[Vid-LLM] 功能分类体系 | 视频如何被“观看“ | LLM的主要作用
第4章:Vid-LLM功能分类体系
在前一章中,我们探讨了构建和训练视频大语言模型(Vid-LLMs)的不同方法体系或"配方"。
我们了解了它们如何获取基础知识(预训练)、专精特定任务(指令微调)或充当智能规划者(基于LLM的视频代理)。
现在,让我们从关注如何构建转向关注它们投入使用后扮演什么角色。本章将介绍Vid-LLM功能分类体系,这就像一份蓝图,根据两个关键方面描述Vid-LLM执行的不同工作或"功能":
- 它如何"观看"或处理视频
- 大语言模型(LLM)本身主要用视频信息做什么
"功能分类体系"解决什么问题?
假设您正在观看一位厨师制作精致舒芙蕾的详细视频。您可能需要以下几种帮助:
- 需要快速概览整个制作过程
- 想要从视频中获取详细的逐步食谱
- 寻找厨师执行特定动作的精确时刻,如"折叠蛋白"
- 希望有个智能助手能引导您完成食谱,甚至根据提问建议下一步操作
每种需求都要求Vid-LLM执行略有不同的"工作"。
Vid-LLM功能分类体系帮助我们分类这些不同的"工作",理解各种Vid-LLMs如何设计以擅长它们。就像知道工具是锤子、螺丝刀还是扳手——每种都有特定功能。
让我们解析Vid-LLMs如何设计以执行这些多样化角色。
Vid-LLM的"眼睛":视频如何被"观看"
在LLM开始工作前,它需要"理解"视频。Vid-LLMs处理原始视频信息主要有两种方式:
1. 视频分析器:智能侦探
描述:将视频分析器视为细致观察视频的智能侦探。
它不只看到原始像素,而是专注于提取高级语义细节。它经过训练能识别特定物体(如"打蛋器"、“碗”、“烤箱”)、动作(如"混合"、“烘焙”、“折叠”)和事件(如"舒芙蕾膨胀")。视频分析器的输出通常是检测到的物品、动作列表或关键时刻描述,然后传递给LLM。
类比:如果您向人类专家展示厨师视频,他们不只看到颜色;他们会识别"分离蛋黄的动作"、“打发蛋白的碗"或"烤箱温度设置”。
2. 视频编码器:通用翻译器
描述:视频编码器更像通用翻译器。它获取视频帧的原始视觉(有时包括听觉)信息,将其转换为称为嵌入的紧凑数值化"语言"。这些嵌入是捕捉视频内容本质的密集数字向量,但并非人类可读标签。LLM可以直接处理这些数值化嵌入,与您的文本问题一起。
类比:视频编码器不会识别"打发的蛋白",而是生成代表"被轻柔折叠的白色泡沫物质"的复杂数字代码。LLM随后学习将这个数字代码与文本描述关联。
3. 混合方法(分析器+编码器):两者兼用
一些先进Vid-LLMs结合两种方法。它们可能使用视频分析器获取特定任务(如找出所有"混合"动作)的高级细节,同时使用视频编码器为LLM提供更通用、丰富的视频数值化表示以推理更广泛上下文。这让它们能利用两种方法的优势。
Vid-LLM的"大脑":LLM的主要作用(其角色)
视频信息(无论是分析细节还是原始嵌入)到达LLM后,LLM承担主要"角色"或"功能"。
让我们看看最常见的几种:
1. LLM作为摘要生成器:简洁报告者
描述:在此角色中,LLM的主要工作是获取所有视频信息(通常来自视频分析器的高级细节)并生成视频内容的简短摘要。它聚焦于最重要的事件或关键要点。
类比:您观看漫长的烹饪节目后,朋友快速告诉您:“厨师演示了制作巧克力舒芙蕾,强调打发技术和烤箱温度控制。”
解决烹饪用例(场景1:快速概览):
如果我们使用LLM作为摘要生成器的Vid-LLM,它可以提供舒芙蕾视频的简要概览。
# 概念示例:带视频分析器的LLM摘要生成器
class VidLLMSummarizer:def __init__(self):print("Vid-LLM摘要生成器就绪!")def summarize_video(self, video_file: str) -> str:print(f"分析视频'{video_file}'的关键事件...")# 内部视频分析器提取如"混合"、"烘焙"等事件# LLM随后用这些生成摘要analyzed_events = self._run_video_analyzer(video_file)# LLM处理analyzed_events并生成摘要summary = f"摘要:视频展示厨师准备舒芙蕾,包括{analyzed_events[0]}、{analyzed_events[1]}和{analyzed_events[2]}。"return summarydef _run_video_analyzer(self, video_file):# 模拟视频分析器识别关键步骤if "souffle" in video_file:return ["食材准备", "混合面糊", "烘焙膨胀"]return ["常规事件"]my_summarizer = VidLLMSummarizer()
summary_output = my_summarizer.summarize_video("souffle_tutorial.mp4")
print(f"\nVid-LLM的摘要:{summary_output}")
概念性输出:
Vid-LLM摘要生成器就绪!
分析视频'souffle_tutorial.mp4'的关键事件...Vid-LLM的摘要:摘要:视频展示厨师准备舒芙蕾,包括食材准备、混合面糊和烘焙膨胀。
这里,VidLLMSummarizer接收视频,内部_run_video_analyzer提取关键高级事件,然后LLM据此撰写简洁摘要。
2. LLM作为文本解码器:详细讲述者
描述:当LLM作为文本解码器时,其主要角色是生成关于视频的详细描述性文本。
这通常涉及将视频编码器的细致数值化嵌入转换为丰富、类人的语言,描述物体、动作及其随时间的关系。这在视频字幕生成或回答问题的详细答案中很常见。
类比:就像与您全程观看烹饪节目的朋友,能叙述每个步骤和细节:“首先,厨师小心分离蛋黄,然后轻柔地将打发蛋白拌入巧克力混合物,确保不消泡。”
解决烹饪用例(场景2:详细食谱描述):
LLM作为文本解码器的Vid-LLM能提供舒芙蕾食谱的更深入描述。
# 概念示例:带视频编码器的LLM文本解码器
class VidLLMTextDecoder:def __init__(self):print("Vid-LLM文本解码器就绪!")def describe_video(self, video_file: str) -> str:print(f"将视频'{video_file}'编码为语言兼容格式...")# 内部视频编码器将帧转换为数值化嵌入# LLM随后将这些解码为描述性文本video_embeddings = self._run_video_embedder(video_file)# LLM将嵌入解码为详细描述description = f"详细食谱:{video_embeddings[0]}。接着,{video_embeddings[1]}。"return descriptiondef _run_video_embedder(self, video_file):# 模拟视频编码器生成数值化表示# 为简化,我们用文本描述作为嵌入占位符if "souffle" in video_file:return ["厨师精确分离蛋黄和蛋白", "然后小心将蛋白拌入巧克力基底"]return ["常规视频特征"]my_text_decoder = VidLLMTextDecoder()
detailed_description = my_text_decoder.describe_video("souffle_tutorial.mp4")
print(f"\nVid-LLM的详细描述:{detailed_description}")
概念性输出:
Vid-LLM文本解码器就绪!
将视频'souffle_tutorial.mp4'编码为语言兼容格式...Vid-LLM的详细描述:详细食谱:厨师精确分离蛋黄和蛋白。接着,然后小心将蛋白拌入巧克力基底。
这里,VidLLMTextDecoder使用内部_run_video_embedder获取数值化特征(此处用文本占位符表示),然后LLM将其转化为详细叙述。
3. LLM作为管理者(或代理):智能协调者
描述:在这个复杂角色中,LLM充当管理者或"代理"。
它不只被动总结或描述,而是协调其他工具(如物体检测器、动作识别器甚至文本转语音模块)来理解视频并响应复杂请求。LLM运用推理能力分解复杂任务,决定使用哪些工具,处理它们的输出,然后制定全面响应甚至规划动作序列。这通常依赖视频分析器的特定细节。
类比:您问主厨:"如何制作这个舒芙蕾?"他们可能先识别所有食材,列出步骤,然后引导您完成每个部分,甚至根据需要建议替代工具。
解决烹饪用例(场景4:智能助手):
作为管理者的LLM会处理舒芙蕾视频的多步骤请求。
# 概念示例:带视频分析器(工具)的LLM管理者/代理
class VidLLMManager:def __init__(self):print("Vid-LLM管理者(代理)就绪!")# 这些是LLM可"调用"的专业工具self.ingredient_detector = lambda v: "鸡蛋、糖、巧克力" if "souffle" in v else ""self.action_sequencer = lambda v: "打发、折叠、烘焙" if "souffle" in v else ""def assist_with_recipe(self, video_file: str, query: str) -> str:print(f"代理处理视频'{video_file}'的查询'{query}'...")if "ingredients" in query.lower():ingredients = self.ingredient_detector(video_file) # LLM调用工具return f"这个舒芙蕾的主要食材是:{ingredients}。"elif "next step" in query.lower():actions = self.action_sequencer(video_file).split(', ') # LLM调用另一个工具return f"根据视频,打发后的下一步是:{actions[1]}。"return "我可以帮助查询食材或下一步!"my_manager = VidLLMManager()
assistant_response = my_manager.assist_with_recipe("souffle_tutorial.mp4", "关键食材有哪些?")
print(f"\nVid-LLM管理者的回答:{assistant_response}")
概念性输出:
Vid-LLM管理者(代理)就绪!
代理处理视频'souffle_tutorial.mp4'的查询'关键食材有哪些?'...Vid-LLM管理者的回答:这个舒芙蕾的主要食材是:鸡蛋、糖、巧克力。
这里,VidLLMManager作为中央大脑,解释您的问题,然后决定使用哪个"工具"(ingredient_detector、action_sequencer)从视频(由视频分析器提供)获取必要信息。
4. LLM作为回归器:精确测量者
描述:作为回归器的LLM设计用于输出结构化数据或数值而非自由格式文本。这对以下任务至关重要:
- 时间定位:找出文本描述事件的开始和结束时间戳(如"0:45-1:10")
- 物体定位:预测查询中提及物体的边界框坐标(如
[x1, y1, x2, y2]) - 异常检测:输出异常事件可能性的分数
这通常需要视频编码器的精确数值化嵌入以准确映射。
类比:您问"厨师什么时候加糖?“助手回答"视频中0:32到0:38之间”,提供精确时间测量。
解决烹饪用例(场景3:查找特定动作):
要找出精确时刻,LLM作为回归器是理想选择。
# 概念示例:带视频编码器的LLM回归器
class VidLLMRegressor:def __init__(self):print("Vid-LLM回归器(定位器)就绪!")def find_event_time(self, video_file: str, event_description: str) -> str:print(f"处理视频'{video_file}'定位'{event_description}'...")# 内部视频编码器提供详细特征# LLM从中回归(预测)时间戳video_features_for_event = self._get_event_features(video_file, event_description)# LLM输出具体时间范围if "folds egg whites" in event_description.lower():return "事件位于1:15-1:45"elif "adds sugar" in event_description.lower():return "事件位于0:30-0:40"return "事件未精确定位"def _get_event_features(self, video_file, event_description):# 模拟获取视频中与事件相关的数值化特征return {"features": f"{event_description}的数据"}my_regressor = VidLLMRegressor()
time_output = my_regressor.find_event_time("souffle_tutorial.mp4", "厨师何时折叠蛋白?")
print(f"\nVid-LLM回归器的输出:{time_output}")
概念性输出:
Vid-LLM回归器(定位器)就绪!
处理视频'souffle_tutorial.mp4'定位'厨师何时折叠蛋白?'...Vid-LLM回归器的输出:事件位于1:15-1:45
这里,VidLLMRegressor接收视频和事件描述,使用_get_event_features(代表视频编码器)获取相关数据,然后LLM预测具体时间范围。
5. LLM作为隐藏层:内部助手
描述:在此角色中,LLM不直接生成面向用户的最终答案。相反,它作为更大视觉处理流程中的内部组件或"隐藏层"。其输出(通常是数值化表示)传递给模型另一部分,以帮助高级图像/视频生成、特征优化或引导进一步视觉分析等任务。它几乎充当强大的"特征提取器"本身。这总是依赖视频编码器的原始特征以深度集成。
类比:想象舒芙蕾视频由机器人厨师处理。LLM可能在内部生成面糊稠度的详细"状态描述",然后帮助机器人决定还需混合多久,而无需告知人类。
解决烹饪用例(场景5:内部视频分析):
作为隐藏层的LLM会贡献给另一系统的任务,而非直接面向用户。
# 概念示例:带视频编码器的LLM隐藏层
class VidLLMHiddenLayer:def __init__(self):print("Vid-LLM隐藏层组件就绪!")def generate_internal_features(self, video_segment_data: dict) -> list:print("LLM处理视频片段生成内部特征...")# 视频编码器提供segment_data# LLM处理以创建供其他系统使用的增强内部特征enriched_features = [f"LLM增强_{video_segment_data['raw_feature_1']}", f"LLM增强_{video_segment_data['raw_feature_2']}"]return enriched_features# 假设另一系统(如自动质量检查器)
class AutomatedQualityChecker:def __init__(self):self.hidden_llm = VidLLMHiddenLayer()print("质量检查器初始化,含内部LLM")def check_batter_consistency(self, current_video_segment: dict) -> str:print("检查面糊稠度...")# 使用内部LLM获取增强特征llm_output_features = self.hidden_llm.generate_internal_features(current_video_segment)# 分析增强特征判断稠度if "LLM增强_smooth" in llm_output_features:return "面糊稠度:完美(LLM验证)"return "面糊稠度:需更多混合(LLM验证)"# 模拟视频编码器提供的视频片段原始特征
current_frame_features = {"raw_feature_1": "liquid", "raw_feature_2": "smooth"}quality_checker = AutomatedQualityChecker()
consistency_report = quality_checker.check_batter_consistency(current_frame_features)
print(f"\n质量检查器报告:{consistency_report}")
概念性输出:
Vid-LLM隐藏层组件就绪!
质量检查器初始化,含内部LLM
检查面糊稠度...
LLM处理视频片段生成内部特征...质量检查器报告:面糊稠度:完美(LLM验证)
此例中,VidLLMHiddenLayer的输出不是人类可读答案,而是帮助AutomatedQualityChecker做出判断的增强特征,展示其作为内部助手的角色。
内部机制:功能如何运作一瞥
让我们通过概念序列图看看两种不同功能的内部运作。
1. 带视频分析器的LLM摘要生成器
展示"智能侦探"(视频分析器)如何识别关键事件,LLM随后将其编译成快速报告。
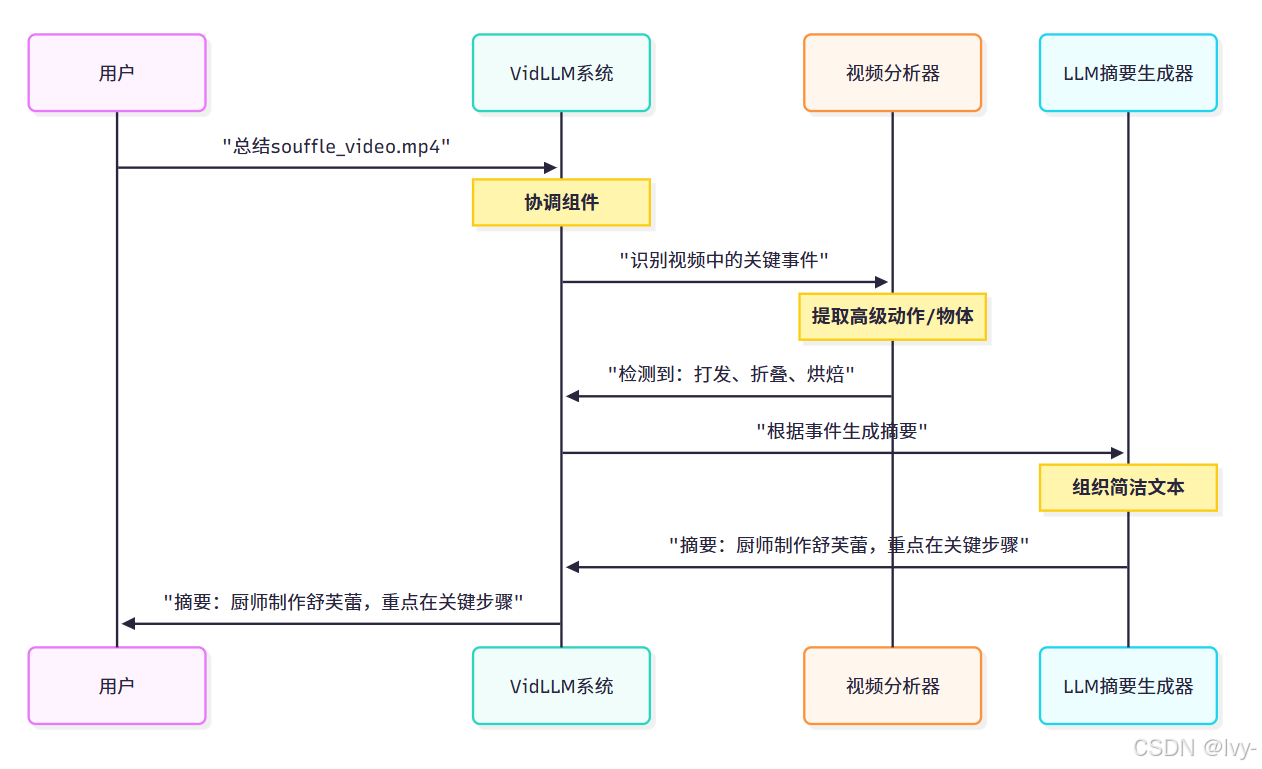
在此流程中,视频分析器向LLM摘要生成器提供预处理的语义信息,后者快速生成简洁文本概览。
2. 带视频编码器的LLM文本解码器
展示"通用翻译器"(视频编码器)如何将视频转换为数值化语言,LLM随后"解码"为详细故事。
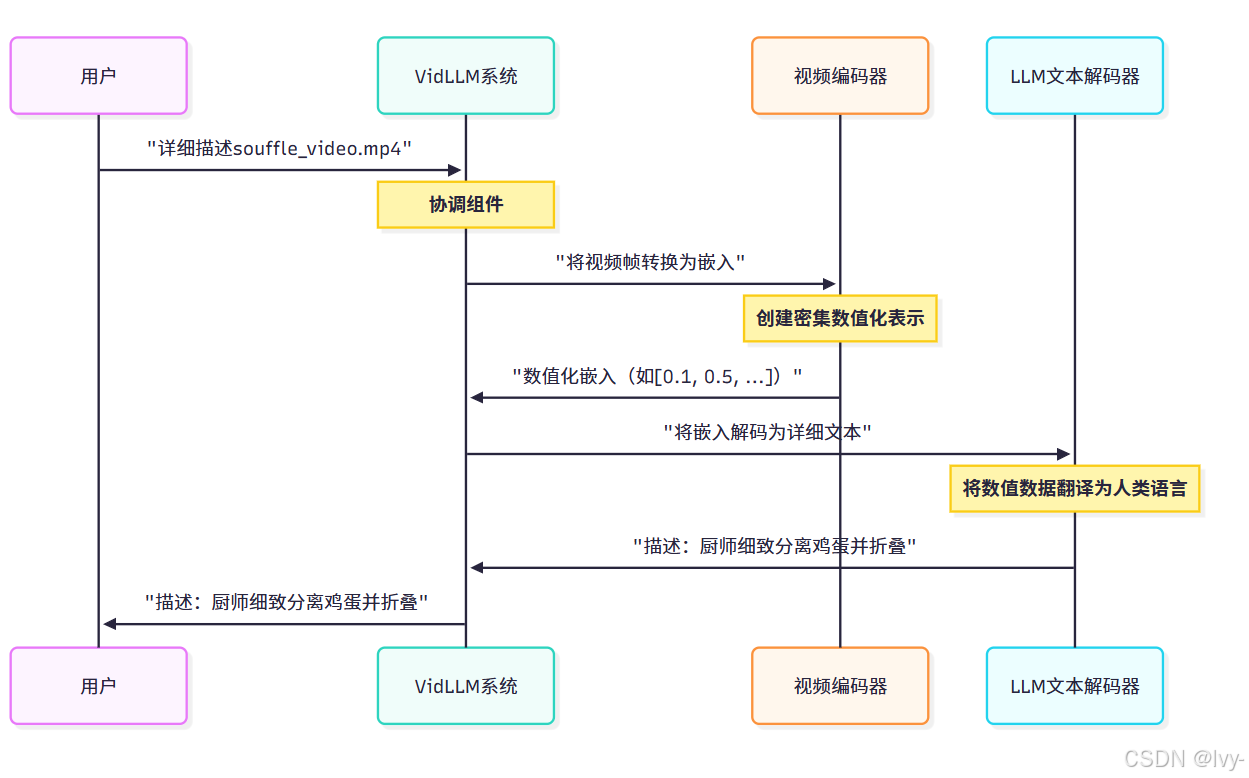
这里,视频编码器提供原始密集特征,LLM文本解码器直接负责将这些特征转换为详细、人类可读的描述。
Vid-LLM功能总结
Vid-LLMs能执行的不同功能的概览:
| LLM主要角色 | 视频如何被"观看" | 功能描述 | 类比(舒芙蕾助手) |
|---|---|---|---|
| 摘要生成器 | 视频分析器 | 生成简短的高级摘要 | 快速概览:“厨师分3个主要阶段制作舒芙蕾” |
| 文本解码器 | 视频编码器(或混合) | 产出详细的描述性文本/答案 | 叙述每个步骤:“厨师精确分离蛋黄,然后轻柔折叠蛋白” |
| 管理者(代理) | 视频分析器(用于工具输出) | 协调外部工具,规划动作,复杂推理 | 引导您完成食谱,提问、建议工具和下一步 |
| 回归器 | 视频编码器(或混合) | 输出时间戳或坐标等结构化数据 | 精确定位:“加糖在0:30-0:40” |
| 隐藏层 | 视频编码器 | 作为其他系统的内部特征增强器 | 为自动质量控制系统内部评估面糊稠度 |
结语
本章我们学习了令人兴奋的Vid-LLM功能分类体系,概述了Vid-LLMs能执行的不同"工作"或"角色"。
我们探索了它们的"眼睛"(视频分析器或编码器)如何处理视频,以及它们的"大脑"(LLM)如何承担从总结描述到管理工具和预测精确数据等各种角色。
理解这些功能有助于我们掌握Vid-LLMs的多样化能力及其如何为不同应用定制。
既然我们已经了解不同类型的功能,接下来让我们探索数据集和基准测试在开发和评估这些惊人模型中的关键作用。
下一章:数据集和基准测试