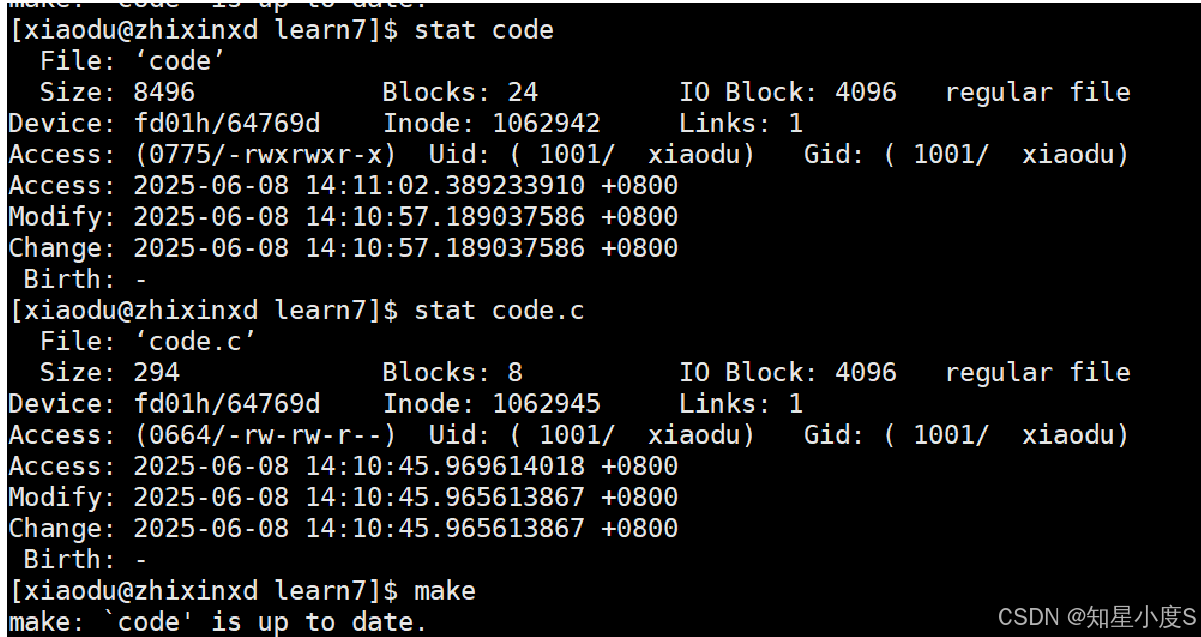
答案是文件属性变化不会触发重新编译。
总结:
①make在执行时,如果没有显式指定目标(如make clean),则会寻找Makefile中从上向下扫描到的第一个未被声明为伪目标(.PHONY)且不以.开头的目标,并将其作为默认目标执行~②伪目标(Phony Target) 是一种特殊类型的目标,它不对应任何实际生成的文件,而是用于执行特定的操作或命令,总是被执行~
③make的决策基于一个简单原则:
“如果目标文件的修改时间早于其依赖的任意一个文件,则目标需要重新生成。”
完整编译😁
根据上一篇博客的学习,我们知道代码的完整编译流程通常包括预处理、编译、汇编和链接四个主要阶段,这样一步到位好像有一点不太对劲,那我们重新编写Makefile
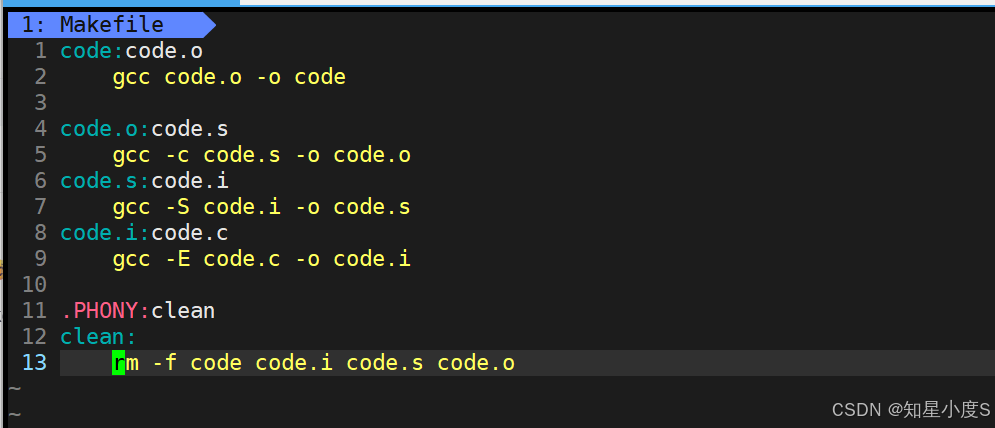
这样我们就实现了完整的编译过程,当我们命令行输入make的时候,就会进行预处理、编译、汇编、链接,同时形成code.i、code.s、code.o、code文件,也就最终形成了我们的可执行程序code~
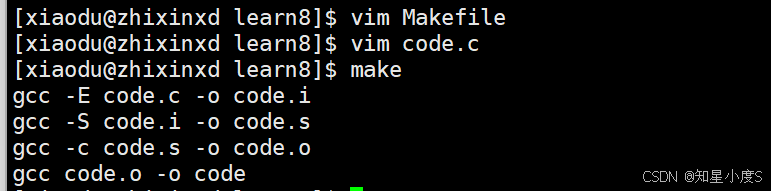
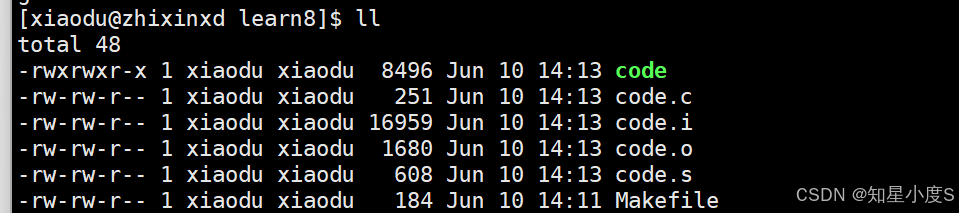

我们可以看到Makefile的第一个目标就是code,那么它是怎么一层层实现的呢?
接下来,我们就结合刚刚的示例来看看:
在默认方式下,也就是我们只输入make命令时,make会按照以下步骤工作:
- 查找Makefile:
make会在当前目录下寻找名为“Makefile”或“makefile”的文件。
- 确定目标文件:
- 如果找到Makefile,
make会寻找文件中的第一个目标文件(target)。在上面的例子中,它会找到code这个文件,并将其作为最终的目标文件。
- 如果找到Makefile,
- 处理依赖关系:
- 如果code文件不存在,或是code所依赖的后面的
code.o文件的修改时间比code这个文件新(可以用touch/stat命令测试),那么make就会执行后面所定义的命令来生成code这个文件。 - 如果code所依赖的
code.o文件不存在,make会在当前文件中寻找目标为code.o文件的依赖性。如果找到,则再根据那一个规则生成code.o文件,依此类推生成code.i,code.s文件,最终生成code文件,也就是我们得到的可执行程序(类似于一个堆栈的过程) 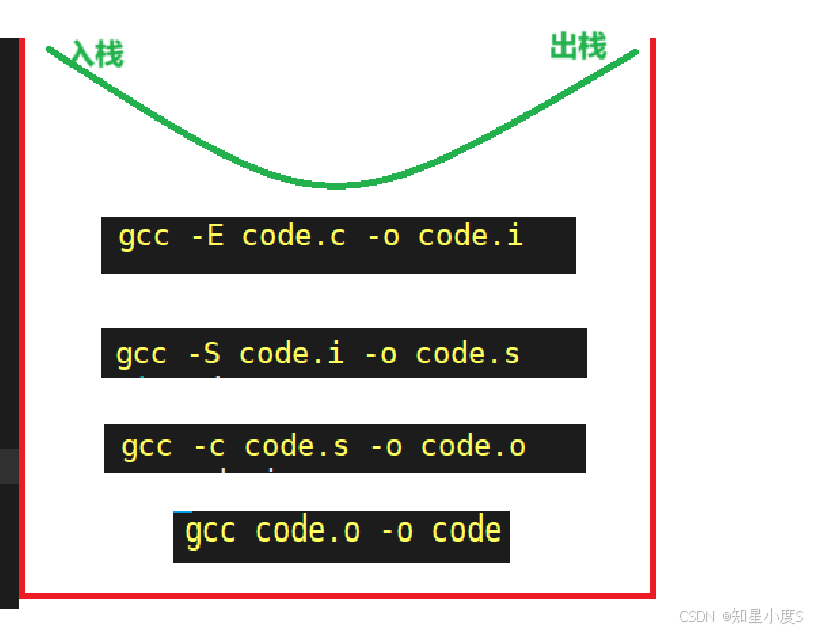
- 如果code文件不存在,或是code所依赖的后面的
- 编译过程:
- 当然,如果C文件和H文件是存在的。
make会先生成code.o文件,然后再用code.o文件来声明make的终极任务,即生成可执行文件code - 这就是整个
make的依赖性体现,make会一层又一层地去找文件的依赖关系,直到最终编译出第一个目标文件。
- 当然,如果C文件和H文件是存在的。
- 错误处理:
- 在找寻的过程中,如果出现错误,比如最后被依赖的文件找不到,那么
make就会直接退出,并报错。 - 而对于所定义的命令的错误,或是编译不成功的情况,
make根本不理会,它只关心文件的依赖性。即如果在我找了依赖关系之后,冒号后面的文件还是不存在,那么对不起,我就不工作~
- 在找寻的过程中,如果出现错误,比如最后被依赖的文件找不到,那么
当我们命令行输入make clean的时候就会执行我们的清理操作~
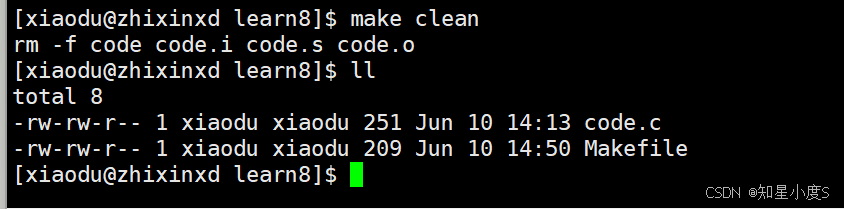
这样看起来完整编译还是有一点麻烦,我们的一般实践是什么样子呢?
我们一般使用使用gcc -c code.c生成同名的.o文件,也就是code.o文件,然后gcc code.o -o code形成我们的可执行程序~这是我们的一般实践,比完整编译流程代码量简单一些~
补充语法😝
1. 变量定义🤗
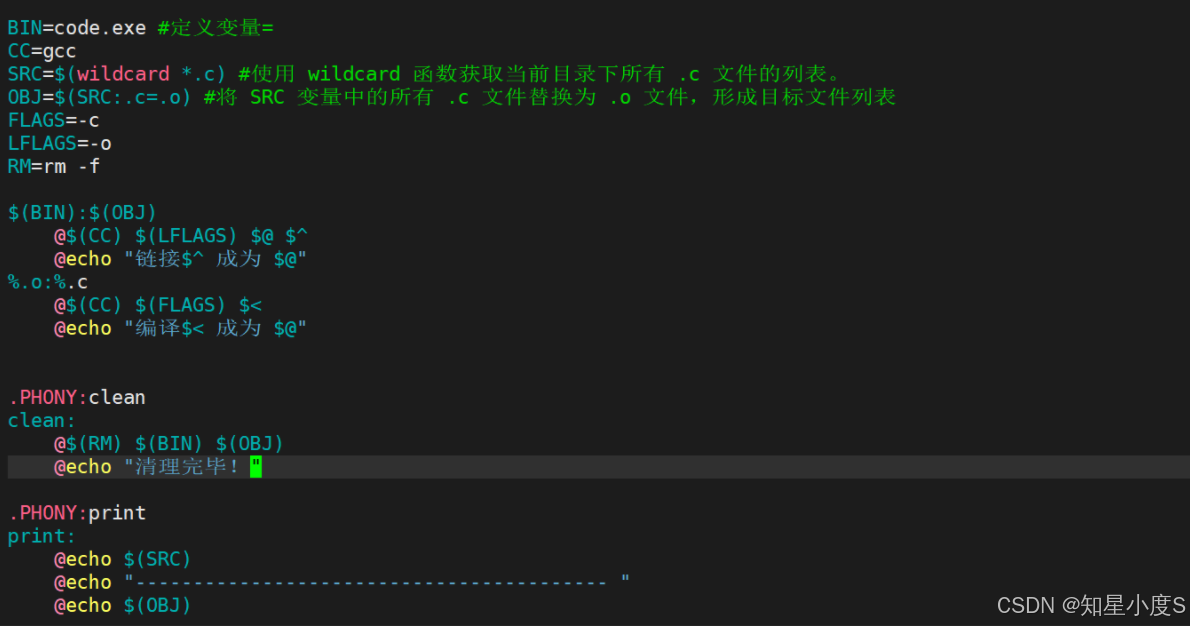
Makefile中使用 = 来定义变量
例如:
makefile
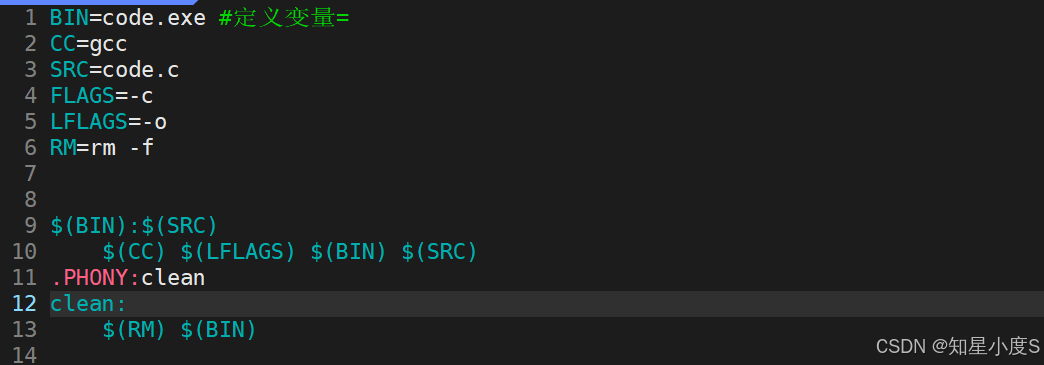
BIN=code.exe # 定义可执行文件变量CC=gcc # 定义编译器变量LFLAGS=-o # 定义链接选项变量FLAGS=-c # 定义编译选项变量RM=rm -f # 定义删除命令变量变量可以在规则中的命令部分通过 $(变量名) 的方式引用,例如 $(CC) 就代表 gcc
我们可以定义一个伪目标来进行打印测试,是否创建了变量:
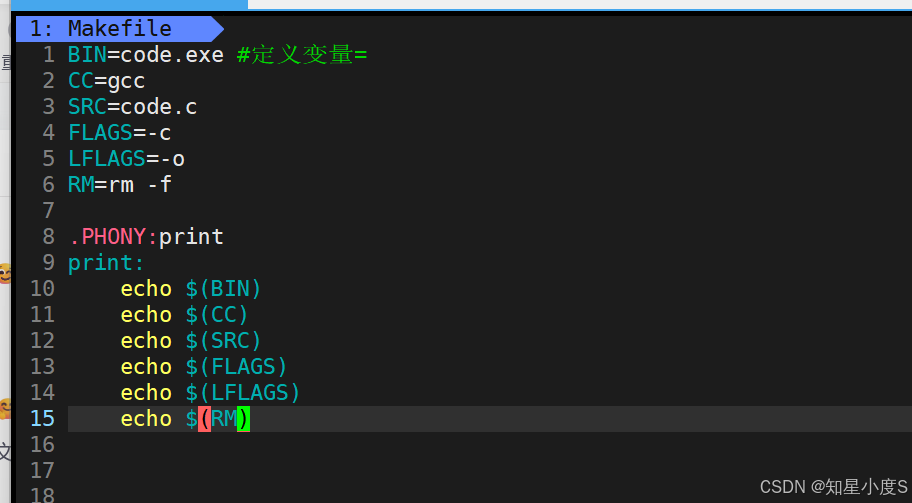
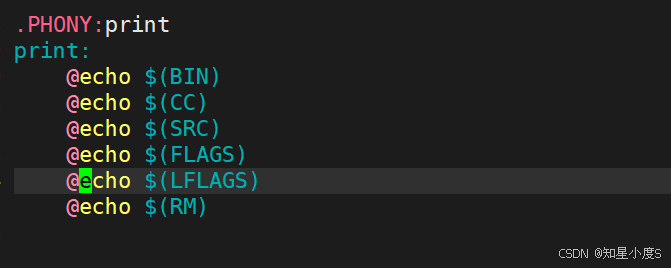
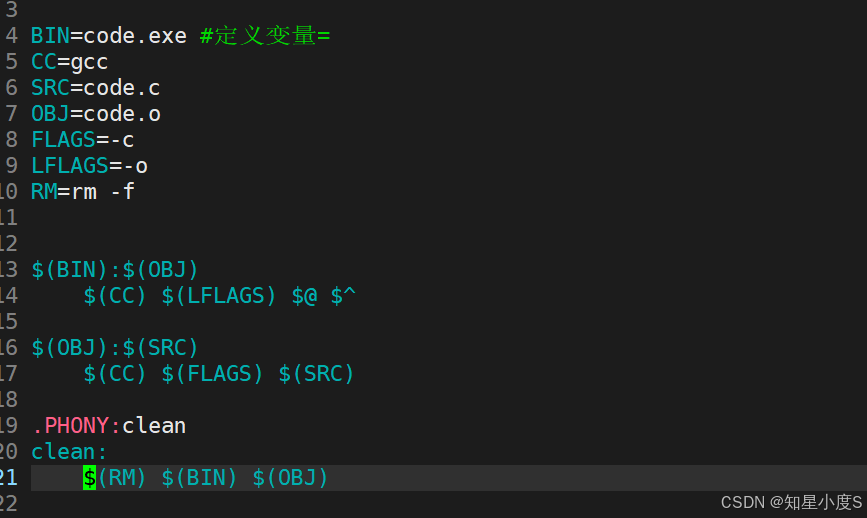
1 BIN=code.exe #定义变量=2 CC=gcc3 SRC=code.c4 FLAGS=-c5 LFLAGS=-o6 RM=rm -f7 8 .PHONY:print 9 print:10 echo $(BIN)11 echo $(CC)12 echo $(SRC)13 echo $(FLAGS)14 echo $(LFLAGS)15 echo $(RM) 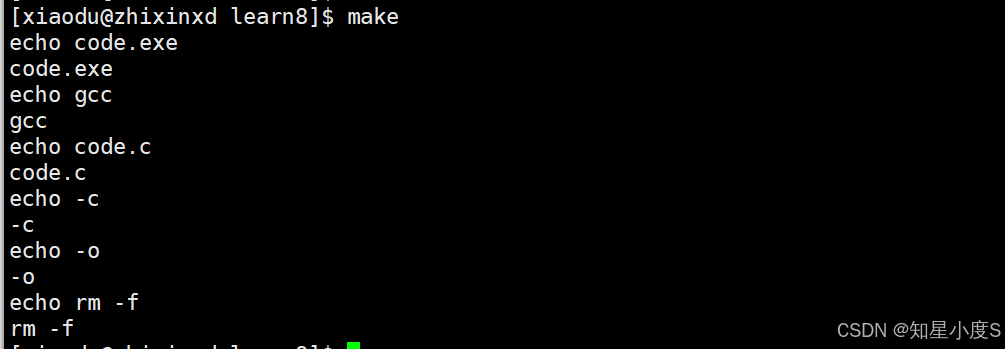
我们还可以在前面加一个@就不会显示我们的命令了~而是直接打印变量内容~
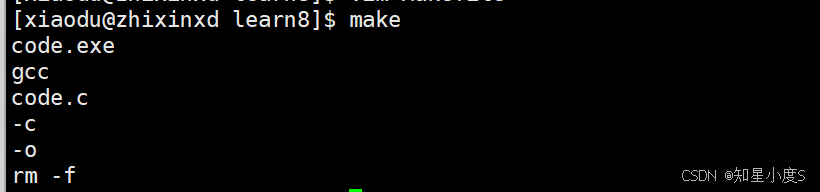
有了变量,那么我们就可以使用变量来进行重新编译了~
结合前面的代码来试一试:
测试结果:
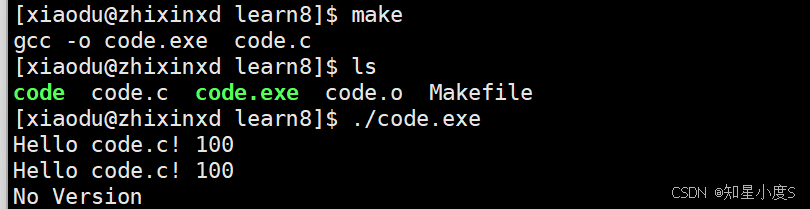

可以看出来有了变量就方便我们进行随时替换,类似于我们C语言的宏定义一样~
2.$@和$^和$<🐷
除此之外,我们还可以对上面的代码进行优化~
$@和$^是自动变量,它们的作用是根据当前规则的上下文自动展开为特定的文件名,用于简化规则的编写。
| 自动变量 | 含义 | 示例场景 |
|---|---|---|
$@ | 当前规则的目标文件名 | 编译 .c 到 .o:$@ 是 .o 文件名 |
$^ | 当前规则的所有依赖文件列表 | 链接多个
|

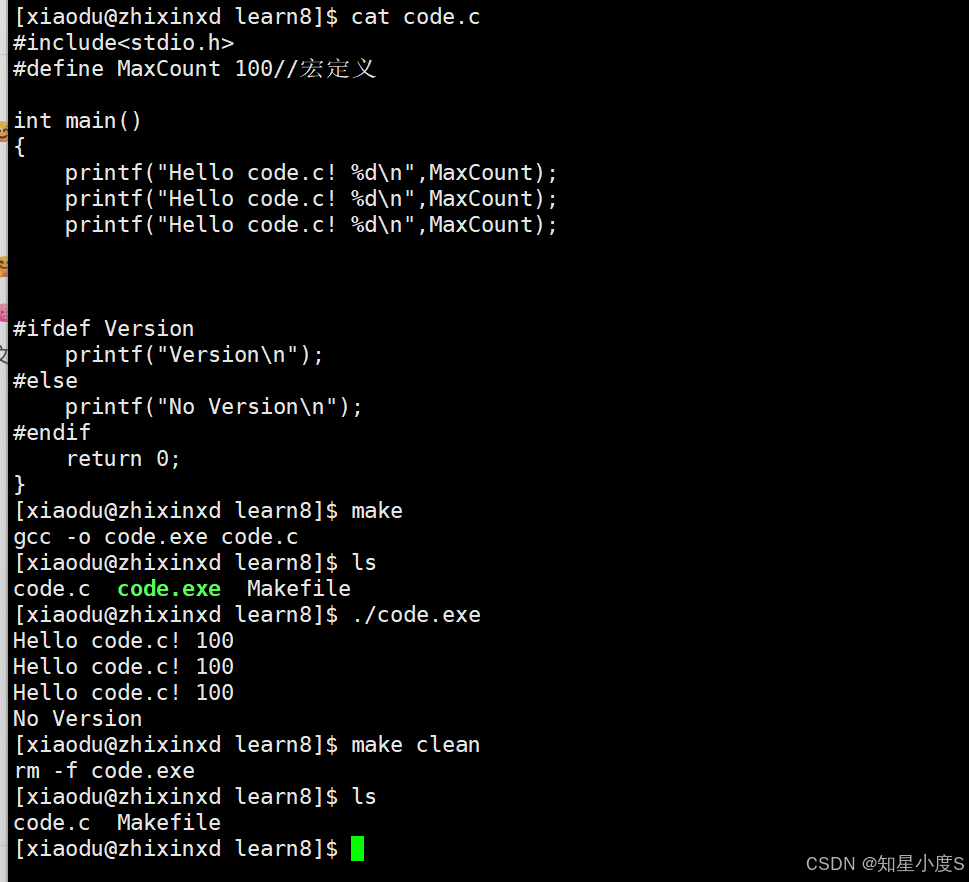
我们可以看到同样编译成功~
知道了这个,那么我们前面的一般实践就可以进行改写~
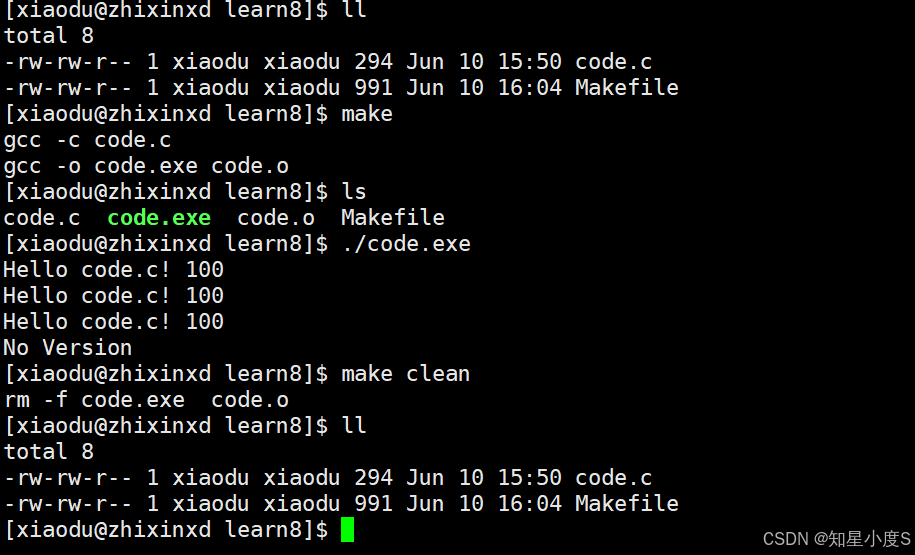
同样编译成功~
还有一个与$^有点区别的$<
$<的作用是:在规则的命令中,自动展开为当前规则的第一个依赖文件的完整名称。
如果规则有多个依赖文件,$< 始终指向第一个依赖文件,而 $^ 包含所有依赖文件,例如目标是 main.o,依赖是 main.c 和 main.h,则 $< 是 main.c
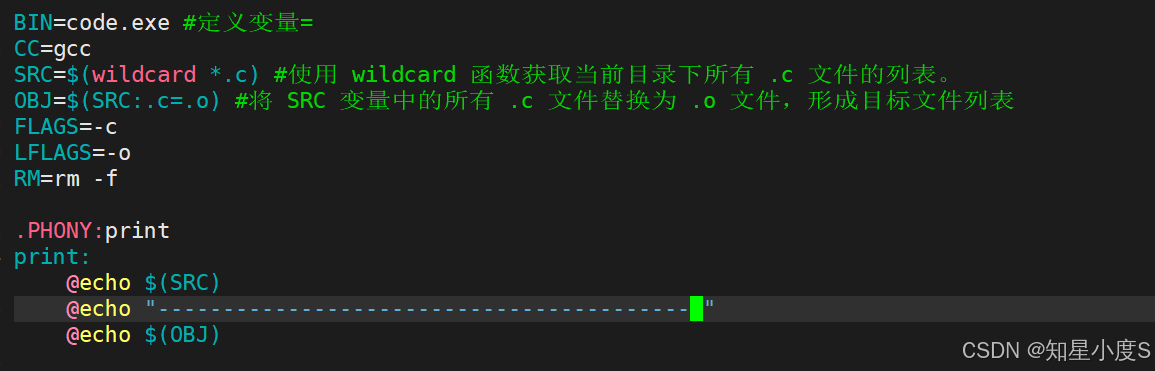
3. 自动获取文件列表😄
SRC=$(wildcard *.c) 使用 wildcard 函数获取当前目录下所有 .c 文件的列表。这种方式比直接使用 shell 命令更高效,也更符合Makefile的语法规范。
4. 文件替换😝
OBJ=$(SRC:.c=.o) 将 SRC 变量中的所有 .c 文件替换为 .o 文件,形成目标文件列表。例如,如果 SRC 是 main.c utils.c,那么 OBJ 就会是 main.o utils.o。
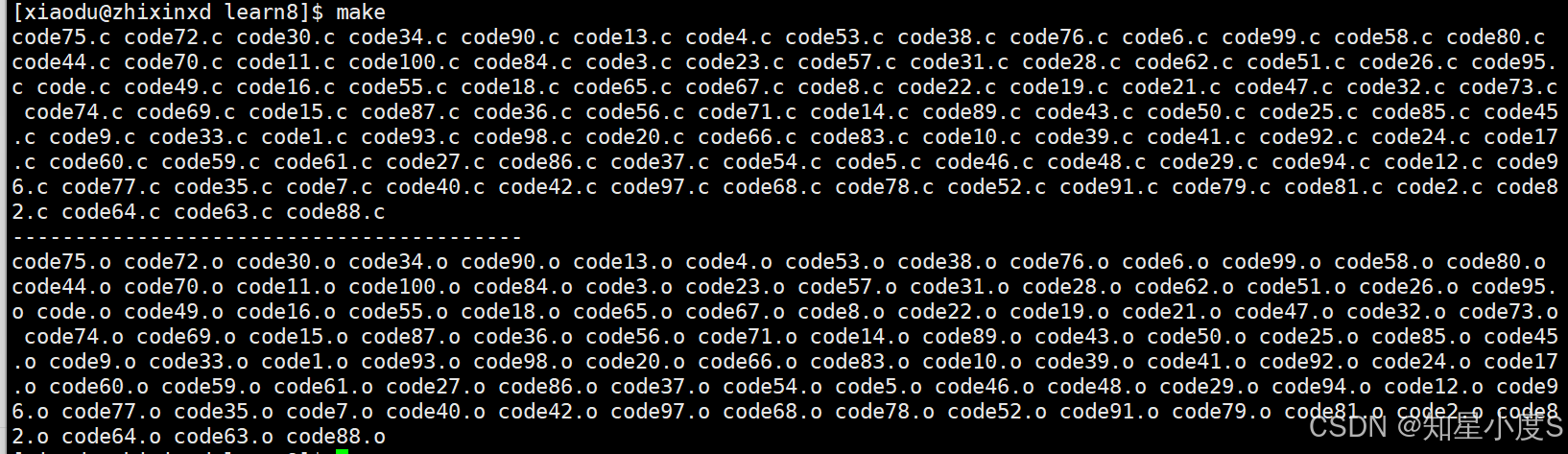
接下来,我们进行3、4的验证:
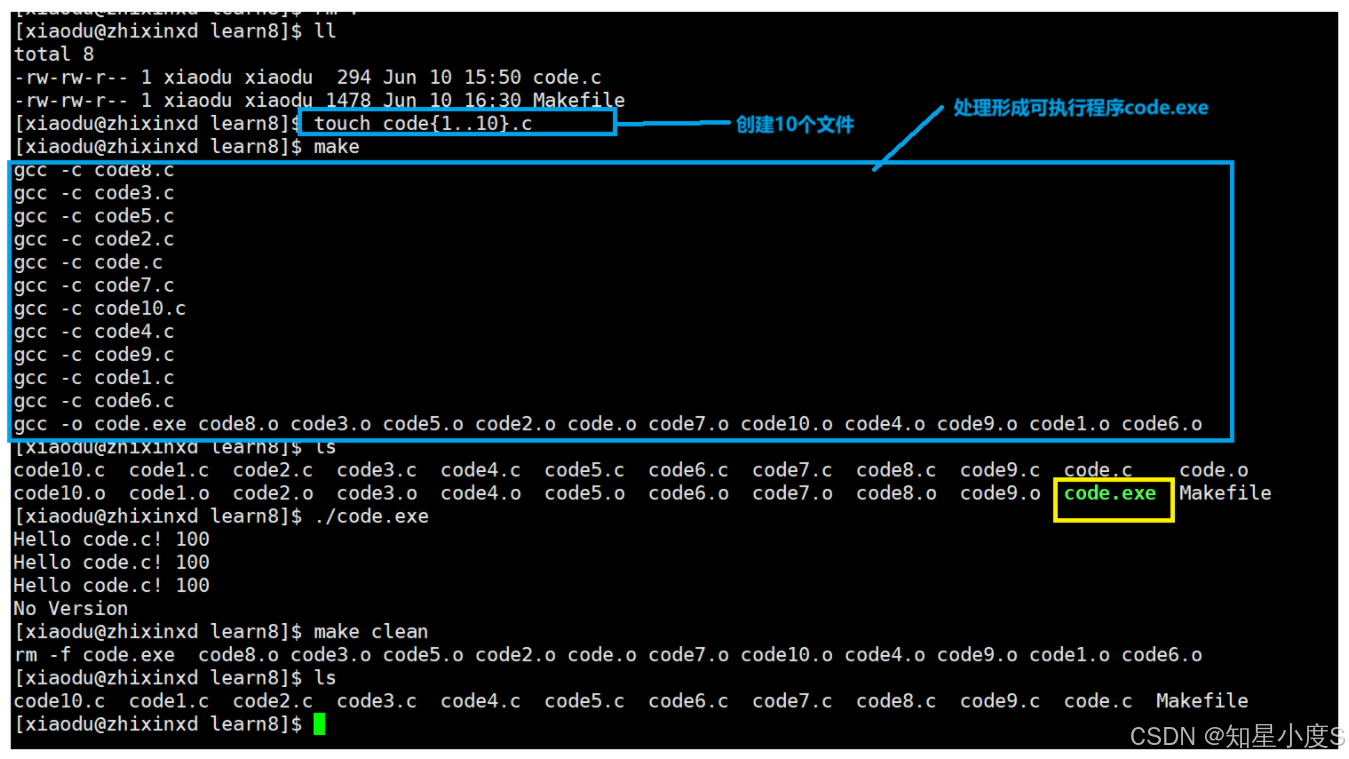
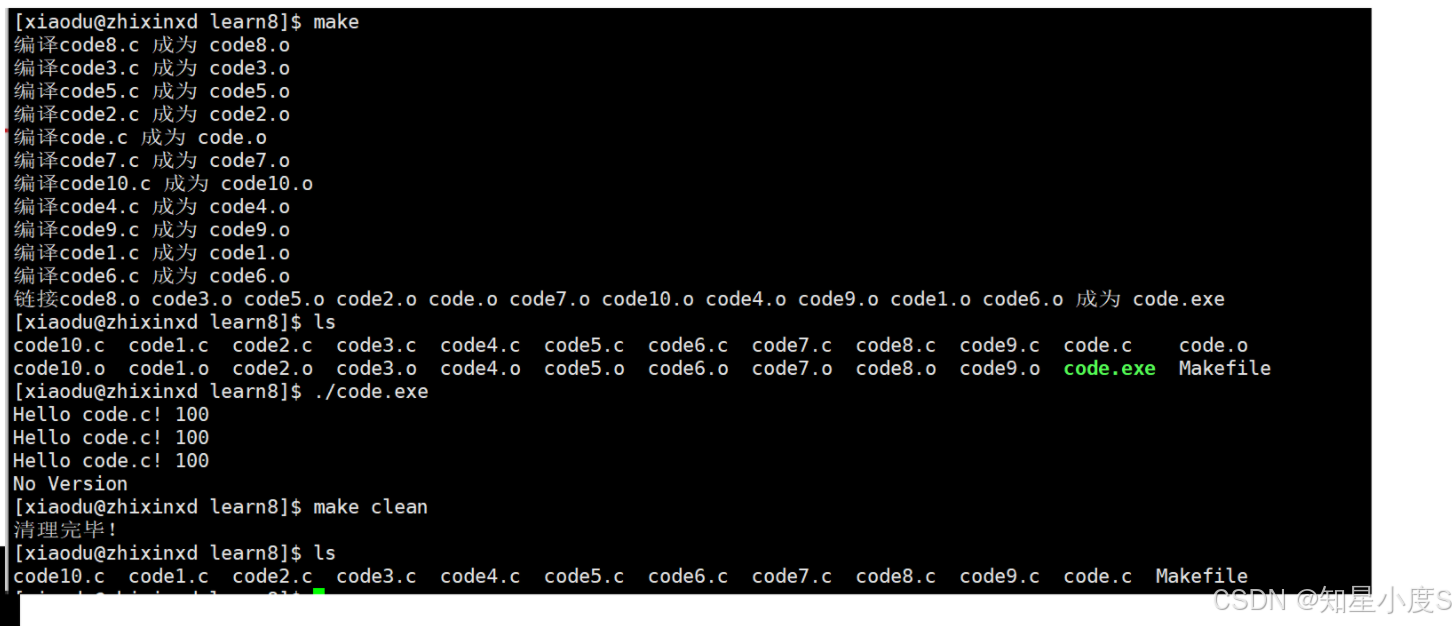
首先创建100个.c文件

命令行输入make,可以看到SRC已经有了全部的.c文件,OBJ已经有了全部的.o文件,也就是目标文件~
5、模式规则😀
%.o:%.c 是一个模式规则,表示所有以 .o 结尾的目标文件都依赖于同名的 .c 文件。
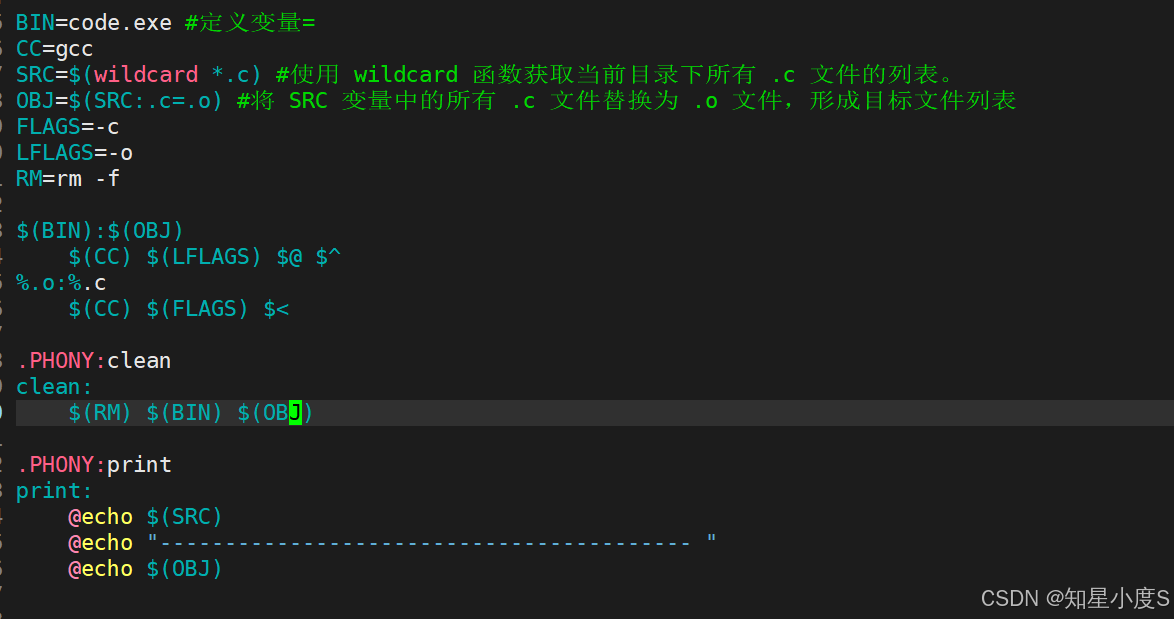
$< 是自动变量,代表第一个依赖文件名,这里是 .c 文件,编译.c文件会形成对应的同名.o文件
优化,让执行指令不显示:
总结❤
Makefile通过自动化编译、增量编译和项目管理三大核心功能,显著提升开发效率。仅需执行make命令,即可自动编译修改过的源文件并链接生成可执行文件,无需手动干预。其依赖分析机制智能识别需重新编译的文件,避免冗余操作,大幅缩短编译时间。通过定义clean等伪目标,可一键完成项目清理、调试信息输出等管理任务,使项目构建与维护更加高效便捷,是C/C++项目开发的标准构建工具,以后要通过实际操作来更好地掌握~
♥♥♥本篇博客内容结束,期待与各位优秀程序员交流,有什么问题请私信♥♥♥
♥♥♥如果这一篇博客对你有帮助~别忘了点赞分享哦~♥♥♥
✨✨✨✨✨✨个人主页✨✨✨✨✨✨