深度学习TR3周:Pytorch复现Transformer
- 🍨 本文为🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者:K同学啊
本周任务:
1.从整体上把握Transformer模型,明白它是个什么东西,可以干嘛
2.读懂Transformer的复现代码
一、Transformer与Seq2Seq+
Seq2Seq2
- 用于处理序列数据的模型架构,广泛应用于自然语言处理(NLP)任务,如机器翻译、文本摘要和对话系统等。
- 核心思想是将输入序列转换为输出序列。
- 问题:解码器从编码器接收的唯一信息是最后一个编码器隐藏状态,这是一种类似输入序列数字总结的向量表示。因此,对于较长的文本,如果我们仍希望解码器使用一个向量表示来输出译文,是不合理的。则如果想得到更优质的翻译结果,需要向解码器提供每个编码器时间步的向量表示,而不是只有一个向量表示。
- 如何向解码器提供每个编码器时间步的向量表示呢?------引入注意力机制
注意力机制
- 编码器和解码器之间的接口,为解码器提供每个编码器隐藏状态的信息。通过此设置,模型能有选择地侧重输入序列的有用部分,有助于模型有效地处理输入长句。
- 本质:通过为每个单词分配分值,注意力为不同单词分配不同的注意力。然后利用softmax对编码器隐藏状态进行加权求和,得到上下文向量(context vector)。
- 实现步骤:①准备隐藏状态 ②获取每个编码器隐藏状态分数 ③通过softmax层运行所有分数 ④通过softmax得分将每个编码器隐藏状态相乘 ⑤向量求和 ⑥将上下文向量输入解码器
通过学习Seq2Seq,知晓Attention对RNN的优点。
有没有一种神经网络结构直接基于attention构造,不依赖RNN、LSTM或CNN网络结构?
----Transformer
Seq2Seq和Transformer都是用于处理序列数据的深度学习模型,但它们是两种不同架构。
1.Seq2Seq
- 定义:一种用于序列到序列任务的模型架构,最初用于机器翻译。这意味着它可以处理输入序列,并生成相应的输出序列。
- 结构:通常由编码器和解码器两个主要部分组成。编码器负责将输入序列编码为固定大小的向量,而解码器则使用此向量生成输出序列。
- 问题:传统Seq2Seq模型在处理长序列时可能会遇到梯度消失/爆炸等问题,而Transformer模型的提出正是为了解决这些问题。
2.Transformer
- 定义:一种更现代的深度学习模型,专为处理序列数据而设计,最初用于自然语言处理任务。它不依赖于RNN或CNN等传统结构,而是引入注意力机制。
- 结构:主要由编码器和解码器组成,由自注意力层和全连接前馈网络组成。它使用注意力机制来捕捉输入序列中不同位置之间的依赖关系,同时通过多头注意力来提高模型的表达能力。
- 优势:能够更好地处理长距离依赖关系,同时具有更好的并行性,
在某种程度上,可以将Transformer看作是Seq2Seq的一种演变,Transformer可以执行Seq2Seq任务,并且相对于传统的Seq2Seq模型具有更好的性能和可扩展性。(论文原文:Attention Is All You Need)
与RNN这类神经网络结构相比,Transformer一个巨大的优点:模型在处理序列输入时,可以对整个序列输入进行并行计算,不需要按照时间步循环递归处理输入序列。
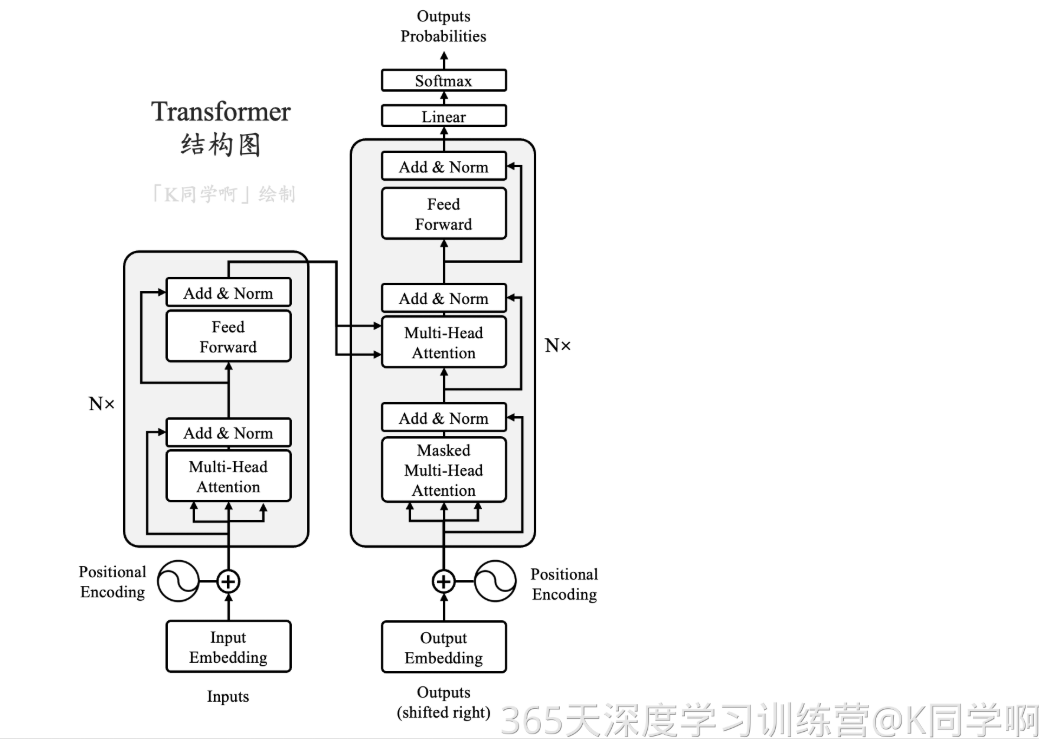
下图是Transformer整体结构图,与Seq2Seq模型相似,Transformer模型结构中,左半部分为编码器,右半部分为解码器。
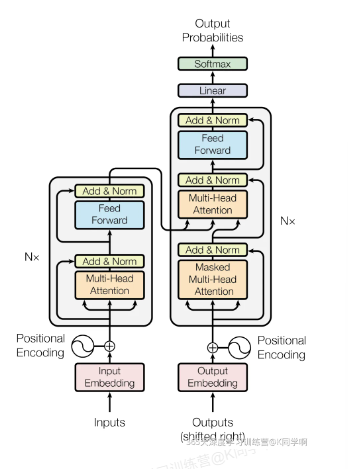
二、Transformer宏观结构
Transformer可以看作seq2seq模型的一种。
从seq2seq角度对Transformer进行宏观结构学习,以机器翻译任务为例,先将Transformer看作一个黑盒,黑盒的输入是法语文本序列,输出是英语文本序列。

将上图中间部分“THE TRANSFOEMER”拆分成seq2seq标准结构,得到下图:左边是编码部分encoders,右边是解码部分decoders。
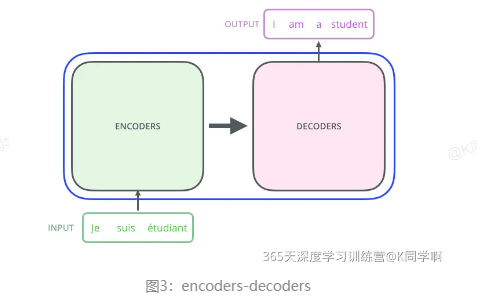
再将上图中的编码器和解码器细节绘出,得到下图。
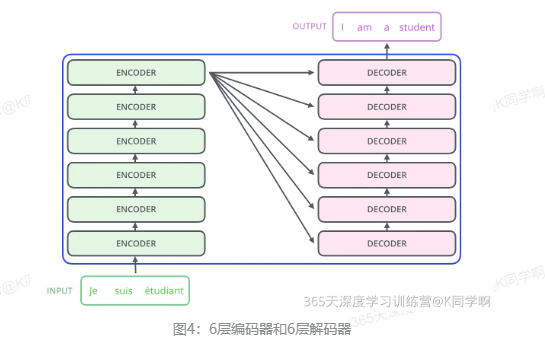
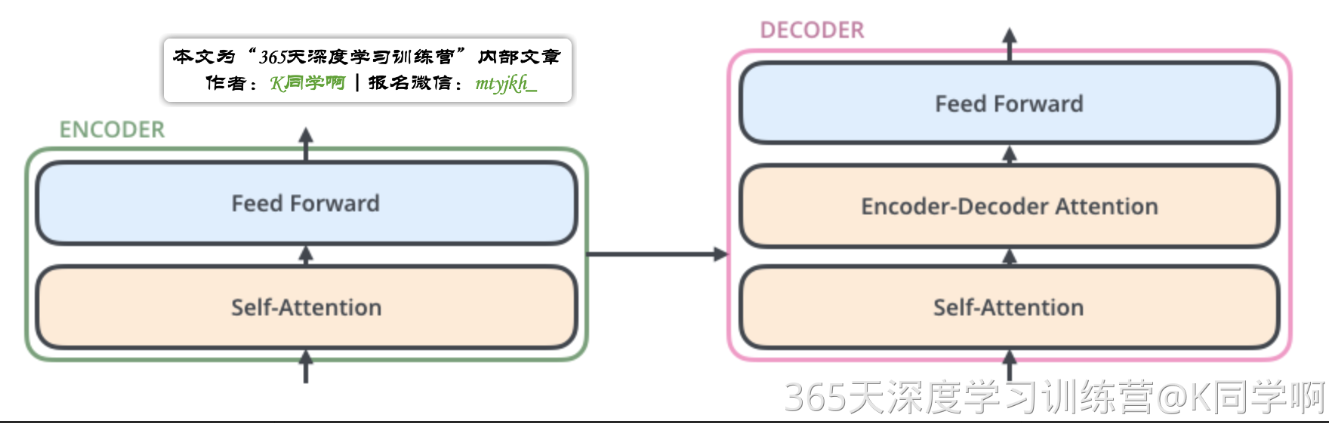
可以看到,编码部分由多层编码器(encoder)组成,解码部分也由多层解码器(decoder)组成。每层解码器、解码器网络结构是一样的,但是不同层编码器、解码器网络结构不共享参数。
其中,单层编码器主要由自注意力层(Self-Attention Layer)和全连接前馈网络(Feed Forward Neural Network,FFNN)组成,如下图。
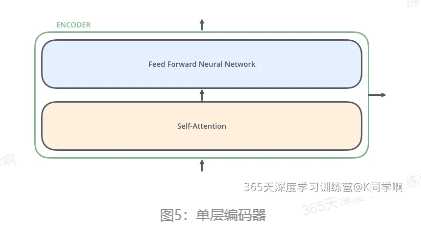
其中,解码器在编码器的自注意力层和全连接前馈网络中间插入了一个Encoder-Decoder Attention层,帮助解码器聚焦于输入序列最相关的部分。
三、复现Transformer
import math
import torch
import torch.nn as nn
device = torch.device("cpu")
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)输出结果:
1.shape变化类
import torch.nn as nnclass Transpose(nn.Module):def init_(self,*dims, contiguous=False):super(Transpose,self).init_() #确保正确调用父类的构造函数self.dims=dims #存储交换的维度self.contiguous= contiguous #存储是否需要返回连续内存布局的标志def forward(self,x):#如果需要连续内存布局,调用.contiguous()方法来确保if self.contiguous:return x.transpose(*self.dims).contiguous()else:return x.transpose(*self.dims)注:python没有指针概念
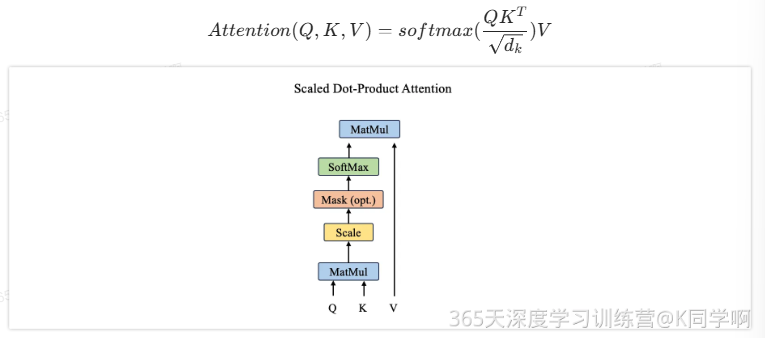
2.Scaled Dot-Product Attention
Scaled Dot-Product Attention 是Self-Attention的一个具体表现
import torch.nn.functional as F
class ScaledDotProductAttention(nn.Module):def __init__ (self,d_k:int):super(ScaledDotProductAttention, self).__init__()#确保正确调用父类的构造函数#初始化函数,dk表示键/查询向量的维度self.d_k=d_kdef forward(self,q,k,v,mask = None):#计算注意力机制的核心步骤#q:查询向量,k:键向量,v:值向量,mask:用于遮挡部分位置的掩码#计算查询和键的点积,得到相似度分数。这里的k在上层已经完成了转置scores =torch.matmul(q,k)#scores形状:[bs,n heads,d k,q len]#缩放分数,防止数值过大导致softmax梯度过小scores=scores/(self.d_k**0.5)#应用掩码(如果提供了掩码),将被掩码位置的分数设为一个极小值if mask is not None:scores.masked_fill(mask,-1e9)#对分数应用softmax,得到注意力权重attn =F.softmax(scores,dim=-1)# attn形状:[bs,n heads, q len, q len]#根据注意力权重加权求和值向量context =torch.matmul(attn,v)# context形状:[bs,n heads, q len, d_v]return context3.多头注意力机制
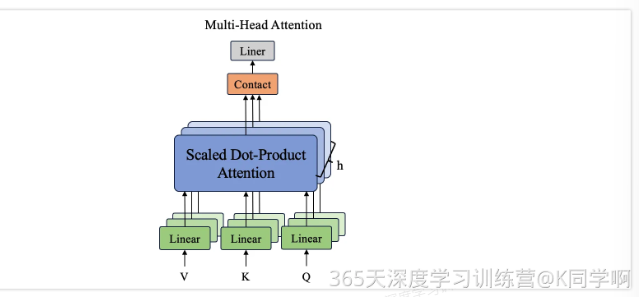
class MultiHeadAttention(nn.Module):def __init__ (self,d_model,n_heads):"""多头注意力机制的初始化函数参数:d_model:输入特征的维度n_heads:注意力头的数量d_k:每个头中键/查询向量的维度d_v:每个头中值向量的维度"""super(MultiHeadAttention,self).__init__() #确保正确调用父类的构造函数assert d_model %n_heads ==0, f"d_model({d_model}) 必须被 n_heads({n_heads})整除"self.d_k= d_model//n_headsself.d_v= d_model//n_headsself.n_heads = n_heads#定义用于生成查询、键和值的线性层self.W_Q=nn.Linear(d_model,self.d_k*n_heads, bias=False)self.W_K=nn.Linear(d_model,self.d_k*n_heads, bias=False)self.W_V=nn.Linear(d_model,self.d_v*n_heads, bias=False)#用于将多头输出的拼接结果投影回输入特征维度的线性层self.W_0=nn.Linear(n_heads *self.d_v,d_model, bias=False)self.attention = ScaledDotProductAttention(self.d_k)def forward(self,Q,K,V,mask = None):#前向传播函数,计算多头注意力#0:查询向量,K:键向量,V:值向量,mask:用于遮挡部分位置的掩码bs =Q.size(0) #获取批量大小#将输入通过线性层生成多头的查询、键和值,并对其进行维度变换q_s = self.W_Q(Q).view(bs,-1,self.n_heads, self.d_k).transpose(1,2) #q_s形状:[bs,n_heads,qlen,dk]k_s = self.W_K(K).view(bs, -1, self.n_heads, self.d_k).permute(0,2,3,1) # k_s形状: [bs,n_heads,dk,g_len]v_s= self.W_V(V).view(bs,-1,self.n_heads, self.d_v).transpose(1, 2) # v_s形状:[bs,n_heads,q_len,d_v]#计算缩放点积注意力context = self.attention(q_s, k_s, v_s, mask)#将多头的输出拼接起来,拼接后的形状:[bs,qlen,(n heads*dv)]context = context.transpose(1,2).contiguous().view(bs, -1, self.n_heads * self.d_v)#通过线性层映射回输入特征维度output =self.W_0(context) # output形状:[bs,g_len,d_model]return output4.前馈传播
class Feedforward(nn.Module):def __init__ (self,d_model,d_ff,dropout=0.1):super(Feedforward,self).__init__()#两层线性映射和激活函数ReLUself.linear1 =nn.Linear(d_model,d_ff)self.dropout = nn.Dropout(dropout)self.linear2 =nn.Linear(d_ff, d_model)def forward(self,x):x= torch.nn.functional.relu(self.linear1(x))x= self.dropout(x)x= self.linear2(x)return x5.位置编码
class PositionalEncoding(nn.Module):"实现位置编码"def __init__ (self,dmodel,dropout,max_len=5000):super(PositionalEncoding,self).__init__()self.dropout = nn.Dropout(p=dropout)#初始化Shape为(max len,d model)的PE(positional encoding)pe =torch.zeros(max_len,dmodel).to(device)#初始化一个tensor[[0,1,2,3,...]]position =torch.arange(0,max_len).unsqueeze(1)#这里就是sin和cos括号中的内容,通过e和1n进行了变换div_term = torch.exp(torch.arange(0,d_model,2)*-(math.log(10000.0)/ d_model))pe[:,0::2]=torch.sin(position*div_term)#计算PE(pos,2i)pe[:,1::2]=torch.cos(position*div_term)#计算PE(pos,2i+1)pe = pe.unsqueeze(0)#为了方便计算,在最外面在unsqueeze出一个batch#如果一个参数不参与梯度下降,但又希望保存model的时候将其保存下来#这个时候就可以用register bufferself.register_buffer("pe",pe)def forward(self,x):"""x为embedding后的inputs,例如(1,7,128),batch size为1,7个单词,单词维度为128"""#将x和positional encoding相加。x=x+ self.pe[:,:x.size(1)].requires_grad_(False)return self.dropout(x) 6.编码层
class EncoderLayer(nn.Module):def __init__ (self,d_model,n_heads, d_ff, dropout=0.1):super(EncoderLayer,self).__init__()#编码器层包含自注意力机制和前馈神经网络self.self_attn =MultiHeadAttention(d_model,n_heads)self.feedforward = Feedforward(d_model, d_ff, dropout)self.norm1= nn.LayerNorm(d_model)self.norm2= nn.LayerNorm(d_model)self.dropout = nn.Dropout(dropout)def forward(self,x,mask):#自注意力机制attn_output =self.self_attn(x,x,x,mask)x=x+ self.dropout(attn_output)x= self.norm1(x)#前馈神经网络ff_output = self.feedforward(x)x=x+ self.dropout(ff_output)x= self.norm2(x)return x7.解码层
class DecoderLayer(nn.Module):def __init__ (self,d_model,n_heads,d_ff, dropout=0.1):super(DecoderLayer,self).__init__()#解码器层包含自注意力机制、编码器-解码器注意力机制和前馈神经网络self.self_attn=MultiHeadAttention(d_model,n_heads)self.enc_attn=MultiHeadAttention(d_model,n_heads)self.feedforward =Feedforward(d_model,d_ff, dropout)self.norm1= nn.LayerNorm(d_model)self.norm2= nn.LayerNorm(d_model)self.norm3= nn.LayerNorm(d_model)self.dropout = nn.Dropout(dropout)def forward(self,x,enc_output, self_mask, context_mask):#自注意力机制attn_output=self.self_attn(x,x,x,self_mask)x=x+ self.dropout(attn_output)x= self.norm1(x)#编码器-解码器注意力机制attn_output = self.enc_attn(x,enc_output, enc_output, context_mask)x=x+ self.dropout(attn_output)x= self.norm2(x)#前馈神经网络ff_output = self.feedforward(x)x=x+ self.dropout(ff_output)x= self.norm3(x)return x8.Transformer模型构建
class Transformer(nn.Module):def __init__ (self, vocab_size, d_model, n_heads,n_encoder_layers, n_decoder_layers,d_ff, dropout=0.1):super(Transformer,self).__init__()# Transformer 模型包含词嵌入、位置编码、编码器和解码器self.embedding=nn.Embedding(vocab_size,d_model)self.positional_encoding= PositionalEncoding(d_model, dropout)self.encoder_layers = nn.ModuleList([EncoderLayer(d_model,n_heads,d_ff, dropout) for _ in range(n_encoder_layers)])self.decoder_layers = nn.ModuleList([DecoderLayer(d_model,n_heads, d_ff, dropout) for _ in range(n_decoder_layers)]) self.fc_out = nn.Linear(d_model,vocab_size)self.dropout = nn.Dropout(dropout)def forward(self,src,trg,src_mask, trg_mask):#词嵌入和位置编码src=self.embedding(src)src=self.positional_encoding(src)trg= self.embedding(trg)trg=self.positional_encoding(trg)#编码器for layer in self.encoder_layers :src=layer(src,src_mask)# 解码器for layer in self.decoder_layers:trg =layer(trg,src,trg_mask,src_mask)#输出层output = self.fc_out(trg)return output9.输出模型结构
#使用示例
vocab_size =10000 #假设词汇表大小为10000
d_model=512
n_heads=8
n_encoder_layers=6
n_decoder_layers=6
d_ff = 2048
dropout =0.1transformer_model = Transformer(vocab_size, d_model, n_heads, n_encoder_layers, n_decoder_layers, d_ff, dropout)#定义输入,这里的输入是假设的,需要根据实际情况修改
src=torch.randint(0,vocab_size,(32,10)) #源语言句子
trg=torch.randint(0,vocab_size,(32,20)) #目标语言句子#掩码,用于屏蔽填充的位置
src_mask=(src !=0).unsqueeze(1).unsqueeze(2)
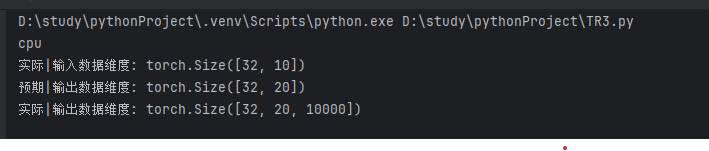
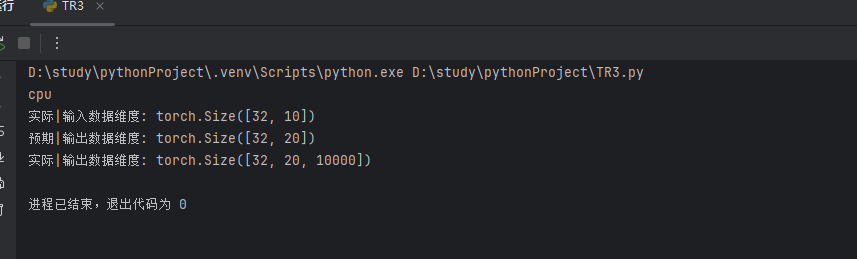
trg_mask =(trg !=0).unsqueeze(1).unsqueeze(2) #掩码,用于屏蔽填充的位置print("实际|输入数据维度:",src.shape)
print("预期|输出数据维度:",trg.shape)
output =transformer_model(src,trg,src_mask,trg_mask)
print("实际|输出数据维度:",output.shape)输出结果:
四、总结
Transformer要比RNN、CNN这种传统网络难懂很多,学起来压力很大,但自己论文也是与此相关,需要不断地看和理解。整个框架逻辑比较清晰,但具体的细节还需要再研究。Transformer模型主要由编码器和解码器组成,它们由自注意力层和全连接前馈网络组成。它使用注意力机制来捕捉输入序列中不同位置之间的依赖关系,同时通过多头注意力来提高模型的表达能力。