MySql多表查询完全指南:从基础概念到实战应用
一、多表查询简介
1.1 什么是多表查询
多表查询是指在 SQL 查询中同时操作两个或多个数据库表,通过表之间的关联关系获取整合数据的技术。在实际业务场景中,数据通常分散在多个表中,例如用户信息、用户行为、商品信息等,多表查询是整合这些数据的核心手段。

1.2 多表查询的重要性
- 数据完整性:获取单一表无法提供的关联信息(如用户及其发布的文章)
- 业务分析需求:支持复杂业务场景(如统计用户活跃度、分析订单关联商品)
- 数据建模优化:避免单表数据冗余,符合数据库设计范式
1.3 核心挑战:笛卡尔积问题
笛卡尔积是多表查询中最常见的陷阱,当未指定表关联条件时,查询结果会是两张表行数的乘积(如 A 表 10 行,B 表 20 行,笛卡尔积结果为 200 行)。
示例:错误查询导致笛卡尔积
解决方案:使用JOIN...ON明确表关联条件
-- 正确写法:通过ON指定用户表与文章表的关联字段
SELECT * FROM users u JOIN posts p ON u.id = p.user_id;二、多表查询核心技术
2.1 表连接类型(JOIN)
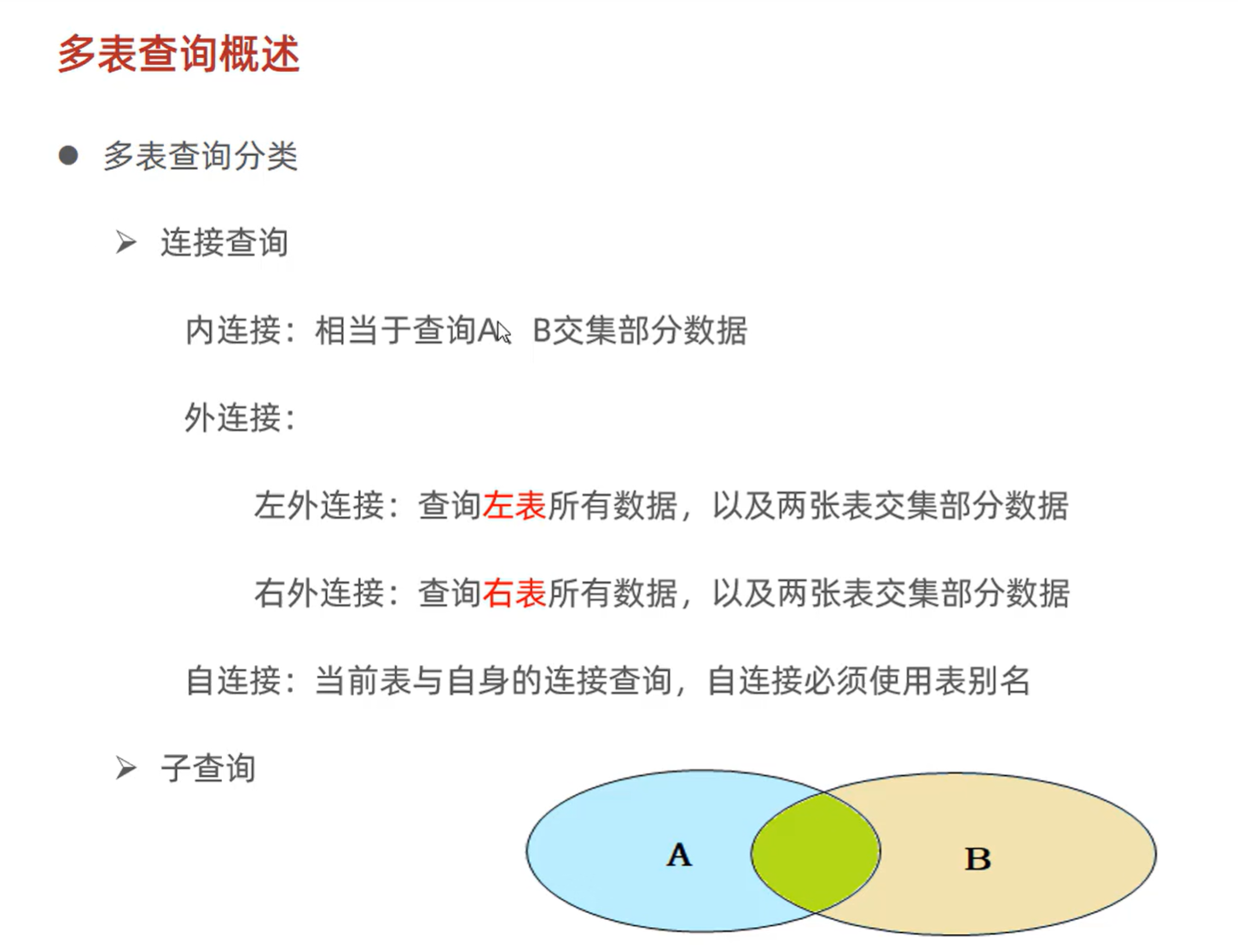
2.1.1 连接类型对比
| 连接类型 | 说明 | 示例场景 |
|
| 仅返回两表中匹配的记录 | 查询用户已发布的文章 |
|
| 返回左表所有记录和右表匹配的记录 | 统计用户粉丝数(包括无粉丝的用户) |
|
| 返回右表所有记录和左表匹配的记录 | 较少使用,可通过 LEFT JOIN 反转实现 |
|
| 返回两表所有记录,无论是否匹配(MySQL 不支持,可用 UNION 组合左右连接) | 合并两个系统的用户数据 |
|
| 生成笛卡尔积(显式写法) | 仅在特殊场景使用(如生成测试数据) |
2.1.2 连接示例
-- INNER JOIN:查询用户及其发布的文章
SELECT u.username, p.title
FROM users u INNER JOIN posts p ON u.id = p.user_id;-- LEFT JOIN:查询用户及其所有文章(包括未发布的)
SELECT u.username, p.title
FROM users u LEFT JOIN posts p ON u.id = p.user_id;INNER JOIN(内连接)

核心逻辑:
只返回两个表中完全匹配的记录,相当于取交集。
示例分析:
SELECT u.username, p.title
FROM users u INNER JOIN posts p ON u.id = p.user_id;假设存在以下数据:
- users 表:
| id | username |
| 1 | Alice |
| 2 | Bob |
| 3 | Charlie |
- posts 表:
| id | title | user_id |
| 10 | SQL 入门 | 1 |
| 11 | Python 进阶 | 1 |
| 12 | Java 基础 | 2 |
执行结果:
| username | title |
| Alice | SQL 入门 |
| Alice | Python 进阶 |
| Bob | Java 基础 |
关键点:
- Charlie 未出现在结果中,因为他没有对应的文章(
posts.user_id中没有 3)。 - 匹配条件:
users.id(主键) =posts.user_id(外键)。

LEFT JOIN(左连接)
核心逻辑:
返回左表(users)的所有记录,以及右表(posts)中匹配的记录。若右表无匹配,则对应字段显示为NULL。
示例分析:
SELECT u.username, p.title
FROM users u LEFT JOIN posts p ON u.id = p.user_id;执行结果:
| username | title |
| Alice | SQL 入门 |
| Alice | Python 进阶 |
| Bob | Java 基础 |
| Charlie | NULL |
关键点:
- Charlie 出现在结果中,但
title为NULL,因为他没有文章。 - 左表完整性:无论右表是否匹配,左表的记录都会被保留。
对比总结
| 连接类型 | 结果特点 | 适用场景 |
|
| 只返回匹配的记录 | 查询 “有对应关系” 的数据(如用户 + 文章) |
|
| 保留左表所有记录,右表无匹配时补 | 查询 “所有 X,无论是否有 Y”(如用户 + 文章,包含无文章的用户) |
常见误区
- 误用
INNER JOIN导致数据丢失:
若需要显示所有用户(即使无文章),使用INNER JOIN会漏掉这些用户。 - 混淆
LEFT JOIN和RIGHT JOIN:
RIGHT JOIN是保留右表所有记录,在 MySQL 中通常用LEFT JOIN反转表顺序替代。 - 关联条件错误:
ON子句中的字段必须是关联字段(如users.id和posts.user_id),否则会产生笛卡尔积。
实战建议
-
何时用
INNER JOIN:
当你只关心 “同时存在于两个表” 的数据时(如查询有订单的用户)。 - 何时用
LEFT JOIN:
当你需要确保 “不遗漏左表数据” 时(如统计用户活跃度,即使无活动也要显示用户)。 - 结合
WHERE过滤:sql
-- 查询有文章的用户(等价于INNER JOIN)
SELECT u.username, p.title
FROM users u LEFT JOIN posts p ON u.id = p.user_id
WHERE p.title IS NOT NULL; -- 过滤掉无文章的用户2.2 关联条件:ON vs WHERE
2.2.1 核心区别
- ON 子句:在表连接时指定关联条件,先过滤再关联
- WHERE 子句:在表关联完成后对结果进行过滤
2.2.2 示例对比
-- 场景:查询普通用户(role='user')的文章
-- 方式1:使用ON+WHERE(推荐写法)
SELECT u.username, p.title
FROM users u INNER JOIN posts p ON u.id = p.user_id
WHERE u.role = 'user';-- 方式2:全部用WHERE(等价于INNER JOIN,但逻辑不清晰)
SELECT u.username, p.title
FROM users u, posts p
WHERE u.id = p.user_id AND u.role = 'user';2.3 结果集合并:UNION 与 UNION ALL

2.3.1 功能对比
| 操作符 | 说明 | 性能 | 去重 |
|
| 合并结果并去除重复记录 | 较慢(需去重) | 是 |
|
| 直接合并结果,保留所有记录 | 较快 | 否 |
2.3.2 应用场景
-- 场景:查询用户的草稿和已发布文章
SELECT id, title, '草稿' AS status FROM drafts WHERE user_id = 123
UNION ALL -- 此处用UNION ALL更高效,因草稿和文章ID不会重复
SELECT id, title, status FROM posts WHERE user_id = 123;示例数据
假设用户 ID=123 在两个表中的数据如下:
drafts 表(草稿)
| id | title |
| 101 | SQL 草稿文章 |
| 102 | Python 笔记 |
posts 表(已发布文章)
| id | title | status |
| 201 | SQL 教程 | 已发布 |
| 202 | Python 入门 | 已发布 |
查询结果
执行以下 SQL:
SELECT id, title, '草稿' AS status FROM drafts WHERE user_id = 123
UNION ALL
SELECT id, title, status FROM posts WHERE user_id = 123;结果:
| id | title | status |
| 101 | SQL 草稿文章 | 草稿 |
| 102 | Python 笔记 | 草稿 |
| 201 | SQL 教程 | 已发布 |
| 202 | Python 入门 | 已发布 |
关键点解析
- 列结构对齐:
-
- 第一个查询返回
id, title, '草稿' - 第二个查询返回
id, title, status
两部分的列数和数据类型必须一致('草稿'是字符串,与posts.status类型匹配)。
- 第一个查询返回
- UNION ALL vs UNION:
-
UNION ALL:直接合并结果,保留所有记录(即使重复)。UNION:合并后去重(需额外排序,性能略低)。
在这个例子中,由于drafts.id和posts.id是不同的序列(不会重复),用UNION ALL更高效。
- 应用场景:
-
- 合并用户的不同类型内容(如草稿 + 已发布文章)。
- 整合多个表的相似数据(如不同部门的员工列表)。
拓展:如果 ID 可能重复?
假设posts表中也有id=101的记录:
SELECT id, title, '草稿' AS status FROM drafts WHERE user_id = 123
UNION -- 用UNION去重
SELECT id, title, status FROM posts WHERE user_id = 123;结果(假设重复 ID 的标题不同):
| id | title | status | |
| 101 | SQL 草稿文章 | 草稿 | ← 草稿中的 101 |
| 101 | SQL 正式文章 | 已发布 | ← 文章中的 101(因 title 不同,未被去重) |
| 102 | Python 笔记 | 草稿 | |
| 201 | SQL 教程 | 已发布 | |
| 202 | Python 入门 | 已发布 |
结论:
UNION根据整行数据去重,而非仅 ID。- 若需按 ID 去重,需用更复杂的逻辑(如子查询或窗口函数)。
性能建议
- 优先用
UNION ALL:
若确定无重复记录,避免UNION的去重开销。 - 索引优化:
在user_id上添加索引,加速过滤条件。 - 字段类型一致:
确保合并的列数据类型兼容(如INT与VARCHAR可能导致隐式转换)。
2.4 聚合与分组查询
2.4.1 常用聚合函数
COUNT(*):统计记录数SUM(column):求和AVG(column):求平均值MAX/MIN(column):求最大 / 最小值GROUP_CONCAT(column):将分组结果合并为字符串(MySQL 特有)
2.4.2 分组查询示例
-- 统计每个用户的文章数和评论数
SELECT u.username,COUNT(p.id) AS post_count,COUNT(c.id) AS comment_count
FROM users u
LEFT JOIN posts p ON u.id = p.user_id
LEFT JOIN comments c ON p.id = c.post_id
GROUP BY u.id, u.username
ORDER BY post_count DESC;2.5 子查询与窗口函数
2.5.1 子查询
子查询是指在一个查询中嵌套另一个查询,常用于以下场景:
- 过滤条件依赖子查询结果(如查询点赞数高于平均的文章)
- 聚合结果作为字段(如示例 3 中的评论数统计)
-- 子查询示例:查询点赞数前10的文章
SELECT p.title,(SELECT COUNT(*) FROM likes WHERE post_id = p.id) AS like_count
FROM posts p
ORDER BY like_count DESC
LIMIT 10;2.5.2 窗口函数
窗口函数用于在分组内进行排序、排名等操作,不改变结果集行数。
RANK():并列排名(如 1,1,3)DENSE_RANK():连续排名(如 1,1,2)ROW_NUMBER():唯一序号(如 1,2,3)
-- 窗口函数示例:用户活跃度排名
SELECT u.username,p.post_count,c.comment_count,RANK() OVER (ORDER BY p.post_count + c.comment_count DESC) AS activity_rank
FROM users u
LEFT JOIN (SELECT user_id, COUNT(*) AS post_count FROM posts GROUP BY user_id) p ON u.id = p.user_id
LEFT JOIN (SELECT user_id, COUNT(*) AS comment_count FROM comments GROUP BY user_id) c ON u.id = c.user_id;三、多表查询实战示例
3.1 一对一关联:用户与个人信息
-- 查询用户及其详细资料
SELECT u.username,u.email,p.real_name,p.phone
FROM users u
INNER JOIN profiles p ON u.id = p.user_id
WHERE u.role = 'admin';3.2 一对多关联:用户与文章
-- 查询用户及其所有文章(按时间倒序)
SELECT u.username,p.title,p.content,p.created_at
FROM users u
LEFT JOIN posts p ON u.id = p.user_id
ORDER BY p.created_at DESC;3.3 多对多关联:文章与标签
-- 查询文章及其标签(合并为字符串)
SELECT p.title,GROUP_CONCAT(t.tag_name SEPARATOR ', ') AS tags
FROM posts p
LEFT JOIN post_tag_relation rel ON p.id = rel.post_id
LEFT JOIN tags t ON rel.tag_id = t.id
GROUP BY p.id, p.title;3.4 自连接:用户互粉关系
-- 查询互相关注的用户对
SELECT u1.username AS user1,u2.username AS user2
FROM follows f1
INNER JOIN follows f2 ON f1.follower_id = f2.following_id AND f1.following_id = f2.follower_id
INNER JOIN users u1 ON f1.follower_id = u1.id
INNER JOIN users u2 ON f1.following_id = u2.id
WHERE f1.follower_id < f1.following_id; -- 避免重复显示3.5 时间序列查询:用户 30 天活跃度
-- 统计用户近30天的每日发帖、评论、点赞数
SELECT DATE(created_at) AS activity_date,COUNT(CASE WHEN action_type = 'post' THEN 1 END) AS posts,COUNT(CASE WHEN action_type = 'comment' THEN 1 END) AS comments,COUNT(CASE WHEN action_type = 'like' THEN 1 END) AS likes
FROM (SELECT created_at, 'post' AS action_type FROM posts WHERE user_id = 123UNION ALLSELECT created_at, 'comment' AS action_type FROM comments WHERE user_id = 123UNION ALLSELECT created_at, 'like' AS action_type FROM likes WHERE user_id = 123
) AS user_activity
WHERE created_at >= CURDATE() - INTERVAL 30 DAY
GROUP BY activity_date
ORDER BY activity_date;四、多表查询最佳实践
4.1 性能优化策略
- 避免笛卡尔积:永远使用
JOIN...ON而非逗号分隔表 - 合理使用索引:在关联字段(如
user_id、post_id)上创建索引 - 减少数据量:用
LIMIT限制结果集,用SELECT 具体字段代替SELECT * - 优化连接顺序:将小表作为驱动表(如
LEFT JOIN时左表为小表) - 避免子查询嵌套:复杂子查询可拆分为 CTE(公用表表达式)
4.2 查询写法规范
- 表别名:为每个表指定简短别名(如
u代表users,p代表posts) - 字段前缀:多表同名字段添加表别名前缀(如
u.id、p.id) - 格式对齐:SQL 关键字大写,子句换行对齐,提高可读性
- 注释说明:复杂查询添加注释,说明业务逻辑和关键条件
4.3 常见错误及解决方案
| 错误类型 | 现象 | 解决方案 |
| 笛卡尔积 | 结果行数异常增多 | 检查 是否缺少 条件,或 条件是否完整 |
| 数据重复 | 同一记录多次出现 | 检查多对多关联是否未分组,或是否误用 而非 |
| 性能低下 | 查询执行时间过长 | 分析查询计划( ),优化索引,拆分复杂查询 |
| 关联条件错误 | 结果数据不符合预期 | 检查 条件是否正确(如外键关系是否匹配),用 验证唯一性 |
五、总结与拓展
多表查询是 SQL 编程的核心技能,掌握连接类型、关联条件、聚合函数等技术后,可应对 90% 以上的业务查询需求。实际应用中,需结合数据库设计、业务场景和性能要求灵活组合技术。
拓展学习方向:
- 高级查询技术:CTE(WITH 子句)、递归查询、窗口函数高级用法
- 性能优化:查询执行计划分析、索引优化、分表查询策略
- 分布式查询:跨库多表查询(如 MySQL FederationX、中间件 ShardingSphere)
- 非关系型数据库查询:MongoDB 多文档关联、Cassandra 宽表设计
通过不断实践和优化,多表查询将成为数据分析师、后端开发人员处理复杂数据需求的利器。
六、多表查询实战示例
以下是几个基于你提供的数据库结构的多表查询示例,涵盖常见的查询场景和 SQL 技术:
1. 查询用户及其发布的文章(INNER JOIN)
SELECT u.username, p.title, p.content, c.name AS category
FROM users u
INNER JOIN posts p ON u.id = p.user_id
LEFT JOIN categories c ON p.category_id = c.id
WHERE u.role = 'user'
ORDER BY p.created_at DESC;说明:查询所有普通用户发布的文章,同时关联分类信息,按发布时间倒序排列。
2. 统计每个用户的粉丝数(GROUP BY + COUNT)
SELECT u.username, COUNT(f.follower_id) AS follower_count
FROM users u
LEFT JOIN follows f ON u.id = f.following_id
GROUP BY u.id
ORDER BY follower_count DESC;说明:统计每个用户的粉丝数量,即使没有粉丝也会显示(使用 LEFT JOIN)。
3. 查询文章及其评论数、点赞数(子查询 + GROUP BY)
SELECT p.title, p.content,(SELECT COUNT(*) FROM comments WHERE post_id = p.id) AS comment_count,(SELECT COUNT(*) FROM likes WHERE post_id = p.id) AS like_count
FROM posts p
WHERE p.status = '已发布'
ORDER BY like_count DESC
LIMIT 10;说明:查询已发布文章的标题、内容,并通过子查询统计评论数和点赞数,按点赞数排序取前 10 条。
4. 查询用户的通知信息(多表 JOIN + 条件过滤)
SELECT n.id,n.type,u.username AS source_user,p.title AS post_title,c.content AS comment_content,n.is_read,n.created_at
FROM notifications n
INNER JOIN users u ON n.source_user_id = u.id
LEFT JOIN posts p ON n.post_id = p.id
LEFT JOIN comments c ON n.comment_id = c.id
WHERE n.user_id = 123 -- 用户IDAND n.is_read = FALSE
ORDER BY n.created_at DESC;说明:查询用户未读的通知信息,关联发送者、文章和评论内容。
5. 查询用户的草稿和已发布文章(UNION ALL)
SELECT id, title, '草稿' AS status, created_at
FROM drafts
WHERE user_id = 123
UNION ALL
SELECT id, title, status, created_at
FROM posts
WHERE user_id = 123
ORDER BY created_at DESC;说明:将用户的草稿和已发布文章合并显示,方便用户查看所有内容。
6. 查询带标签的想法(多对多关联查询)
SELECT t.content,GROUP_CONCAT(tag.tag_name SEPARATOR ', ') AS tags
FROM thought t
LEFT JOIN thought_tag_relation rel ON t.id = rel.thought_id
LEFT JOIN tag ON rel.tag_id = tag.id
WHERE t.user_id = 123
GROUP BY t.id;说明:查询用户的想法及其关联的标签,使用 GROUP_CONCAT 合并多个标签为字符串。
7. 查询用户的活跃程度(窗口函数)
SELECT u.username,p.post_count,c.comment_count,RANK() OVER (ORDER BY p.post_count + c.comment_count DESC) AS activity_rank
FROM users u
LEFT JOIN (SELECT user_id, COUNT(*) AS post_count FROM posts GROUP BY user_id
) p ON u.id = p.user_id
LEFT JOIN (SELECT user_id, COUNT(*) AS comment_count FROM comments GROUP BY user_id
) c ON u.id = c.user_id
ORDER BY activity_rank;说明:使用窗口函数 RANK() 对用户的活跃度进行排名,活跃度由发帖数和评论数共同决定。
8. 查询用户之间的互粉关系(自连接)
SELECT u1.username AS user1,u2.username AS user2
FROM follows f1
INNER JOIN follows f2 ON f1.follower_id = f2.following_id AND f1.following_id = f2.follower_id
INNER JOIN users u1 ON f1.follower_id = u1.id
INNER JOIN users u2 ON f1.following_id = u2.id
WHERE f1.follower_id < f1.following_id; -- 避免重复显示说明:查询互相关注的用户对,使用自连接和条件过滤避免重复结果。
9. 查询用户最近 30 天的活跃度趋势(时间序列)
SELECT DATE(created_at) AS activity_date,COUNT(CASE WHEN action_type = 'post' THEN 1 END) AS posts,COUNT(CASE WHEN action_type = 'comment' THEN 1 END) AS comments,COUNT(CASE WHEN action_type = 'like' THEN 1 END) AS likes
FROM (SELECT created_at, 'post' AS action_type FROM posts WHERE user_id = 123UNION ALLSELECT created_at, 'comment' AS action_type FROM comments WHERE user_id = 123UNION ALLSELECT created_at, 'like' AS action_type FROM likes WHERE user_id = 123
) AS user_activity
WHERE created_at >= CURDATE() - INTERVAL 30 DAY
GROUP BY activity_date
ORDER BY activity_date;说明:使用 UNION ALL 合并用户的发帖、评论和点赞行为,统计近 30 天的每日活跃度。
10. 查询未被评论的文章(LEFT JOIN + IS NULL)
SELECT p.id, p.title, p.content
FROM posts p
LEFT JOIN comments c ON p.id = c.post_id
WHERE c.id IS NULLAND p.status = '已发布';说明:查询没有评论的已发布文章,通过 LEFT JOIN 和 IS NULL 过滤。
这些示例展示了 SQL 中常见的多表查询技术,包括连接类型(INNER JOIN、LEFT JOIN)、聚合函数(COUNT、GROUP_CONCAT)、子查询、窗口函数等。根据实际业务需求,你可以灵活组合这些技术来构建更复杂的查询。