第一章 绪论
第一章 绪论:机器学习概述与分类
一、机器学习概述
1. 为什么要“机器学习”?

2. 什么是机器学习?
机器学习(Machine Learning)是人工智能(AI)的核心分支领域,它赋予计算机系统从数据中"学习"并改进的能力,而无需显式编程。1959年,Arthur Samuel将机器学习定义为"赋予计算机无需明确编程就能学习的能力的研究领域"。

3. 机器学习的本质
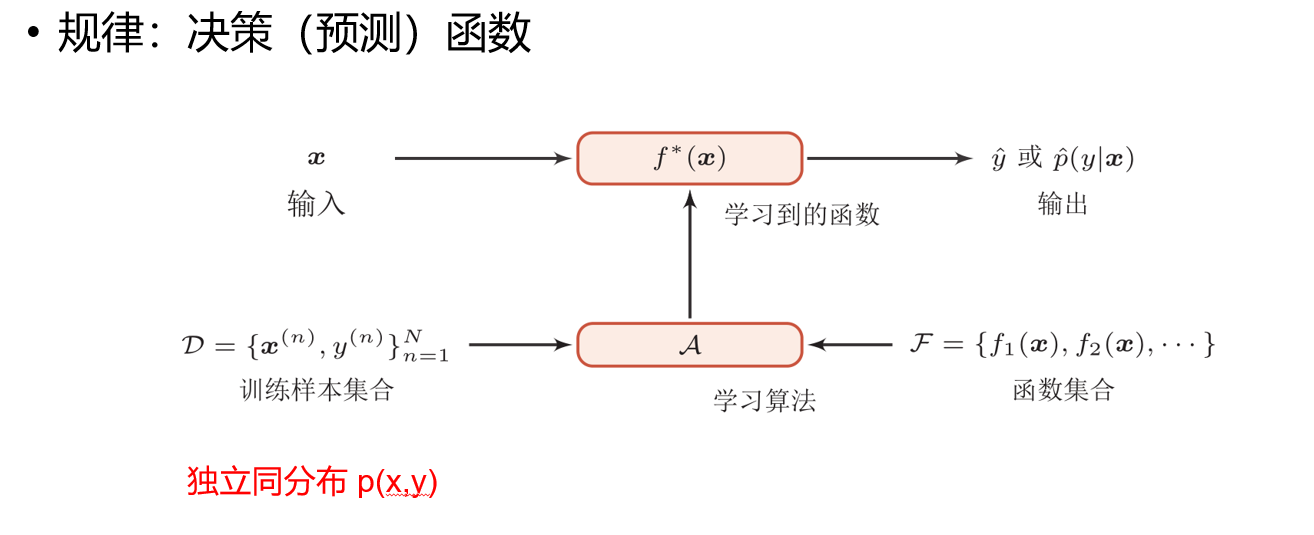
机器学习的核心在于通过算法解析数据,从中学习模式,然后对真实世界中的事件做出决策或预测。与传统编程不同,在机器学习中,我们不是直接告诉计算机如何完成任务,而是"教"计算机如何从数据中学习完成任务。
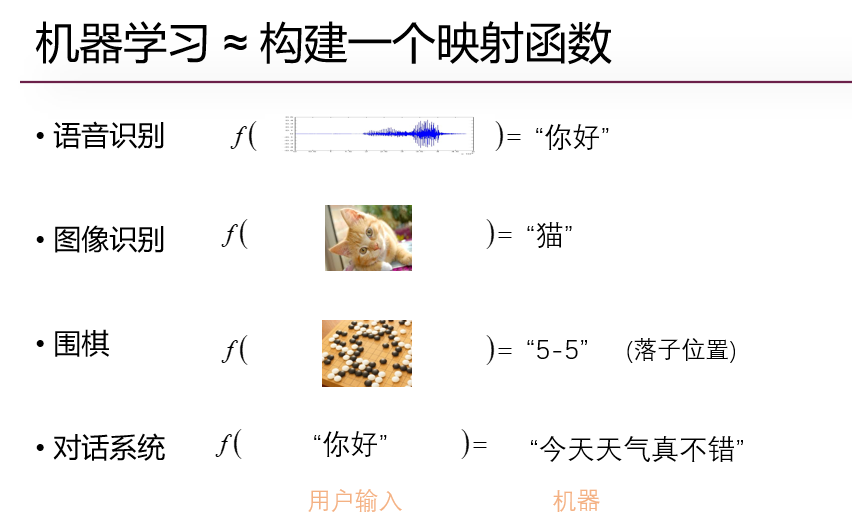
4. 机器学习的发展历史
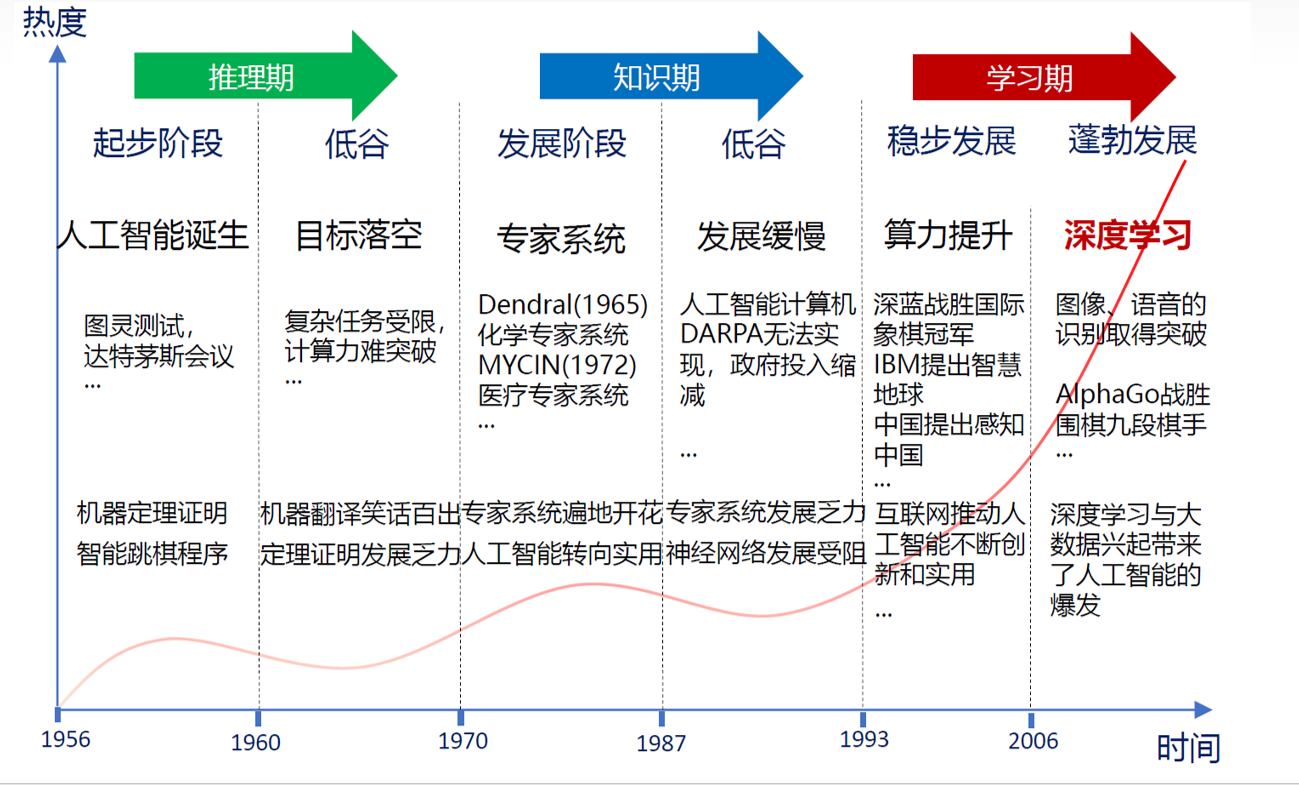
5. 机器学习的应用领域
机器学习已广泛应用于各个领域:
- 自然语言处理:机器翻译、情感分析

- 推荐系统:电商推荐、内容推荐

- 医疗诊断:疾病预测、医学影像分析

- 金融科技:信用评分、欺诈检测

- 自动驾驶:环境感知、路径规划

二、机器学习的分类
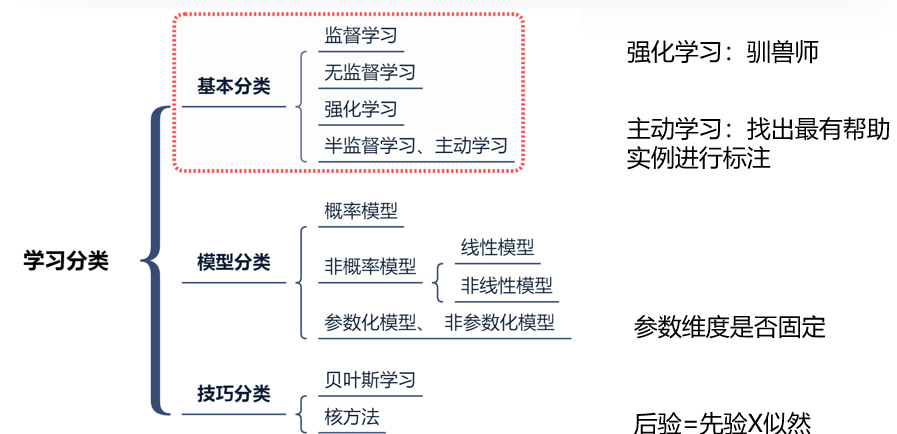
(一)基本分类
1. 监督学习(Supervised Learning)

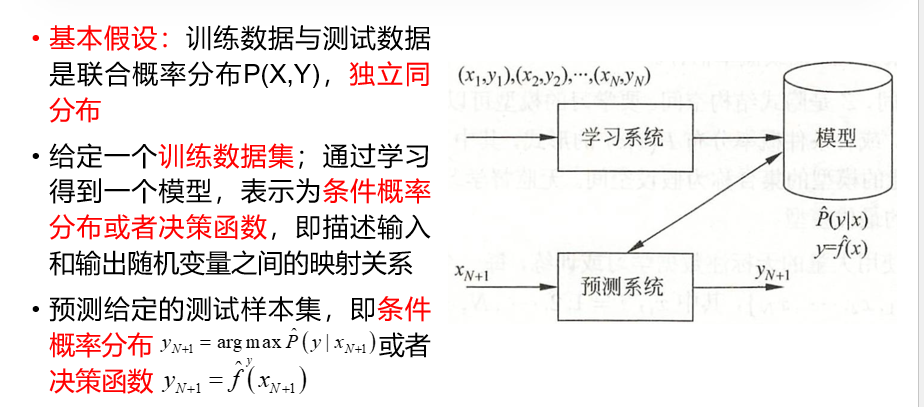
监督学习是最常见的机器学习类型,其特点是训练数据包含输入和对应的期望输出(标签)。算法通过学习输入与输出之间的映射关系,对新的输入数据做出预测。
详细分类:
- 分类问题:输出为离散类别
- 二分类:垃圾邮件检测、疾病诊断
- 多分类:手写数字识别、图像分类
- 回归问题:输出为连续值
- 线性回归:房价预测
- 非线性回归:股票价格预测
典型算法:
- 传统方法:K近邻(KNN)、朴素贝叶斯、决策树
- 统计方法:支持向量机(SVM)、逻辑回归
- 集成方法:随机森林、梯度提升树(GBDT)
- 深度方法:全连接神经网络、卷积神经网络(CNN)
应用场景:
- 自然语言处理:文本分类、情感分析
- 计算机视觉:目标检测、人脸识别
- 金融领域:信用评分、欺诈检测
2. 无监督学习(Unsupervised Learning)
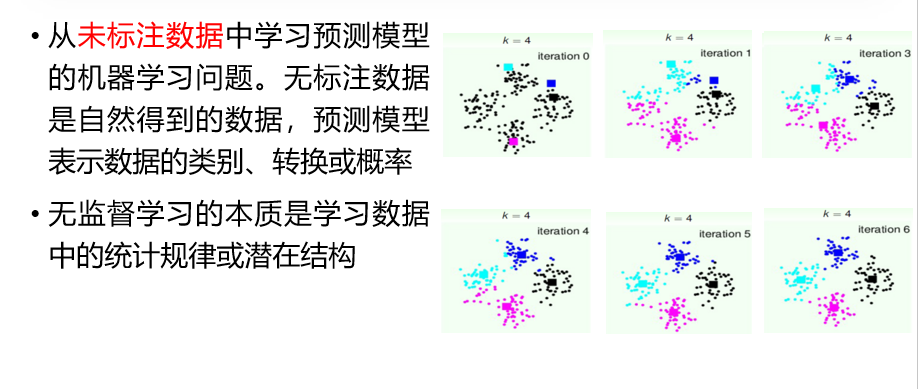
无监督学习的训练数据没有标签,系统试图从数据中发现隐藏的模式或结构。
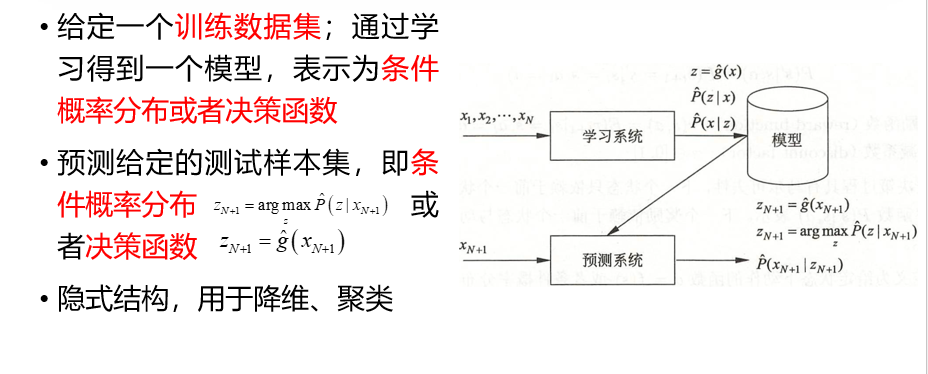
-
详细分类:
- 聚类分析:将相似样本分组
- 划分方法:K-means、K-medoids
- 层次方法:凝聚式、分裂式
- 密度方法:DBSCAN、OPTICS
- 降维技术:减少特征维度
- 线性方法:主成分分析(PCA)、线性判别分析(LDA)
- 非线性方法:t-SNE、UMAP
- 关联规则:发现项目间关系
- Apriori算法
- FP-growth算法
典型算法:
- 聚类:高斯混合模型(GMM)、谱聚类
- 降维:独立成分分析(ICA)、因子分析
- 生成模型:生成对抗网络(GAN)、变分自编码器(VAE)
应用场景:
- 市场细分:客户分群
- 异常检测:网络入侵识别
- 推荐系统:用户行为分析
- 聚类分析:将相似样本分组
3. 强化学习(Reinforcement Learning)
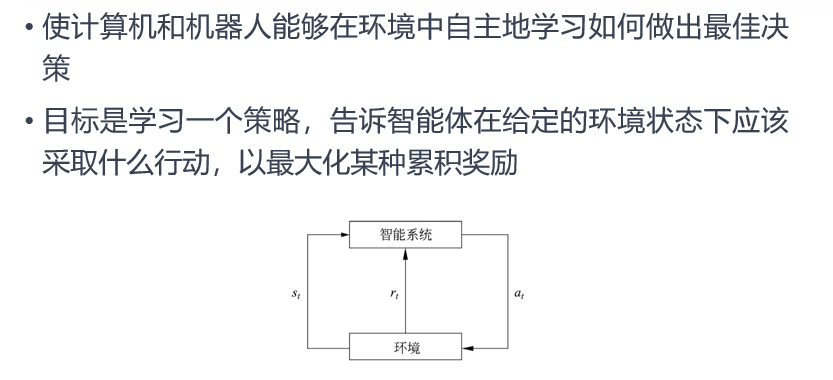
通过与环境交互学习最优策略,以获得最大化的累积奖励。
核心要素:
- 智能体(Agent):学习主体
- 环境(Environment):智能体交互的外部系统
- 状态(State):环境的当前状况
- 动作(Action):智能体的行为
- 奖励(Reward):环境对动作的反馈
详细分类:
- 基于值的方法:学习价值函数
- Q-learning
- Deep Q Network(DQN)
- 基于策略的方法:直接优化策略
- REINFORCE
- 策略梯度(Policy Gradient)
- 演员-评论家方法:结合值和策略
- A3C
- SAC
典型算法:
- 时序差分:SARSA
- 蒙特卡洛方法
- 逆向强化学习
应用场景:
- 游戏AI:AlphaGo、星际争霸AI
- 机器人控制:机械臂操作
- 自动驾驶:路径规划
4. 半监督学习(Semi-supervised Learning)与主动学习
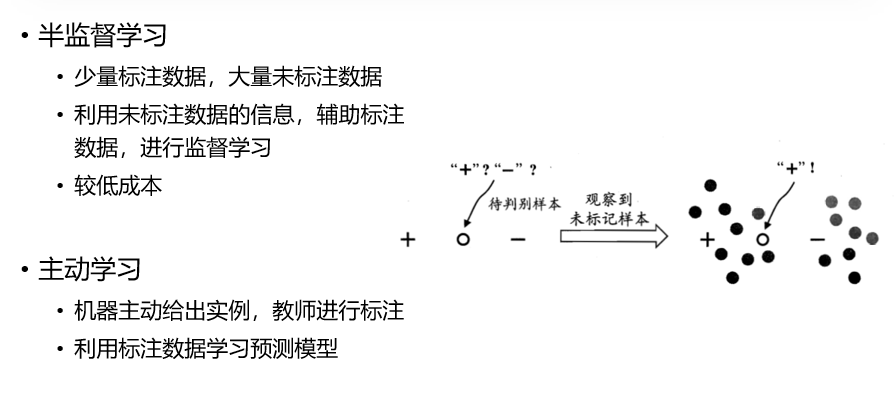
半监督学习:
- 特点:结合少量标注数据和大量未标注数据
- 方法分类:
- 自训练(Self-training)
- 协同训练(Co-training)
- 图半监督学习(标签传播)
- 应用场景:医学影像分析、语音识别
主动学习:
- 特点:系统主动选择最有价值的样本进行标注
- 查询策略:
- 不确定性采样
- 查询委员会
- 期望模型变化
- 应用场景:文本分类、蛋白质结构预测
(二)模型分类维度
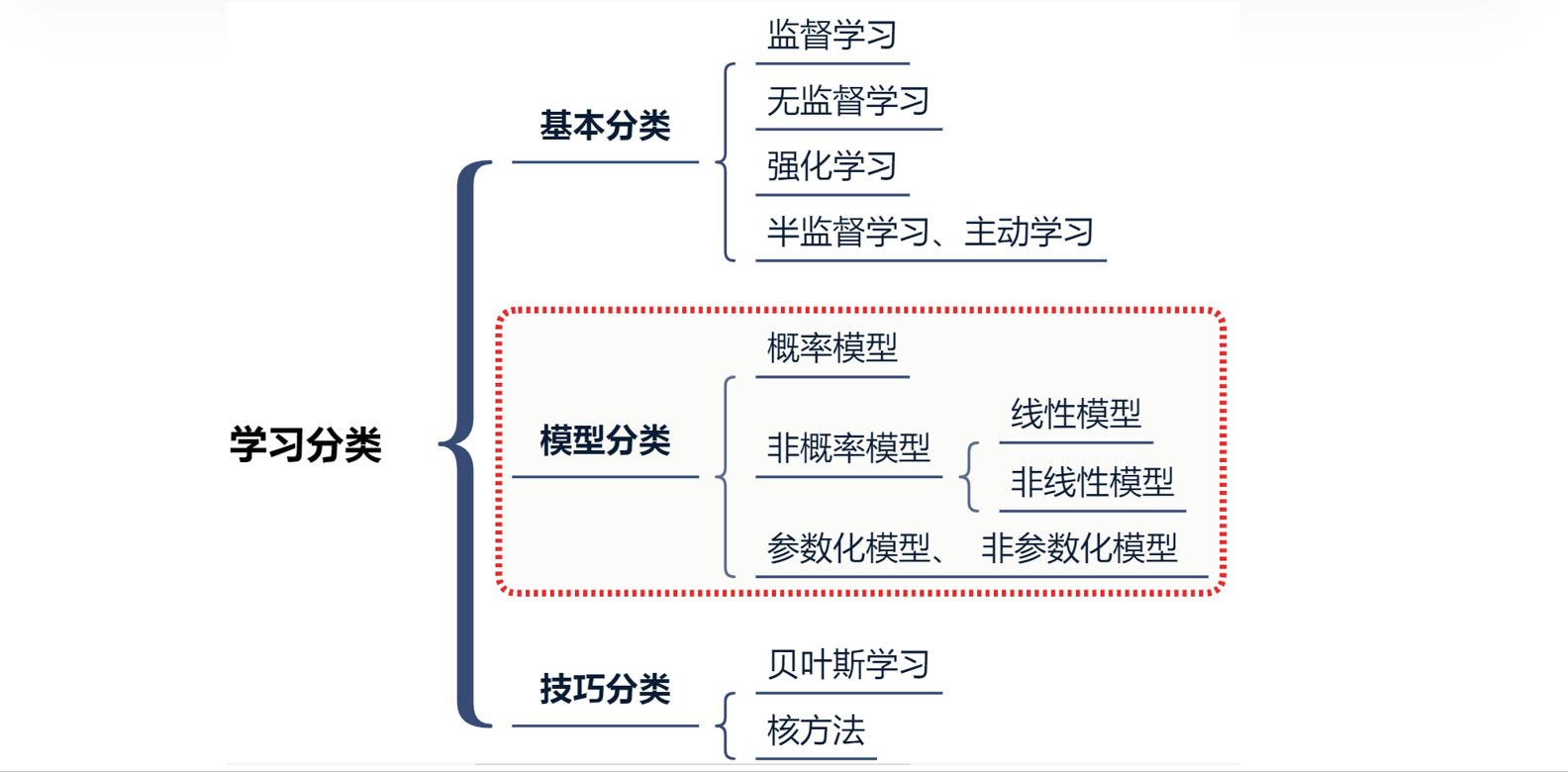
1. 概率模型
定义与特点:
基于概率论框架,建立数据的概率分布模型。
详细分类:
- 生成模型:建模联合分布P(X,Y)
- 朴素贝叶斯
- 隐马尔可夫模型(HMM)
- 贝叶斯网络
- 判别模型:建模条件分布P(Y|X)
- 逻辑回归
- 条件随机场(CRF)
典型方法:
- 贝叶斯方法:贝叶斯线性回归
- 概率图模型:马尔可夫随机场
- 深度生成模型:变分自编码器
优势与局限:
- 优势:提供不确定性估计、可解释性强
- 局限:计算复杂度高、对分布假设敏感
2. 非概率模型
定义与特点:
不依赖概率框架,直接学习输入到输出的映射关系。
2.1 线性模型
- 基本形式:y = wᵀx + b
- 典型算法:
- 感知机
- 线性判别分析
- 特点:简单高效但表达能力有限
2.2 非线性模型
- 典型代表:
- 决策树:ID3、C4.5、CART
- 支持向量机(核方法)
- 神经网络:MLP、CNN、RNN
- 特点:能拟合复杂模式但可能过拟合
3. 参数化与非参数化模型
参数化模型:
- 特点:固定数量参数,假设数据分布形式
- 代表方法:
- 线性回归
- 逻辑回归
- 优势:计算高效、样本需求少
非参数化模型:
- 特点:参数数量随数据增长,无强分布假设
- 代表方法:
- K近邻(KNN)
- 高斯过程
- 决策树
- 优势:灵活性强、适应复杂分布
(三)技巧分类维度
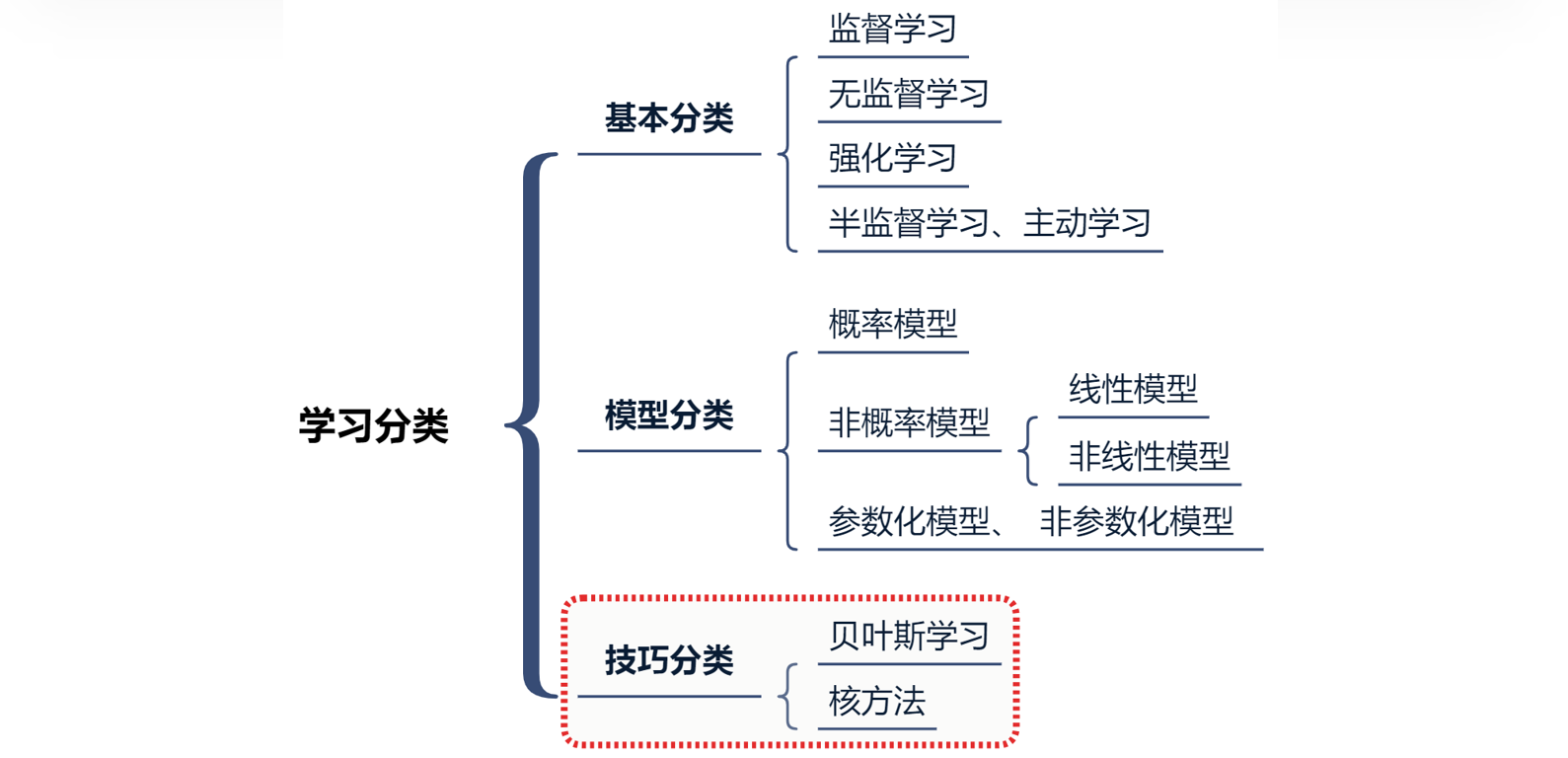
1. 贝叶斯学习

核心思想:
基于贝叶斯定理,将先验知识与观测数据结合得到后验分布。
关键方法:
- 贝叶斯推断:
- 最大后验估计(MAP)
- 贝叶斯网络
- 近似推断:
- 马尔可夫链蒙特卡洛(MCMC)
- 变分推断(VI)
应用场景:
- 垃圾邮件过滤
- 医学诊断
- 推荐系统
2. 核方法

核心思想:
通过核函数将数据隐式映射到高维特征空间,在高维空间中解决线性问题。
关键技术:
- 核函数类型:
- 线性核
- 多项式核
- 高斯核(RBF)
- Sigmoid核
- 核技巧应用:
- 支持向量机(SVM)
- 核主成分分析(KPCA)
- 核岭回归
优势与局限:
- 优势:有效处理非线性、维度灾难问题
- 局限:核选择困难、大规模数据计算成本高
小结
-
在机器学习中,可根据是否包含数据标签而被分为监督学习和无监督学习,有时也会包括半监督学习、主动学习和强化学习。
-
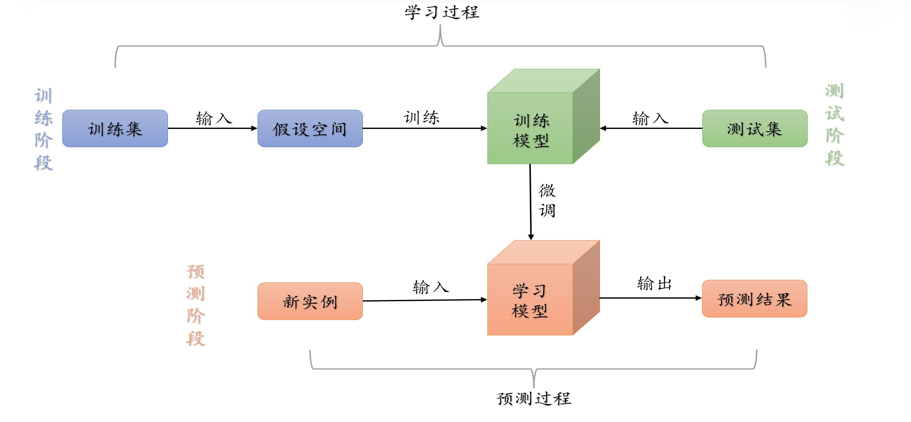
监督学习是指从标注数据中学习预测模型的机器学习问题,学习输 入输出之间对应关系,预测给定的输入产生相应的输出。监督学习 过程包含三部曲:训练阶段、测试阶段和预测阶段。训练阶段和测试阶段组成学习过程,两个阶段有时可以合二为一。
机器学习作为人工智能的重要支柱,正在深刻改变我们解决问题的方式。理解机器学习的基本概念和分类体系,是深入这一领域的第一步。在接下来的章节中,我们将详细探讨各类机器学习算法的原理、实现和应用。