Text2SQL、ChatBI简介
概述
传统BI的三大核心瓶颈:
- 问数之难:不同用户往往存在个性化的分析逻辑,尽管企业内部已经创建大量报表和看板,但仍然无法完全满足业务部门对数据的个性化需求。但传统BI门槛较高,非技术人员在统一培训前,往往难以自行使用BI进行个性化分析。
- 问知之迟:传统BI的分析流程需预先定义数据模型、依赖技术团队支持,从需求提出到洞察生成存在显著延迟,不同的业务方,不同时间点,不同场景下,可能是同一个取数需求,都需要重新排期进行,不仅耗费精力,更难以支撑瞬息万变的实时决策场景。
- 问策之限:分析深度受限于预设指标与固定逻辑,传统BI缺乏动态探索与深度推理能力,难以主动揭示复杂业务场景中的隐性关联与根因,制约策略生成。
Text-to-SQL,Text2SQL,把自然语言转化为SQL,也叫文本到SQL,自然语言到SQL,Text2SQL、T2S、NL2SQL、Natural2SQL、Text2Query、Chat2Query。
早在LLM之前已有大量专注于此任务的机器学习项目。在大模型出现以后,凭借其强大的自然语言理解和推理能力,让T2S得到大力的推进。
在RAG中QA对,在text2sql中,便是query-sql对。
最佳实践:
- 清楚描述数据库上下文;
- 限制数据查询输出的大小;
- 在执行之前验证和检查生成的SQL语句。
引申:
- Text2DSL:Domain Specific Language,领域特定语言
- Text2GQL:Graph Query Language,图查询语言
- Text2API:
- Text2Vis:论文
供参考的T2S问题分类:
- 常规指标查询
- 进阶指标查询
- 时间变种
- 实体信息变种
- 多设备查询
- 多意图拆解
- 嵌套查询
- 图表输出
提示词策略
- Informal Schema:非正式模式策略,简称IS,以自然语言提供表及其关联列的描述,模式信息以不太正式的方式表达;
- API Docs:API文档,简称AD,相比之下,Rajkumar(2022)等人进行的评估中概述的AD策略,遵循OpenAI文档中提供的默认SQL翻译提示。此提示遵循稍微更正式的数据库模式定义。
- Select 3:包括数据库中每个表的三个示例行。此附加信息旨在提供每个表中包含的数据的具体示例,以补充模式描述;
- 1SL:1 Shot Learning,在提示中提供1个黄金示例;
- 5SL:5 Shot Learning,在提示中提供5个黄金示例。
T2S与ChatBI
LLM的迅猛发展使得T2S的准确率得到不少提升,也催生出一大批开源或付费ChatBI系统。
ChatBI=NLU模块+T2S引擎+数据库连接+可视化引擎+对话管理。
Benchmark
T2S任务的评价主要有两种:精确匹配率(Exact Match,EM)、执行正确率(Execution Accuracy,EX,也叫EA)
- EM:计算模型生成的SQL和标注SQL的匹配程度,结果存在低估的可能。
- EX:计算SQL执行结果正确的数量在数据集中的比例,结果存在高估的可能。
EM,为了处理由成分顺序带来的匹配错误,当前精确匹配评估将预测的SQL语句和标准SQL语句按着SQL关键词分成多个子句,每个子句中的成分表示为集合,当两个子句对应的集合相同则两个子句相同,当两个SQL所有子句相同则两个SQL精确匹配成功。
评价指标另有VES:Valid Efficiency Score。VES旨在衡量模型生成的有效SQL的效率。有效SQL,指的是预测的SQL查询,其结果集与基准SQL的结果集一致。任何无法执行正确值的SQL查询都将被声明为无效。VES指标可以考虑执行结果的效率和准确性,提供对模型性能的全面评估。
评估数据集有很多
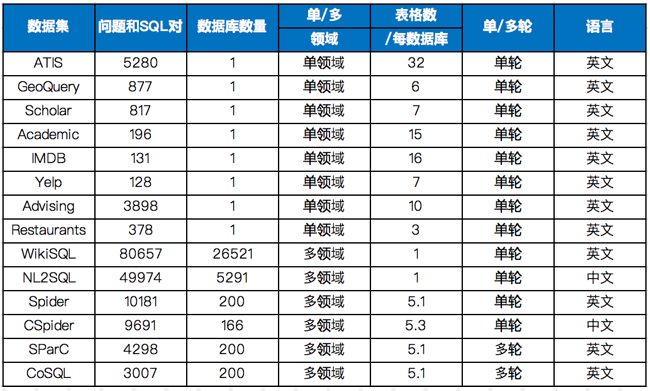
Spider
有两个版本:
- Spider 1.0:官网,论文;
- Spider 2.0:官网,论文,GitHub。
Spider 1.0是耶鲁大学推出,包含10181个问题和5693个SQL,涉及200个数据库
Spider 2.0是由香港大学、Salesforce Research等团队提出的T2S Benchmark框架,用来LLMs在真实企业级数据工作流中的能力。Spider 1.0和BIRD存在数据库规模小、SQL复杂度低、缺乏多方言支持等局限性,而企业级场景涉及超大规模模式(平均812列)、多数据库系统(BigQuery/Snowflake/SQLite等)和复杂数据工程流程。Spider 2.0通过以下创新点突破现有框架:
- 真实数据源:基于Google Analytics、Salesforce等企业数据库,包含213个数据库和632个任务;
- 跨方言支持:覆盖6种SQL方言的多种特殊函数;
- 项目级交互:整合代码库(如DBT项目)和文档,模拟真实开发环境;
- 长上下文处理:平均每个SQL包含148.3个token,远超BIRD的30.9和Spider 1.0的18.5。
实验表明,o1-preview在Spider 2.0上的成功率仅20%左右,远低于其在Spider 1.0上90%+和BIRD上70%+的表现。揭示现有模型在模式链接、方言适配和多步推理上的瓶颈。
提供两种任务设置:
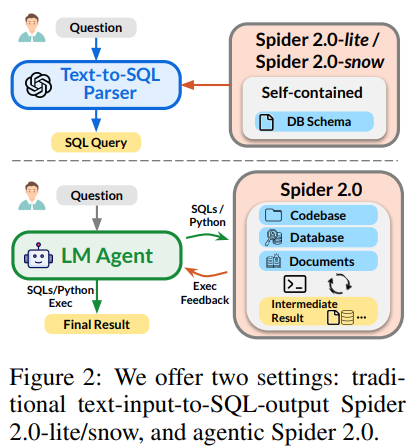
提供两个简化版数据集:
- Spider 2.0-Lite:托管在BigQuery、Snowflake和SQLite上;
- Spider 2.0-Snow:全部托管在Snowflake上。
| 维度 | Spider 2.0 | Spider 2.0-Lite | Spider 2.0-Snow |
|---|---|---|---|
| 任务类型 | 代码代理任务,多轮交互 | 纯文本到SQL,单轮生成 | 纯文本到SQL,单轮生成 |
| 数据库支持 | 6种,含BigQuery/Snowflake/PG | BigQuery/Snowflake/SQLite | 仅Snowflake |
| 示例数量 | 632 | 547 | 547 |
| 复杂度 | 极高(动态环境交互+多方言) | 高(跨数据库适配) | 中(单一方言聚焦) |
| 成本 | 需付费(云资源消耗) | 需付费(BigQuery使用费) | 完全免费(Snowflake提供配额) |
| 核心挑战 | 复杂数据工程流程(清洗→转换→分析) | 跨数据库模式链接与函数适配 | Snowflake方言深度优化 |
| 适用场景 | 企业级代码代理研究 | 跨平台模型泛化能力评估 | 单一云数据库性能基准测试 |
Spider-Agent框架
官方提供的基于ReAct构建的解决方案,专为数据库任务设计的代理框架,针对SQL和数据库交互设计一套动作空间,支持:
- 多动作空间:支持SQL执行、文件编辑、命令行操作等;
- 迭代调试:通过执行反馈不断改进解决方案;
- 上下文管理:有效整合代码库、文档等多源信息
动作空间是Spider-Agent的核心,定义模型可执行的操作:
- Bash:运行shell命令,例如查看文件或执行
dbt run; - CreateFile:创建新的SQL脚本文件;
- EditFile:修改或覆盖现有文件内容;
- ExecuteSQL:在数据库上执行SQL查询,并可选择保存结果;
- GetTables:获取数据库中的表名和模式;
- GetTableInfo:查询指定表的列信息;
- SampleRows:从表中采样数据并保存为JSON格式;
- FAIL:任务失败;
- Terminate:任务已成功完成。
这些动作赋予模型灵活性,使其能够与数据库和代码环境无缝交互。
Bird
官网,论文,GitHub
一个开创性的跨领域数据集,包含超过12751个独特的问题-SQL对,95个大型数据库,达33.4GB。涵盖超过37个专业领域,如区块链、曲棍球、医疗保健和教育等。
GPT-3.5-turbo在BIRD数据集上的表现进行详细的错误分析与分类:
- 错误的模式链接(Wrong Schema Linking,占41.6%):模型能准确地理解数据库的结构,但错误地将其与不适当的列和表关联起来。表明schema linking仍然是T2S模型的一个重大障碍。
- 误解数据库内容(Misunderstanding Database Content,占40.8%):当ChatGPT无法回忆起正确的数据库结构(如rtype不属于satscores表)或生成假的schema项(如lap_records没有出现在formula_1数据库中)时,尤其是当数据库非常大时,就会发生这种情况。如何使模型真正理解数据库结构和内容仍然是LLMs中的痛点话题。
- 误解知识证据(Misunderstanding Knowledge Evidence,占17.6%):没有准确解释人类注释的证据的情况。如直接复制公式
DIVIDE(SUM(spent),COUNT(spent))。表明ChatGPT在面对不熟悉的提示或知识时,缺乏鲁棒性,导致它直接复制公式,而不考虑SQL语法。这种脆弱性可能会导致安全问题。例如如果故意通过一个不熟悉的公式引入一个毒药知识证据,GPT可能会在没有验证的情况下无意中将其复制到输出中,从而使系统暴露于潜在的数据安全风险中。 - 语法错误(Syntax Error,占3.0%):比例较小,表明ChatGPT在语义解析方面表现良好,少部分错误体现在一些特殊的关键词,如混淆使用MySQL的
year()和SQLite中的STRFTIME()。
IJCKG2025 Archer
Archer包含三种推理类型:算术推理、常识推理和假设推理。算术推理在SQL的具体应用场景中占有重要比例。常识推理是指基于隐含的常识知识进行推理的能力,Archer包含一些需要理解数据库才能推断出缺失细节的问题;假设推理要求模型具备反事实思维能力,即根据可见事实和反事实假设对未见情况进行想象和推理的能力。
Archer包含1042个中文问题、1042个英文问题以及521条对应的SQL查询,覆盖20个不同领域的20个数据库。其中8个数据库用作训练集,2个数据库用作验证集,10个数据库用作测试集。数据集及排行榜地址:https://sig4kg.github.io/archer-bench/
评估指标:
- VA:VAlid SQL,成功执行的预测SQL语句的比例,无论答案是否正确;
- EX:EXecution accuracy,预测SQL语句执行结果与标准SQL语句执行结果相匹配的比例。
开源
Awesome Text2SQL
GitHub,关于LLMs、Text2SQL、Text2DSL、Text2API、Text2Vis等主题的精选教程资源。
Chat2db
旨在成为一个通用的开源SQL客户端和报告工具,支持几乎所有比较流行的数据库、缓存。
7B开源模型:
https://github.com/CodePhiliaX/Chat2DB-GLM
https://huggingface.co/Chat2DB/Chat2DB-SQL-7B
部署
git clone https://github.com/CodePhiliaX/Chat2DB
cd Chat2DB/docker
docker compose up -d
浏览器打开http://localhost:10824,开始体验。
输入默认用户名密码chat2db。
设置API Key
创建数据库连接
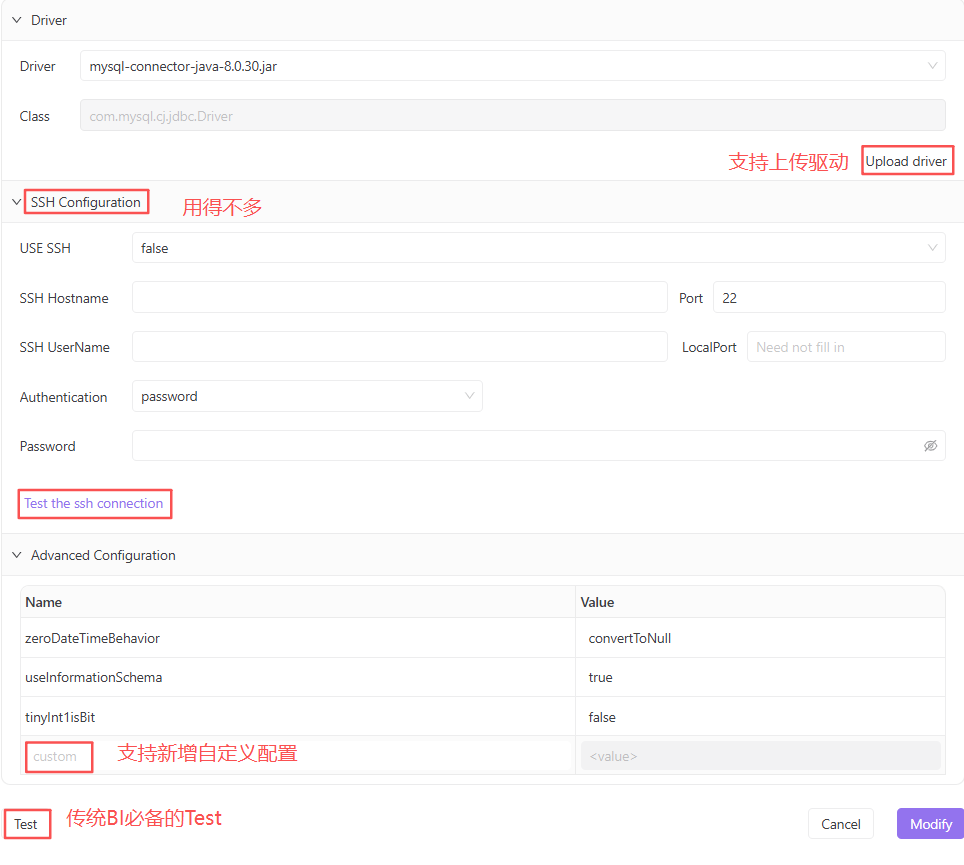
上面截图没体现出来,可新增多个自定义配置。
新增Dashboard:
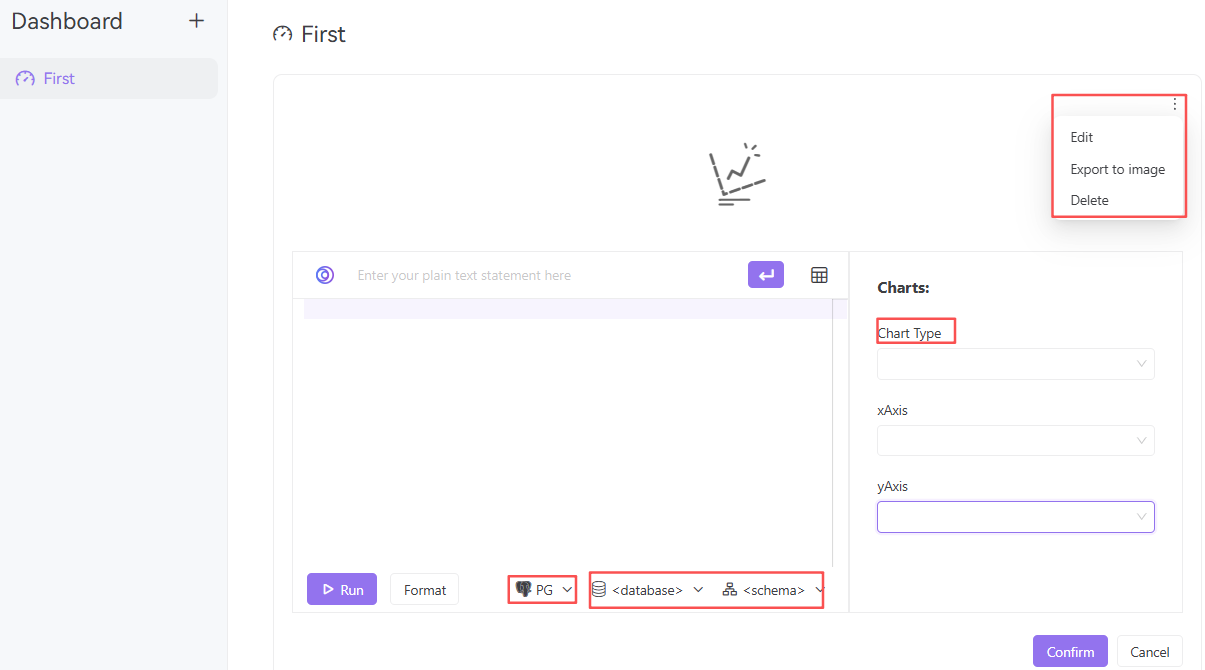
Chart Type支持3种
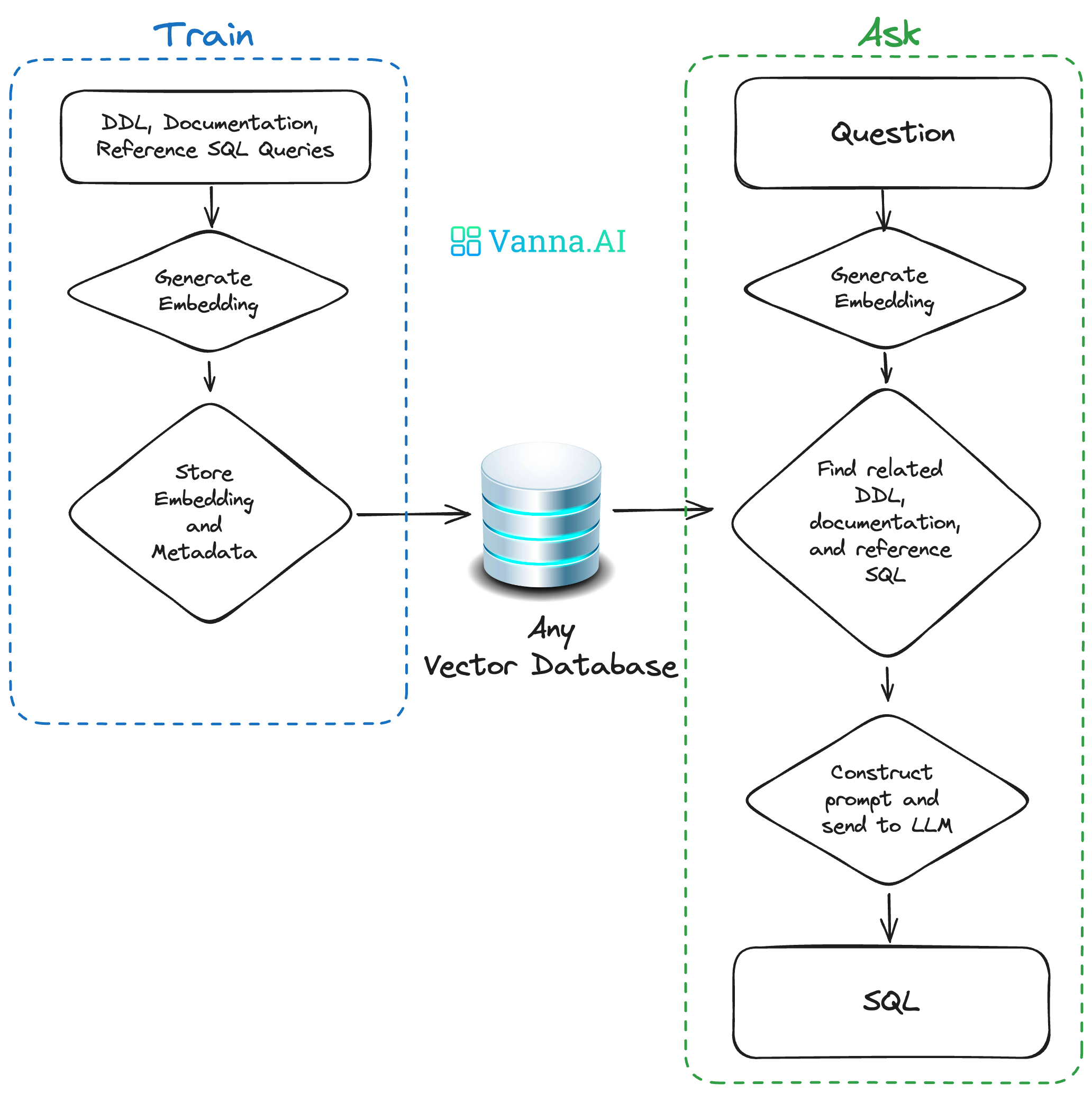
Vanna
一款开源AI SQL代理,能够将自然语言问题转化为可操作的数据库洞察。该平台提供了多种部署选项,以满足不同的组织需求:
- Vanna Cloud:无需设置即可使用的企业级平台,针对你的特定数据环境和行业背景进行训练;
- Vanna Enterprise:本地部署,以实现完全的数据主权;
- Vanna API:具备集成能力,可将AI驱动的数据库交互嵌入到现有应用程序中;
- 开源基础:为希望构建自定义解决方案的开发者提供最大程度的灵活性。
支持Snowflake、BigQuery等主流数据库,并可轻松创建连接器以支持其他数据库。可通过多种前端部署,包括Jupyter Notebooks、Slack机器人、Web应用和Streamlit界面。
开源的开源Python RAG框架。Vanna通过整合上下文(元数据、定义、查询等)以及领域知识文档来训练RAG模型。在Vanna框架的基础上可以使用现有工具(例如Streamlit、Slack)构建自定义可视化UI,实现对话结果的可视化。
两个步骤:
- 基于数据训练RAG模型;
- 提出问题返回SQL查询,并且可以将查询配置为在数据库上自动运行。
WrenAI
开源,官网
数据库内容不会传输到LLMs,确保数据安全。
部署
git clone https://github.com/Canner/WrenAI
cd WrenAI/docker/
cp .env.example .env
docker compose up -d
浏览器打开http://localhost:3000,比较贴心地给出自带的数据源和数据集
上面提到RAG的QA对,WrenAI也能看到类似知识库维护界面
API界面没有维护入口,需要在.env文件里配置,然后重启服务。

SQL Chat
GitHub,具备T2S聊天功能的SQL客户端。
SuperSonic
参考SuperSonic部署实战。
Dataherald
https://github.com/Dataherald/dataherald
一个T2S引擎,为在关系数据库上的企业级问答而构建。
功能:
- 允许业务用户从数据仓库中获得结果,而无需通过数据分析师;
- 在SaaS应用程序中启用来自生产数据库的Q+A
- 创建ChatGPT插件
包含四大模块:引擎、管理控制台、企业后端和Slackbot。其中,核心引擎模块包含了LLM代理、向量存储和数据库连接器等关键组件。模块化设计,将不同的功能模块封装成独立的类和方法,便于代码维护和扩展,可轻松地集成新的工具和功能。
database-build
https://github.com/supabase-community/database-build
一个基于WASM的浏览器内PostgreSQL沙盒,带有AI辅助功能。它让用户可以直接在网页浏览器中操作PostgreSQL,而无需在本地安装或设置数据库。
DuckDB-NSQL
https://github.com/NumbersStationAI/DuckDB-NSQL
一个由MontherDuck和Numbers Station为DuckDB SQL分析任务构建的T2S LLM。可以帮助用户利用DuckDB的全部功能及其分析潜力,而不需要在DuckDB文档和SQL shell之间来回切换。
EZQL
https://github.com/outerbase/ezql
开发商Outerbase已被Cloudflare收购。
付费/闭源
DataGrip
新版本能力:
- 使用自然语言请求查询和信息
- 解释复杂的SQL,例如存储过程
- 优化架构和SQL
- 比较两个数据库对象的DDL
- 修复SQL错误
- 格式化和重写SQL
观远
核心亮点:
- 知识库冷启动:快速构建精准问数体系
基于企业现有BI资产(仪表板、卡片、数据集等),观远ChatBI实现低门槛知识迁移与快速激活:
• 多源数据无缝接入:支持40+数据库连接与文件类数据抽取,未来可扩展直连模式,确保数据来源的全面性与实时性,为问数场景提供坚实的数据底座。
• 业务知识高效萃取:自动从既有BI资产中提取业务逻辑与问答知识(如指标定义、分析维度关联),加速知识库初始化过程,避免从零开始的资源浪费。
• 问答准确率闭环检测:上线前对主题进行自动化问答测试,确保准确率达90%+,通过“测试-优化-再测试”机制,保障问数结果的精准性与业务贴合度。
- 多端交互体验:打破时空限制的智能问数
观远ChatBI深度适配PC端、移动端、OA系统(如飞书),构建全场景智能交互体系:
• 多端协同问数:业务人员可在办公桌面、移动终端随时随地发起数据查询,即时获取可视化分析结果,实现“数据随需而至”。
• OA集成深化场景:对接企业级协作平台机器人(如飞书机器人),在日常办公流中直接嵌入数据问答能力,提升办公效率。
• 交互动作立体化:支持问答结果的收藏、点赞/踩、SQL复制与导出等操作,便于业务人员对优质分析内容进行沉淀复用,同时通过用户反馈优化模型,形成“问数-反馈-迭代”的正向循环。
- 知识库自迭代:打造个性化企业知识生态
通过知识自动沉淀、智能自检、个性化学习,观远ChatBI构建可持续进化的企业级知识库:
• 知识自动录入:从历史对话、用户行为中挖掘新知识,提示用户将其纳入知识库,实现业务知识的动态积累,避免人工维护的繁琐与遗漏。
• 知识智能自检:定期对知识库进行冲突检查与近似检查,提醒用户合并或更新知识,确保知识库的纯净度与一致性。
• 个性化学习引擎:引入用户行为数据,为不同角色建立个人知识库,提供精细化问题推荐与指标口径确认,实现“千人千面”的智能分析体验。
SQLAI.ai
官网,划分为多个SQL生成器,每个都服务于特定的目的:
- Explain SQL Queries:解释SQL查询,提供带摘要、输出可视化和详细查询分解的解释;
- Format SQL Query:格式化SQL查询,以提高可读性并减少出错的可能性;
- Analyze Your Data:允许上传CSV数据并向AI提问;
- Generate SQL Query:
- Fix SQL Queries:
- Optimize SQL Query:
推荐阅读
- NL2SQL