R-4B: 通过双模退火与强化学习激励多模态大语言模型的通用自主思考能力
⭐️ 简介
在本代码库中,我们推出R-4B——一个面向通用自动思考任务的多模态大语言模型,能够根据任务复杂度自主切换渐进式思考与直接响应生成模式。这种能力使R-4B在保证响应质量的同时,显著提升推理效率并降低计算成本。
R-4B的开发采用两阶段训练范式:(1) 双模态退火训练,建立视觉问答任务的思考与非思考双能力基础;(2) 双模态策略优化(BPO),使模型能根据输入需求自适应切换思考与非思考模式。
🚀 核心特性
-
🧠 智能思考,快速行动:自适应且可控的思考模式! 我们的模型提供三种响应流程控制模式。
- 自动思考模式:释放自动思考能力,适用于从简单问答到复杂科学分析的各类主题。仅在关键时启动思考,节省时间与算力。
- 支持手动控制:可显式命令模型启用·
思考或非思考功能,为每项任务自由选择最优策略。
-
🏆 卓越性能,全面开放! 我们的模型现已完全开源,在同等规模模型中实现顶尖性能。
📢 动态
- [2025.08.20] 🚀 支持vLLM引擎! 我们的R-4B模型现已全面兼容vLLM,实现高性能推理。
- [2025.08.18] 🏆 登顶开源榜首! 我们激动地宣布,R-4B在OpenCompass多模态推理榜单中位列所有开源模型第一!
- [2025.08.11] 🥇 20B级冠军! R-4B在OpenCompass多模态学术榜单20B参数以下模型中排名第一!
- [2025.08.05] 🎉 R-4B正式发布! 模型已在Hugging Face开放下载。
🔥 快速开始
以下示例展示如何通过🤗 Transformers使用R-4B。
使用🤗 Transformers对话
[!注意]
用户可通过thinking_mode参数动态控制模型响应模式(auto-thinking自动思考/thinking深度思考/non-thinking快速响应):thinking_mode=auto为自动思考模式;thinking_mode=long为深度思考模式;thinking_mode=short为快速响应模式。
默认采用auto-thinking自动思考模式。
import requests
from PIL import Image
import torch
from transformers import AutoModel, AutoProcessormodel_path = "YannQi/R-4B"# Load model
model = AutoModel.from_pretrained(model_path,torch_dtype=torch.float32,trust_remote_code=True,
).to("cuda")# Load processor
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)# Define conversation messages
messages = [{"role": "user","content": [{"type": "image","image": "http://images.cocodataset.org/val2017/000000039769.jpg",},{"type": "text", "text": "Describe this image."},],}
]# Apply chat template
text = processor.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,thinking_mode="auto"
)# Load image
image_url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(image_url, stream=True).raw)# Process inputs
inputs = processor(images=image,text=text,return_tensors="pt"
).to("cuda")# Generate output
generated_ids = model.generate(**inputs, max_new_tokens=16384)
output_ids = generated_ids[0][len(inputs.input_ids[0]):]# Decode output
output_text = processor.decode(output_ids,skip_special_tokens=True,clean_up_tokenization_spaces=False
)# Print result
print("Auto-Thinking Output:", output_text)
使用vLLM实现快速R-4B部署与推理
- 我们推荐使用vLLM进行快速R-4B模型的部署与推理
安装
R-4B的代码需要最新版本的vllm。请从本地源码进行安装:
git clone https://github.com/vllm-project/vllm.git
cd vllm
VLLM_USE_PRECOMPILED=1 uv pip install --editable .
在线服务
[!TIP]
thinking_mode开关在 vLLM 创建的 API 中同样可用。
默认为auto-thinking模式。
- 服务
vllm serve \yannqi/R-4B \--served-model-name r4b \--tensor-parallel-size 8 \--gpu-memory-utilization 0.8 \--host 0.0.0.0 \--port 8000 \--trust-remote-code
- Openai 聊天完成客户端
import base64
from PIL import Image
from openai import OpenAI# Set OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"client = OpenAI(api_key=openai_api_key,base_url=openai_api_base,
)# image url
image_messages = [{"role": "user","content": [{"type": "image_url","image_url": {"url": "http://images.cocodataset.org/val2017/000000039769.jpg"},},{"type": "text", "text": "Describe this image."},],},
]chat_response = client.chat.completions.create(model="r4b",messages=image_messages,max_tokens=16384,extra_body={"chat_template_kwargs": {"thinking_mode": "auto"},},
)
print("Chat response:", chat_response)
📈 实验结果
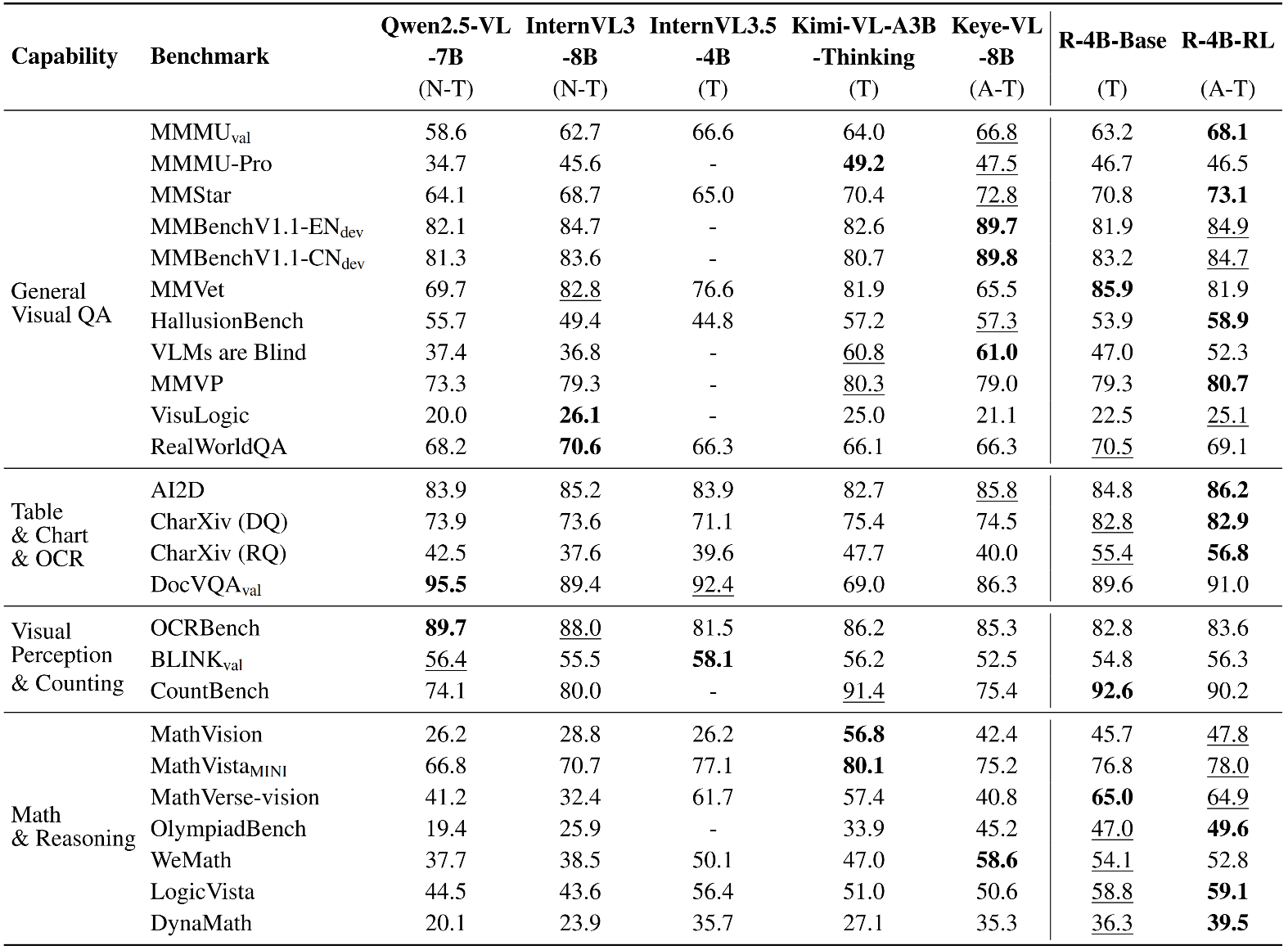
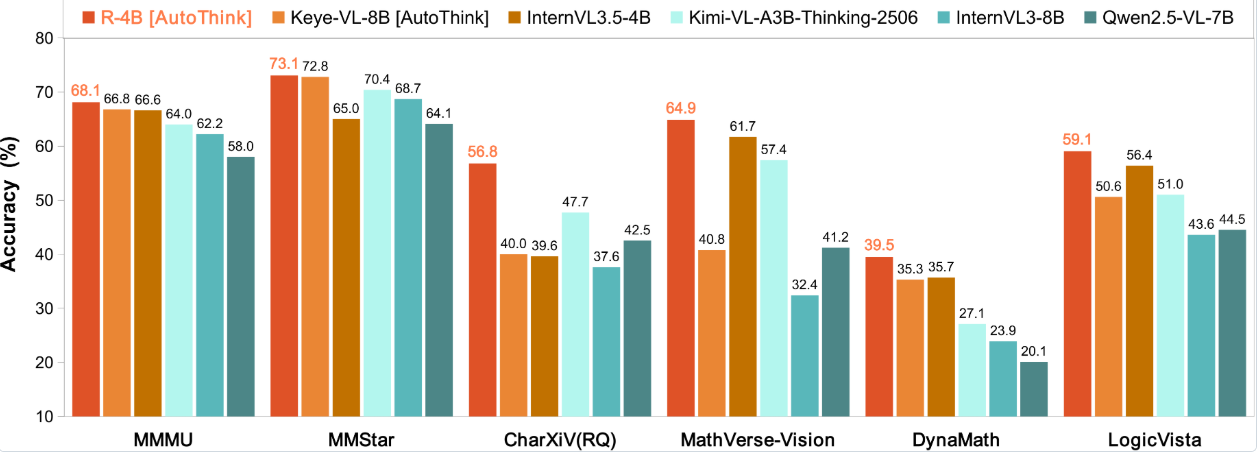
- R-4B凭借强大的尖端感知能力确立了自身地位,其性能可与更大规模的模型竞争。
- 在需要复杂逻辑推理和数学问题解决的评估集(如WeMath、MathVerse和LogicVista)中,R-4B展现出强劲的性能曲线,突显了其在逻辑推导和解决复杂量化问题方面的高级自适应思维能力。