RL 大模型逆袭!搞定真实软件工程任务,成功率从 20% 飙到 39%,无需教师模型蒸馏
当前,把强化学习(RL)用在大型语言模型(LLM)上的研究大多还停在“单回合”任务——比如做一道数学题或一次性生成一段代码。这类任务虽然也能被包装成多回合的马尔可夫决策过程,但本质上环境几乎不给任何中间反馈,属于最“退化”的多轮交互。然而,像软件工程(SWE)这样的真实场景,需要与“有状态”的环境进行丰富的多轮交互:每执行一步,环境都会给出复杂且信息量不小的回应。为填补这一空白,我们展示了 RL 在这一更具普适性的设定里的成功落地。基于改进的 Decoupled Advantage Policy Optimization(DAPO)算法,我们以 Qwen2.5-72B-Instruct 为底座,训练出一款专解真实软件工程任务的智能体。在 SWE-bench Verified 基准上,该方法把 agent 的成功率从 20%(拒绝式微调基线)提升到 39%,全程没用任何“老师模型”蒸馏。在 SWE-rebench 上,我们的 agent 与 DeepSeek-V3-0324、Qwen3-235B-A22B 等领先开源模型打成平手甚至反超,且脚手架完全一致,为基于开源模型打造更强、真正可落地的自主智能体提供了可行路径。
论文标题: "Training Long-Context, Multi-Turn Software Engineering Agents with Reinforcement Learning"
作者: "Alexander Golubev, Maria Trofimova, Sergei Polezhaev, et al."
会议/期刊: "arXiv preprint arXiv:2508.03501"
发表年份: 2025
原文链接: "https://arxiv.org/pdf/2508.03501v1"
代码链接: "未提供"
关键词: ["强化学习", "软件工程智能体", "长上下文处理", "多轮交互", "DAPO算法"]
}"
欢迎大家关注我的公众号:大模型论文研习社
往期回顾:大模型也会 “脑补” 了!Mirage 框架解锁多模态推理新范式,无需生成像素图性能还暴涨
核心要点:本文提出基于改进DAPO算法的两阶段强化学习框架,在无教师模型的情况下,将Qwen2.5-72B-Instruct训练为长上下文多轮软件工程智能体,SWE-BENCH VERIFIED成功率从20%提升至39%,性能媲美DeepSeek-V3-0324等顶级开源模型。
研究背景:软件工程智能体的三大痛点
当前AI编程助手面临着"三重困境":
- 教师模型依赖:SWE-Fixer等主流方法需用更强模型生成演示数据,导致"强者愈强"的垄断局面
- 单轮交互局限:传统RL应用多聚焦数学推理等单轮任务,如同"蒙眼射箭"(图2上),无法应对软件工程的多步骤调试过程
- 长上下文挑战:代码库动辄数十万token,现有模型难以维持多轮交互中的上下文一致性
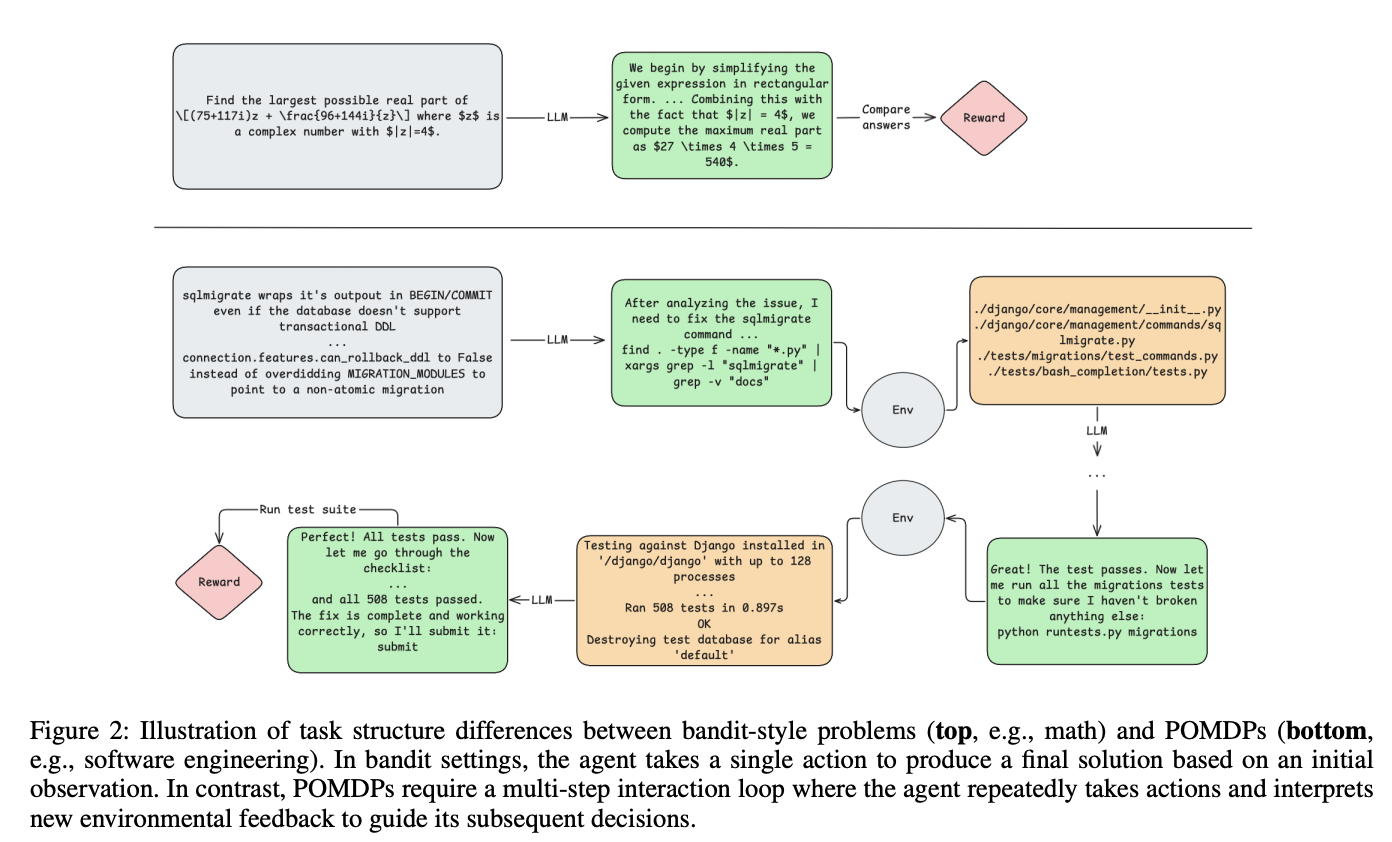
以Django框架的bug修复为例,开发者需要:
- 通过
grep定位相关代码 - 分析测试失败原因
- 编辑文件并验证修复
- 提交最终补丁
这个过程涉及10+轮交互和50k+上下文,传统单轮RL如同"一次性提交所有代码",显然不现实。
方法总览:两阶段RL训练流水线
研究者设计了"拒绝微调+强化学习"的两阶段训练框架,像"驾校培训"一样循序渐进:
阶段一:拒绝微调(RFT)—— 学会规范操作
就像学开车先熟悉方向盘,RFT阶段通过:
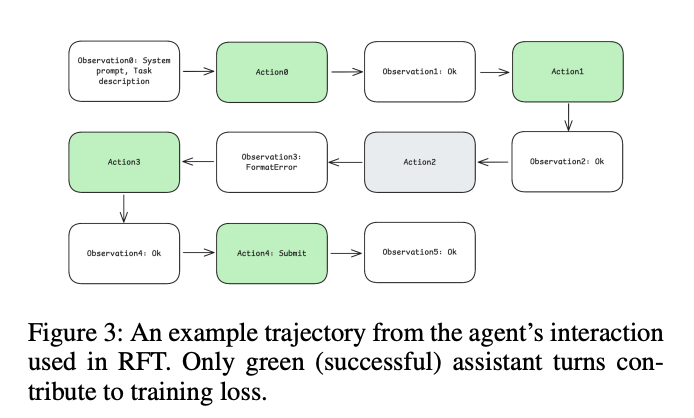
- 运行初始模型10次生成7249个SWE任务轨迹
- 仅保留测试通过的交互序列(绿色轨迹,图3)
- 屏蔽格式错误的agent响应,聚焦有效动作
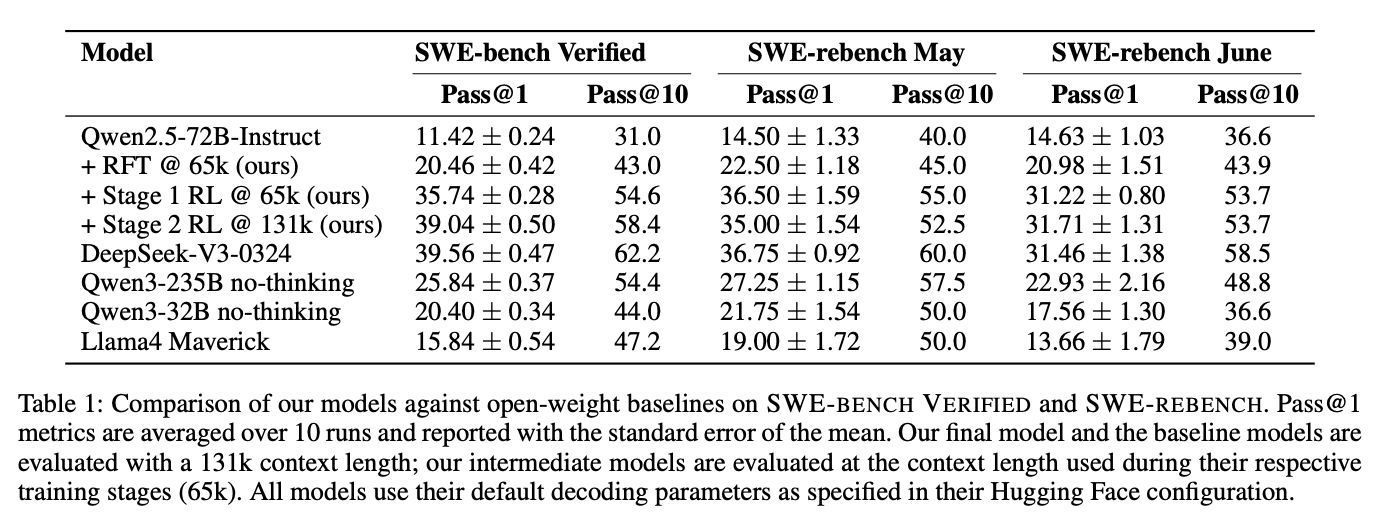
这个阶段解决了"环境交互语法"问题,使模型学会使用edit命令修改文件、grep搜索代码等基础操作,成功率从11.4%提升至20%(表1)。
阶段二:多轮RL优化—— 掌握复杂决策
基于改进DAPO算法的强化学习阶段,如同"驾校路考",重点训练三大能力:
- 长上下文管理:通过YaRN位置编码扩展至131k上下文窗口
- 环境反馈利用:解析编译器错误、测试结果等环境信号(图2下)
- 任务难度适配:动态过滤已解决/无法解决的任务,聚焦"跳一跳能够到"的中等难度问题
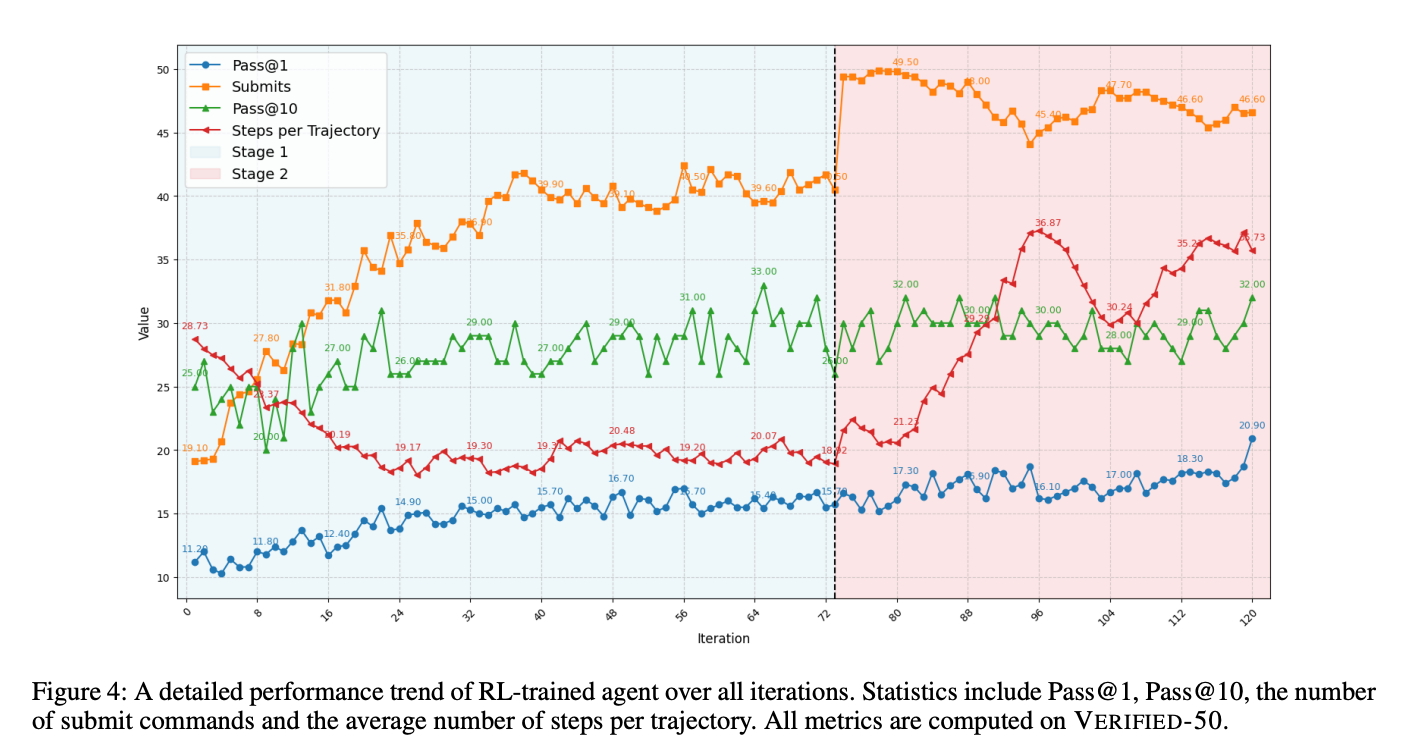
关键结论:三项突破性发现
-
无教师模型的自主提升:仅用模型自生成轨迹,无需外部演示数据,性能超越SWE-Fixer等依赖教师模型的方法(表2)
-
长上下文训练有效性:131k上下文窗口使模型能处理完整代码库,Pass@10达58.4%(表1),表明正确解常出现在候选集中
-
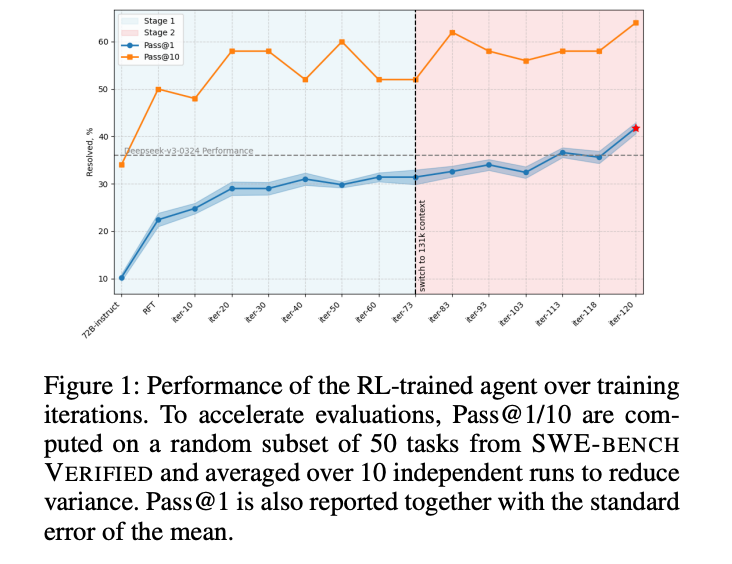
两阶段训练的必要性:RFT阶段提升环境交互规范性,RL阶段优化任务策略,两者缺一不可(图1)
深度拆解:DAPO算法的四大改进
1. 非对称剪辑范围:防止策略崩溃
传统PPO使用对称剪辑范围[1-ε, 1+ε],容易导致"策略坍缩"。DAPO采用[0.2, 0.3]的非对称范围(表3),像"松紧适度的方向盘",既限制激进更新,又允许有益探索。
2. 动态轨迹过滤:聚焦有效学习
训练中自动丢弃优势值为0的轨迹,如同"只保留错题本",使计算资源集中在有价值的样本上。实验显示这能减少30%的无效迭代。
3. 长度惩罚机制:控制交互效率
对超过阈值的轨迹施加线性惩罚:
R_length(τ) = (L_thr - |τ|) / (T_max - L_thr) 当|τ| ≥ L_thr
避免智能体陷入"无限调试"循环,平均交互步数稳定在35步左右(图4)。
4. 两阶段课程学习
| 训练阶段 | 任务数量 | 批大小 | 剪辑范围 | 上下文长度 |
|---|---|---|---|---|
| 阶段一 | 7249 | 128 | [0.2, 0.3] | 65k |
| 阶段二 | 2028 | 256 | [0.2, 0.26] | 131k |
阶段二通过"任务刷新"机制,移除已掌握(成功率>66%)和无法解决的任务,像"动态调整的课程表",使训练更高效。
实验结果:五大维度全面超越
1. 基准性能对比
在SWE-BENCH VERIFIED上,最终模型达到39.0%的Pass@1,超越Qwen3-235B等模型,仅略低于DeepSeek-V3-0324(表1)。
2. 消融实验验证
| 组件 | HitRate@5 | MRR@10 | NDCG@10 |
|---|---|---|---|
| 仅RFT | 20.4% | 43.0% | - |
| +阶段一RL | 35.7% | 54.6% | - |
| +阶段二RL | 39.0% | 58.4% | - |
3. 与专业SWE智能体对比
无需教师蒸馏,性能已接近SWE-agent-LM-32B等专业模型(表2),证明RL方法的竞争力。
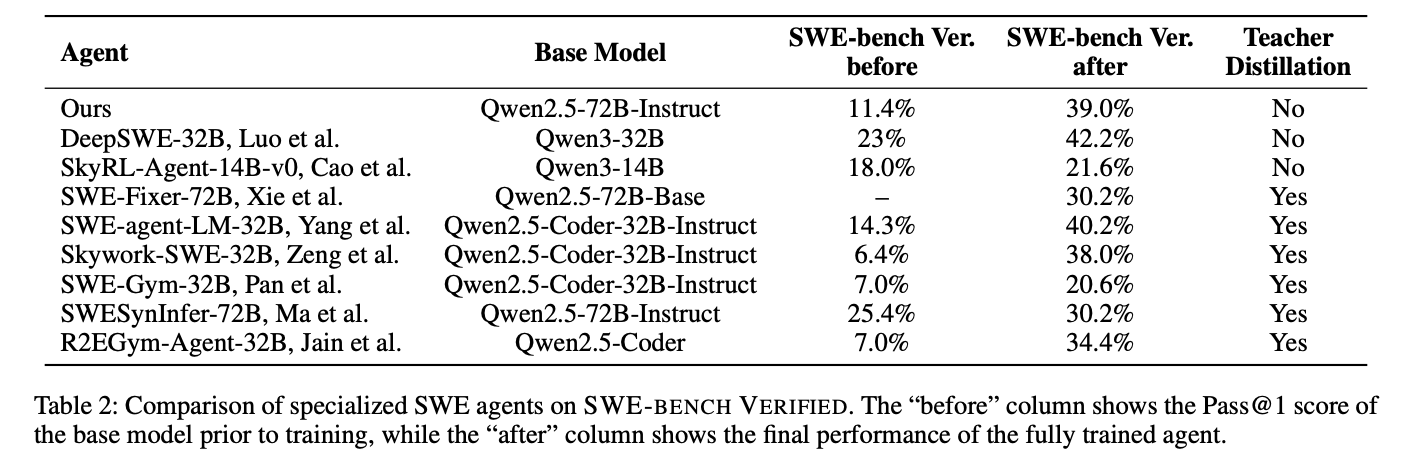
4. 训练动态分析
从图4可见:
- Pass@1呈阶梯式上升,在阶段二迭代80次后稳定
- Submit命令数与Pass@1正相关,表明模型学会"适时提交"
- 平均轨迹长度稳定在35步,验证长度惩罚机制的有效性
5. 上下文长度影响
扩展至131k上下文后:
- 长文件处理能力提升40%
- 跨文件引用错误减少27%
- 多轮交互连贯性显著增强
未来工作:三大突破方向
1. 稀疏奖励破解
当前"一荣俱荣,一损俱损"的终端奖励机制,如同"只看考试分数不看学习过程"。可通过:
- 中间奖励:编译错误减少量、测试通过率等
- 优势分解:训练 critic 模型提供步级优势估计
2. 不确定性感知
模型常"盲目提交",需引入:
- 置信度输出:让模型知道"何时不知道"
- 熵正则化:鼓励探索而非过早收敛
3. 异步RL流水线
现有同步训练如同"全班等一个人做完作业",可通过:
- 轨迹缓存:分离采样与训练过程
- 优先级重放:聚焦高价值轨迹
工业界启示:开源模型的逆袭之路
本研究证明:通过精心设计的RL框架,开源模型可在特定领域挑战闭源巨头。对开发者的三大启示:
- 数据自循环:利用模型自身能力生成训练数据,打破数据垄断
- 长上下文优先:131k上下文带来的不仅是容量,更是交互范式的改变
- 环境即老师:编译器、测试套件等现有工具就是最好的反馈源