Thinkless:基于RL让LLM自适应选择长/短推理模式,显著提升推理效率和准确性!!
摘要:能够进行扩展的推理链(chain-of-thought reasoning)的推理语言模型(Reasoning Language Models),在需要复杂逻辑推理的任务上展现出了卓越的性能。然而,对所有问题都应用复杂的推理过程常常会导致显著的计算效率低下,特别是当许多问题本身就存在简单直接的解决方案时。这引发了这样一个开放性问题:大型语言模型(LLMs)能否学会何时进行思考?为了回答这一问题,我们提出了 Thinkless,这是一个可学习的框架,能够使 LLM 根据任务的复杂性以及模型自身的能力,自适应地在简短推理和长篇推理之间进行选择。Thinkless 在强化学习范式下进行训练,并采用两种控制标记:<short> 用于简洁的回答,<think> 用于详细的推理。我们方法的核心是一种解耦的组相对策略优化(Decoupled Group Relative Policy Optimization,DeGRPO)算法,该算法将混合推理的学习目标分解为两个部分:(1)控制标记损失,用于管理推理模式的选择;(2)回答损失,用于提高生成答案的准确性。这种解耦的公式化方法使得我们能够对每个目标的贡献进行精细控制,稳定训练过程,并有效防止了在普通 GRPO 中观察到的崩溃现象。在经验性实验中,Thinkless 在多个基准测试(如 Minerva Algebra、MATH-500 和 GSM8K)上能够将长链推理的使用减少 50% - 90%,显著提高了推理语言模型的效率。
目录
一、背景动机
二、核心贡献
三、实现方法
3.1 基于SFT的蒸馏
3.2 强化学习
四、实验结论
4.1 准确率和推理效率提升
4.2 DeGRPO 训练分析
一、背景动机
大模型通过链式思考在处理复杂的推理任务中有明显的效果,这些模型通过链式思考(chain-of-thought reasoning)生成中间步骤,最终得出答案。然而,这种复杂的推理过程在处理简单问题时会导致不必要的计算开销,例如增加内存占用和计算成本。
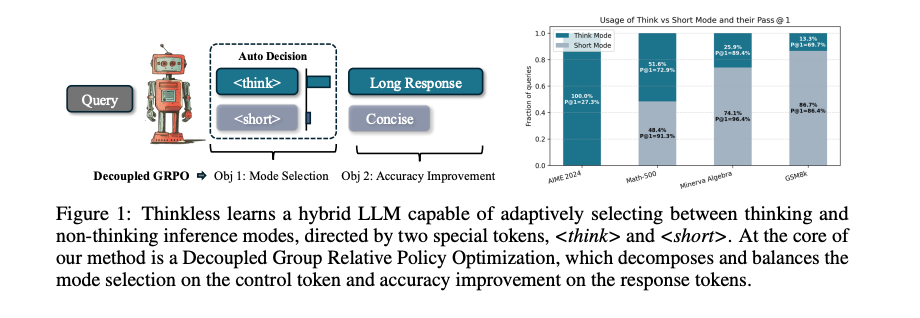
该文章提出了 Thinkless,这是一个可学习的框架,能够使 LLM 根据任务的复杂性以及模型自身的能力,自适应地在简短推理和长篇推理之间进行选择。Thinkless 在强化学习范式下进行训练,并采用两种控制标记:<short> 用于简洁的回答,<think> 用于详细的推理。
二、核心贡献
论文题目:Thinkless: LLM Learns When to Think
论文地址:https://arxiv.org/pdf/2505.13379
1、提出Thinkless框架,Thinkless是一个可学习的框架,使LLMs能够根据任务复杂性和模型自身能力,自适应地选择短形式(short-form)和长形式(long-form)推理。
2、设计了DeGRPO强化学习算法,该算法将混合推理的学习目标分解为两个部分
- 控制推理模式的选择
- 提高生成答案的准确性。这种解耦方法能够平衡两个目标的贡献,稳定训练过程,并有效防止模式崩溃。
3、在多个基准测试(如Minerva Algebra、MATH-500和GSM8K)中,Thinkless能够将长链推理的使用减少50%到90%,显著提高了推理语言模型的效率。
三、实现方法
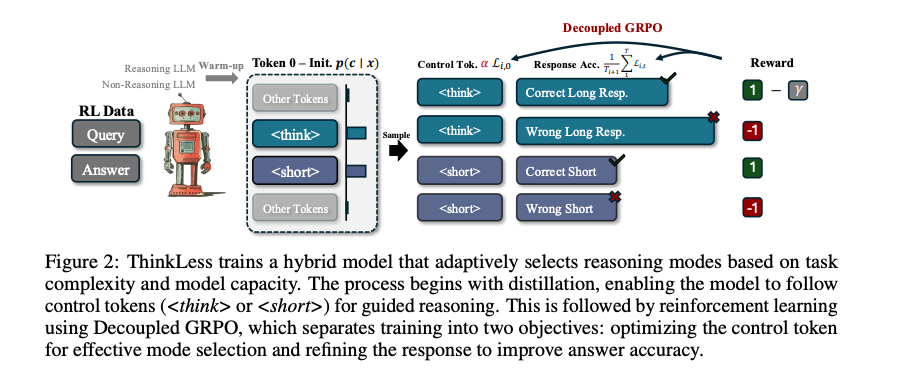
Thinkless的实现分为两个阶段:蒸馏(Distillation) 和 强化学习(Reinforcement Learning)。
3.1 基于SFT的蒸馏
- 目标:蒸馏阶段的目标是使模型能够生成两种风格的回复:短形式(short-form)和长形式(long-form)。
- 数据集:使用推理模型和Instruct模型来生成两种类型的回复。
-
推理模型(Reasoning Model):选择一个能够生成详细推理链的模型,例如 DeepSeek-R1-671B。该模型通过逐步推理生成长形式响应。
-
指令跟随模型(Instruction-Following Model):选择一个优化用于生成简洁答案的模型,例如 Qwen2.5-Math-1.5B-Instruct。
-
-
训练:使用监督微调(Supervised Fine-Tuning, SFT)对目标模型进行训练,使其能够根据控制标记(<think>和<short>)生成不同风格的响应。
3.2 强化学习
- 目标:训练模型根据输入查询的复杂性和模型自身能力,选择合适的推理模式。
- 控制标记:使用两个控制标记 <think>和<short>,分别表示长形式和短形式推理。
- 奖励函数
- 如果选择<short>且答案正确,奖励为1.0。
- 如果选择<think>且答案正确,奖励为1.0 - γ(γ > 0,偏好短形式答案)。
- 如果答案错误,奖励为-1.0。

- DeGRPO算法
- 将学习目标分解为两个部分:推理模式选择(Mode Selection)和响应准确性提升(Accuracy Improvement)。
-
模式选择(Mode Selection):控制标记 c 的损失,用于决定推理模式。
-
准确性提升(Accuracy Improvement):响应标记 a 的损失,用于提高生成答案的准确性。
-
-
通过引入权重系数 α,平衡控制标记和响应标记的贡献,避免模式崩溃。
- 将学习目标分解为两个部分:推理模式选择(Mode Selection)和响应准确性提升(Accuracy Improvement)。
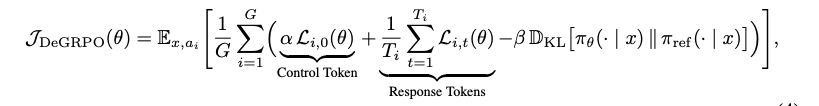
四、实验结论
4.1 准确率和推理效率提升
-
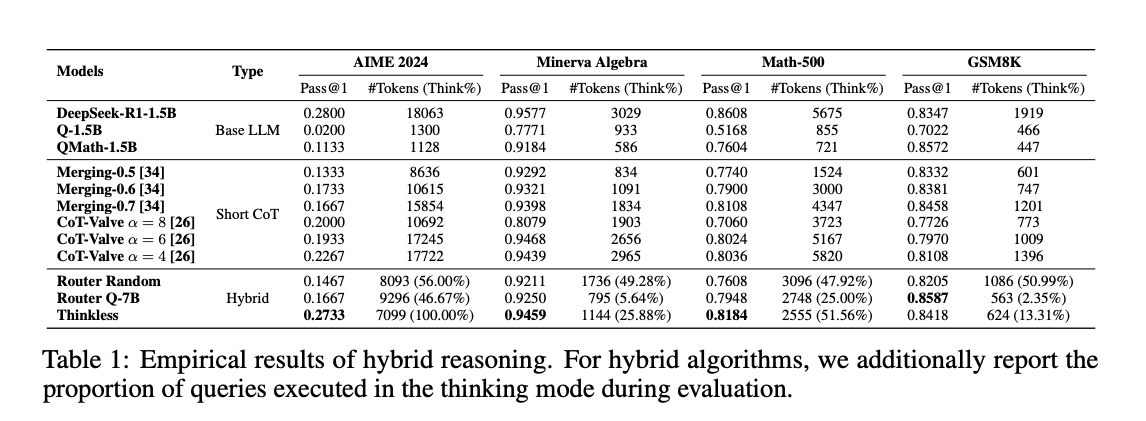
在 Minerva Algebra 数据集上,Thinkless 将长链推理的使用减少到25%,在 GSM8K 数据集上减少到13.31%,显著提高了推理效率。
-
Thinkless 能够根据问题的复杂度自适应地选择推理模式。对于简单问题,模型倾向于选择短形式推理;对于复杂问题,模型则选择长形式推理。
-
在减少推理长度的同时,Thinkless 保持了较高的准确率。例如,在 Minerva Algebra 数据集上,Thinkless 的准确率达到了94.59%,仅比全长链推理模型低1%。
-
与现有的混合推理方法相比,Thinkless 在多个数据集上表现更好。例如,在 AIME 2024 数据集上,Thinkless 的准确率达到27.33%,而基于路由器的方法准确率仅为16.67%。
4.2 DeGRPO 训练分析
-
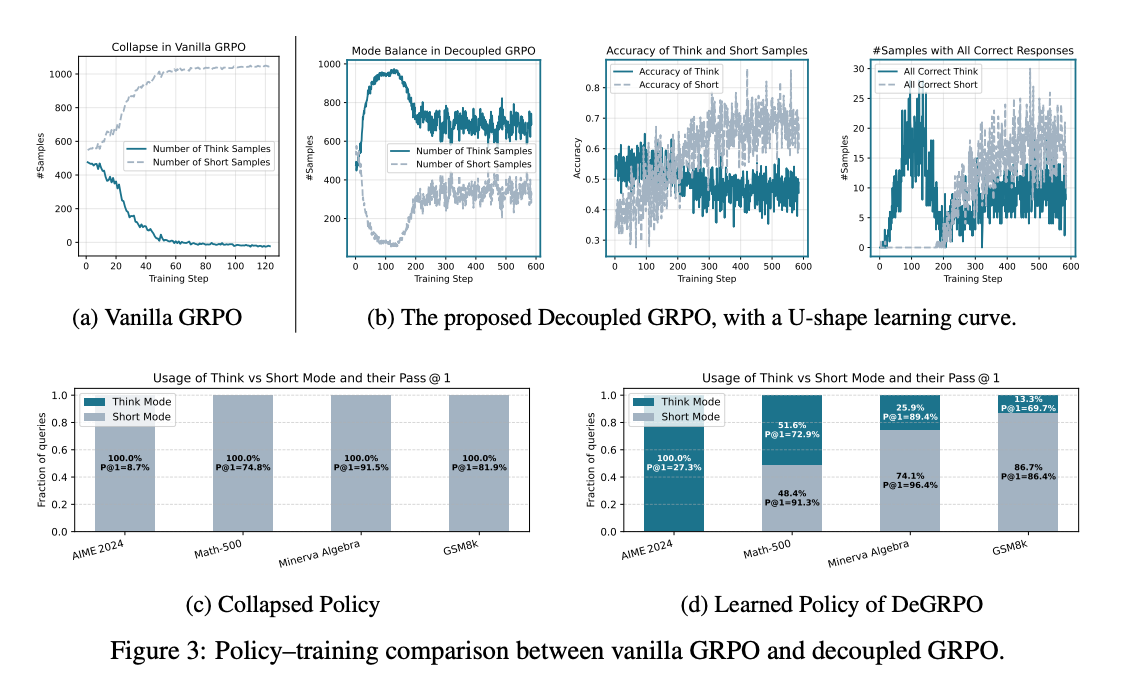
在标准 GRPO 中,模型在训练初期可能会过度偏好长链或短链推理,导致模式崩溃。而 DeGRPO 算法通过解耦训练目标,有效避免了这一问题。
-
DeGRPO 算法在训练过程中表现出U形学习曲线。初始阶段,长链推理的使用比例较高,随着训练的进行,短链推理的准确率逐渐提高,模型开始更多地选择短链推理,最终达到平衡。
五、总结
本文提出了Thinkless框架,其通过强化学习使LLMs能够自适应地选择推理模式。此外,设计了设计了DeGRPO强化学习算法,它通过解耦推理模式选择和响应准确性提升,平衡了两个学习目标的贡献。实验结果表明,Thinkless能够显著减少长链推理的使用,提高推理效率,同时保持较高的准确性。