高效I/O处理:模型与多路复用的探讨
目录
一、了解IO模型
(一)异步IO和同步IO
(二)五种IO快速回顾
二、IO多路复用
(一)IO 多路复用模型
(二)select 实现原理
(三)poll 实现原理
(四)epoll 实现原理
(五)总结
三、总结
参考推荐阅读
干货分享,感谢您的阅读!
在现代计算机系统中,输入/输出(I/O)操作的效率直接影响到整体性能与用户体验。无论是大型服务器处理海量请求,还是嵌入式设备与传感器的实时数据交互,了解 I/O 模型及其多路复用机制显得尤为重要。本文将深入探讨 I/O 的五种主要模型,包括阻塞、非阻塞、同步、异步以及信号驱动 I/O,解析它们的工作原理与适用场景。同时,我们还将聚焦多路复用技术的核心概念与实现方式,揭示其在提升并发处理能力、降低资源消耗中的关键作用。通过对这些基础理论的深入理解,您将能够更有效地设计与优化高性能应用程序,推动技术的不断进步与创新。
一、了解IO模型
I/O 模型是指在进行输入输出操作时,操作系统和应用程序之间如何进行交互的方式。
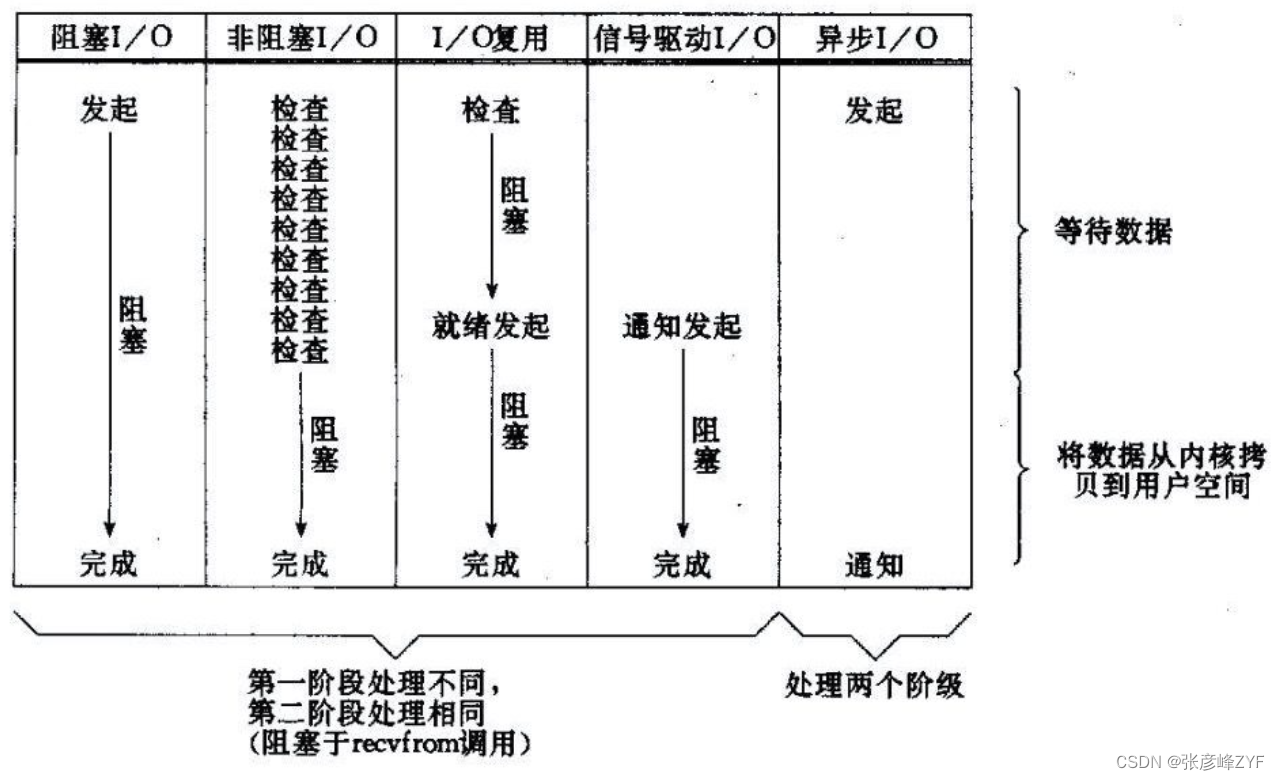
(一)异步IO和同步IO
上图中,阻塞式I/O、非阻塞式I/O、I/O复用、信号驱动式I/O 在操作系统层面都是同步IO,它们都会阻塞在数据从内核空间复制到用户空间的缓冲区;异步IO模型在两个阶段都不会阻塞调用进程,在操作系统层面实现真正的异步IO。
同步 I/O:
- 同步 I/O 模型是指进程发起一个 I/O 操作后,必须等待这个操作完成才能进行下一步操作。在这种模型下,当应用程序发起一个 I/O 请求时,它会被阻塞,直到操作系统将数据从内核空间复制到用户空间的缓冲区中,然后应用程序才能继续执行。
- 阻塞式 I/O、非阻塞式 I/O、I/O 复用、信号驱动式 I/O 这些模型都属于同步 I/O,因为它们都需要应用程序等待 I/O 操作完成才能进行下一步操作。
异步 I/O:
- 异步 I/O 模型则不同,当应用程序发起一个 I/O 请求后,它可以立即继续执行其他任务,不需要等待操作完成。当 I/O 操作完成后,操作系统会通知应用程序。
- 异步 I/O 模型确实能够在两个阶段都不阻塞调用进程,因为应用程序发起请求后就可以继续执行其他任务,而不必等待数据从内核空间复制到用户空间的缓冲区中。
- 异步 I/O 模型通常需要操作系统或硬件设备的支持,以便在 I/O 操作完成时通知应用程序。通常涉及到事件驱动的编程模式,比如回调函数或事件循环。异步 I/O 通常用于处理大量的并发连接或需要高性能的应用程序中。
(二)五种IO快速回顾
| 模型 | 描述 | 适用场景 |
|---|---|---|
| 阻塞式 I/O | 应用程序发起 I/O 请求后被阻塞,直到操作完成。 | 单任务环境,简单应用程序,对于少量连接或低并发的应用。 |
| 非阻塞式 I/O | 应用程序发起 I/O 请求后继续执行,但需要通过轮询等方式检查操作是否完成。 | 单任务环境,需要处理多个 I/O 事件,但需要谨慎处理轮询造成的 CPU 消耗。 |
| I/O 复用 | 允许一个进程同时监视多个文件描述符的 I/O 事件,当某个文件描述符准备好时通知应用程序。 | 需要同时处理多个 I/O 事件的场景,如网络服务器。 |
| 信号驱动式 I/O | 将信号处理函数与文件描述符关联,当文件描述符准备好进行 I/O 操作时,触发相应的信号处理函数。 | 某些需要提高应用程序性能的情况,但在处理复杂 I/O 事件时可能变得复杂。 |
| 异步 I/O | 应用程序发起 I/O 请求后立即返回,当操作完成时,操作系统通知应用程序。 | 需要高性能和高并发的应用程序,可以在两个阶段都不阻塞调用进程。 |
二、IO多路复用
(一)IO 多路复用模型
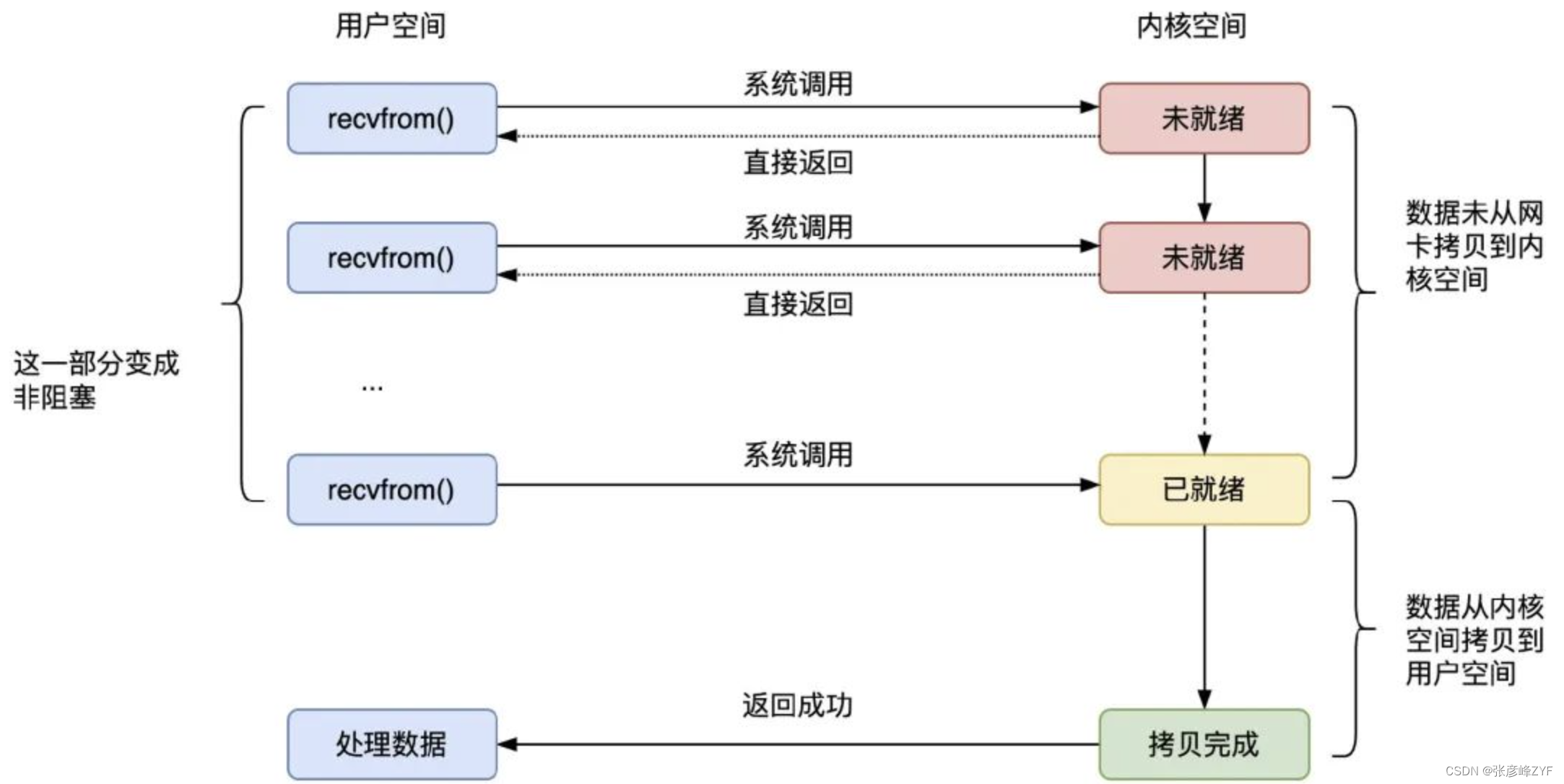
在使用多路复用模型时,通常会使用像 select()、poll()、epoll() 这样的系统调用。这些调用允许应用程序同时监视多个文件描述符,等待其中任何一个文件描述符就绪(即有数据可读或可写)。当文件描述符就绪时,这些系统调用会返回,并告知应用程序哪些文件描述符已经就绪。
然后,应用程序可以进一步操作就绪的文件描述符,比如调用 recvfrom() 函数将数据从内核空间拷贝到用户空间。尽管这个阶段仍然是阻塞的,但因为在 select() 或其他多路复用系统调用中已经知道哪些文件描述符有数据可读,因此整体上效率会有很大的提升。
(二)select 实现原理
select() 函数是一个用于多路复用 I/O 的系统调用,它允许一个进程监视多个文件描述符的状态,以确定它们是否处于可读、可写或异常状态。其基本原理是在内核中检查指定的文件描述符,并在其中任何一个文件描述符就绪时返回。
具体地,select() 函数参数分析如下:
- nfds:要检查的文件描述符的数量,即最大文件描述符加一。
- readfds:指向包含要检查是否可读的文件描述符集合的指针。
- writefds:指向包含要检查是否可写的文件描述符集合的指针。
- exceptfds:指向包含要检查是否有异常情况的文件描述符集合的指针。
- timeout:超时时间,指定
select()调用的最长等待时间,当为NULL时表示永远等待。
调用 select() 后,内核会遍历传入的文件描述符集合,检查它们的状态。如果有任何一个文件描述符就绪(可读、可写或异常),select() 就会返回。返回后,可以通过检查相应的文件描述符集合来确定哪些文件描述符处于就绪状态。
在实际使用中,通常会使用 FD_SET()、FD_CLR()、FD_ISSET() 等宏来设置和检查文件描述符集合。
具体可以看下以下代码中的标注:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>#define MAXCLINE 5 // 最大连接数
#define MAXBUF 1024 // 缓冲区大小int main(void)
{int sock_fd, i, ret;int fd[MAXCLINE]; // 存放连接的文件描述符队列struct sockaddr_in server_addr, client_addr;socklen_t sin_size = sizeof(struct sockaddr_in);char buf[MAXBUF];// 创建 socketsock_fd = socket(AF_INET, SOCK_STREAM, 0);if (sock_fd < 0) {perror("socket");exit(EXIT_FAILURE);}// 绑定 socketserver_addr.sin_family = AF_INET;server_addr.sin_port = htons(8888);server_addr.sin_addr.s_addr = INADDR_ANY;memset(&(server_addr.sin_zero), 0, sizeof(server_addr.sin_zero));if (bind(sock_fd, (struct sockaddr *)&server_addr, sizeof(server_addr)) < 0) {perror("bind");exit(EXIT_FAILURE);}// 监听 socketif (listen(sock_fd, 5) < 0) {perror("listen");exit(EXIT_FAILURE);}// 接受连接,并将连接的文件描述符存入数组for (i = 0; i < MAXCLINE; i++) {fd[i] = accept(sock_fd, (struct sockaddr *)&client_addr, &sin_size);if (fd[i] < 0) {perror("accept");exit(EXIT_FAILURE);}}// 循环监听连接上的数据是否到达while (1) {fd_set fdsr; // 用于存放需要监听的文件描述符集合FD_ZERO(&fdsr); // 清空文件描述符集合// 将要监听的文件描述符加入集合int max = 0;for (i = 0; i < MAXCLINE; i++) {FD_SET(fd[i], &fdsr);if (fd[i] > max)max = fd[i];}// 调用 select 进行多路复用ret = select(max + 1, &fdsr, NULL, NULL, NULL);if (ret < 0) {perror("select");exit(EXIT_FAILURE);}// 遍历文件描述符集合,判断哪些连接有数据到达for (i = 0; i < MAXCLINE; i++) {if (FD_ISSET(fd[i], &fdsr)) { // 文件描述符有数据到达ret = recv(fd[i], buf, sizeof(buf), 0);if (ret < 0) {perror("recv");exit(EXIT_FAILURE);} else if (ret == 0) { // 对方关闭连接printf("Connection closed by client.\n");close(fd[i]);FD_CLR(fd[i], &fdsr); // 从文件描述符集合中清除} else {buf[ret] = '\0';printf("Received message from client %d: %s\n", i + 1, buf);}}}}return 0;
}
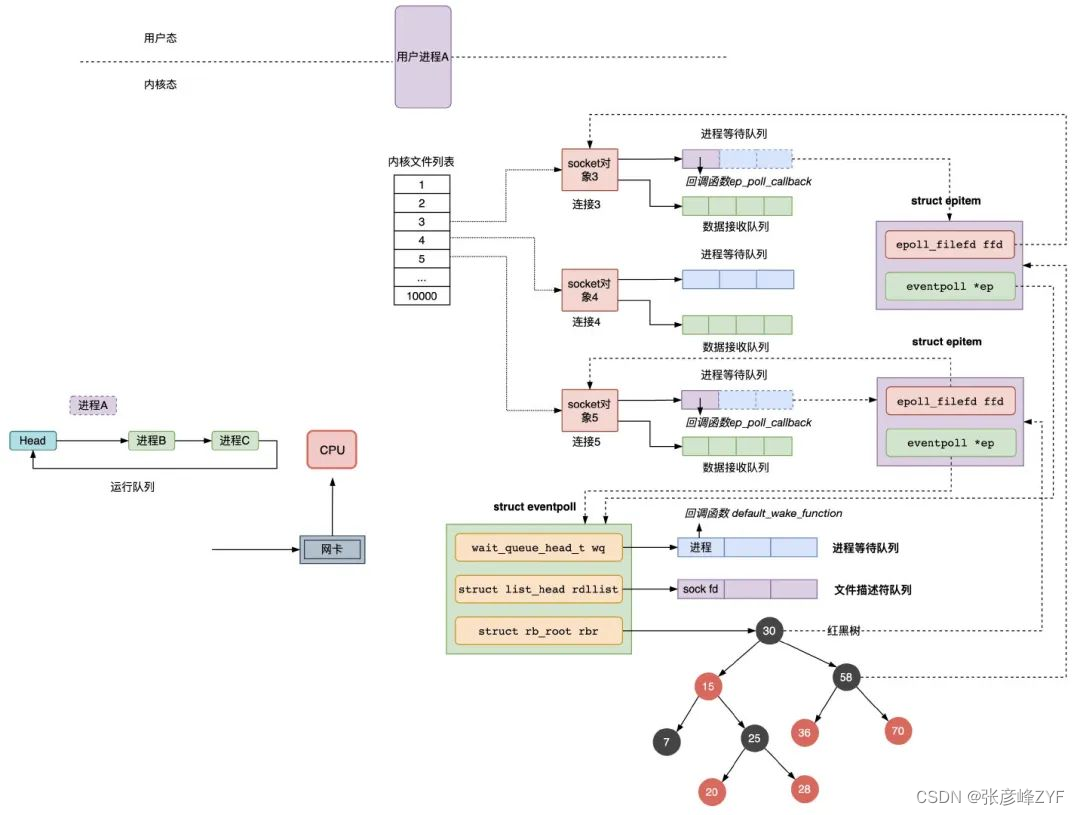
select 的执行过程
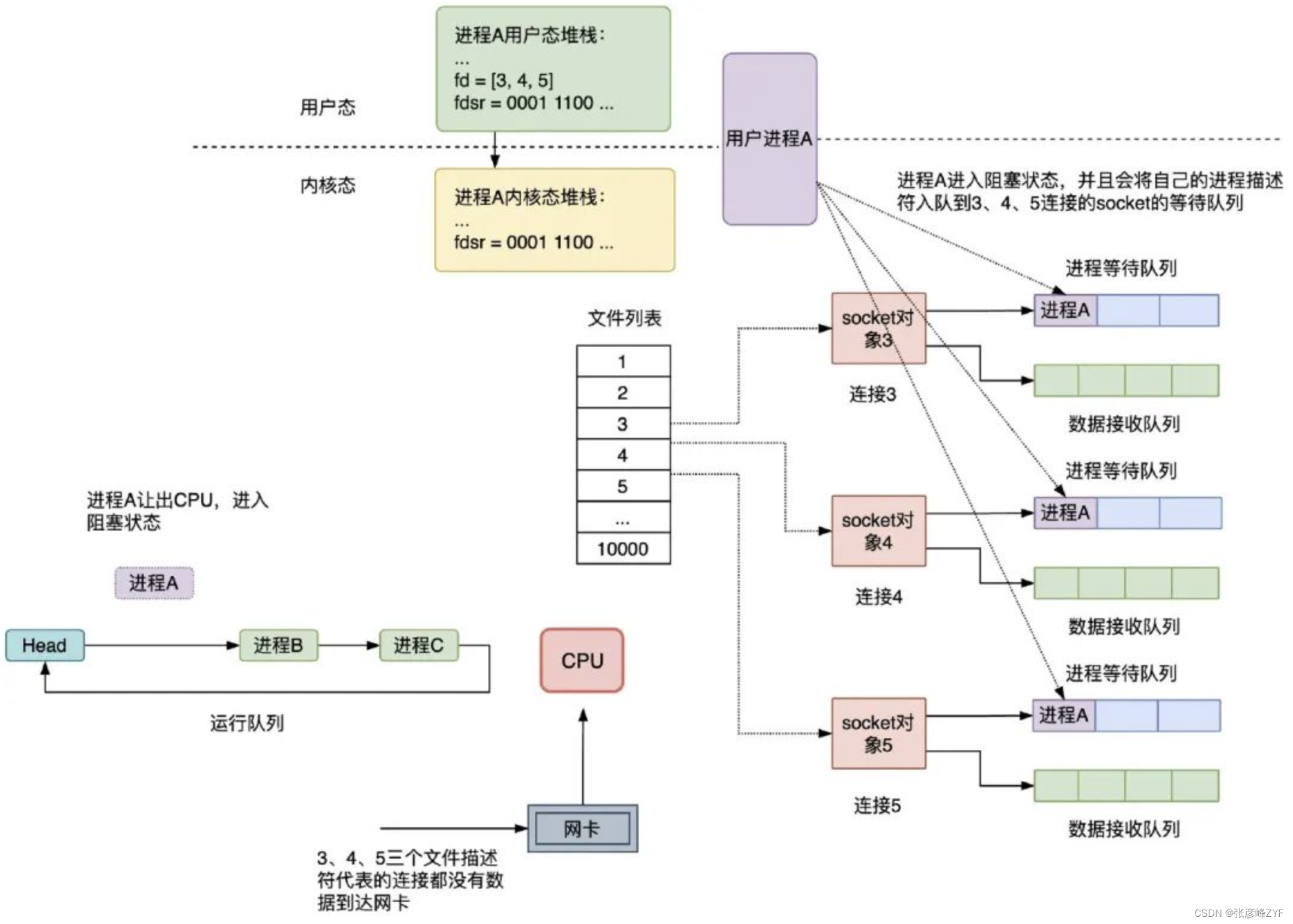
在服务器进程 A 启动的时候,要监听的连接的 socket 文件描述符是 3、4、5,如果这三个连接均没有数据到达网卡,则进程 A 会让出 CPU,进入阻塞状态,同时会将进程 A 的进程描述符和被唤醒时用到的回调函数组成等待队列项加入到 socket 对象 3、4、5 的进程等待队列中,注意,这时 select 调用时fdsr 文件描述符集会从用户空间拷贝到内核空间,如下图所示:
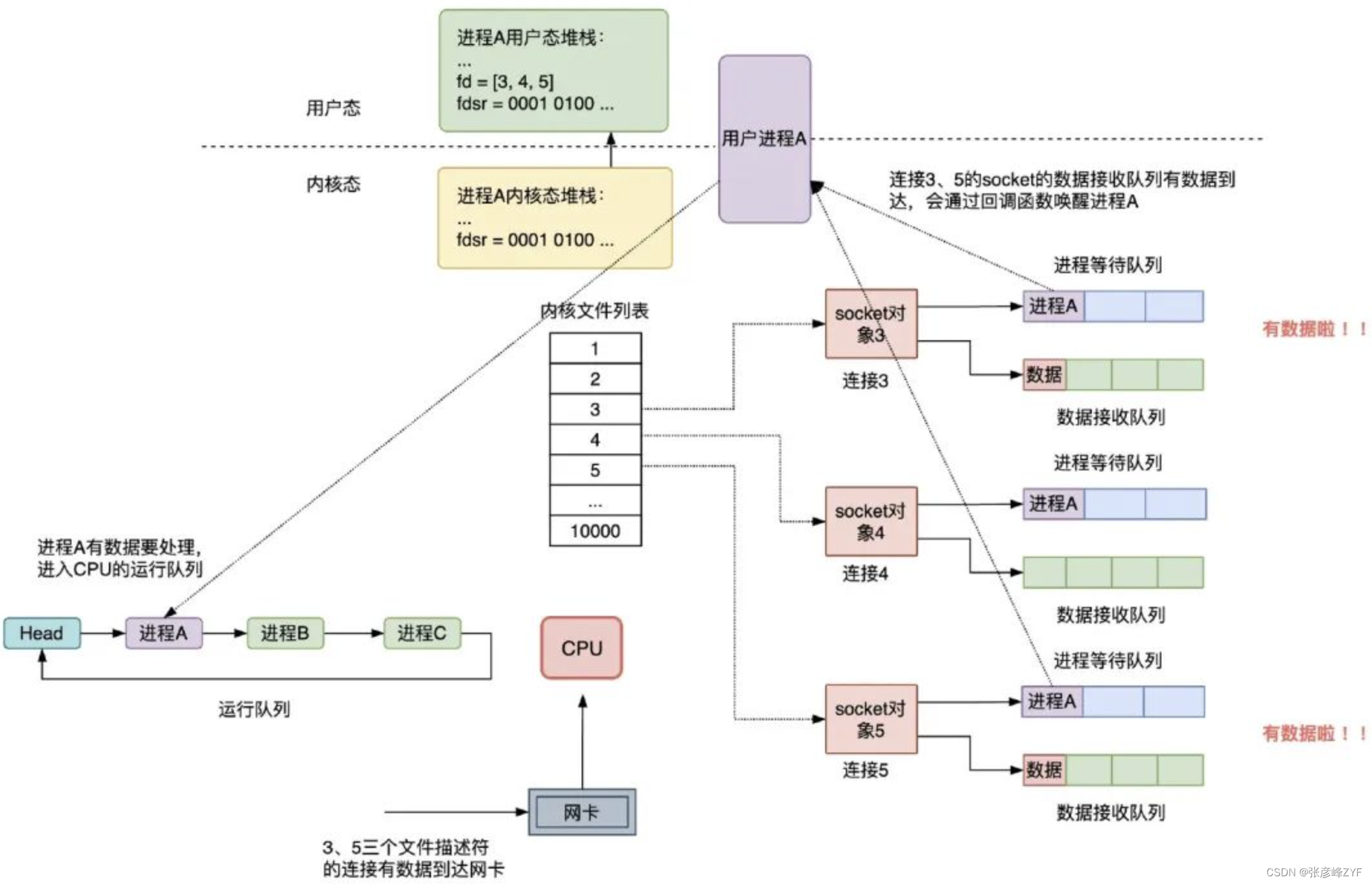
当网卡接收到数据,然后网卡通过中断信号通知 CPU 有数据到达,执行中断程序,中断程序主要做了两件事:
- 将网络数据写入到对应 socket 的数据接收队列里面;
- 唤醒队列中的等待进程 A,重新将进程 A 放入 CPU 的运行队列中;
假设连接 3、5 有数据到达网卡,注意,这时 select 调用结束时,fdsr 文件描述符集会从内核空间拷贝到用户空间:
(三)poll 实现原理
poll() 函数是一种多路复用 I/O 模型,与 select() 类似,允许一个进程监视多个文件描述符,等待其中任何一个文件描述符就绪(即有数据可读或可写):
-
准备文件描述符数组:在调用
poll()函数之前,需要准备一个struct pollfd类型的数组,数组的每个元素对应一个待监视的文件描述符。结构体中包含文件描述符的值以及所关心的事件,如可读、可写等。 -
调用
poll():一旦文件描述符数组准备好,程序会调用poll()函数,将数组和数组中元素的个数传递给它。poll()函数会在这些文件描述符中的任何一个就绪时返回。 -
检查返回值:一旦
poll()函数返回,程序会检查返回值,以确定哪些文件描述符已经就绪。通常返回值表示就绪文件描述符的个数。 -
处理就绪文件描述符:程序员可以遍历检查每个文件描述符对应的
pollfd结构体,以确定哪些文件描述符处于就绪状态。然后可以执行相应的读取或写入操作。
在内核层面,poll() 函数的实现通常会使用轮询机制,检查每个文件描述符是否已经就绪。不同于 select(),poll() 传递的是指向结构体数组的指针,因此无需复制文件描述符集合到内核空间,这在一定程度上减少了开销。
与 select() 不同的是,poll() 没有最大文件描述符数的限制,因为它使用了结构体数组而不是位图来表示文件描述符。因此poll() 在处理大量文件描述符时,通常比 select() 更有效率。
使用 poll() 函数简单实现多路复用 I/O:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <sys/types.h>
#include <errno.h>
#include <string.h>
#include <poll.h>#define MAX_CLIENTS 5
#define PORT 8888int main() {int i, ret, sockfd, newsockfd;struct sockaddr_in serv_addr, cli_addr;socklen_t addrlen = sizeof(struct sockaddr_in);struct pollfd fds[MAX_CLIENTS + 1]; // +1 for the listening socket// Create socketsockfd = socket(AF_INET, SOCK_STREAM, 0);if (sockfd < 0) {perror("socket");exit(EXIT_FAILURE);}// Set up server addressmemset(&serv_addr, 0, sizeof(serv_addr));serv_addr.sin_family = AF_INET;serv_addr.sin_addr.s_addr = htonl(INADDR_ANY);serv_addr.sin_port = htons(PORT);// Bind socketif (bind(sockfd, (struct sockaddr*)&serv_addr, sizeof(serv_addr)) < 0) {perror("bind");exit(EXIT_FAILURE);}// Listen for incoming connectionsif (listen(sockfd, MAX_CLIENTS) < 0) {perror("listen");exit(EXIT_FAILURE);}// Initialize pollfd structuresfds[0].fd = sockfd;fds[0].events = POLLIN;for (i = 1; i <= MAX_CLIENTS; i++) {fds[i].fd = -1;}while (1) {// Call pollret = poll(fds, MAX_CLIENTS + 1, -1);if (ret < 0) {perror("poll");exit(EXIT_FAILURE);}// Check for new connectionif (fds[0].revents & POLLIN) {newsockfd = accept(sockfd, (struct sockaddr*)&cli_addr, &addrlen);if (newsockfd < 0) {perror("accept");exit(EXIT_FAILURE);}// Add new client to fds arrayfor (i = 1; i <= MAX_CLIENTS; i++) {if (fds[i].fd == -1) {fds[i].fd = newsockfd;fds[i].events = POLLIN;break;}}if (i > MAX_CLIENTS) {fprintf(stderr, "Too many clients\n");close(newsockfd);}if (--ret <= 0) continue;}// Check for data from clientsfor (i = 1; i <= MAX_CLIENTS; i++) {if (fds[i].fd != -1 && (fds[i].revents & POLLIN)) {char buffer[1024];ret = recv(fds[i].fd, buffer, sizeof(buffer), 0);if (ret < 0) {perror("recv");close(fds[i].fd);fds[i].fd = -1;} else if (ret == 0) {printf("Client disconnected\n");close(fds[i].fd);fds[i].fd = -1;} else {printf("Received message from client %d: %s\n", i, buffer);}if (--ret <= 0) break;}}}close(sockfd);return 0;
}
- 在初始化
pollfd结构体数组之后,通过poll()函数等待任何一个文件描述符就绪。 - 如果监听套接字(
sockfd)上有新连接到来,poll()函数会检测到并调用accept()接受连接,然后将新的客户端套接字添加到pollfd数组中。 - 如果某个客户端套接字上有数据到达,
poll()函数同样会检测到并调用recv()接收数据,并进行相应的处理。
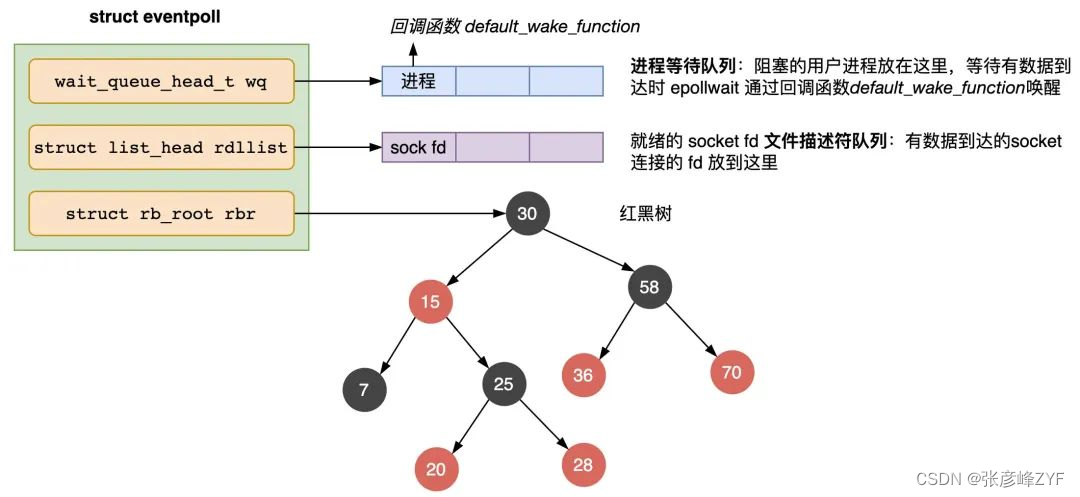
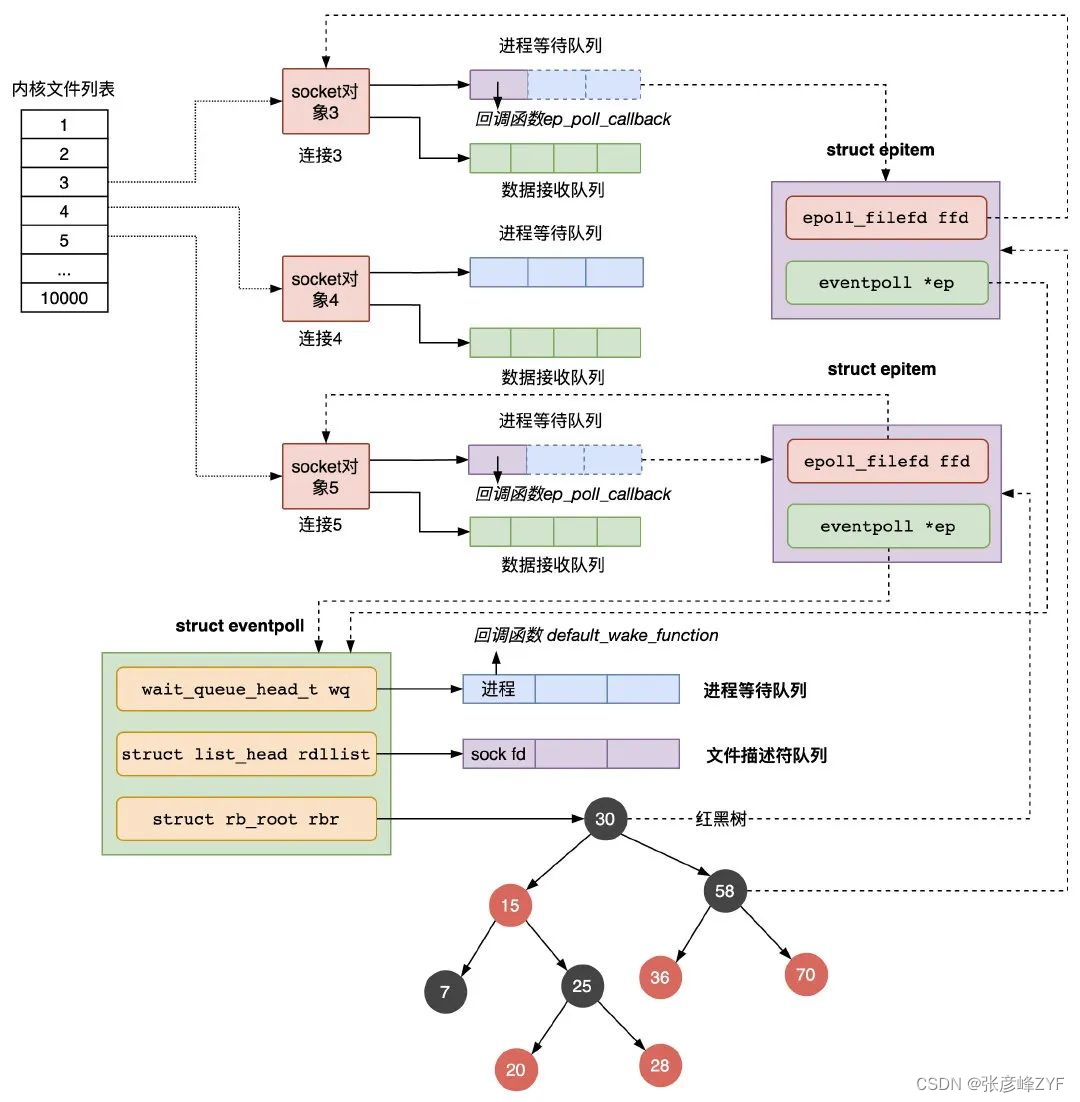
(四)epoll 实现原理
epoll 是 Linux 系统提供的一种高效的多路复用 I/O 模型,相比于 select 和 poll,它在处理大量连接时有更好的性能表现。
数据结构:
epoll使用了三种主要数据结构:epoll_create()创建的 epoll 实例,epoll_ctl()用于修改监听的文件描述符集合,以及epoll_wait()用于等待就绪事件的函数。- 内核维护了一个红黑树(rbtree),用于存储需要监听的文件描述符。这个树的节点是一个
epitem结构体,包含文件描述符、事件类型等信息。 - 另外,内核还维护了一个链表,用于存储当前就绪的事件,这个链表的节点是
rdllink结构体。
epoll 实例:
- 使用
epoll_create()创建一个 epoll 实例,返回一个文件描述符,这个描述符代表了一个 epoll 对象。 - epoll 实例是一个文件描述符,通过对这个描述符进行操作,可以控制对哪些文件描述符进行监听以及对就绪事件的处理。
添加和删除文件描述符:
- 使用
epoll_ctl()函数向 epoll 实例中添加或删除要监听的文件描述符。 - 添加文件描述符时,会创建一个
epitem结构体,将其插入到红黑树中。 - 删除文件描述符时,会将对应的
epitem结构体从红黑树中移除。
等待就绪事件:
- 使用
epoll_wait()函数等待文件描述符的就绪事件。 - 内核会遍历红黑树,检查哪些文件描述符已经就绪,将其加入到就绪链表中。
- 用户空间可以通过
epoll_wait()返回的事件列表来获取就绪的文件描述符,并进行相应的处理。
总的来说,epoll 的实现原理涉及了三个主要的数据结构:红黑树、链表和 epoll 实例。它通过将文件描述符的就绪事件保存在内核空间的数据结构中,避免了 select 和 poll 中频繁的内存复制操作,从而提高了处理大量连接时的效率。
epoll 的基本用法是:
int main(void) {struct epoll_event events[5];int epfd = epoll_create(10); // 创建一个 epoll 对象......for(i = 0; i < 5; i++){static struct epoll_event ev;.....ev.data.fd = accept(sock_fd, (struct sockaddr *)&client_addr, &sin_size);ev.events = EPOLLIN;epoll_ctl(epfd, EPOLL_CTL_ADD, ev.data.fd, &ev); // 向 epoll 对象中添加要管理的连接}while(1){nfds = epoll_wait(epfd, events, 5, 10000); // 等待其管理的连接上的 IO 事件for(i=0; i<nfds; i++){......read(events[i].data.fd, buff, MAXBUF)}}
主要涉及到三个函数:
// 创建一个 eventpoll 内核对象
int epoll_create(int size);
// 将连接到socket对象添加到 eventpoll 对象上,epoll_event是要监听的事件
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
// 等待连接 socket 的数据是否到达
int epoll_wait(int epfd, struct epoll_event *events,int maxevents, int timeout); epoll_create
epoll_ctl
epoll_wait
(五)总结
下面是使用 select、poll 和 epoll 实现 IO 多路复用的简单对比分析:
| 特点 | select | poll | epoll |
|---|---|---|---|
| 文件描述符数量限制 | 通常受限于文件描述符数量 | 通常受限于文件描述符数量 | 没有显著限制 |
| 内核空间数据结构 | 使用位图表示文件描述符集合 | 使用数组表示文件描述符集合 | 使用红黑树存储文件描述符 |
| 内存复制开销 | 需要将文件描述符集合复制到内核空间 | 需要将文件描述符集合复制到内核空间 | 无需将文件描述符集合复制到内核空间 |
| 时间复杂度 | O(n) | O(n) | O(log n) |
| 适用场景 | 文件描述符数量少且不频繁变化 | 文件描述符数量少且不频繁变化 | 文件描述符数量大且频繁变化 |
| 并发连接处理性能 | 性能较差 | 性能较好 | 性能最佳 |
从上表中可以看出:
select和poll的效率都受到文件描述符数量的限制,并且需要将文件描述符集合复制到内核空间,因此在处理大量连接时效率较低。epoll利用了红黑树来存储文件描述符,避免了内存复制的开销,并且在文件描述符数量较大且频繁变化时性能最佳。- 因此,对于高并发的网络应用,通常选择
epoll来实现 IO 多路复用,而select和poll则适用于文件描述符数量较少且不频繁变化的情况。
三、总结
在本文中,我们探讨了 I/O 操作的五种主要模型及其在现代计算机系统中的应用,分别是阻塞 I/O、非阻塞 I/O、同步 I/O、异步 I/O 和信号驱动 I/O。通过分析这些模型的特点与适用场景,我们了解到每种模型都有其独特的优势与局限性,开发者可以根据具体需求选择最合适的 I/O 方案。
此外,我们深入讨论了多路复用技术,包括 select、poll 和 epoll 等实现方式,揭示了它们在处理高并发请求中的重要性。多路复用不仅能够有效减少系统资源的浪费,还能够提升 I/O 操作的响应速度,使得高性能应用得以顺畅运行。
通过对 I/O 模型与多路复用技术的深入理解,开发者将能够更好地优化应用程序,提升整体性能,为用户提供更加流畅的体验。随着技术的不断发展,掌握这些基础知识将为您在计算机科学与软件开发领域的进一步探索打下坚实的基础。
参考推荐阅读
彻底搞懂IO模型:五种IO模型透彻分析 | 骏马金龙
高性能IO模型分析-IO模型简介(一) - 知乎
https://blog.51cto.com/u_15287666/4917767
IO模型:BIO、NIO、AIO的解析与应用-百度开发者中心
谈谈你对IO多路复用机制的理解-io 多路复用
https://www.cnblogs.com/yrxing/p/14143644.html
https://www.cnblogs.com/88223100/p/Deeply-learn-the-implementation-principle-of-IO-multiplexing-select_poll_epoll.html
你管这破玩意叫 IO 多路复用?-阿里云开发者社区
select - 彻底搞懂IO多路复用 - 个人文章 - SegmentFault 思否