字节跳动开源Seed-OSS:36B参数模型以512K上下文与可控思考预算重新定义AI实用主义
文章目录
- 字节跳动开源Seed-OSS:36B参数模型以512K上下文与可控思考预算重新定义AI实用主义
- 前言
- 一、王牌组合:过目不忘的大脑 + 收放自如的开关 🧠⚖️
- 1.1 “过目不忘”的记忆力
- 1.2 “收放自如”的思考力
- 二、“小个子”的大能量:效率才是硬道理 ⚡
- 三、为开发者而生:一次真正彻底的开源 🌟
- 结语:AI竞赛的下半场,实用主义为王 🏆
字节跳动开源Seed-OSS:36B参数模型以512K上下文与可控思考预算重新定义AI实用主义
前言
在过去几年中,AI大模型的“军备竞赛”为我们呈现了一场又一场数字奇观。模型的参数量从百亿迅速攀升至万亿,上下文窗口也从几千扩展到几十万。我们为AI能力的飞速进步感到震撼,然而对于真正希望将AI应用于业务中的开发者和企业来说,一个根本问题始终萦绕不去:
AI的“蛮力”越来越大,但它的“巧劲”在哪里?
我们常常觉得自己面对的是一个能力强大却难以捉摸的“黑箱”。它时而表现出惊人的创造力,时而却输出毫无逻辑的内容;我们无法得知为了回答一个简单问题,它在背后消耗了多少计算资源;更无法控制它在处理复杂任务时应当投入多少“思考深度”。
现在,字节跳动Seed团队带着其首次开源的大语言模型Seed-OSS,给出了一个明确的答案。这款36B参数的模型并未参与万亿参数的竞赛,而是亮出了两张直击应用痛点的王牌:512K原生超长上下文和可控的“思考预算”。
这不仅是一次新模型的发布,更像是一份“AI实用主义”的宣言。字节似乎在向世界宣告:AI的下一站,不应再是无休止的参数竞争,而是如何让AI变得更智能、更可控、更高效地为人类服务。

一、王牌组合:过目不忘的大脑 + 收放自如的开关 🧠⚖️
Seed-OSS最令人兴奋的,是它将两个看似独立、实则相辅相成的能力完美结合。
1.1 “过目不忘”的记忆力
首先,是强大的长时记忆能力。Seed-OSS原生支持512K的上下文窗口,这是什么概念呢?
这意味着它能一次性“阅读”并理解约90万汉字的内容。你可以将一整本厚厚的法律文书、一个包含数百个文件的复杂代码库,或一部长篇小说手稿直接输入模型,而无需担心它“前读后忘”。
关键在于“原生支持”这四个字。许多模型的长上下文能力是通过后续技术“扩展”实现的,就像给一辆小轿车加挂额外车厢——虽然能装载更多,但运行起来总显得笨重。而Seed-OSS的512K能力是在训练阶段就内置的,这意味着它在处理长文本时,对全局逻辑的把握和对细节的关联更加自然和精准。
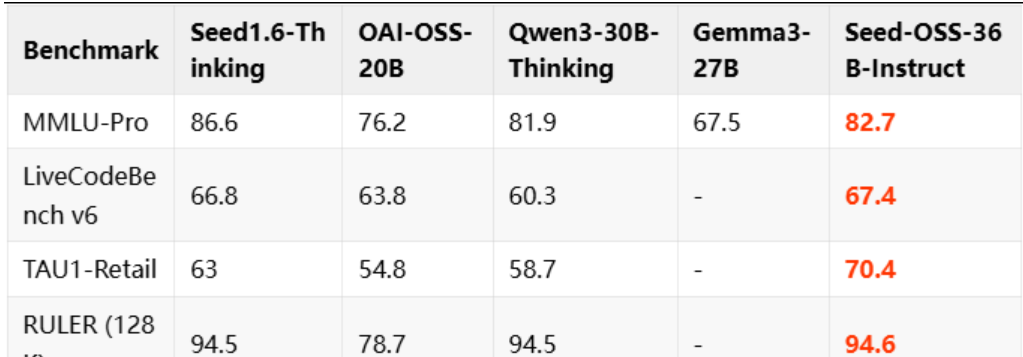
在权威长文本理解测试RULER中,Seed-OSS以94.6分刷新了开源模型的记录,充分证明了其长文本处理能力。
1.2 “收放自如”的思考力
如果说512K长上下文赋予了AI一个“巨胃”,那么“思考预算”就相当于为用户提供了一个控制“消化系统”的开关。
这是Seed-OSS最具革命性的创新之一。用户在向模型提问时,可以明确指定一个“思考预算”,例如512、1024或8192个tokens。模型会在内部先进行“思考”(生成思维链),当预算用尽时,自动停止思考并开始输出最终答案。
这一功能解决了AI应用中的一个核心痛点:成本与效果的平衡。
- 对于简单问题(如“如何做意大利面?”),你可以设置一个较小的预算(甚至为0),使模型快速直接地给出答案,避免不必要的算力浪费。
- 对于复杂问题(如“请分析这份财报并总结核心风险”),你可以分配充足的预算,让模型进行深度、多步骤的推理,确保答案质量。
模型甚至会在思考过程中像一位尽职的助手一样,实时汇报预算使用情况:
# 示例:模型在思考过程中的预算反馈
<seed:cot_budget_reflect>I have used 129 tokens, and there are 383 tokens remaining for use.</seed:cot_budget_reflect>
这种“可控性”,使AI从一个性能不稳定的“黑箱”转变为一个资源消耗可预测、思考深度可调节的“透明工具”。这对企业进行成本控制和应用优化具有重要意义。
当“超长记忆”与“可控思考”结合时,一个全新的应用范式随之诞生。你可以先以极低的预算让模型快速通读一份50万字的报告并生成摘要;然后针对感兴趣的章节,再分配高额预算进行深入分析与推理。这才是真正智能、高效的人机协作模式。
二、“小个子”的大能量:效率才是硬道理 ⚡
在参数动辄千亿的时代,字节开源的36B模型显得格外“小巧”。但这正是其强大之处。
Seed-OSS通过测试成绩证明:聪明的架构和高效的训练远比赛单纯的参数堆砌更重要。
| 能力指标 | 测试成绩 | 排名 |
|---|---|---|
| 数学推理(AIME24) | 91.7 | 开源模型第一 |
| 编程能力(LiveCodeBench V6) | 67.4 | 开源模型第一 |
与OpenAI开源的GPT-OSS-120B相比,Seed-OSS以不到三分之一的参数量,在长上下文处理、编程等多项关键能力上实现了超越。
这背后得益于GQA注意力机制、SwiGLU激活函数等一系列经过行业验证的高效技术组件。字节跳动展示了一场精彩的“工程魔术”:用更少的资源,实现更大的价值。
三、为开发者而生:一次真正彻底的开源 🌟
除了技术突破,字节此次的开源策略也充分体现了对开发者社区的诚意与尊重。
-
完全开放的Apache 2.0许可证:无论是学术研究还是商业应用,都可以自由使用、修改和二次分发,无需担心法律风险。
-
两个基座版本:
- 含合成数据版本:性能更强,适合追求极致效果的商业应用。
- 不含合成数据版本:数据更“纯净”,为学术界进行数据污染分析等研究提供了宝贵的“对照组”。
这种设计充分考虑了社区的不同需求。
-
低门槛的部署方案:支持4-bit/8-bit量化,兼容vLLM框架,并提供完整的API服务脚本。这意味着即使没有顶级服务器集群,甚至在消费级GPU上也可以运行这一强大模型,极大降低了个人开发者和中小企业的使用门槛。
以下是一个简单的API调用示例:
import requests# 设置API端点与密钥
api_endpoint = "https://api.seed-oss.com/v1/chat/completions"
headers = {"Authorization": "Bearer YOUR_API_KEY","Content-Type": "application/json"
}# 构造请求数据
data = {"model": "seed-oss-36b","messages": [{"role": "user", "content": "请总结这篇长文档的核心观点。"}],"max_tokens": 1024,"cot_budget": 512 # 设置思考预算为512 tokens
}# 发送请求
response = requests.post(api_endpoint, headers=headers, json=data)
print(response.json())
结语:AI竞赛的下半场,实用主义为王 🏆
Seed-OSS的开源,可能标志着AI大模型竞赛进入“下半场”。
上半场是巨头们不计成本的“军备竞赛”,比拼的是参数规模和数据量。而下半场,当基础能力逐渐接近时,竞争焦点将转向如何更好地解决真实问题,以及如何为开发者提供更灵活、高效、可控的工具。
字节跳动通过Seed-OSS明确选择了“实用主义”路线。它没有追求最耀眼的“参数皇冠”,而是致力于成为一个更接地气、更擅长解决实际问题的“效率大师”。
对整个AI生态而言,这无疑是一个积极的信号。当越来越多的大型科技公司开始关注效率、开放性和实用性时,AI技术的落地与普及才会真正加速到来。
相关资源:
- Seed-OSS 开源地址
- 官方文档
- 模型下载与体验
声明:本文内容基于官方发布信息及测试数据,仅供参考。实际性能可能因使用环境和任务类型有所不同。