Prometheus-1--什么是Prometheus?
Prometheus是一个开源的系统监控和告警工具,广泛用于云原生环境中的指标采集、存储和可视化,逐渐成为现代监控领域的标杆工具。
最初由SoundCloud公司开发,后来成为独立项目并广泛流行。它专为云原生环境和微服务架构设计,支持高维数据模型和灵活的查询语言(PromQL),是CNCF(云原生计算基金会)的孵化项目之一。
1、核心特点
1、多维数据模型
使用指标名称 + 标签(key/value)唯一标识时间序列数据。
2、灵活的查询语言(PromQL)
- 支持对时间序列数据进行聚合、过滤、计算等复杂操作。
- 例如:rate(http_requests_total[5m]) 计算每秒请求数。
3、拉取(Pull)模式采集数据
- Prometheus Server主动从目标(如Exporter)拉取指标,而非被动接收。
- 支持服务发现(如Kubernetes、Consul)动态发现监控目标。
4、独立性
- 无需依赖外部存储,本地存储时间序列数据(默认保留15天)。
- 支持远程存储(如 Thanos、VictoriaMetrics)扩展数据保留。
5、强大的告警系统
通过Alertmanager管理告警规则,支持去重、分组、路由到多种通知渠道(如邮件、Slack、钉钉)。
6、丰富的可视化工具
- 原生Web UI支持基础查询和图表展示。
- 与Grafana集成可创建复杂仪表盘。
2、架构组成
典型架构图:
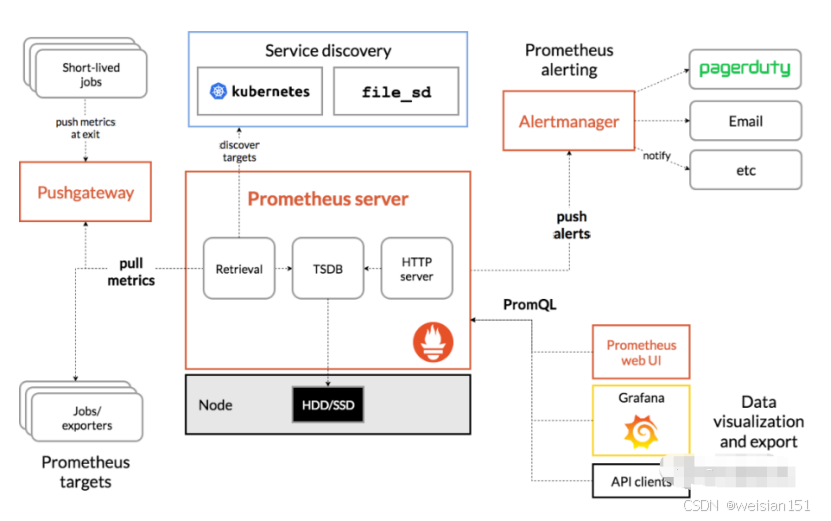
1、Prometheus Server
Prometheus Server是核心组件,负责抓取指标数据、存储指标数据、查询指标数据,配置和触发报警等。
功能包含:
- 指标抓取:通过HTTP协议定期从配置的目标(如Exporter、应用、节点等)的/metrics接口拉取指标数据。
- 存储指标数据:将抓取到的指标数据存储在本地的时间序列数据库(TSDB)中。
- 评估规则(Rules):
- 记录规则(Recording Rules):预计算复杂查询,提高查询效率。
- 告警规则(Alerting Rules):定义何时触发告警。
- 提供查询接口:通过内置的PromQL查询语言,对外提供查询接口(如/api/v1/query)。
- 转发告警:当告警规则被触发时,将告警信息发送给Alertmanager。
2、Exporters
Prometheus本身不直接采集指标,而是通过Exporter来暴露各种系统的指标。Exporter是一个独立运行的服务,包含各类中间件、系统、应用的指标采集器,暴露/metrics接口,Prometheus Server可通过/metrics接口获取检测目标的指标数据。
主要功能包含:
- 采集目标系统的指标(如Redis、MySQL、Java应用、服务器硬件等)。
- 将这些指标转换为Prometheus可识别的格式。
- 暴露/metrics接口供Prometheus Server抓取。
常见Exporter:
- node_exporter(主机资源)
- mysqld_exporter(MySQL)
- redis_exporter(Redis)
- blackbox_exporter(黑盒探测)
- cadvisor(容器指标)
- 自定义Exporter(如Java应用集成Prometheus客户端库)
3、Pushgateway(临时上报指标)
Prometheus采用Pull模式抓取数据,这在大多数场景下非常合适。但对于一些短生命周期的任务(比如定时脚本、CI任务等),它们无法等待Prometheus来抓取,因此可以主动将指标推送到Pushgateway,供Prometheus后续抓取。
主要作用:
- 用于短时任务(如CronJob)推送指标到Prometheus。
- Prometheus Server从Pushgateway拉取数据。
注意:
Pushgateway不推荐用于长期运行的服务,容易造成数据混乱。
Pushgateway支持临时任务或短生命周期任务主动推送指标。
4、Alertmanager
Prometheus Server只负责判断是否触发告警,真正的告警处理是由Alertmanager来完成的。
主要功能包括:
- 分组(Grouping):将相似的告警合并,减少通知数量。
- 抑制(Inhibition):在某些告警触发时,抑制其他相关告警的通知。
- 去重(Deduplication):避免重复通知。
- 路由(Routing):根据告警标签将告警信息路由到不同的接收方(如邮件、Slack、钉钉、Webhook等)。
5、可视化工具
Prometheus自带了一个简单的图形界面用于查询和展示时间序列数据,但大多数用户会结合Grafana等可视化工具,创建更美观、交互性更强的仪表盘(Dashboard)来展示监控数据。
包含:
- Prometheus Web UI:基础查询和图表。
- Grafana:支持多数据源(Prometheus、MySQL、Elasticsearch等)的复杂仪表盘。
3、工作原理
Prometheus的核心原理可以概括为**“拉取数据 + 多维存储 + 灵活查询”**。
原理概述:
1、Prometheus Server定期从配置的目标(Exporter、Pushgateway、应用等)的/metrics接口拉取指标数据。
2、拉取到的数据被存储在本地的时间序列数据库中。
3、Prometheus根据配置的规则进行评估:
- 如果是记录规则,则生成新的时间序列。
- 如果是告警规则,则判断是否触发告警。
4、如果触发告警,Prometheus会将告警发送给Alertmanager。
5、Alertmanager对告警进行分组、抑制、去重后,将通知发送给指定的接收方(如邮箱、Slack、钉钉等)。
6、用户可以通过Prometheus自带的UI或Grafana查询数据、查看图表、设置告警。
1、Pull模式(拉取模式)
Prometheus采用HTTP协议定期从目标服务中拉取数据,而不是传统的Push(推送)模式。这意味着Prometheus主动去“问”每个目标系统:“你现在有什么指标?”
目标发现:
- Prometheus Server根据配置文件prometheus.yml中的scrape_configs定义的目标(如localhost:9090/metrics)定期拉取数据。
- 支持静态配置(手动指定目标)和动态服务发现(如Kubernetes、Consul、DNS等)。
HTTP请求:
-
Prometheus通过HTTP协议定期(默认1分钟)向目标端点的/metrics接口发起请求,获取指标数据。
-
目标端点可以是:
- 服务自身暴露的指标(如Java服务集成Prometheus客户端库)。
- Exporter(如Node Exporter、Redis Exporter)。
-
Pushgateway(用于短生命周期任务,如CronJob)。
-
优点:架构简单、易于维护、服务端无需维护连接。
-
缺点:不适用于短生命周期任务(如定时脚本)。
2、暴露/metrics接口
被监控的服务需要通过HTTP暴露一个/metrics接口,返回Prometheus可识别的文本格式指标数据。
3、时间序列数据库(TSDB)
Prometheus将采集到的时间序列指标数据存储在本地磁盘的TSDB中,默认保留15天。数据按时间分块存储,并采用高效的压缩算法(如Gorilla TSDB的压缩算法)。数据结构支持多维标签(labels),便于灵活查询和聚合。
Prometheus的监控模型的三个核心概念:
- 时间序列(Time Series):每个指标是一个时间序列,由一个时间戳和一个数值组成
- 指标名称(Metric Name):如http_requests_total,表示某种行为的度量
- 标签(Labels):用于对指标进行多维度分类,如{method=“GET”, status=“200”}
4、PromQL查询语言
Prometheus提供了一种强大的查询语言PromQL(Prometheus Query Language),可以进行时间序列的筛选、聚合、计算、函数操作等。
promql示例:
-- 计算过去5分钟内HTTP请求的平均速率
rate(http_requests_total[5m])-- 监控服务实例的CPU使用率
node_cpu_seconds_total{mode!="idle"}
4、适用场景
(1)、服务器监控:CPU、内存、磁盘、网络等硬件指标(通过Node Exporter)。
示例指标:
- 服务器CPU使用率(如node_cpu_seconds_total)。
- 内存占用(如node_memory_MemAvailable_bytes)。
- 磁盘I/O(如node_disk_io_time_seconds_total)。
- 网络延迟(如node_network_receive_bytes_total)。
实现方式:
- 使用Exporter(如Node Exporter、MySQL Exporter)收集基础设施指标,并暴露/metrics接口。
- Kubernetes环境中,可通过kube-state-metrics监控集群状态。
(2)、应用监控
在Java、Go、Python等应用中集成Prometheus客户端库。如:接口调用次数、延迟、错误率(通过应用内埋点或Sidecar)。
示例指标:
- HTTP请求延迟(如http_request_latency_seconds)。
- 接口调用次数(如http_requests_total)。
- 服务错误率(如errors_total)。
- 自定义业务指标(如订单处理量、用户登录次数)。
实现方式:
- 在服务中集成Prometheus客户端库(如prometheus/client_golang),暴露/metrics接口。
- 或使用Sidecar模式(如Envoy代理)捕获服务流量并生成指标。
(3)、中间件监控
使用各类Exporter(如Redis Exporter、MySQL Exporter)检测连接数、查询性能等。
(4)、容器和Kubernetes监控
节点资源、Pod状态、容器指标(通过kube-state-metrics和cAdvisor)。
(5)、日志和调用链监控
需结合Loki(日志)、Tempo(调用链)实现全栈观测。
5、指标类型
Prometheus支持以下四种核心指标类型。
1、Counter(计数器)
单调递增的计数器,用于统计某些总数类型的指标,重启后重置。如:请求总数、错误数。
- 示例:http_requests_total(累计HTTP请求次数)。
2、Gauge(仪表盘)
可增可减的数值,用于表示当前状态。如:内存使用、并发请求数。
- 示例:node_memory_MemFree_bytes(当前空闲内存)。
3、Histogram(直方图)
统计值的分布情况(如响应时间)。如:接口延迟。
- 示例:http_request_latency_seconds_bucket(延迟分桶统计)。
4、Summary(摘要)
类似Histogram,但更适用于精确的分位数计算。如:上传大小、下载速度。
- 示例:http_request_latency_seconds(分位数统计)。
5、Untyped(未定义类型)
未指定类型的指标,用于兼容旧系统,也可以由用户自定义指标。
6、安装与配置示例
(1)、安装Prometheus
- Docker安装
bash示例:
docker run -d -p 9090:9090 prom/prometheus
- Linux原生安装
bash示例:
# 下载二进制包
wget https://github.com/prometheus/prometheus/releases/download/v2.51.0/prometheus-2.51.0.linux-amd64.tar.gz
# 解压
tar xvfz prometheus-*.tar.gz
进入目录
cd prometheus-*
# 启动
./prometheus --config.file=prometheus.yml
(2)、配置文件prometheus.yml
yaml示例:
global:scrape_interval: 15s # 抓取间隔scrape_configs:- job_name: "prometheus"static_configs:- targets: ["localhost:9090"] # 监控自身- job_name: "node-exporter"static_configs:- targets: ["localhost:9100"] # 监控服务器硬件
解释:
scrape_configs指定要prometheus server定时监测的任务信息。如果还有其他监控配置,在依次添加。
(3)、启动Node Exporter
用于监控服务器的相关指标。
bash示例:
docker run -d -p 9100:9100 \-v "/proc:/host/proc" \-v "/sys:/host/sys" \-v "/:/rootfs" \quay.io/prometheus/node-exporter
7、常用查询示例(PromQL)
promql示例:
# CPU使用率
rate(node_cpu_seconds_total{mode!="idle"}[1m])# 内存使用率
(node_memory_MemTotal_bytes - node_memory_MemFree_bytes) / node_memory_MemTotal_bytes# HTTP请求延迟(95%分位)
histogram_quantile(0.95, sum(rate(http_request_latency_seconds_bucket[5m])) by (le, job))# QPS(每秒请求数)
rate(http_requests_total[1m])
8、告警配置
在prometheus.yml中引用告警规则文件。
yaml示例:
rule_files:- alert.rules.yml
告警规则示例(alert.rules.yml):
yaml示例:
groups:- name: instance-healthrules:- alert: HighCpuUsageexpr: rate(node_cpu_seconds_total{mode!="idle"}[5m]) > 0.8for: 2mlabels:severity: warningannotations:summary: "CPU 使用率过高"description: "实例 {{ $labels.instance }} 的 CPU 使用率超过 80% (当前值: {{ $value }}%)"
9、可视化与告警通知
Grafana集成:
1、安装Grafana:docker run -d -p 3000:3000 grafana/grafana
2、添加Prometheus数据源(URL: http://prometheus:9090)
3、导入预定义仪表盘(如Node Exporter Full、JVM Micrometer)。
告警通知:
配置Alertmanager将告警发送到Slack、邮件或钉钉机器人。例如:
yaml示例:
receivers:- name: slackslack_configs:- api_url: https://hooks.slack.com/services/XXX/XXXchannel: "alerts"
10、优势与局限性
优势:
- 简单易用:独立部署,无需依赖复杂外部存储。
- 强大的查询语言:PromQL支持灵活的聚合和计算。
- 社区生态丰富:数百种Exporter和集成工具。
- 实时监控:秒级采集和告警延迟。
局限性:
- 不适合高精度日志或事件监控(需结合ELK或Loki)。
- 本地存储容量有限(需远程存储扩展)。
- 无法直接采集非时间序列数据(如调用链)。
11、Prometheus生态工具
- Prometheus Server:核心监控服务。
- Alertmanager:告警管理。
- Pushgateway:短任务指标推送。
- Grafana:可视化。
- Node Exporter:Linux主机指标采集。
- Blackbox Exporter:黑盒探测(HTTP、TCP、ICMP)。
- JMX Exporter:Java应用指标采集。
- cAdvisor:容器指标采集。
- kube-state-metrics:Kubernetes状态指标采集。
- VictoriaMetrics:高性能Prometheus兼容存储。
- Thanos:支持长期存储和全局视图的扩展组件。
- Prometheus Operator:Kubernetes上自动化部署Prometheus的工具。
12、总结一句话
Prometheus是一个强大的开源监控系统,采用Pull模式采集指标,支持多维数据模型和灵活查询语言PromQL,适用于云原生和微服务架构,通过丰富的Exporter和生态工具,能够构建完整的监控、告警和可视化体系。
向阳前行,Dare To Be!!!