LangGraph基础知识(Human-in-the-loop)(五)
一、HIL的由来
基于之前的学习我们可以构造出一个具有自主决策且根据任务路由和长期记忆的Agent。但是在实际的落地中,一个有趣且现实的情况是:我们希望`AI Agent`能够帮助我们自主处理各种任务,但当它现在有能力做到时,我们又开始担心它可能做出不当的决策,尤其是涉及到高风险操作时。比如,`Agent` 可能会不小心删除生产环境中的数据库,或是转移账户中的余额等敏感数据。这些操作是无法容忍的。
在自主代理类架构下衍生出的非常明确的一类需求是:能否在保持`Agent`自主决策的基础上,对某些可以预见或计划的关键节点引入人工干预,暂时中止其自我决策过程,转而由人工介入进行审批和确认,再让其继续执行后续任务?比如以下场景:
- 删除数据库操作:当`Agent`决定删除数据库时,可以先中止操作,要求人工确认是否继续执行。经过人工确认后,`Agent`才继续删除数据库并执行后续操作。
- 机票改签操作:当`Agent`决定更改机票时,系统会向用户发出通知,等待用户确认是否同意改签,用户点击确认后,`Agent`才会继续执行改签操作。
- .......
通过这种方式,既能保持`Agent`的自主性,又能避免出现意外或不可控的风险,实现人机协作的平衡。而实现这种功能的技术,在`Agent`技术领域会被普遍称之为`Human-in-the-loop`(HIL)。
二、交互图
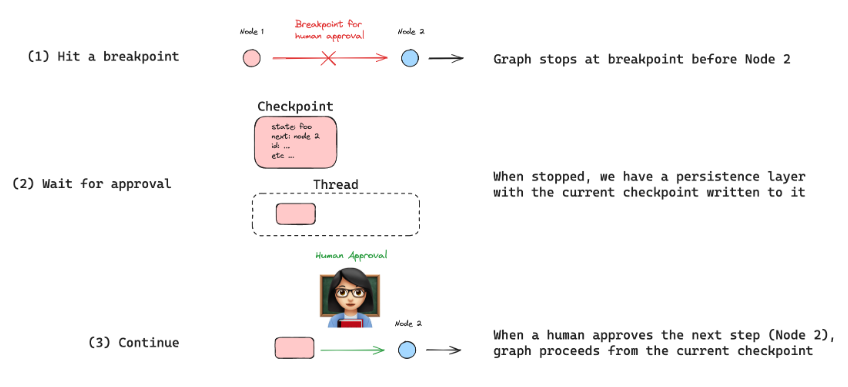
`LangGraph`能够在中断后继续运行的核心在于我们之前介绍的`checkpointer`组件。这个组件能够在一个独立的线程中保存图中每个节点的状态。由于这些信息被持久化保存(包括将内存用作持久存储),我们就可以随时提取并修改图产生的数据。更改完成后,再将这些数据重新传回到图中以继续运行流程。这一机制是`LangGraph`已成功实现的功能。**由此可见 `Human-in-the-loop (HIL)` 并不是一个全新的组件,而是基于`LangGraph`底层的构建组件延展出来的一种实现方法。那这里我们就需要清楚两个概念,其一是用于中断两个本应顺序执行节点的操作,在`LangGraph`中称其为`breakpoint`(断点),其二是`breakpoint`是构建在`checkpointer`之上的。
三、标准图结构中如何添加断点
如下代码实现的业务场景是一个自动化的人机交互流程,用于执行内容删除这种高度敏感性的操作。我们定义两个主要的功能节点:`call_model`和`execute_users`。`call_model`节点处理大模型的调用和响应,如果用户输入包含“删除”的内容,则会触发需要人工审批的流程。`execute_users`节点根据人工审核的结果来决定最终的响应内容。如下代码所示:
import getpass
import os
from dotenv import load_dotenv
load_dotenv()
from langchain_openai import ChatOpenAI# if not os.environ.get("OPENAI_API_KEY"):
# os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter your OpenAI API key: ")llm = ChatOpenAI(model="deepseek-chat")
from typing import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.memory import MemorySaver
from IPython.display import Image, display
from langchain_core.tools import tool
from langgraph.graph import MessagesState, START
from langgraph.prebuilt import ToolNode
from langgraph.graph import END, StateGraph
import json
from langgraph.checkpoint.memory import MemorySaver
from langchain_core.messages import AnyMessage, SystemMessage, HumanMessage, AIMessage# 定义状态模式
class State(TypedDict):user_input: strmodel_response: struser_approval: str# 定义用于大模型交互的节点
def call_model(state):messages = state["user_input"]if '删除' in state["user_input"]:state["user_approval"] = f"用户输入的指令是:{state['user_input']}, 请人工确认是否执行!"else:response = llm.invoke(messages)state["user_approval"] = "直接运行!"state["model_response"] = responsereturn state# 定义人工介入的breakpoint内部的执行逻辑
def execute_users(state):if state["user_approval"] == "是":response = "您的删除请求已经获得管理员的批准并成功执行。如果您有其他问题或需要进一步的帮助,请随时联系我们。"return {"model_response":AIMessage(response)}elif state["user_approval"] == "否":response = "对不起,您当前的请求是高风险操作,管理员不允许执行!"return {"model_response":AIMessage(response)} else:return state# 定义翻译节点
def translate_message(state: State):system_prompt = """Please translate the received text in any language into English as output"""messages = state['model_response']messages = [SystemMessage(content=system_prompt)] + [HumanMessage(content=messages.content)]response = llm.invoke(messages)return {"model_response": response}# 构建状态图
builder = StateGraph(State)# 向图中添加节点
builder.add_node("call_model", call_model)
builder.add_node("execute_users", execute_users)
builder.add_node("translate_message", translate_message)# 构建边
builder.add_edge(START, "call_model")
builder.add_edge("call_model", "execute_users")
builder.add_edge("execute_users", "translate_message")
builder.add_edge("translate_message", END)# 设置 checkpointer,使用内存存储
memory = MemorySaver()# 在编译图的时候,添加短期记忆,并使用interrupt_before参数 设置 在 execute_users 节点之前中止图的运行,等待人工审核
graph = builder.compile(checkpointer=memory, interrupt_before=["execute_users"])# 生成可视化图像结构
display(Image(graph.get_graph().draw_mermaid_png()))会输出构件流程图的可视化结构:
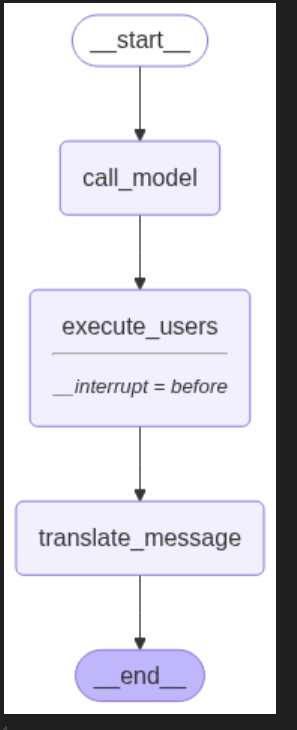
在添加了`breakpoint` (断点)后的图结构中,它的运行逻辑将变成:只要到达被设置为`breakpoint`的节点时,图就会中止运行。这里我们进行一个实际的调用测试来理解这个过程,代码如下所示:
# 创建一个线程
config = {"configurable": {"thread_id": "1"}}# 运行图,直至到断点的节点
async for chunk in graph.astream({"user_input": "我将在数据库中删除 id 为 1 的所有信息"}, config, stream_mode="values"):print(chunk)
# 运行结果{'user_input': '我将在数据库中删除 id 为 1 的所有信息', 'model_response': AIMessage(content='', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 44, 'prompt_tokens': 774, 'total_tokens': 818, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 704}, 'prompt_cache_hit_tokens': 704, 'prompt_cache_miss_tokens': 70}, 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_8802369eaa_prod0425fp8', 'id': 'a1015ba5-79b2-4a2a-b84b-babdabb6c5e9', 'finish_reason': 'stop', 'logprobs': None}, id='run--353ea15c-8524-4724-b063-e5ae5dbc2247-0', usage_metadata={'input_tokens': 774, 'output_tokens': 44, 'total_tokens': 818, 'input_token_details': {'cache_read': 704}, 'output_token_details': {}}), 'user_approval': '用户输入的指令是:我将在数据库中删除 id 为 1 的所有信息, 请人工确认是否执行!'}通过`get_state()`方法,可以查看到截至断点`breakpoint`前,图的运行过程中都产生了哪些状态信息:
snapshot = graph.get_state(config)
snapshot
# 运行结果
StateSnapshot(values={'user_input': '我将在数据库中删除 id 为 1 的所有信息', 'user_approval': '用户输入的指令是:我将在数据库中删除 id 为 1 的所有信息, 请人工确认是否执行!'}, next=('execute_users',), config={'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f048f6e-d729-6f95-8001-7c6c42292fde'}}, metadata={'source': 'loop', 'writes': {'call_model': {'user_input': '我将在数据库中删除 id 为 1 的所有信息', 'user_approval': '用户输入的指令是:我将在数据库中删除 id 为 1 的所有信息, 请人工确认是否执行!'}}, 'thread_id': '1', 'step': 1, 'parents': {}}, created_at='2025-06-14T08:09:43.135221+00:00', parent_config={'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f048f6e-d71c-67e7-8000-46e7983e8de3'}}, tasks=(PregelTask(id='82526634-ab72-7504-c7dd-6cb8f8bdf3e2', name='execute_users', path=('__pregel_pull', 'execute_users'), error=None, interrupts=(), state=None, result=None),))
我们先来看如何在图中止运行后,在图状态中添加用户的决策。
为实现这一点,我们可以手动设置`snapshot.values['user_approval']`为'是',用以说明在即将执行的`execute_users`节点,人工审批的状态被手动设定为同意。接下来,使用`graph.update_state(config, snapshot.values)`来更新状态图中的状态。这个调用将状态图中的当前状态更新为包含了新的`user_approval`值的`snapshot.values`。
snapshot.values['user_approval']='是'
graph.update_state(config, snapshot.values)修改完状态后,如果想让图基于`breakpoint`继续执行后续的操作,则只需要在`astream`方法中将`input`参数设置为 `None`, 则会让图形从上次中断的地方继续。如下代码所示:
async for chunk in graph.astream(None, config, stream_mode="values"):print(chunk)
# 运行结果
{'user_input': '我将在数据库中删除 id 为 1 的所有信息', 'user_approval': '是'}
{'user_input': '我将在数据库中删除 id 为 1 的所有信息', 'model_response': AIMessage(content='您的删除请求已经获得管理员的批准并成功执行。如果您有其他问题或需要进一步的帮助,请随时联系我们。', additional_kwargs={}, response_metadata={}), 'user_approval': '是'}
{'user_input': '我将在数据库中删除 id 为 1 的所有信息', 'model_response': AIMessage(content='Your deletion request has been approved by the administrator and successfully processed. If you have any other questions or need further assistance, please feel free to contact us.', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 31, 'prompt_tokens': 43, 'total_tokens': 74, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 43}, 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_8802369eaa_prod0425fp8', 'id': '6b81791f-b7c3-46e4-af42-1afc09545bc9', 'finish_reason': 'stop', 'logprobs': None}, id='run--938684a4-dd79-4780-8092-a6a71197b7ac-0', usage_metadata={'input_tokens': 43, 'output_tokens': 31, 'total_tokens': 74, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}}), 'user_approval': '是'}等待人工输入是一种常见的 HIL 交互模式,它能够允许我们构建的代理向用户提出需要确认的问题,并等待确认输入后再继续。其中具体要执行的关键步骤是:
1. 需要在图编译时通过`interrupt_before`或者`interrupt_after`设置断点。
2. 需要在图编译时设置一个`checkpointer` 来保存图的状态。
3. 需要使用 `.update_state` 来更新图的状态,其中要包含我们得到的人工响应。
4. 恢复图的执行,等待图运行结束,输出最终的响应结果。
我们可以把上述过程构建成一个具备多轮对话形式的人机交互流程,如下代码所示:
# 创建一个函数来封装对话逻辑
def run_dialogue(graph, config, all_chunks=[]):while True:# 接收用户输入user_input = input("请输入您的消息(输入'退出'结束对话):")if user_input.lower() == '退出':break# 运行图,直至到断点的节点for chunk in graph.stream({"user_input": user_input}, config, stream_mode="values"):all_chunks.append(chunk)# 处理可能的审批请求last_chunk = all_chunks[-1]if last_chunk["user_approval"] == f"用户输入的指令是:{last_chunk['user_input']}, 请人工确认是否执行!":user_approval = input(f"当前用户的输入是:{last_chunk['user_input']}, 请人工确认是否执行!请回复 是/否。")graph.update_state(config, {"user_approval": user_approval})# 继续执行图for chunk in graph.stream(None, config, stream_mode="values"):all_chunks.append(chunk)# 显示最终模型的响应print("人工智能助理:", all_chunks[-1]["model_response"].content)调用代码:
# 初始化配置和状态存储
config = {"configurable": {"thread_id": "2"}}# 使用该函数运行对话
run_dialogue(graph, config)四、 复杂代理架构中如何添加动态断点
上面案例中实现的人机交互模式,我们可以在不同的用户输入决策下完全自定义具体需要执行的操作逻辑。而这样的交互过程,我们可以手动实现来理解这个中间过程,当然也可以在`LangGraph`框架的封装下,借助`Router Agent`的机制从节点内部来进行动态管理,尤其是在涉及工具调用的`ReAct`框架下,其特征会更明显,且可以更加清晰的帮助我们理解`breakpoint`在图执行过程中的内部逻辑。其基本过程如下图所示:
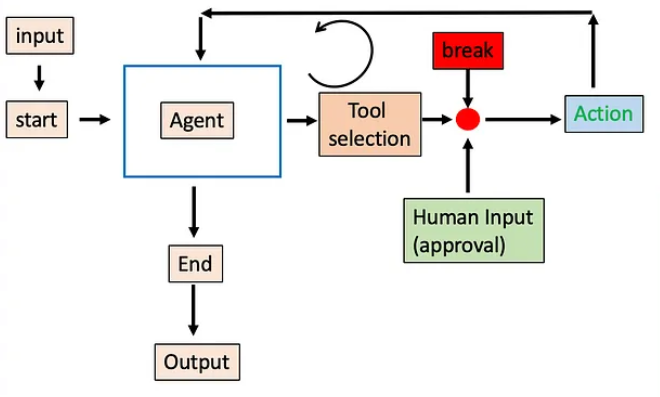
我们如何能做到在Tool Calling 的架构中,某些工具需要人工审核,某些工具不需要人工审核呢?由此才有了`dynamic breakpoints` (动态断点)的应用。
案例实战
我们可以根据`dynamic breakpoints` (动态断点)的思路进一步扩展`Agent`的复杂程度。
下面的案例中,我们实现一个灵活且自主的天气信息管理系统,这个系统通过四个主要的工具函数来操作天气数据,这些函数包括查询、插入、和删除天气信息,以及获取实时天气。其中我们将删除功能作为高危敏感工具,使用`dynamic breakpoints` 的机制来控制,仅当用户的需求触发`Agent`判断需要执行该工具时,由人工介入决定是否执行删除数据操作,具体的工具函数描述如下:
1. 获取实时天气(`get_weather`):此工具允许用户输入城市名称,通过调用`OpenWeather API`获取该城市当前的天气情况,返回的数据以JSON格式呈现,包括温度、天气状况等信息。
2. 插入天气信息到数据库(`insert_weather_to_db`):这个工具用于将获取的天气数据存入数据库。
3. 从数据库查询天气信息(`query_weather_from_db`):此工具允许用户通过城市名查询已存储的天气信息。
4. 从数据库删除天气信息(`delete_weather_from_db`):允许用户删除指定城市的天气信息。
在明确了系统的功能需求之后,我们现在开始进行具体的代码实现。首先,既然涉及到数据库的操作,我们先建立一个具体的数据表。
from sqlalchemy import create_engine, Column, Integer, String, Float
from sqlalchemy.orm import sessionmaker, declarative_base# 创建基类
Base = declarative_base()# 定义 WeatherInfo 模型
class Weather(Base):__tablename__ = 'weather'city_id = Column(Integer, primary_key=True) # 城市IDcity_name = Column(String(50)) # 城市名称main_weather = Column(String(50)) # 主要天气状况description = Column(String(100)) # 描述temperature = Column(Float) # 温度feels_like = Column(Float) # 体感温度temp_min = Column(Float) # 最低温度temp_max = Column(Float) # 最高温度# 数据库连接 URI
DATABASE_URI = 'mysql+pymysql://root:123456@localhost/langgraph_agent?charset=utf8mb4' # 这里要替换成自己的数据库连接串
engine = create_engine(DATABASE_URI)# 如果表不存在,则创建表
Base.metadata.create_all(engine)# 创建会话
Session = sessionmaker(bind=engine)
依次定义外部工具函数库。代码如下:
from langchain_core.tools import tool
from typing import Union, Optional
from pydantic import BaseModel, Field
import requestsclass WeatherLoc(BaseModel):location: str = Field(description="The location name of the city")class WeatherInfo(BaseModel):"""Extracted weather information for a specific city."""city_id: int = Field(..., description="The unique identifier for the city")city_name: str = Field(..., description="The name of the city")main_weather: str = Field(..., description="The main weather condition")description: str = Field(..., description="A detailed description of the weather")temperature: float = Field(..., description="Current temperature in Celsius")feels_like: float = Field(..., description="Feels-like temperature in Celsius")temp_min: float = Field(..., description="Minimum temperature in Celsius")temp_max: float = Field(..., description="Maximum temperature in Celsius")class QueryWeatherSchema(BaseModel):"""Schema for querying weather information by city name."""city_name: str = Field(..., description="The name of the city to query weather information")class DeleteWeatherSchema(BaseModel):"""Schema for deleting weather information by city name."""city_name: str = Field(..., description="The name of the city to delete weather information")@tool(args_schema = WeatherLoc)
def get_weather(location):"""Function to query current weather.:param loc: Required parameter, of type string, representing the specific city name for the weather query. \Note that for cities in China, the corresponding English city name should be used. For example, to query the weather for Beijing, \the loc parameter should be input as 'Beijing'.:return: The result of the OpenWeather API query for current weather, with the specific URL request address being: https://api.openweathermap.org/data/2.5/weather. \The return type is a JSON-formatted object after parsing, represented as a string, containing all important weather information."""# Step 1.构建请求url = "https://api.openweathermap.org/data/2.5/weather"# Step 2.设置查询参数params = {"q": location, "appid": "xxxx", # 输入API key"units": "metric", # 使用摄氏度而不是华氏度"lang":"zh_cn" # 输出语言为简体中文}# Step 3.发送GET请求response = requests.get(url, params=params)# Step 4.解析响应data = response.json()return json.dumps(data)@tool(args_schema=WeatherInfo)
def insert_weather_to_db(city_id, city_name, main_weather, description, temperature, feels_like, temp_min, temp_max):"""Insert weather information into the database."""session = Session() # 确保为每次操作创建新的会话try:# 创建天气实例weather = Weather(city_id=city_id,city_name=city_name,main_weather=main_weather,description=description,temperature=temperature,feels_like=feels_like,temp_min=temp_min,temp_max=temp_max)# 添加到会话session.add(weather)# 提交事务session.commit()return {"messages": [f"天气数据已成功存储至Mysql数据库。"]}except Exception as e:session.rollback() # 出错时回滚return {"messages": [f"数据存储失败,错误原因:{e}"]}finally:session.close() # 关闭会话@tool(args_schema=QueryWeatherSchema)
def query_weather_from_db(city_name: str):"""Query weather information from the database by city name."""session = Session()try:# 查询天气数据weather_data = session.query(Weather).filter(Weather.city_name == city_name).first()print(weather_data)if weather_data:return {"city_id": weather_data.city_id,"city_name": weather_data.city_name,"main_weather": weather_data.main_weather,"description": weather_data.description,"temperature": weather_data.temperature,"feels_like": weather_data.feels_like,"temp_min": weather_data.temp_min,"temp_max": weather_data.temp_max}else:return {"messages": [f"未找到城市 '{city_name}' 的天气信息。"]}except Exception as e:return {"messages": [f"查询失败,错误原因:{e}"]}finally:session.close() # 关闭会话@tool(args_schema=DeleteWeatherSchema)
def delete_weather_from_db(city_name: str):"""Delete weather information from the database by city name."""session = Session()try:# 查询要删除的天气数据weather_data = session.query(Weather).filter(Weather.city_name == city_name).first()if weather_data:# 删除记录session.delete(weather_data)session.commit()return {"messages": [f"城市 '{city_name}' 的天气信息已成功删除。"]}else:return {"messages": [f"未找到城市 '{city_name}' 的天气信息。"]}except Exception as e:session.rollback() # 出错时回滚return {"messages": [f"删除失败,错误原因:{e}"]}finally:session.close() # 关闭会话自己在申请查询天气的apikey
使用`ToolNode`构建外部工具库,代码如下:
from langgraph.prebuilt import ToolNodetools = [get_weather, insert_weather_to_db, query_weather_from_db, delete_weather_from_db]
tool_node = ToolNode(tools)接下来定义用于`Agent`的基座模型,并绑定外部工具库。
import getpass
import os
import json
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
from langgraph.graph import MessagesState, START
from langgraph.prebuilt import ToolNode
from langgraph.graph import END, StateGraph
from langgraph.checkpoint.memory import MemorySaver
from dotenv import load_dotenv
load_dotenv()
# if not os.environ.get("OPENAI_API_KEY"):
# os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter your OpenAI API key: ")llm = ChatOpenAI(model="deepseek-chat")
llm = llm.bind_tools(tools)def call_model(state):messages = state["messages"]response = llm.invoke(messages)return {"messages": [response]}def should_continue(state):messages = state["messages"]last_message = messages[-1]if not last_message.tool_calls:return "end"elif last_message.tool_calls[0]["name"] == "delete_weather_from_db":return "run_tool"else:return "continue"
def run_tool(state):new_messages = []tool_calls = state["messages"][-1].tool_calls# tools = [get_weather, insert_weather_to_db, query_weather_from_db, delete_weather_from_db]tools = [delete_weather_from_db]tools = {t.name: t for t in tools}for tool_call in tool_calls:tool = tools[tool_call["name"]]result = tool.invoke(tool_call["args"])new_messages.append({"role": "tool","name": tool_call["name"],"content": result,"tool_call_id": tool_call["id"],})return {"messages": new_messages}节点函数和路由函数定义完毕后,开始构建图的完整结构。代码如下:
workflow = StateGraph(MessagesState)workflow.add_node("agent", call_model)
workflow.add_node("action", tool_node)
workflow.add_node("run_tool", run_tool)workflow.add_edge(START, "agent")workflow.add_conditional_edges("agent",should_continue,{"continue": "action","run_tool":"run_tool","end": END,},
)workflow.add_edge("action", "agent")
workflow.add_edge("run_tool", "agent")最后,在编译图的阶段,添加`checkpointer` 与具体的 `breakpoint`。
memory = MemorySaver()graph = workflow.compile(checkpointer=memory, interrupt_before=["run_tool"])完整的`Agent`结构编译完成后,我们现在可以与该系统进行用户交互,进行功能的测试。首先进行常规的天气信息咨询:
config = {"configurable": {"thread_id": "9"}}for chunk in graph.stream({"messages": "北京的天气怎么样?,查询出来并保存在数据库中"}, config, stream_mode="values"):chunk["messages"][-1].pretty_print()运行结果:
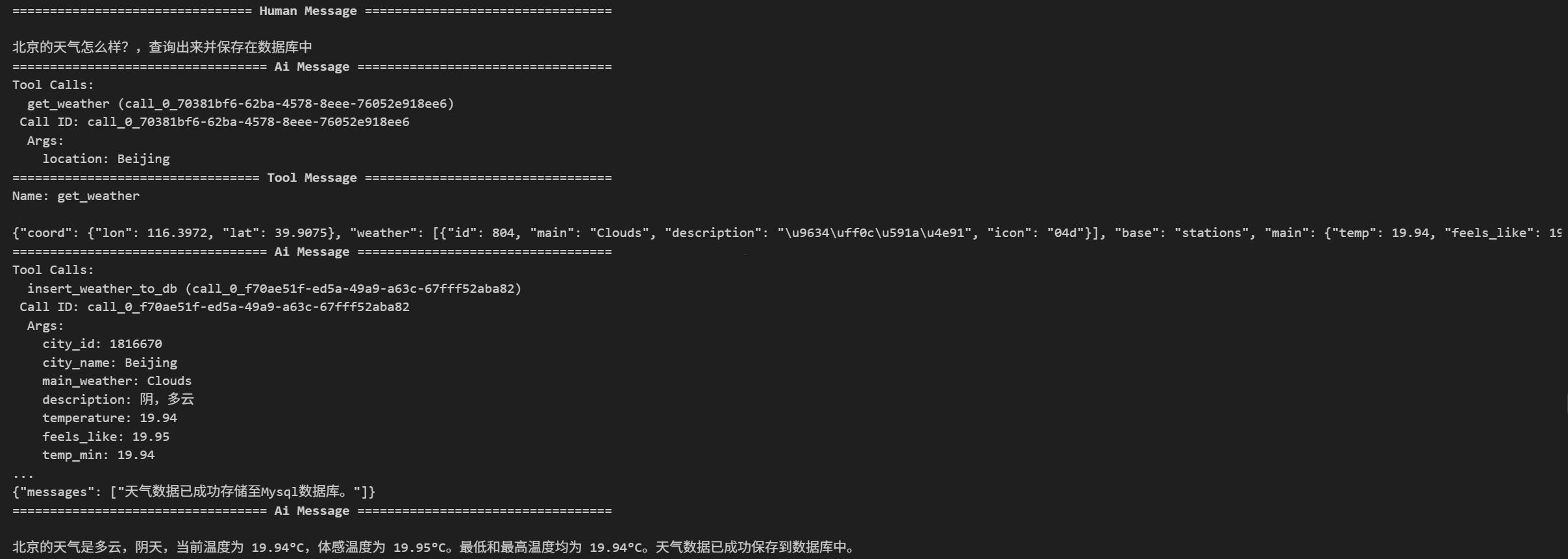
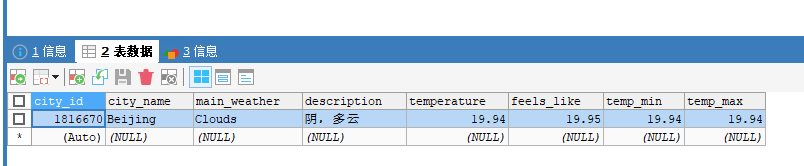
查看数据库中的数据:
而接下来,我们触发高危操作,让其删除数据库中的一些数据,请求如下:
config = {"configurable": {"thread_id": "9"}}for chunk in graph.stream({"messages": "帮我删除数据库中北京的天气数据"}, config, stream_mode="values"):chunk["messages"][-1].pretty_print()================================ Human Message ================================= 帮我删除数据库中北京的天气数据 ================================== Ai Message ================================== Tool Calls: delete_weather_from_db (call_0_ee2797a9-0158-4421-9f18-2cee6ba435ee) Call ID: call_0_ee2797a9-0158-4421-9f18-2cee6ba435ee Args: city_name: Beijing
首先还是同样,如果允许删除操作,仍然在`input`参数中填写`None`,将上述全部状态信息传递到图中使其恢复中断的执行,如下所示:
for chunk in graph.stream(None, config, stream_mode="values"):chunk["messages"][-1].pretty_print()
#运行结果
================================== Ai Message ==================================
Tool Calls:delete_weather_from_db (call_0_445628e9-7a5e-466f-b933-4d6bd4cf4a93)Call ID: call_0_445628e9-7a5e-466f-b933-4d6bd4cf4a93Args:city_name: Beijing
================================= Tool Message =================================
Name: delete_weather_from_db{'messages': ["城市 'Beijing' 的天气信息已成功删除。"]}
================================== Ai Message ==================================数据库中北京的天气数据已成功删除!查看数据库中天气数据:

接下来,我们就可以按照这种思路,去构建完全自动化的具有人工介入的自主循环代理工作流。这个过程的关键是:如何去处理执行外部工具或者不执行外部工具的操作逻辑。解决的思路是:当从用户那里获得自然语言反馈是不允许执行高危操作的时候,我们可以将这些反馈作为工具调用的模拟数据进行插入。代码如下所示:
config = {"configurable": {"thread_id": "10"}}for chunk in graph.stream({"messages": "帮我删除数据库中上海的天气数据"}, config, stream_mode="values"):state = graph.get_state(config)# print(state.next)# print(state.tasks)# 检查是否有任务,如果没有则结束循环if not state.tasks:# print("所有任务都已完成。")chunk["messages"][-1].pretty_print()breakif state.tasks[0].name == 'run_tool':while True:user_input = input("是否允许执行删除操作?请输入'是'或'否':")if user_input in ["是", "否"]:breakelse:print("输入错误,请输入'是'或'否'。")if user_input == "是":graph.update_state(config=config, values=chunk)for event in graph.stream(None, config, stream_mode="values"):event["messages"][-1].pretty_print()elif user_input == "否":state = graph.get_state(config)tool_call_id = state.values["messages"][-1].tool_calls[0]["id"]print(tool_call_id)#我们现在需要构造一个替换工具调用。把参数改为“xxsd”,请注意,我们可以更改任意数量的参数或工具名称-它必须是一个有效的new_message = {"role": "tool",# 这是得到的用户不允许操作的反馈"content": "管理员不允许执行该操作!","name": "delete_weather_from_db","tool_call_id": tool_call_id,}graph.update_state(config, {"messages": [new_message]}, as_node="run_tool",)for event in graph.stream(None, config, stream_mode="values"):event["messages"][-1].pretty_print()