HashMap相关学习
1. 手写HashMap的put方法和get方法
1.1 基础部分搭建
package map;public class MyHashMap<K,V> {/*** 哈希表*/private Node<K,V>[] table;/*** 键值对的个数*/private int size;@SuppressWarnings("unchecked")public MyHashMap() {this.table = new Node[16];}static class Node<K,V>{/*** 哈希值*/int hash;/*** 键*/K key;/*** 值*/V value;/*** 下一个结点的内存地址*/Node<K,V> next;/*** 构造节点对象* @param hash 哈希值* @param key 键* @param value 值* @param next 下一个结点地址*/public Node(int hash, K key, V value, Node<K,V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;}}/*** 获取集合中键值对的个数* @return*/public int size() {return size;}
}1.2 put方法
1.2.1 基础部分
/*** 向Map中添加一个键值对* @param key 键* @param value 值* @return value,如果key重复,则返回oldValue,如果key不重复,则返回newValue*/
public V put(K key, V value) {return null;
}/*** 通过key获取value* @param key 键* @return 值*/
public V get(K key) {return null;
}
1.2.2 核心实现
- 当key为null时,则将该键值对存储到table数组中索引为0的位置
private V putForNullKey(V value) {Node<K,V> node = table[0];if(node == null) {table[0] = new Node<>(0,null,value, null);size++;return value;}Node<K,V> prev = null;while(node != null) {if(node.key == null) {V oldValue = node.value;node.value = value;return oldValue;}prev.next = node;node = node.next;}prev.next = new Node<>(0,null,value, null);size++;return value;
}
- 当key不为null时,则就需要调用key的hashcode()方法,获取到key的哈希值
int hash = key.hashCode();
int index = hash % table.length;
Node<K,V> node = table[index];
if(node == null) {table[index] = new Node<>(hash, key, value, null);size++;return value;
}
Node<K,V> prev = null;
while(null != node) {if(key.equals(node.key)) {V oldValue = node.value;node.value = value;return oldValue;}prev = node;node = node.next;
}
prev.next = new Node<>(hash, key, value, null);
size++;
return value;
1.3 重写toString方法
1.3.1 Node<K,V>类中的重写
@Override
public String toString() {return "Node{key=" + key + ", value=" + value + '}';
}
1.3.2 MyHashMap类中的重写
/**
* 重写toSting方法,输出集合时调用
* @return
*/
@Override
public String toString() {StringBuilder sb = new StringBuilder();for(int i = 0; i < table.length; i++) {Node<K,V> node = table[i];while(null != node) {sb.append(node);sb.append("\n");node = node.next;}}return sb.toString();
}
1.4 get方法
1.4.1 key为null
if(key == null) {Node<K,V> node = table[0];if(node == null) {return null;}while(null != node) {if(null == node.key) {return node.value;}node = node.next;}
}
1.4.1 key不为null
int hash = key.hashCode();
int index = hash % table.length;
Node<K,V> node = table[index];
if(node == null) {return null;
}
while(null != node) {if(key.equals(node.key)) {return node.value;}
}
return null;
1.5 测试
1.5.1 测试put方法
public class MyHashMapTest {public static void main(String[] args) {MyHashMap<String, String> myHashMap = new MyHashMap<>();myHashMap.put("key1", "value1");myHashMap.put("key2", "value2");myHashMap.put("key3", "value3");myHashMap.put(null, "value4");System.out.println(myHashMap);}
}
输出结果:
Node{key=null, value=value4}
Node{key=key1, value=value1}
Node{key=key2, value=value2}
Node{key=key3, value=value3}
1.5.1 测试get方法
public class MyHashMapTest {public static void main(String[] args) {MyHashMap<String, String> myHashMap = new MyHashMap<>();myHashMap.put("key1", "value1");myHashMap.put("key2", "value2");myHashMap.put("key3", "value3");myHashMap.put(null, "value4");System.out.println(myHashMap.get(null));}
}
输出结果:
value4
2. 不同jdk版本的HashMap
2.1 初始化
- Java8之前,构造方法执行时初始化table数组
- Java8之后,第一次调用put方法的时候初始化table数组
2.2 链表插入
- Java8之前,头插法
- Java8之后,尾插法
2.3 数据结构
- Java8之前,数组 + 单向链表
- Java8之后,数组 + 单向链表 + 红黑树
3. 容量和扩充
3.1 初始化容量永远是2的次幂
首先初始化时,先设一个不是2的次幂的容量,然后查看源码进行分析
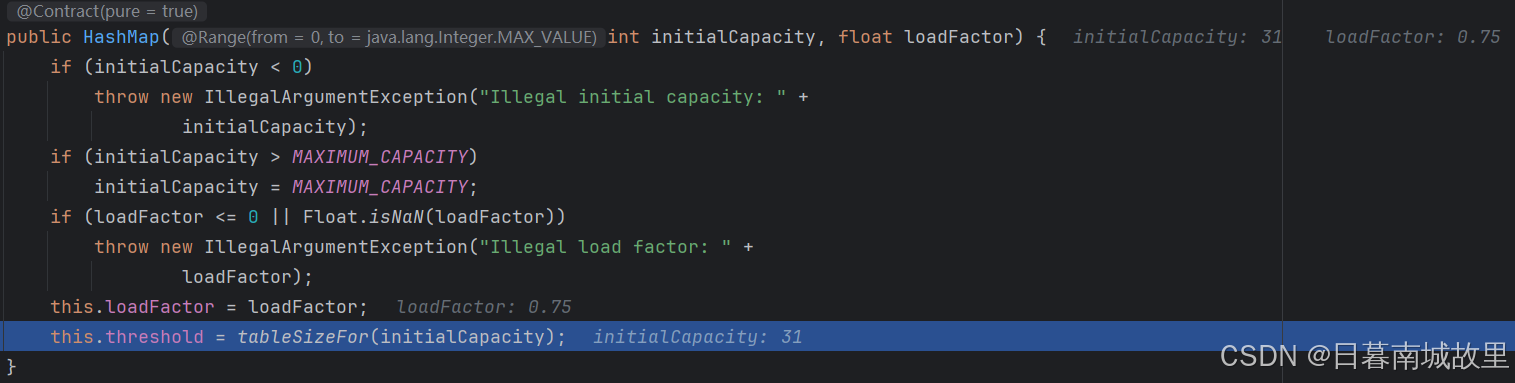
Map<String, String> map = new HashMap<>(31);
首先进入有参数的构造方法

然后进入到这个方法,发现在最后一行代码有一个对集合大小设置的一个方法,在这个方法结束之后,这里的容量就变成32了,即2的次幂。
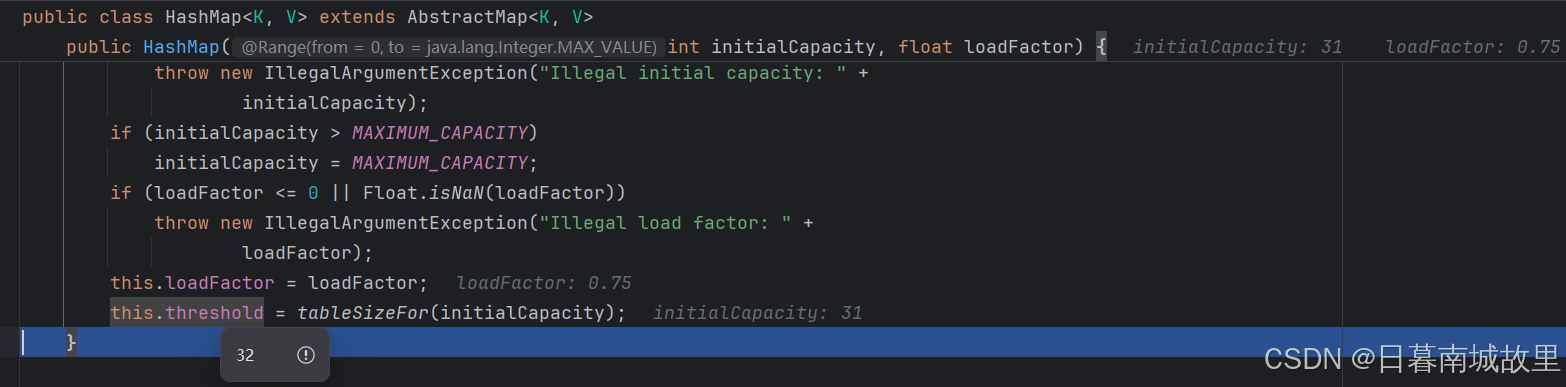
将容量设置为2的次幂的原因是加快哈希运算,减少哈希冲突。
- 加快哈希运算:对于计算机而言,使用二进制进行运算的速度是最快的。当一个数字是2的次幂时,hash & (length - 1) 的结果和 hash % length的结果是相同的。由于使用了&运算符,因此会提升效率。
- 减少哈希冲突:由于底层运算是hash & (length - 1),如果length是偶数,length - 1后一定是奇数,奇数二进制位最后一位一定是1,1和其他二进制位进行与运算,结果可能是1,也可能是0,这样可以减少哈希冲突,让散列分布更加均匀;如果length是奇数,length - 1后一定是偶数,偶数二进制位最后一位一定是0,0和任何数进行与运算,结果一定是0,这样就会导致发生大量的哈希冲突,白白浪费了一半的空间。
3.2 扩容机制
- 初始化容量为16
- 扩容时机:如果HashMap中存储元素的个数超过“数组长度 * loadFactor”的结果(loadFactor指的是负载因子,loadFactor的默认值一般为0.75),那么就需要执行数组扩容操作,就比如原先数量为16,负载因子为0.75,那当存储的数量超过12时,就会进行扩容
- 扩容为原来的2倍,原先为16,扩容后则为32
- 由于HashMap扩容后,需要重新再去计算每个元素的位置,会十分的消耗性能,因此建议在创建HashMap之前预测存入的元素个数,从而给一个合理的初始化容量,避免进行频繁地扩容操作