去噪扩散概率模型(DDPM)全解:从数学基础到实现细节
一、 概述
在这篇博客文章中,我们将深入探讨去噪扩散概率模型(也被称为 DDPMs,扩散模型,基于得分的生成模型,或简称为自动编码器),这可以说是AIGC最近几年飞速发展的基石,如果你想做生成式人工智能,这个模型肯定是绕不过的门槛,基于扩散模型,研究人员已经在图像/音频/视频的有条件或无条件生成任务中取得了显著成果。当前一些流行的应用包括 OpenAI 的 GLIDE 和 DALL-E 2,海德堡大学的 Latent Diffusion,以及 Google Brain 的 ImageGen。
这篇文章详细介绍 (Ho 等人,2020) 提出的原始 DDPM 论文公式推导过程,并基于 Phil Wang 的 PyTorch 实现(其本身基于 原始 TensorFlow 实现)进行逐步实现。需要注意的是,用扩散方法进行生成建模的想法最早其实是在 (Sohl-Dickstein 等人,2015) 中提出的。然而,直到 (Song 等人,2019)(斯坦福大学)和随后 (Ho 等人,2020)(Google Brain)分别改进该方法之后,它才真正引起广泛关注。
- 公式推导本文学习的是:龙老师教AI的Diffusion Model | 扩散模型原理及代码实现,3小时快速上手
- 代码GitHub地址:https://github.com/huggingface/notebooks/blob/main/examples/annotated_diffusion.ipynb
其他生成模型如GAN、Normalizing Flows相比,扩散模型其实并不复杂:它们的共同点都是从一个简单分布中的噪声出发,转换为真实的数据样本。在扩散模型中,神经网络学习逐步对数据去噪,从纯噪声开始恢复出图像
二、论文解读
对于生成图像来说,可以分为两个阶段:

1. 前向扩散过程:逐步向图像添加高斯噪声,直到最终变成纯噪声
目标:得到每个时间步t的加噪图像

引入两个参数 α t \alpha_t αt和 β t \beta_t βt, 其中 α t \alpha_t αt=1- β t \beta_t βt
α t = 1 − β t \alpha_t=1-\beta_t αt=1−βt β β β 越来越大,论文中0.0001到0.002,从而 α α α 也就是要越来越小(噪声需要随步数增多)
x t = a t x t − 1 + 1 − α t z 1 x_t=\sqrt{a_t}x_{t-1}+\sqrt{1-\alpha_t}z_1 xt=atxt−1+1−αtz1
z t z_t zt是由标准正太分布采样得到的噪声,对应代码就是:
x = torch.randn(batch_size, channels, height, width)
需要得到 x t x_t xt由 x 0 x_0 x0直接得到的公式,这和训练过程有关,在每个训练步骤中,对于一个 batch,每张图片只随机选取一个时间步 t,然后训练模型去预测该时间步下的噪声。推到过程如下:
x t − 1 = a t − 1 x t − 2 + 1 − α t − 1 z 2 x_{t-1}=\sqrt{a_{t-1}}x_{t-2}+\sqrt{1-\alpha_{t-1}}z_2 xt−1=at−1xt−2+1−αt−1z2 带入到上式得:
x t = a t ( a t − 1 x t − 2 + 1 − α t − 1 z 2 ) + 1 − α t z 1 x_t= \sqrt {a_t}( \sqrt {a_{t- 1}}x_{t- 2}+ \sqrt {1- \alpha _{t- 1}}z_2) + \sqrt {1- \alpha _t}z_1 xt=at(at−1xt−2+1−αt−1z2)+1−αtz1
其中每次加入的噪声都服从高斯分布 z 1 , z 2 , … ∼ N ( 0 , 1 ) z_1,z_2,\ldots\sim\mathcal{N}(0,\mathbf{1}) z1,z2,…∼N(0,1),化简得:
x t = a t a t − 1 x t − 2 + ( a t ( 1 − α t − 1 ) z 2 + 1 − α t z 1 ) x_t=\sqrt{a_ta_{t-1}}x_{t-2}+(\sqrt{a_t(1-\alpha_{t-1})}z_2+\sqrt{1-\alpha_t}z_1) xt=atat−1xt−2+(at(1−αt−1)z2+1−αtz1)
括号两项里分别服从 N ( 0 , 1 − α t ) \mathcal{N}(0,1-\alpha_t) N(0,1−αt), N ( 0 , a t ( 1 − α t − 1 ) ) \mathcal{N}(0,a_t(1-\alpha_{t-1})) N(0,at(1−αt−1))
这里就是相加后仍服从高斯分布,即 a t ( 1 − α t − 1 ) z 2 + 1 − α t z 1 ∼ N ( 0 , ( 1 − α t α t − 1 ) ) \sqrt{a_t(1-\alpha_{t-1})}z_2+\sqrt{1-\alpha_t}z_1\sim\mathcal{N}(0,(1-\alpha_t\alpha_{t-1})) at(1−αt−1)z2+1−αtz1∼N(0,(1−αtαt−1)),得到:
x t = α t α t − 1 x t − 2 + 1 − α t α t − 1 z 2 x_t=\sqrt{\alpha_t\alpha_{t-1}}x_{t-2}+\sqrt{1-\alpha_t\alpha_{t-1}}z_2 xt=αtαt−1xt−2+1−αtαt−1z2不断往里套, 就能发现规律了, 其实就是累乘:
x t = α ‾ t x 0 + 1 − α ‾ t z t x_t=\sqrt{\overline{\alpha}_t}x_0+\sqrt{1-\overline{\alpha}_t}z_t\text{ } xt=αtx0+1−αtzt
可以看到 x t x_t xt其实可以看成是原始数据 x 0 x_0 x0和随机噪音 z t z_t zt的线性组合,其中 α ‾ t \sqrt{\overline{\alpha}_t} αt和 1 − α ‾ t \sqrt{1-\overline{\alpha}_t} 1−αt为组合系数,它们的平方和等于1
2. 反向去噪过程
目标:就是通过一个纯噪声图像一步步去噪还原为特定分布的图像(正常图像),其中神经网络被训练用于预测噪声
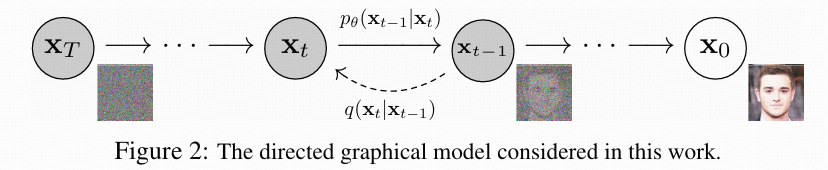
一步一步来,要求 q ( x t − 1 ∣ x t ) q \left( x_{t-1}|x_{t}\right) q(xt−1∣xt)很麻烦,但如果引入 x 0 x_{0} x0作为已知量,利用贝叶斯公式就可以得到下式:
q ( x t − 1 ∣ x t , x 0 ) = q ( x t ∣ x t − 1 , x 0 ) q ( x t − 1 ∣ x 0 ) q ( x t ∣ x 0 ) q \left( x_{t-1}|x_{t},x_{0} \right)=q \left( x_{t}|x_{t-1},x_{0} \right) \frac{q \left( x_{t-1}|x_{0} \right)}{q \left( x_{t}|x_{0} \right)} q(xt−1∣xt,x0)=q(xt∣xt−1,x0)q(xt∣x0)q(xt−1∣x0)
已知 x 0 x_{0} x0的情况下,各个因式都能够求出来并且符合正太分布:
q ( x t − 1 ∣ x 0 ) = a ‾ t − 1 x 0 + 1 − a ‾ t − 1 z ∼ N ( a ‾ t − 1 x 0 , 1 − a ‾ t − 1 ) {q \left(\mathbf{x}_{t - 1}|\mathbf{x}_{0}\right)}\ =\sqrt{\overline{a}_{t-1}} \boldsymbol{x}_{0}\boldsymbol{+}\sqrt{\boldsymbol{1}-\overline{a}_{t-1}} \boldsymbol{z}\ \ \ \ \sim \mathcal{N} \left(\sqrt{\overline{a}_{t-1}} \boldsymbol{x}_{0} , \boldsymbol{1}-\overline{a}_{t-1}\right) q(xt−1∣x0) =at−1x0+1−at−1z ∼N(at−1x0,1−at−1)
q ( x t ∣ x 0 ) = a ‾ t x 0 + 1 − a ‾ t z ∼ N ( a ‾ t x 0 , 1 − a ‾ t ) {q \left(\mathbf{x}_{t }|\mathbf{x}_{0}\right)}\ =\sqrt{\overline{a}_{t}} \boldsymbol{x}_{0}\boldsymbol{+}\sqrt{\boldsymbol{1}-\overline{a}_{t}} \boldsymbol{z}\ \ \ \ \sim \mathcal{N} \left(\sqrt{\overline{a}_{t}} \boldsymbol{x}_{0} , \boldsymbol{1}-\overline{a}_{t}\right) q(xt∣x0) =atx0+1−atz ∼N(atx0,1−at)
q ( x t ∣ x t − 1 , x 0 ) = a t x t − 1 + 1 − α t z ∼ N ( a t x t − 1 , 1 − α t ) {q\left(\mathbf{x}_{t}|\mathbf{x}_{t - 1}, \mathbf{x}_{0}\right)} = \sqrt{a_{t}}\boldsymbol{x}_{t-1}\boldsymbol{+}\sqrt{\boldsymbol{1}-\boldsymbol {\alpha}_{t}}\boldsymbol{z}\qquad\ \sim \mathcal{N} \left(\ \sqrt{a_{t}}\boldsymbol{x}_{t-1} ,\begin{array}{c} \boldsymbol{1}-\boldsymbol{\alpha}_{t}\end{array}\right) q(xt∣xt−1,x0)=atxt−1+1−αtz ∼N( atxt−1,1−αt)
将正太分布转换为e的指数形式进行乘除运算:
连续型随机变量 X 如果有如下形式的密度函数: f ( x ) = 1 2 π σ e − ( x − μ ) 2 2 σ 2 ( μ ∈ R , σ > 0 ) f \left( x \right)= \frac{1}{ \sqrt{2 \pi} \sigma}e^{- \frac{ \left( x- \mu \right)^{2}}{2 \sigma^{2}}} \left( \mu \in R, \sigma>0 \right) f(x)=2πσ1e−2σ2(x−μ)2(μ∈R,σ>0)
则称 X 服从参数为 ( μ , σ 2 ) (μ,σ^2) (μ,σ2) 的正态分布(normaldistribution) ,记为 X − N ( μ , σ 2 ) X−N(μ,σ^2) X−N(μ,σ2)
得到结果:
∝ exp ( − 1 2 ( ( x t − α t x t − 1 ) 2 β t + ( x t − 1 − α ˉ t − 1 x 0 ) 2 1 − α ˉ t − 1 − ( x t − α ˉ t x 0 ) 2 1 − α ˉ t ) ) \propto\exp\Big(-\frac{1}{2} \big(\frac{(\mathbf{x}_{t}- \sqrt{\alpha_{t}}\mathbf{x}_{t-1})^{2}}{\beta_{t}}+\frac{(\mathbf{x}_{t-1}- \sqrt{\bar{\alpha}_{t-1}}\mathbf{x}_{0})^{2}}{1-\bar{\alpha}_{t-1}}-\frac{( \mathbf{x}_{t}-\sqrt{\bar{\alpha}_{t}}\mathbf{x}_{0})^{2}}{1-\bar{\alpha}_{t} }\big)\Big) ∝exp(−21(βt(xt−αtxt−1)2+1−αˉt−1(xt−1−αˉt−1x0)2−1−αˉt(xt−αˉtx0)2))
将平方项展开,合并同类项:
∝ exp ( − 1 2 ( ( x t − α t x t − 1 ) 2 β t + ( x t − 1 − α ˉ t − 1 x 0 ) 2 1 − α ˉ t − 1 − ( x t − α ˉ t x 0 ) 2 1 − α ˉ t ) ) = exp ( − 1 2 ( x t 2 − 2 α t x t x t − 1 + α t x t − 1 2 β t + x t − 1 2 − 2 α ˉ t − 1 x 0 x t − 1 + α ˉ t − 1 x 0 2 1 − α ˉ t − 1 − ( x t − α ˉ t x 0 ) 2 1 − α ˉ t ) ) = exp ( − 1 2 ( ( α t β t + 1 1 − α ˉ t − 1 ) x t − 1 2 − ( 2 α t β t x t + 2 α ˉ t − 1 1 − α ˉ t − 1 x 0 ) x t − 1 + C ( x t , x 0 ) ) ) \begin{gathered} \propto\exp\left(-\frac{1}{2}\left(\frac{(\mathbf{x}_t-\sqrt{\alpha_t}\mathbf{x}_{t-1})^2}{\beta_t}+\frac{(\mathbf{x}_{t-1}-\sqrt{\bar{\alpha}_{t-1}}\mathbf{x}_0)^2}{1-\bar{\alpha}_{t-1}}-\frac{(\mathbf{x}_t-\sqrt{\bar{\alpha}_t}\mathbf{x}_0)^2}{1-\bar{\alpha}_t}\right)\right) \\ =\exp\left(-\frac{1}{2}(\frac{\mathbf{x}_t^2-2\sqrt{\alpha_t}\mathbf{x}_t\mathbf{x}_{t-1}+\alpha_t\mathbf{x}_{t-1}^2}{\beta_t}+\frac{\mathbf{x}_{t-1}^2-\mathbf{2}\sqrt{\bar{\alpha}_{t-1}}\mathbf{x}_0\mathbf{x}_{t-1}+\bar{\alpha}_{t-1}\mathbf{x}_0^2}{1-\bar{\alpha}_{t-1}}-\frac{(\mathbf{x}_t-\sqrt{\bar{\alpha}_t}\mathbf{x}_0)^2}{1-\bar{\alpha}_t})\right) \\ =\exp\left(-\frac{1}{2}\left((\frac{\alpha_{t}}{\beta_{t}}+\frac{1}{1-\bar{\alpha}_{t-1}})\mathbf{x}_{t-1}^{2}-(\frac{2\sqrt{\alpha_{t}}}{\beta_{t}}\mathbf{x}_{t}+\frac{2\sqrt{\bar{\alpha}_{t-1}}}{1-\bar{\alpha}_{t-1}}\mathbf{x}_{0})\mathbf{x}_{t-1}+C(\mathbf{x}_{t},\mathbf{x}_{0})\right)\right) \end{gathered} ∝exp(−21(βt(xt−αtxt−1)2+1−αˉt−1(xt−1−αˉt−1x0)2−1−αˉt(xt−αˉtx0)2))=exp(−21(βtxt2−2αtxtxt−1+αtxt−12+1−αˉt−1xt−12−2αˉt−1x0xt−1+αˉt−1x02−1−αˉt(xt−αˉtx0)2))=exp(−21((βtαt+1−αˉt−11)xt−12−(βt2αtxt+1−αˉt−12αˉt−1x0)xt−1+C(xt,x0)))
exp ( − ( x − μ ) 2 2 σ 2 ) = exp ( − 1 2 ( 1 σ 2 x 2 − 2 μ σ 2 x + μ 2 σ 2 ) ) \exp \left(- \frac{ \left( x- \mu \right)^{2}}{2 \sigma^{2}} \right)= \exp \left(- \frac{1}{2} \left( \frac{1}{ \sigma^{2}}x^{2}- \frac{2 \mu}{ \sigma^{2}}x+ \frac{ \mu^{2}}{ \sigma^{2}} \right) \right) exp(−2σ2(x−μ)2)=exp(−21(σ21x2−σ22μx+σ2μ2))
因为是要得到 x t − 1 {x}_{t - 1} xt−1的分布,所以将其他看作常熟进行化简,得到得结果和标准正太分布比对,即可得到均值和方差,也就能得到 x t − 1 {x}_{t - 1} xt−1的分布,分析上式可以知道方差是个常数,仅和 α t \alpha_t αt、 β t \beta_t βt有关(这是提前设好的值):
σ 2 = 1 / ( α t β t + 1 1 − α t − 1 ‾ ) = 1 / ( α t − α t ∗ α t − 1 ‾ + β t β t ∗ ( 1 − α t − 1 ‾ ) ) = 1 − α t − 1 ‾ 1 − α t ‾ ∗ β t \begin{aligned} \sigma^{2} & =1/(\frac{\alpha_t}{\beta_t}+\frac{1}{1-\overline{\alpha_{t-1}}}) \\ & =1/(\frac{\alpha_t-\alpha_t*\overline{\alpha_{t-1}}+\beta_t}{\beta_t*(1-\overline{\alpha_{t-1}})}) \\ & =\frac{1-\overline{\alpha_{t-1}}}{1-\overline{\alpha_t}}*\beta_t \end{aligned} σ2=1/(βtαt+1−αt−11)=1/(βt∗(1−αt−1)αt−αt∗αt−1+βt)=1−αt1−αt−1∗βt
可以得到均值:
μ ~ t − 1 ( x t , x 0 ) = α t ( 1 − α ‾ t − 1 ) 1 − α ‾ t x t + α ‾ t − 1 β t 1 − α ‾ t x 0 \tilde{ \mu}_{t-1} \left( x_{t},x_{0} \right)= \frac{ \sqrt{ \alpha_{t}} \left( 1- \overline{ \alpha}_{t-1} \right)}{1- \overline{ \alpha}_{t}}x_{t}+ \frac{ \sqrt{ \overline{ \alpha}_{t-1}} \beta_{t}}{1- \overline{ \alpha}_{t}}x_{0} μ~t−1(xt,x0)=1−αtαt(1−αt−1)xt+1−αtαt−1βtx0
可以看出只和 x t , x 0 x_{t},x_{0} xt,x0有关系,而 x 0 x_{0} x0是我们要求得目标是不知道的,可以根据第一个得到的公式:
x t = α ‾ t x 0 + 1 − α ‾ t z t x_t=\sqrt{\overline{\alpha}_t}x_0+\sqrt{1-\overline{\alpha}_t}z_t\text{ } xt=αtx0+1−αtzt
可以得到:
x 0 = 1 α t ( x t − 1 − α ‾ t z t ) x_{0}= \frac{1}{ \sqrt{ \alpha_{t}}} \left( x_{t}- \sqrt{1- \overline{ \alpha}_{t}}z_{t} \right) x0=αt1(xt−1−αtzt)
Tips:既然已知 x 0 x_0 x0和 x t x_t xt的关系,为什么不直接一步求解?
扩散模型包括两个过程:前向过程(forward process)和反向过程(reverse process),其中前向过程又称为扩散过程(diffusion process),无论是前向过程还是反向过程都是一个参数化的马尔可夫链(Markov chain)
马尔可夫链是指一个随机过程,其中系统状态的未来演变仅依赖于当前状态,而与过去的状态无关。
将 x 0 x_0 x0 替换为 x t x_t xt,完美闭环:
μ ~ t − 1 = 1 a t ( x t − β t 1 − a ‾ t z t ) \widetilde{ \mu}_{t-1}= \frac{1}{ \sqrt{a_{t}}} \left( x_{t}- \frac{ \beta_{t}}{ \sqrt{1- \overline{a}_{t}}} {z}_{t} \right) μ t−1=at1(xt−1−atβtzt)
z t z_t zt是t时刻的噪声,在推理阶段是未知的,没有公式可以直接求出来,这时候第一步加噪声的步骤开始发力,每一步加的噪声 z t z_t zt 是已知的(作为标签),加完噪声的图像 x t x_t xt (作为输入)也是已知的,所以作者设计了一个Unet网络模型来预测 z t z_t zt,得到 z t z_t zt 的近似值(神经网络求解其实就是一个最优化过程,用来求解近似值再合适不过),计算loss:
∇ θ ∥ ϵ − ϵ θ ( α ˉ t x 0 + 1 − α ˉ t ϵ , t ) ∥ 2 \nabla_\theta \left\| \epsilon - \epsilon_\theta \left( \sqrt{\bar{\alpha}_t} x_0 + \sqrt{1 - \bar{\alpha}_t} \epsilon, t \right) \right\|^2 ∇θ ϵ−ϵθ(αˉtx0+1−αˉtϵ,t) 2
到这一步有了均值和方差就可以得到 x t − 1 {x}_{t-1} xt−1的分布了,但是要得到论文里的:
x t − 1 = 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ θ ( x t , t ) ) + σ t z \mathbf{x}_{t-1}=\tfrac{1}{\sqrt{\alpha_{t}}}\left(\mathbf{x}_{t}-\tfrac{1- \alpha_{t}}{\sqrt{1-\bar{\alpha}_{t}}}\boldsymbol{\epsilon}_{\theta}(\mathbf{ x}_{t},t)\right)+\sigma_{t}\mathbf{z} xt−1=αt1(xt−1−αˉt1−αtϵθ(xt,t))+σtz
还有一个优化过程,这一段公式推理龙老师没讲,我自己找了一篇博客看了一下,感觉有点难懂,需要一些数学功底,有兴趣可以参考扩散模型之DDPM的优化目标部分。
三. 代码实现:
只展示最核心的模块实现,完整代码请访问原作者github仓库或者私信本人
导入依赖包:
import math
from inspect import isfunction
from functools import partial
%matplotlib inline
import matplotlib.pyplot as plt
from tqdm.auto import tqdm
from einops import rearrange
import torch
from torch import nn, einsum
import torch.nn.functional as F
时间步(t)编码:
class SinusoidalPositionEmbeddings(nn.Module):def __init__(self, dim):super().__init__()self.dim = dimdef forward(self, time):device = time.devicehalf_dim = self.dim // 2embeddings = math.log(10000) / (half_dim - 1)embeddings = torch.exp(torch.arange(half_dim, device=device) * -embeddings)embeddings = time[:, None] * embeddings[None, :]embeddings = torch.cat((embeddings.sin(), embeddings.cos()), dim=-1)return embeddings# 实例化模块
embed_fn = SinusoidalPositionEmbeddings(dim=8)# 输入时间步 t,形状为 (batch_size,)
t = torch.tensor([1.0, 10.0, 100.0]) # 3个样本# 输出嵌入
output = embed_fn(t)print("Output shape:", output.shape) # [3, 8]
print("Output:\n", output)
Unet网络,具体实现引用了 ConvNext网络结构
class Unet(nn.Module):def __init__(self,dim,init_dim=None,out_dim=None,dim_mults=(1, 2, 4, 8),channels=3,with_time_emb=True,resnet_block_groups=8,use_convnext=True,convnext_mult=2,):super().__init__()# determine dimensionsself.channels = channelsinit_dim = default(init_dim, dim // 3 * 2)self.init_conv = nn.Conv2d(channels, init_dim, 7, padding=3)dims = [init_dim, *map(lambda m: dim * m, dim_mults)]in_out = list(zip(dims[:-1], dims[1:]))ConvNextif use_convnext:block_klass = partial(ConvNextBlock, mult=convnext_mult)else:block_klass = partial(ResnetBlock, groups=resnet_block_groups)# time embeddingsif with_time_emb:time_dim = dim * 4self.time_mlp = nn.Sequential(SinusoidalPositionEmbeddings(dim),nn.Linear(dim, time_dim),nn.GELU(),nn.Linear(time_dim, time_dim),)else:time_dim = Noneself.time_mlp = None# layersself.downs = nn.ModuleList([])self.ups = nn.ModuleList([])num_resolutions = len(in_out)for ind, (dim_in, dim_out) in enumerate(in_out):is_last = ind >= (num_resolutions - 1)self.downs.append(nn.ModuleList([block_klass(dim_in, dim_out, time_emb_dim=time_dim),block_klass(dim_out, dim_out, time_emb_dim=time_dim),Residual(PreNorm(dim_out, LinearAttention(dim_out))),Downsample(dim_out) if not is_last else nn.Identity(),]))mid_dim = dims[-1]self.mid_block1 = block_klass(mid_dim, mid_dim, time_emb_dim=time_dim)self.mid_attn = Residual(PreNorm(mid_dim, Attention(mid_dim)))self.mid_block2 = block_klass(mid_dim, mid_dim, time_emb_dim=time_dim)for ind, (dim_in, dim_out) in enumerate(reversed(in_out[1:])):is_last = ind >= (num_resolutions - 1)self.ups.append(nn.ModuleList([block_klass(dim_out * 2, dim_in, time_emb_dim=time_dim),block_klass(dim_in, dim_in, time_emb_dim=time_dim),Residual(PreNorm(dim_in, LinearAttention(dim_in))),Upsample(dim_in) if not is_last else nn.Identity(),]))out_dim = default(out_dim, channels)self.final_conv = nn.Sequential(block_klass(dim, dim), nn.Conv2d(dim, out_dim, 1))def forward(self, x, time):x = self.init_conv(x)t = self.time_mlp(time) if exists(self.time_mlp) else Noneh = []# downsamplefor block1, block2, attn, downsample in self.downs:x = block1(x, t)x = block2(x, t)x = attn(x)h.append(x)x = downsample(x)# bottleneckx = self.mid_block1(x, t)x = self.mid_attn(x)x = self.mid_block2(x, t)# upsamplefor block1, block2, attn, upsample in self.ups:x = torch.cat((x, h.pop()), dim=1)x = block1(x, t)x = block2(x, t)x = attn(x)x = upsample(x)return self.final_conv(x)
计算 α t \alpha_t αt和 β t \beta_t βt以及公式中的已知量:
timesteps = 200# define beta schedule
betas = linear_beta_schedule(timesteps=timesteps)# define alphas
alphas = 1. - betas
alphas_cumprod = torch.cumprod(alphas, axis=0)
alphas_cumprod_prev = F.pad(alphas_cumprod[:-1], (1, 0), value=1.0)
sqrt_recip_alphas = torch.sqrt(1.0 / alphas)# calculations for diffusion q(x_t | x_{t-1}) and others
sqrt_alphas_cumprod = torch.sqrt(alphas_cumprod)
sqrt_one_minus_alphas_cumprod = torch.sqrt(1. - alphas_cumprod)# calculations for posterior q(x_{t-1} | x_t, x_0)
posterior_variance = betas * (1. - alphas_cumprod_prev) / (1. - alphas_cumprod)def extract(a, t, x_shape):batch_size = t.shape[0]out = a.gather(-1, t.cpu())return out.reshape(batch_size, *((1,) * (len(x_shape) - 1))).to(t.device)
图像加噪过程:
def q_sample(x_start, t, noise=None):if noise is None:noise = torch.randn_like(x_start)sqrt_alphas_cumprod_t = extract(sqrt_alphas_cumprod, t, x_start.shape)sqrt_one_minus_alphas_cumprod_t = extract(sqrt_one_minus_alphas_cumprod, t, x_start.shape)return sqrt_alphas_cumprod_t * x_start + sqrt_one_minus_alphas_cumprod_t * noise
计算损失:
def p_losses(denoise_model, x_start, t, noise=None, loss_type="l1"):if noise is None:noise = torch.randn_like(x_start)x_noisy = q_sample(x_start=x_start, t=t, noise=noise)predicted_noise = denoise_model(x_noisy, t)if loss_type == 'l1':loss = F.l1_loss(noise, predicted_noise)elif loss_type == 'l2':loss = F.mse_loss(noise, predicted_noise)elif loss_type == "huber":loss = F.smooth_l1_loss(noise, predicted_noise)else:raise NotImplementedError()return loss
训练Unet
from torchvision.utils import save_imageepochs = 5for epoch in range(epochs):for step, batch in enumerate(dataloader):optimizer.zero_grad()batch_size = batch["pixel_values"].shape[0]batch = batch["pixel_values"].to(device)# Algorithm 1 line 3: sample t uniformally for every example in the batcht = torch.randint(0, timesteps, (batch_size,), device=device).long()loss = p_losses(model, batch, t, loss_type="huber")if step % 100 == 0:print("Loss:", loss.item())loss.backward()optimizer.step()# save generated imagesif step != 0 and step % save_and_sample_every == 0:milestone = step // save_and_sample_everybatches = num_to_groups(4, batch_size)all_images_list = list(map(lambda n: sample(model, batch_size=n, channels=channels), batches))all_images = torch.cat(all_images_list, dim=0)all_images = (all_images + 1) * 0.5save_image(all_images, str(results_folder / f'sample-{milestone}.png'), nrow = 6)
去噪推理过程:
@torch.no_grad()
def p_sample(model, x, t, t_index):betas_t = extract(betas, t, x.shape)sqrt_one_minus_alphas_cumprod_t = extract(sqrt_one_minus_alphas_cumprod, t, x.shape)sqrt_recip_alphas_t = extract(sqrt_recip_alphas, t, x.shape)# Equation 11 in the paper# Use our model (noise predictor) to predict the meanmodel_mean = sqrt_recip_alphas_t * (x - betas_t * model(x, t) / sqrt_one_minus_alphas_cumprod_t)if t_index == 0:return model_meanelse:posterior_variance_t = extract(posterior_variance, t, x.shape)noise = torch.randn_like(x)# Algorithm 2 line 4:return model_mean + torch.sqrt(posterior_variance_t) * noise # Algorithm 2 but save all images:
@torch.no_grad()
def p_sample_loop(model, shape):device = next(model.parameters()).deviceb = shape[0]# start from pure noise (for each example in the batch)img = torch.randn(shape, device=device)imgs = []for i in tqdm(reversed(range(0, timesteps)), desc='sampling loop time step', total=timesteps):img = p_sample(model, img, torch.full((b,), i, device=device, dtype=torch.long), i)imgs.append(img.cpu().numpy())return imgs@torch.no_grad()
def sample(model, image_size, batch_size=16, channels=3):return p_sample_loop(model, shape=(batch_size, channels, image_size, image_size))samples = sample(model, image_size=image_size, batch_size=64, channels=channels)