使用 LangChain 和 Neo4j 构建知识图谱
在现代 AI 应用中,将文本内容结构化为知识图谱是一种非常实用的方法,可以帮助我们更高效地进行信息查询、知识推理和数据分析。本文将结合 LangChain 官方文档 和实战代码,演示如何使用 LangChain + Neo4j 将文本内容自动转换为知识图谱。
环境准备
我们需要以下组件:
-
Python 3.10+
-
Neo4j 数据库 (可以通过docker 来安装)
-
LangChain 及社区扩展模块
-
统一 AI 模型(如 ChatTongyi 或 Qwen 系列)
首先,安装必要依赖:
pip install langchain langchain-neo4j langchain-community
并确保 Neo4j 服务在本地运行:
docker 安装的命令:
docker run --name neo4j -p7474:7474 -p7687:7687 -d -e NEO4J_AUTH=neo4j/xxxx -e NEO4JLABS_PLUGINS='["apoc"]' -e NEO4J_apoc_export_file_enabled=true -e NEO4J_apoc_import_file_enabled=true -e NEO4J_apoc_import_file_use__neo4j__config=true neo4j:latest核心思路
本文示例展示了如何:
-
使用 LLM(大语言模型)分析文本;
-
将文本转换为图谱节点和关系;
-
将生成的图谱写入 Neo4j 数据库。
主要流程图如下:
文本 → LLM → 图谱节点/关系 → Neo4j
示例代码解析
下面是完整代码示例:
import asyncio
import osfrom langchain_neo4j import Neo4jGraph
from langchain_community.chat_models import ChatTongyios.environ["NEO4J_URI"] = "bolt://localhost:7687"
os.environ["NEO4J_USERNAME"] = "neo4j"
os.environ["NEO4J_PASSWORD"] = "xxxx"async def test():# 初始化 LLMllm = ChatTongyi(model="qwen-plus", api_key="YOUR_API_KEY")# 连接 Neo4j 图数据库graph = Neo4jGraph(refresh_schema=False)# 引入图谱转换器from langchain_experimental.graph_transformers import LLMGraphTransformerllm_transformer = LLMGraphTransformer(llm=llm)# 准备文本from langchain_core.documents import Documenttext = """Marie Curie, born in 1867, was a Polish and naturalised-French physicist and chemist who conducted pioneering research on radioactivity.She was the first woman to win a Nobel Prize, the first person to win a Nobel Prize twice, and the only person to win a Nobel Prize in two scientific fields.Her husband, Pierre Curie, was a co-winner of her first Nobel Prize, making them the first-ever married couple to win the Nobel Prize and launching the Curie family legacy of five Nobel Prizes.She was, in 1906, the first woman to become a professor at the University of Paris."""documents = [Document(page_content=text)]# 将文本转换为图谱文档graph_documents = await llm_transformer.aconvert_to_graph_documents(documents)print(f"Nodes:{graph_documents[0].nodes}")print(f"Relationships:{graph_documents[0].relationships}")# 写入 Neo4jgraph.add_graph_documents(graph_documents)if __name__ == '__main__':asyncio.run(test())
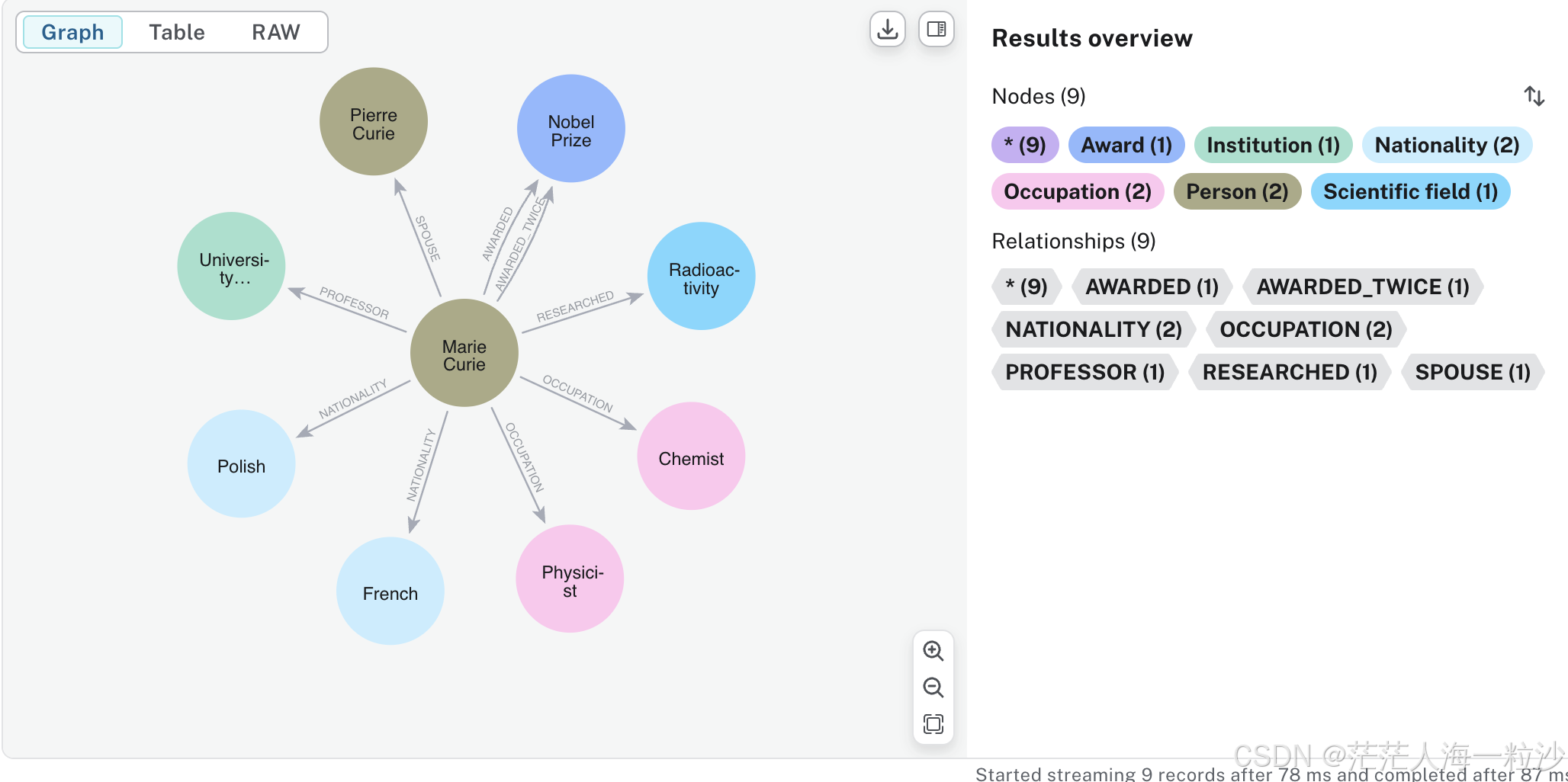
运行结果
Nodes:[Node(id='Marie Curie', type='Person', properties={}), Node(id='Polish', type='Nationality', properties={}), Node(id='French', type='Nationality', properties={}), Node(id='Physicist', type='Occupation', properties={}), Node(id='Chemist', type='Occupation', properties={}), Node(id='Radioactivity', type='Scientific field', properties={}), Node(id='Nobel Prize', type='Award', properties={}), Node(id='Pierre Curie', type='Person', properties={}), Node(id='University Of Paris', type='Institution', properties={})]
Relationships:[Relationship(source=Node(id='Marie Curie', type='Person', properties={}), target=Node(id='Polish', type='Nationality', properties={}), type='NATIONALITY', properties={}), Relationship(source=Node(id='Marie Curie', type='Person', properties={}), target=Node(id='French', type='Nationality', properties={}), type='NATIONALITY', properties={}), Relationship(source=Node(id='Marie Curie', type='Person', properties={}), target=Node(id='Physicist', type='Occupation', properties={}), type='OCCUPATION', properties={}), Relationship(source=Node(id='Marie Curie', type='Person', properties={}), target=Node(id='Chemist', type='Occupation', properties={}), type='OCCUPATION', properties={}), Relationship(source=Node(id='Marie Curie', type='Person', properties={}), target=Node(id='Radioactivity', type='Scientific field', properties={}), type='RESEARCHED', properties={}), Relationship(source=Node(id='Marie Curie', type='Person', properties={}), target=Node(id='Nobel Prize', type='Award', properties={}), type='AWARDED', properties={}), Relationship(source=Node(id='Marie Curie', type='Person', properties={}), target=Node(id='Nobel Prize', type='Award', properties={}), type='AWARDED_TWICE', properties={}), Relationship(source=Node(id='Marie Curie', type='Person', properties={}), target=Node(id='Pierre Curie', type='Person', properties={}), type='SPOUSE', properties={}), Relationship(source=Node(id='Marie Curie', type='Person', properties={}), target=Node(id='University Of Paris', type='Institution', properties={}), type='PROFESSOR', properties={})]
运行效果
http://localhost:7474/browser/preview/