SeeMoE:从零开始实现一个MoE视觉语言模型
\(\leftleftarrows\) 返回文章列表
SeeMoE:从零开始实现一个MoE视觉语言模型
这篇博客介绍了如何使用纯PyTorch实现一个由图像编码器、多模态投影模块和混合专家解码器语言模型组成的专家混合视觉语言模型。该实现可以被认为是Grok 1.5 Vision和GPT-4 Vision的缩小版本(两者都有通过投影模块连接到MoE解码器模型的视觉编码器)。名称"seeMoE"是对Andrej Karpathy的项目"makemore"的致敬,因为这里使用的解码器实现了一个字符级自回归语言模型,非常类似于他在nanoGPT/makemore中的实现,但有一个关键区别:它是一个混合专家解码器(非常类似于DBRX、Mixtral和Grok)。目标是提供一个直观的理解,展示这种看似先进的实现如何工作,以便进行改进或使用关键要点构建更有用的系统。
完整的实现可以在以下仓库的seeMoE_from_Scratch.ipynb中找到:https://github.com/AviSoori1x/seemore
本质上,实现过程是将解码器中每个transformer块的前馈神经网络替换为一个带有噪声Top-K门控的专家混合模块。关于实现细节的更多信息:https://huggingface.co/blog/AviSoori1x/makemoe-from-scratch。
强烈建议在深入研究之前先阅读这两篇博客,并仔细浏览链接到这两个博客的仓库。
在"seeMoE"中,混合专家视觉语言模型(VLM)的简单实现包含3个主要组件。
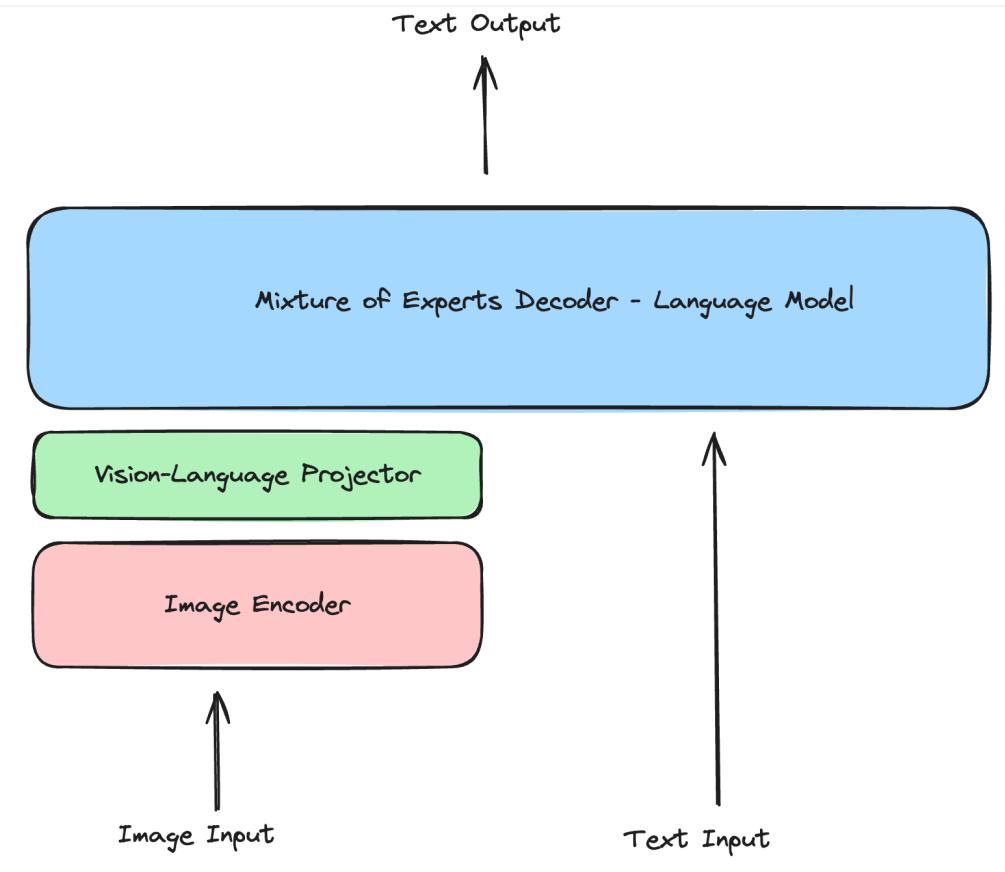
图像编码器用于从图像中提取视觉特征。在这种情况下,使用了一个从零开始实现的CLIP中使用的原始视觉transformer。这实际上是许多现代VLM中的流行选择。一个值得注意的例外是Adept的Fuyu系列模型,它将patchified图像直接传递给投影层。
视觉-语言投影器 - 图像嵌入与解码器使用的文本嵌入形状不同。因此需要"投影",即改变图像编码器提取的图像特征的维度,以匹配文本嵌入空间中观察到的内容。这样图像特征就成为了解码器的"视觉标记"。这可以是单层或MLP。这里使用了MLP,因为它值得展示。
具有专家混合架构的仅解码器语言模型。这是最终生成文本的组件。在实现中,在LLaVA的基础上做了一些改变,将投影模块合并到解码器中。通常不会观察到这种情况,解码器(通常是已经预训练的模型)的架构会保持不变。这里最大的变化是,如前所述,每个transformer块中的前馈神经网络/MLP被替换为一个专家混合块,带有噪声top-k门控机制。基本上每个标记(文本标记+已被映射到与文本标记相同嵌入空间的视觉标记)在每个transformer块中只被n个专家中的top-k个处理。因此,如果它是一个有8个专家和top 2门控的MoE架构,只有2个专家会被激活。
由于图像编码器和视觉语言投影器与seemore(上面链接,仓库在这里:https://github.com/AviSoori1x/seemore)中的保持不变,建议阅读博客/浏览笔记本以了解这些细节。
现在重新审视稀疏专家混合模块的组件:
- 专家 - 只是n个普通MLP
- 门控/路由机制
- 基于路由机制的激活专家的加权求和
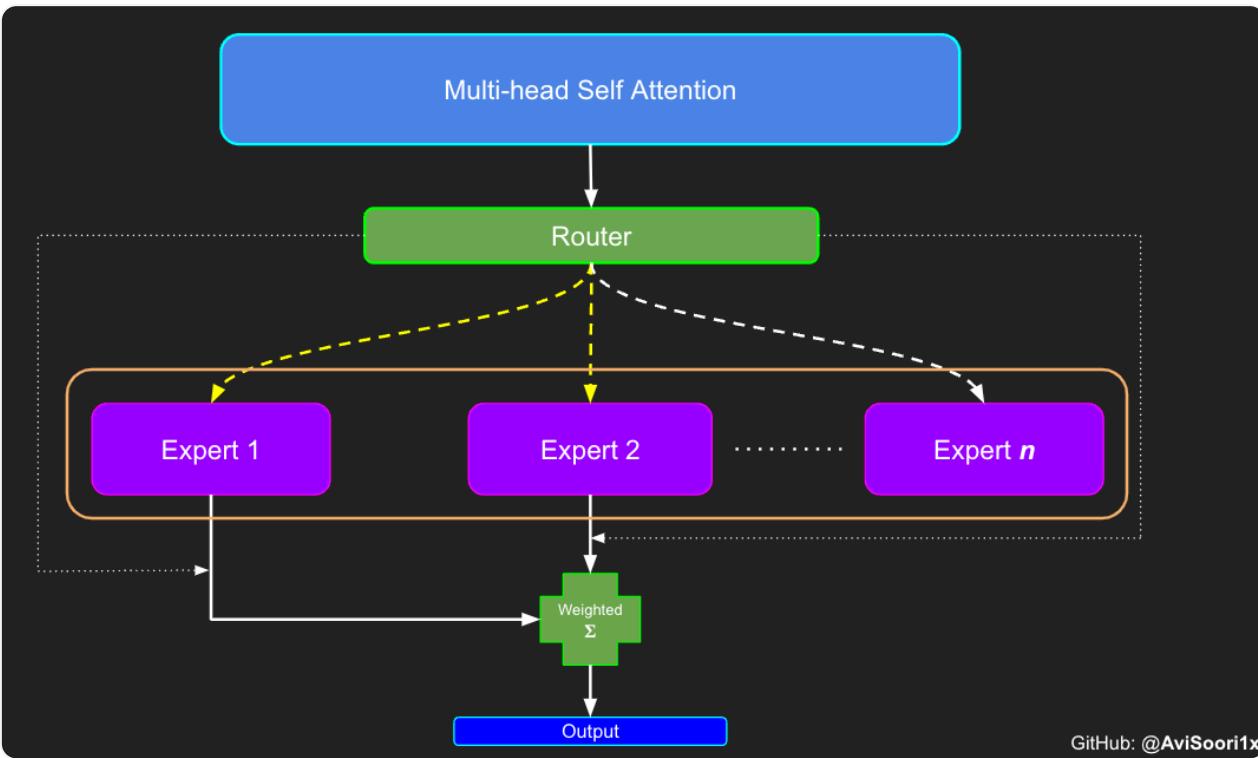
首先是"专家",它就像之前实现编码器时看到的MLP一样。
# 专家模块
class Expert(nn.Module):def __init__(self, n_embed):super().__init__()self.net = nn.Sequential(nn.Linear(n_embed, 4 * n_embed),nn.ReLU(),nn.Linear(4 * n_embed, n_embed),nn.Dropout(dropout),)def forward(self, x):return self.net(x)
路由模块决定哪些专家将被激活。噪声top k门控/路由添加了一点高斯噪声,以确保在选择每个标记的top-k专家时在探索和利用之间有一个很好的平衡。这减少了每次都选择相同的n个专家的可能性,这违背了拥有更大参数计数和稀疏激活以获得更好泛化能力的目的。
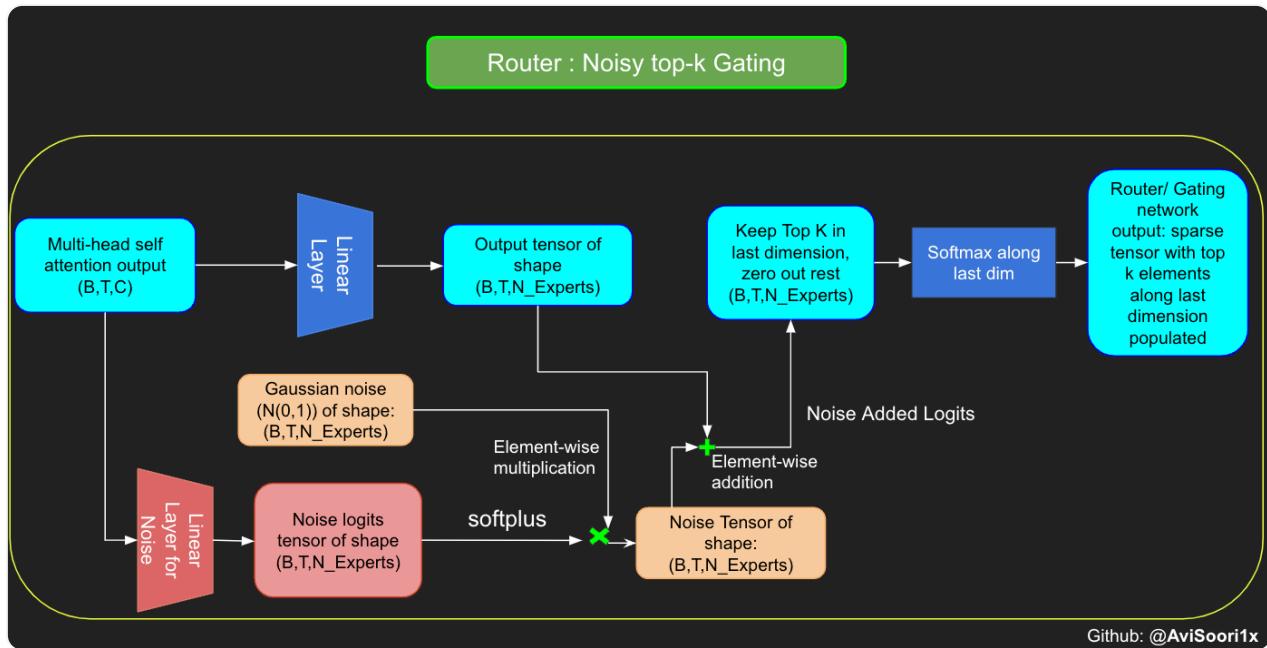
# 噪声top-k门控
class NoisyTopkRouter(nn.Module):def __init__(self, n_embed, num_experts, top_k):super(NoisyTopkRouter, self).__init__()self.top_k = top_k# 路由器logits的层self.topkroute_linear = nn.Linear(n_embed, num_experts)self.noise_linear = nn.Linear(n_embed, num_experts)def forward(self, mh_output):# mh_output是多线程自注意力的输出张量logits = self.topkroute_linear(mh_output)# 噪声logitsnoise_logits = self.noise_linear(mh_output)# 向logits添加缩放单位高斯噪声noise = torch.randn_like(logits) * F.softplus(noise_logits