LangGraph-example 学习
该
example来源于官方,主要用于快速了解LG 的基本使用,本文并没有对 LG 的详细说明,如果想要对他有深入认识可参考文章
该example构建可视化出来的结果图如下:
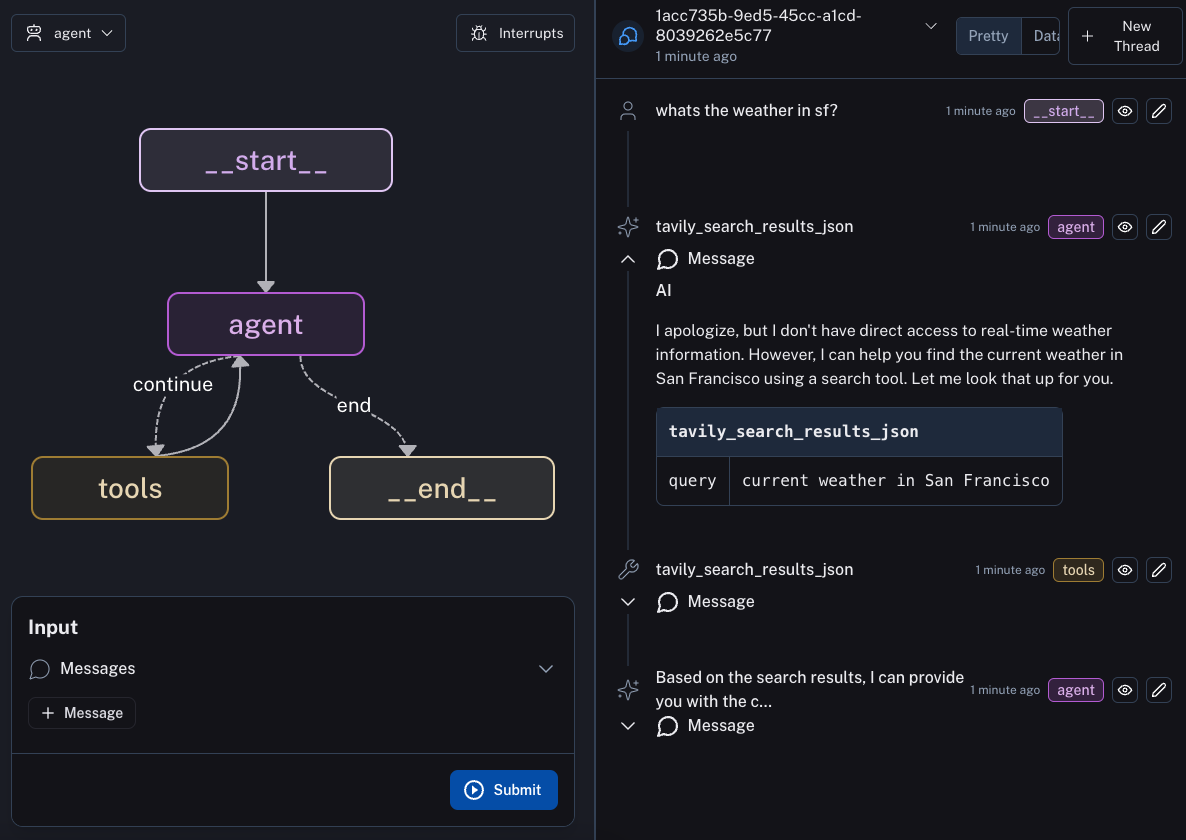
从图中可以发现除了特殊节点
Start和End,还有一个agent和tools节点,在该graph中执行流程如下:
- 用户输入
- 节点名为
agent首先响应然后调用节点名toolstools节点返回给agentagent判断tools结果是否符合预期,不符合继续调用tools,符合则走向End节点,End节点则认为graph结束上述流程在代码中有详细介绍,让我们跟着这个流程清晰认识 LG 的构建流程
1. Graph整体流程定义
- 图配置
此处可以定义图的参数信息,例如 LLM 等信息
# Define the config
class GraphConfig(TypedDict):model_name: Literal["anthropic", "openai"]
- 图定义
# 定义一个图,StateGraph是我们主要使用图定义的类,此处参数传入
# 整个图的状态以及图配置信息
workflow = StateGraph(AgentState, config_schema=GraphConfig)# 在该图中可以体现cycle为此处,即大模型与工具的交互
# 严谨一些讲应该是大模型参与的角色就可能有交互,这也是LG的最大意义
# 为了可以实现更好的应用效果,我们需要通过大模型的加入,但是大模型的加入
# 又会存在一些不确定性(如果只是传统的方法,程序输入输出是一种固定式的,那就不太需要 LG 的存在了,我们自己代码就可以去实现)
# LLM 对问题的理解,构建调用工具的提示词,对工具结果的判断理解等等
# 因此 Agent十分依赖大模型的能力
workflow.add_node("agent", llm_node)
workflow.add_node("action", tool_node)# set_entry_point定义了首先响应的节点是agent
workflow.set_entry_point("agent")# 图中除了节点,节点之间的边也至关重要,这影响到节点之间的逻辑关系
# 边我们已经讲到过存在普通边和条件边,对于条件边定义方法为add_conditional_edges
workflow.add_conditional_edges(# agent节点为该边的起始节点,也说明该边的执行是在agent节点执行后"agent",# 定义映射条件should_continue,# 定义映射关系,key为字符串(自己定义即可),value为其他节点# should_continue的输出将匹配映射关系,从而控制了该边的走向,即在agent之后执行哪个节点{# 如果should_continue输出是continue,则调用action节点"continue": "action",# 如果should_continue输出是end,则调用END节点"end": END,},
)# 刚才我们定义了条件边,控制了agent节点走向 action或者 end的逻辑关系
# 现在我们定义从action响应之后,将其直接返回给agent,这也意味着action响应之后会直接走向agent节点
workflow.add_edge("action", "agent")- 图编译
# 编译图,意味着他会编译成LangChain可运行程序
graph = workflow.compile()
- 条件边
def should_continue(state):messages = state["messages"]last_message = messages[-1]# If there are no tool calls, then we finishif not last_message.tool_calls:return "end"# Otherwise if there is, we continueelse:return "continue"
2. 节点定义
agent节点
@lru_cache(maxsize=4)
def _get_model(model_name: str):
# model_name定义内容在GraphConfig有定义if model_name == "openai":model = ChatOpenAI(temperature=0, model_name="gpt-4o")elif model_name == "anthropic":model = ChatAnthropic(temperature=0, model_name="claude-3-sonnet-20240229")else:raise ValueError(f"Unsupported model type: {model_name}")# 表示模型在执行过程中必要地方可以调用该工具model = model.bind_tools(tools)return modelsystem_prompt = """Be a helpful assistant"""# Define the function that calls the model
def llm_node(state, config):
# 获取输入信息messages = state["messages"]messages = [{"role": "system", "content": system_prompt}] + messagesmodel_name = config.get('configurable', {}).get("model_name", "anthropic")model = _get_model(model_name)response = model.invoke(messages)# We return a list, because this will get added to the existing listreturn {"messages": [response]}
- 工具节点
from langchain_community.tools.tavily_search import TavilySearchResults# 用于执行与 Tavily 搜索相关的任务
# max_results限制了最大返回结果数量
tools = [TavilySearchResults(max_results=1)]# Define the function to execute tools
tool_node = ToolNode(tools)
- 状态定义
from langgraph.graph import add_messages
from langchain_core.messages import BaseMessage
from typing import TypedDict, Annotated, Sequenceclass AgentState(TypedDict):
# 描述了一个包含 messages 字段的字典,其中 messages 是一个消息列表,
# 类型为 BaseMessage,并且有额外的注释 add_messagesmessages: Annotated[Sequence[BaseMessage], add_messages]
这次已经完成了一个
example的学习