Mysql表的增删改查(进阶)

目录
一.数据库约束
1. 主键约束
2. 外键约束
3.唯一约束
4.非空约束
5.默认约束
6.检查约束(了解)
二.表的设计
1. 一对一 (One-to-One)
2. 一对多 (One-to-Many)
3. 多对多 (Many-to-Many)
4.总结对比表
三.数据库表的查询(聚合,多表查询)
1. 聚合查询
2. 分组查询
3. 联合查询
3.1 内连接
3.2 外连接
3.3 自连接
3.4 子查询
3.5 合并查询
一.数据库约束
约束的作用,以及为什么需要约束:
| 约束类型 | 作用 | 为什么需要约束 |
|---|---|---|
| 主键约束 (PRIMARY KEY) | 唯一标识表中的每条记录,确保实体完整性 | 防止数据重复,确保每条记录可唯一标识(如身份证号),支持高效查询和表关联 |
| 外键约束 (FOREIGN KEY) | 维护表之间的关联关系,确保引用完整性 | 防止"孤儿记录"(如订单关联不存在的用户),强制数据一致性,实现级联更新/删除 |
| 唯一约束 (UNIQUE) | 保证列中所有值都不重复(除NULL外) | 避免重复数据(如邮箱/手机号),支持业务唯一性要求,与主键互补(允许多个唯一列) |
| 非空约束 (NOT NULL) | 强制列不能接受NULL值 | 确保关键数据必填(如用户名/价格),防止数据缺失导致业务逻辑错误 |
| 检查约束 (CHECK) | 验证列值满足指定条件(如年龄>0) | 强制业务规则(如库存不能为负),过滤无效数据,保证数据质量 |
| 默认约束 (DEFAULT) | 当插入数据未指定值时自动填充预设值 | 简化数据插入(如自动填充创建时间),确保基础数据完整,减少应用层代码 |
1. 主键约束
语法格式:字段名 字段类型 primary key
创建一个带主键的表
#三种方式
#方式一
create table emp{id int primary key,name varchar(20),sex char(1)
};#方式二
create table emp{id int,name varchar(20),sex char(1),primary key(id)
};#方式三
create table emp{id int,name varchar(20),sex char(1)
};
#创建的时候不指定主键,然后通过 DDL语句进行设置
alter table emp add primary key(id);
删除主键约束
alter table emp drop primary key;主键的自增
关键字:auto_increment 表示自动增长(字段类型必须是整数类型)
注: 主键如果让我们自己添加很有可能重复,我们通常希望在每次插入新记录时,数据库自动生成主键字段 的值.
创建一个主键自增的表 并写出测试代码
create table emp(-- 关键字 AUTO_INCREMENT,主键类型必须是整数类型id int primary key auto_increment,name varchar(20),sex char(1)
);
#测试数据
INSERT INTO emp(ename,sex) VALUES('张三','男');
INSERT INTO emp(ename,sex) VALUES('李四','男');
INSERT INTO emp VALUES(NULL,'翠花','女');
INSERT INTO emp VALUES(NULL,'艳秋','女');
修改主键自增的起始值 默认地 AUTO_INCREMENT 的开始值是 1,如果希望修改起始值,请使用下面的方式:
create table emp(-- 关键字 AUTO_INCREMENT,主键类型必须是整数类型id int primary key auto_increment,name varchar(20),sex char(1)
)AUTO_INCREMENT=100;DELETE和TRUNCATE对自增长的影响
删除表中所有数据有两种方式
| 清空表数据的方式 | 特点 |
| DELETE | 只是删除表中所有数据,对自增没有影响 |
| TRUNCATE | truncate 是将整个表删除掉,然后创建一个新的表 自增的主键,重新从 1开始 |
2. 外键约束
外键约束一般是在多表关联的时候使用,并且使用外键约束可以让两张表之间产生一个对应关系,什么意思呢!比如:一张员工表emp,一张部门表dept。需要查询每个员工所对应的部门信息,因为两表有了外键约束,两表之间产生了一个对应关系,通过对应关系,就能同时查询两张表中的信息
如何使用外键约束?
1.新建表时添加外键:
语法格式:[CONSTRAINT] [外键约束名称] FOREIGN KEY(外键字段名) REFERENCES 主表名(主键字段名)
2.已有表时添加外键:
语法格式:ALTER TABLE 从表 ADD [CONSTRAINT] [外键约束名称] FOREIGN KEY (外键字段名) REFERENCES 主表(主 键字段名)
创建一张员工表emp并创建与部门表相对应的外键,在创建一张部门表dept
#部门表
create table dept{id int primary key auto_increment,name varchar(20),location varchar(20)
};#员工表
create table emp {id int primary key auto_increment,name varchar(20),age int,#外键dept_id int,#外键约束foreign key(dept_id) references dept(id)};1.观察上面代码,在创建员工表的时候同时创建了外键字段dept_id,外键字段的作用就是用来与部门表产生关联的主要桥梁,在进行外键约束的时候我们会通过外键字段与关联表的主键字段进行相匹配,最终产生关联关系.
2.拥有外键约束的表的被称为从表,与拥有外键约束的相关联的表被称为主表。
3.员工表在添加数据的时候,外键字段一定要与主表中的相关联字段合适匹配,不能写主表中字段不匹配的信息。
4.当出现错误匹配时,拥有外键约束的字段会报错。
5.在添加数据时应先添加主表中的数据,再添加从表中的数据。当表中的信息添加有误时,应先调整或删除从表中的数据,再调整或删除主表中的数据
3.唯一约束
唯一约束的特点: 表中的某一列的值不能重复( 对null不做唯一的判断 )
语法格式:字段名 字段值 unique
创建员工表,并把name字段设置为唯一约束
create table emp{id int priamry key auto_increment,name varchar(20) unique,age int
};主键约束与唯一约束的区别:
1. 主键约束 唯一且不能够为空
2. 唯一约束,唯一 但是可以为空
3. 一个表中只能有一个主键 , 但是可以有多个唯一约束
4.非空约束
非空约束的特点: 某一列不予许为空
语法格式:字段名 字段类型 not null
创建员工表,并把name字段设置为非空约束
create table emp{id int priamry key auto_increment,name varchar(20) not null,age int
};
5.默认约束
默认值约束 用来指定某列的默认值
语法格式:字段名 字段类型 DEFAULT 默认值
创建员工表,并让age默认为25
create table emp{id int priamry key auto_increment,name varchar(20) not null,age int default '25'
};6.检查约束(了解)
判断输入值,是否为固定的字段信息
语法格式:check 字段名 = 判定条件
创建员工表,并判断年龄是否等于25
create table emp{id int priamry key auto_increment,name varchar(20) not null,age int default '25',check age = '25'
};二.表的设计
1. 一对一 (One-to-One)
-
关系描述: 表A中的一条记录,在表B中最多只能找到一条记录与之对应;反之亦然(表B中的一条记录,在表A中也最多只能找到一条记录与之对应)。
-
生活化比喻: 就像一个人和他的身份证号。一个人只能有一个身份证号,一个身份证号也只对应一个人。
-
表设计:
-
常见方式1 (外键 + 唯一约束):
-
创建两张表(例如
Users用户表和UserProfiles用户详情表)。 -
在其中一张表(通常是子表/从表,如
UserProfiles)中添加一个指向另一张表(主表,如Users)主键的外键字段(例如user_id)。 -
关键点: 给这个外键字段 (
user_id) 添加 唯一约束 (UNIQUE Constraint)。这确保了UserProfiles表中的每条记录只能关联到Users表中的一个用户,实现了“一对一”。
-
-
常见方式2 (合并表): 如果两个实体的信息紧密相关且经常一起查询,有时也可以直接合并成一张大表。但这不是严格的“表间关系”设计。
-
表关系图示:
-

-
1.UserProfiles.user_id是外键 (FK),指向Users.user_id。 -
2.UserProfiles.user_id有 UNIQUE 约束,确保每个用户只有一个详情记录。 -
3.用户 Alice (
Users.user_id = 1) 只对应一个详情记录 (UserProfiles.user_id = 1)。 -
4.详情记录 101 只对应一个用户 (
Users.user_id = 1)。
2. 一对多 (One-to-Many)
-
关系描述: 表A中的一条记录,在表B中可以找到多条记录与之对应;但表B中的一条记录,在表A中只能找到一条记录与之对应。
-
生活化比喻: 就像一个班级 (表A) 和它的学生 (表B)。一个班级可以有多名学生,但一名学生只能属于一个班级。
-
表设计:
-
创建两张表(例如
Departments部门表和Employees员工表)。 -
在“多”的那张表 (
Employees) 中添加一个指向“一”的那张表 (Departments) 主键的外键字段(例如department_id)。 -
关键点: 这个外键字段 (
department_id) 不需要唯一约束。它允许多条员工记录指向同一个部门ID。
-
-
表关系图示:

-
1.Employees.department_id是外键,指向Departments.dept_id。 -
2.部门 Sales (
dept_id=10) 有多条员工记录与之对应 (Alice, Bob)。 -
3.员工 Alice (
emp_id=1001) 只属于一个部门 (dept_id=10)。
3. 多对多 (Many-to-Many)
-
关系描述: 表A中的一条记录,在表B中可以找到多条记录与之对应;同时,表B中的一条记录,在表A中也可以找到多条记录与之对应。
-
生活化比喻: 就像学生 (表A) 和课程 (表B)。一个学生可以选择多门课程,一门课程也可以被多个学生选修。
-
表设计:
-
创建两张主表(例如
Students学生表和Courses课程表)。 -
关键点: 必须创建第三张表(关联表 / 连接表) (例如
Enrollments选课表) 来建立这种关系。 -
关联表 (
Enrollments) 通常至少包含两个字段:-
一个指向表A (
Students) 主键的外键字段 (例如student_id)。 -
一个指向表B (
Courses) 主键的外键字段 (例如course_id)。
-
-
关联表的主键 (Primary Key) 通常是这两个外键字段的组合 (
student_id, course_id)。这确保了同一个学生不能重复选同一门课(或者根据业务需求,可能需要添加其他字段如选课时间等)。
-
-
表关系图示:
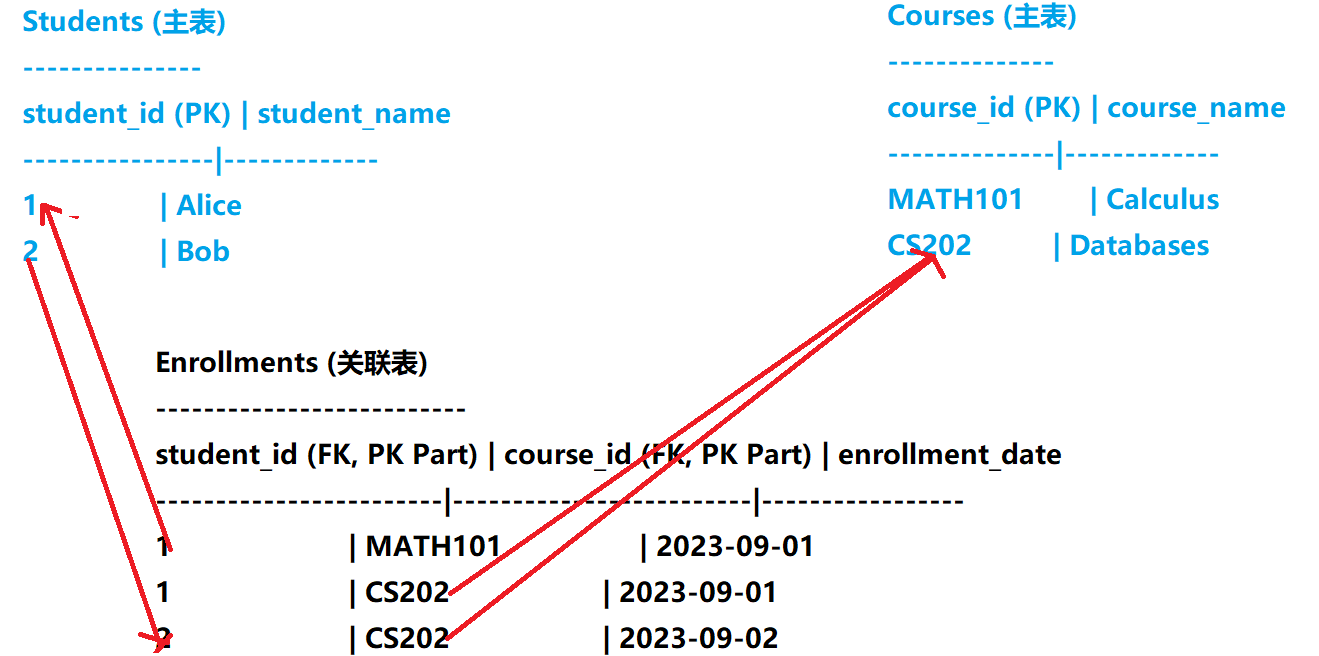
-
1.Enrollments.student_id是外键 ,指向Students.student_id。 -
2.Enrollments.course_id是外键 ,指向Courses.course_id。 -
3.主键 (PK) 是
(student_id, course_id)的组合(这里假设一个学生不能重复选同一门课)。 -
关系体现:
-
学生 Alice (
student_id=1) 选修了多门课程 (MATH101,CS202)。 -
课程 Databases (
CS202) 被多名学生选修 (Alice, Bob)。
-
4.总结对比表
| 关系类型 | 描述 (表A vs 表B) | 设计关键点 | 常见例子 |
|---|---|---|---|
| 一对一 (1:1) | A的一条记录 <=> B的至多一条记录 | 在任一表加指向另一表主键的外键 + 唯一约束 | 用户 - 用户详情 / 人 - 身份证号 |
| 一对多 (1:N) | A的一条记录 <=> B的多条记录 B的一条记录 <=> A的一条记录 | 在“多”方表 (B) 加指向“一”方表 (A) 主键的外键 (不加唯一约束) | 部门 - 员工 / 班级 - 学生 / 订单 - 订单项 |
| 多对多 (M:N) | A的一条记录 <=> B的多条记录 B的一条记录 <=> A的多条记录 | 必须创建关联表,包含两个外键 (分别指向A和B的主键),通常这两外键组合作为关联表的主键 | 学生 - 课程 / 用户 - 角色 / 产品 - 订单 |
核心:外键 (Foreign Key) 是建立表之间关系的最基本桥梁,而 关联表 (Junction Table) 是解决多对多关系的标准方案。
三.数据库表的查询(聚合,多表查询)
1. 聚合查询
之前我们做的查询都是横向查询,它们都是根据条件一行一行的进行判断,而使用聚合函数查询是纵 向查询,它是对某一列的值进行计算,然后返回一个单一的值(另外聚合函数会忽略null空值。在此我们学习常用的聚合函数:
聚合函数作用详解表
| 函数 | 作用描述 | 特点说明 | 示例场景 |
|---|---|---|---|
| COUNT(字段) | 统计指定列不为NULL的记录行数 | 忽略NULL值; 统计非空数据行数 | 统计有邮箱注册的用户数量 |
| SUM(字段) | 计算指定列的数值总和 | 仅适用于数值类型; 忽略NULL值 | 计算销售总额/库存总量 |
| MAX(字段) | 获取指定列的最大值 | 适用于数值、日期、字符串; 在文本中返回字典序最大值 | 查找最高分/最新订单日期 |
| MIN(字段) | 获取指定列的最小值 | 适用于数值、日期、字符串; 在文本中返回字典序最小值 | 查找最低温度/最早入职日期 |
| AVG(字段) | 计算指定列的平均值 | 仅适用于数值类型; 自动忽略NULL值; 等价于SUM(字段)/COUNT(字段) | 计算平均工资/产品平均评分 |
语法格式:select 聚合函数(字段名) from 表名;
数据准备
-- 创建一张学生表
DROP TABLE IF EXISTS student;
CREATE TABLE student (id INT,sn INT comment '学号',name VARCHAR(20) comment '姓名',qq_mail VARCHAR(20) comment 'QQ邮箱'
);
-- 插入两条记录,value_list 数量必须和定义表的列的数量及顺序一致
INSERT INTO student VALUES (100, 10000, '唐三藏', NULL);
INSERT INTO student VALUES (101, 10001, '孙悟空', '11111');-- 创建考试成绩表
DROP TABLE IF EXISTS exam_result;
CREATE TABLE exam_result (
id INT,
name VARCHAR(20),
chinese DECIMAL(3,1),
math DECIMAL(3,1),
english DECIMAL(3,1)
);
-- 插入测试数据
INSERT INTO exam_result (id,name, chinese, math, english) VALUES
(1,'唐三藏', 67, 98, 56),
(2,'孙悟空', 87.5, 78, 77),
(3,'猪悟能', 88, 98.5, 90),
(4,'曹孟德', 82, 84, 67),
(5,'刘玄德', 55.5, 85, 45),
(6,'孙权', 70, 73, 78.5),
(7,'宋公明', 75, 65, 30);count:
统计班级共有多少同学
select count(*) from student;统计班级收集的 qq_mail 有多少个,qq_mail 为 NULL 的数据不会计入结果
select count(qq_mail) from student;
sum:
统计数学成绩总分
select sum(math) from exam_reuslt;avg:
统计平均总分
select avg(chinese + english + math) from exam_result;max:
返回英语最高分
select max(english) from exam_result;min:
返回 > 70 分以上的数学最低分
select min(english) from exam_result where english > 70;2. 分组查询
1.分组查询指的是使用 GROUP BY 语句,对查询的信息进行分组,相同数据作为一组
2.GROUP BY 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 WHERE 语句,而需要用HAVING
语法格式:SELECT 分组字段/聚合函数 FROM 表名 GROUP BY 分组字段 [HAVING 条件];
数据准备
create table emp(
id int primary key auto_increment,
name varchar(20) not null,
role varchar(20) not null,
salary numeric(11,2)
);
insert into emp(name, role, salary) values
('马云','服务员', 1000.20),
('马化腾','游戏陪玩', 2000.99),
('孙悟空','游戏角色', 999.11),
('猪无能','游戏角色', 333.5),
('沙和尚','游戏角色', 700.33),
('隔壁老王','董事长', 12000.66);查询每个角色的最高工资、最低工资和平均工资
select role,max(salary),min(salary),avg(salary) from emp group by role;显示平均工资低于1500的角色和它的平均工资
select role,avg(salary) from emp group by role having avg(salary) < 1500;where 和 having 的区别
| 过滤方式 | 特点 |
| where | where 进行分组前的过滤 where 后面不能写 聚合函数 |
| having | having 是分组后的过滤 having 后面可以写 聚合函数 |
3. 联合查询
多表查询:即在n张表中查询的信息汇集成一列数据呈现。
数据准备
#创建班级表
CREATE TABLE classes (
id INT PRIMARY KEY auto_increment,
name VARCHAR(20),
`desc` VARCHAR(100)
);
#创建学生表
CREATE TABLE student (id INT PRIMARY KEY auto_increment,sn INT UNIQUE,name VARCHAR(20) DEFAULT 'unkown',qq_mail VARCHAR(20),
classes_id int,
FOREIGN KEY (classes_id) REFERENCES classes(id)
);
#创建课程表
CREATE TABLE course (id INT PRIMARY KEY auto_increment,name VARCHAR(20)
);
#创建成绩表
创建课程学生中间表:考试成绩表
CREATE TABLE score (id INT PRIMARY KEY auto_increment,
score DECIMAL(3, 1),student_id int,
course_id int,
FOREIGN KEY (student_id) REFERENCES student(id),
FOREIGN KEY (course_id) REFERENCES course(id)
);insert into classes(name, `desc`) values
('计算机系2019级1班', '学习了计算机原理、C和Java语言、数据结构和算法'),
('中文系2019级3班','学习了中国传统文学'),
('自动化2019级5班','学习了机械自动化');
insert into student(sn, name, qq_mail, classes_id) values
('09982','黑旋风李逵','xuanfeng@qq.com',1),
('00835','菩提老祖',null,1),
('00391','白素贞',null,1),
('00031','许仙','xuxian@qq.com',1),
('00054','不想毕业',null,1),
('51234','好好说话','say@qq.com',2),
('83223','tellme',null,2),
('09527','老外学中文','foreigner@qq.com',2);
insert into course(name) values
('Java'),('中国传统文化'),('计算机原理'),('语文'),('高阶数学'),('英文');
insert into score(score, student_id, course_id) values
-- 黑旋风李逵
(70.5, 1, 1),(98.5, 1, 3),(33, 1, 5),(98, 1, 6),
-- 菩提老祖
(60, 2, 1),(59.5, 2, 5),
-- 白素贞
(33, 3, 1),(68, 3, 3),(99, 3, 5),
-- 许仙
(67, 4, 1),(23, 4, 3),(56, 4, 5),(72, 4, 6),
-- 不想毕业
(81, 5, 1),(37, 5, 5),
-- 好好说话
(56, 6, 2),(43, 6, 4),(79, 6, 6),
-- tellme
(80, 7, 2),(92, 7, 6);
3.1 内连接
隐式内连接
from子句 后面直接写 多个表名 使用where指定连接条件的 这种连接方式是 隐式内连接. 使用where条件过滤无用的数据
语法格式:SELECT 字段名 FROM 左表 别名, 右表 别名 WHERE 连接条件;
查询所有同学的成绩
select sco.score from student stu,score sc where stu.id = sc.student_id;显示内连接(常用)
使用 inner join ...on 这种方式, 就是显式内连接
语法格式:select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件;
-- inner 可以省略
查询“许仙”同学的 成绩
select sco.score from student stu join score sco on stu.id=sco.student_id
and stu.name='许仙';查询所有同学的总成绩,及同学的个人信息
seelct stu.sn,stu.name,stu.qq_mail,sum( sco.score )
from student stu join score sco on stu.id = sco.student_id group by sco.student_id;查询所有同学的成绩,及同学的个人信息
select stu.id, stu.sn, stu.name, stu.qq_mail, sco.score, sco.course_id, cou.name
from student stu join score sco on stu.id = sco.student_id join course cou on sco.course_id = cou.id order by stu.id;此时结果中是没有“老外学中文”同学的信息的,该如何解决。
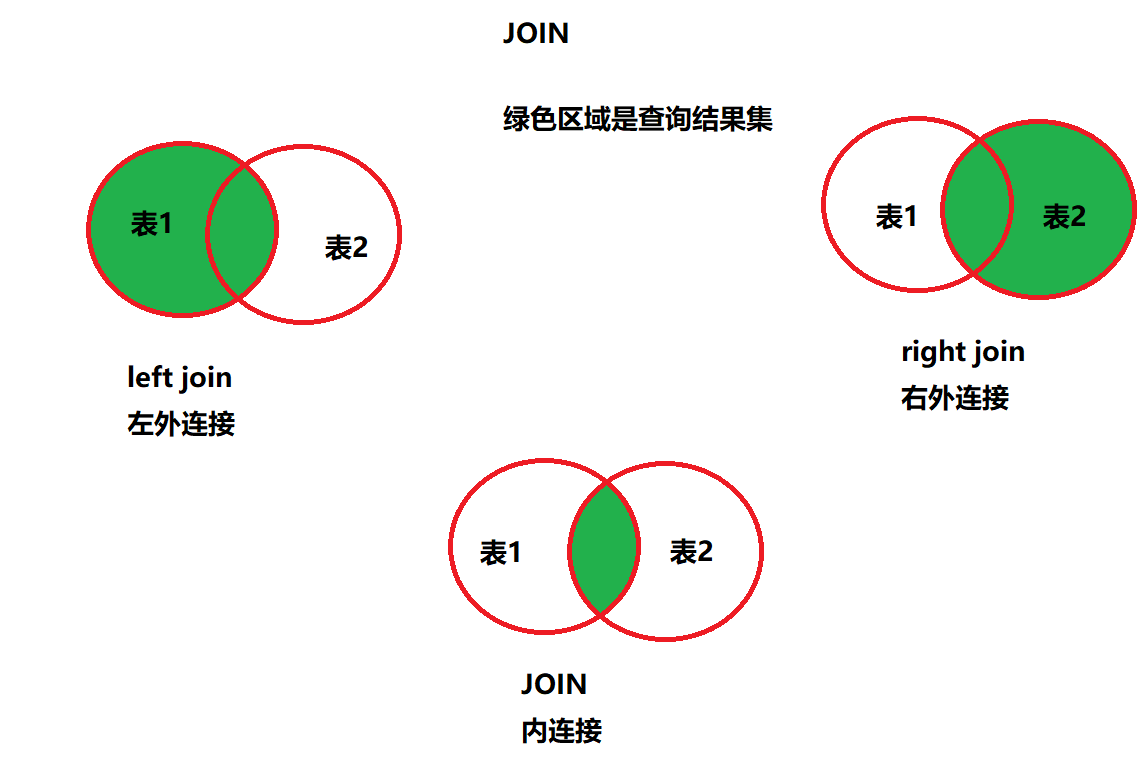
内连接: inner join , 只获取两张表中 交集部分的数据.
左外连接: left join , 以左表为基准 ,查询左表的所有数据, 以及与右表有交集的部分
右外连接: right join , 以右表为基准,查询右表的所有的数据,以及与左表有交集的部分
3.2 外连接
左外连接
左外连接 , 使用 LEFT OUTER JOIN , OUTER 可以省略
左外连接的特点 :
以左表为基准, 匹配右边表中的数据,如果匹配的上,就展示匹配到的数据
如果匹配不到, 左表中的数据正常展示, 右边的展示为null.
语法格式:select 字段名 from 表名1 left join 表名2 on 连接条件;
查询所有同学的成绩,及同学的个人信息,如果该同学没有成绩,也需要显示
右外连接
右外连接 , 使用 RIGHT OUTER JOIN , OUTER 可以省略
右外连接的特点
以右表为基准,匹配左边表中的数据,如果能匹配到,展示匹配到的数据
如果匹配不到,右表中的数据正常展示, 左边展示为null
语法格式:select 字段 from 表名1 right join 表名2 on 连接条件;
SELECT
stu.id,
stu.sn,
stu.NAME,
stu.qq_mail,
sco.score,
sco.course_id,
cou.NAME
FROM
student stu
LEFT JOIN score sco ON stu.id = sco.student_id
LEFT JOIN course cou ON sco.course_id = cou.id
ORDER BY
stu.id;使用左外连接就能解决查询到“老外学中文”同学的信息
3.3 自连接
自连接是指在同一张表连接自身进行查询。
显示所有“计算机原理”成绩比“Java”成绩高的成绩信息
SELECT
stu.*,
s1.score Java,
s2.score 计算机原理
FROM
score s1
JOIN score s2 ON s1.student_id = s2.student_id
JOIN student stu ON s1.student_id = stu.id
JOIN course c1 ON s1.course_id = c1.id
JOIN course c2 ON s2.course_id = c2.id
AND s1.score < s2.score
AND c1.NAME = 'Java'
AND c2.NAME = '计算机原理';3.4 子查询
什么是子查询:
子查询概念
一条select 查询语句的结果, 作为另一条 select 语句的一部分
子查询的特点
子查询必须放在小括号中
子查询一般作为父查询的查询条件使用
子查询常见分类
where型 子查询: 将子查询的结果, 作为父查询的比较条件
from型 子查询 : 将子查询的结果, 作为 一张表,提供给父层查询使用
exists型 子查询: 子查询的结果是单列多行, 类似一个数组, 父层查询使用 IN 函数 ,包含子查 询的结果
语法格式:SELECT 查询字段 FROM 表 WHERE 字段=(子查询);
子查询结果作为条件查询
#查询与“不想毕业” 同学的同班同学
select * from student where classes_id=(select classes_id from student where
name='不想毕业');子查询结果是单列多行
#查询“语文”或“英文”课程的成绩信息
--使用IN
select * from score where course_id in (select id from course where
name='语文' or name='英文');
-- 使用 NOT IN
select * from score where course_id not in (select id from course where
name!='语文' and name!='英文');-- 使用 EXISTS
select * from score sco where exists (select sco.id from course cou
where (name='语文' or name='英文') and cou.id = sco.course_id);
-- 使用 NOT EXISTS
select * from score sco where not exists (select sco.id from course cou
where (name!='语文' and name!='英文') and cou.id = sco.course_id);子查询作为表返回查询
#查询所有比“中文系2019级3班”平均分高的成绩信息
SELECT
*
from
score sco,
(
select
avg( sco.score ) score
from
score sco
join student stu on sco.student_id = stu.id
JOIN classes cls on stu.classes_id = cls.id
where cls.name = '中文系2019级3班'
) tmp
where
sco.score > tmp.score;3.5 合并查询
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all。使用UNION和UNION ALL时,前后查询的结果集中,字段需要一致。
union:
该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行。union all:
该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行。
--union 查询id小于3,或者名字为“英文”的课程select * from course where id<3
union
select * from course where name='英文';--union all 查询id小于3,或者名字为“Java”的课程
-- 可以看到结果集中出现重复数据Java
select * from course where id<3
union all
select * from course where name='英文';SQL查询中各个关键字的执行先后顺序: from > on> join > where > group by > with > having >select > distinct > order by > limit.
下一个内容会学习到索引,事务,以及事务中产生的脏读,幻读,不可重复读问题。上面的知识点有错误的地方,还需要大家共同指出,一起进步!!!!
完结撒花!拜拜!!!!
