Deformable 3D Gaussians:把动态场景装进“可变形的静态世界”
一文读懂为什么不直接做 4D、高频怎么来、AST 时间退火到底在惩罚什么、以及一个刻意“慢热”的训练流程如何把细节捞回来。
论文:Deformable 3D Gaussians for High-Fidelity Monocular Dynamic Scene Reconstruction
Arxiv:2309.13101
Motivation|为什么要在“静态规范空间”里建动态?
-
NeRF 隐式表达:画质赞,但在一般动态场景里实时渲染困难。
-
3D Gaussian Splatting(3DGS):渲染快,但强依赖定制栅格化管线,扩展到“时间维度”并不优雅。
-
核心思路:别直接做随时间变化的 4D 高斯。我们先在一个时间不变的参考系(canonical / 规范空间)学一套静态 3D 高斯,再用一个时间条件的变形场去“驱动”它们随时间运动。
-
训练稳定器:引入 AST(Annealed Smoothing in Time)时间退火平滑,先抑制时间上的高频,后期再把细节补回来。
方法总览
1) 表征解耦:Canonical Gaussians + 变形场
-
Canonical Gaussians:在时间不变的参考系中,学习并维护一组静态 3D 高斯(中心、协方差、颜色等)。
-
变形场(Deformation MLP):给定时刻 ttt,为每个高斯输出一个位置偏移
。最终时刻位置
-
为什么不直接 4DGS?
-
直接把“时间”塞进高斯参数会导致参数爆炸与数据稀疏(每个时刻都要学局部参数)。
-
canonical→deform 的两段式,更可控、更稳:静态里学结构,动态里学运动。
-
实践要点:将作为变形网络输入的高斯中心 μ\muμ 做 detach(停止梯度),避免“中心既当输入又被更新”形成梯度捷径,导致变形场退化。
2) 给变形场喂“高频”:时间/位置的 NeRF 风格多频率编码
问题:原始坐标 + ReLU/SiLU MLP 更擅长拟合低频,难以表达复杂快速的位移模式。
方案:对空间坐标 x\mathbf{x}x 与时间 ttt 都做 NeRF 风格的 Fourier 编码,并与原值拼接后输入 MLP。
-
时间归一化:
-
时间编码(拼上原始 t 以保低频):
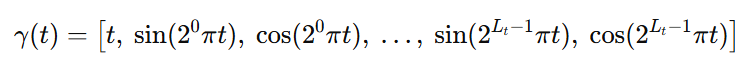
-
空间编码(按维度逐元素):
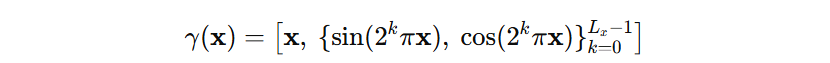
-
变形网络输入:
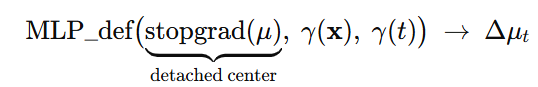
直觉:加了多频率编码后,高频只需线性组合就能表达,MLP 不用“费劲”曲线拟合。
3) 训练流程重排:3k 迭代热身 → 联合优化
-
热身阶段(约 3k iters):只训练 canonical 3D 高斯,先把“静态结构”学稳,等价于给后续变形场一个干净的“锚点”。
-
联合阶段:再与变形场一起进入 3DGS 标准训练循环(反向传播 + densify/prune)。
-
densify:在误差高/贡献大的区域生长更多高斯;
-
prune:剔除贡献小/冗余高斯。
-
好处:避免一上来“结构与运动”纠缠学习带来的震荡,先稳结构,再学运动。
4) AST 时间退火平滑:先抑制高频,再放开细节

做法:训练时对输入时间加噪:
并让 随迭代线性退火到 0。
直觉:
-
初期
大 → 同一时刻被“抖”到邻域 → 时间维上被迫平滑(抗姿态噪声/时间抖动)。
-
后期
一阶近似解释(为什么它在“惩罚时间导数”):
令渲染函数为 ,监督目标为 y。考虑扰动后的 MSE:
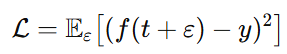
做泰勒展开
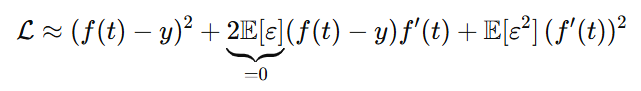
因为,得到:
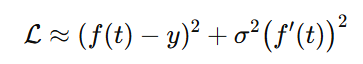
这等价于在目标里显式加上时间导数正则,σ\sigmaσ 越大惩罚越强 → 初期抑制高频,退火后释放高频。
训练细节(Train)
-
阶段一(热身 ~3k iters)
-
目标:得到高质量 canonical 高斯(位置/形状/颜色等)。
-
做法:按 3DGS 常规监督(如重建误差)优化,仅更新 canonical 参数。
-
-
阶段二(联合)
-
目标:在稳定静态结构上学习时变运动。
-
做法:变形场与 canonical 联合反向传播,并按 3DGS 流水线执行 densify / prune。
-
-
优化器:Adam。
-
学习率:变形场的 lr 做指数衰减(早期更依赖全局/低频,后期更精修局部/高频)。
监督项可复用 3DGS 的常见配方(如基于像素的重建损失等),不强行引入额外复杂度。
Pipeline(工作流一图串)
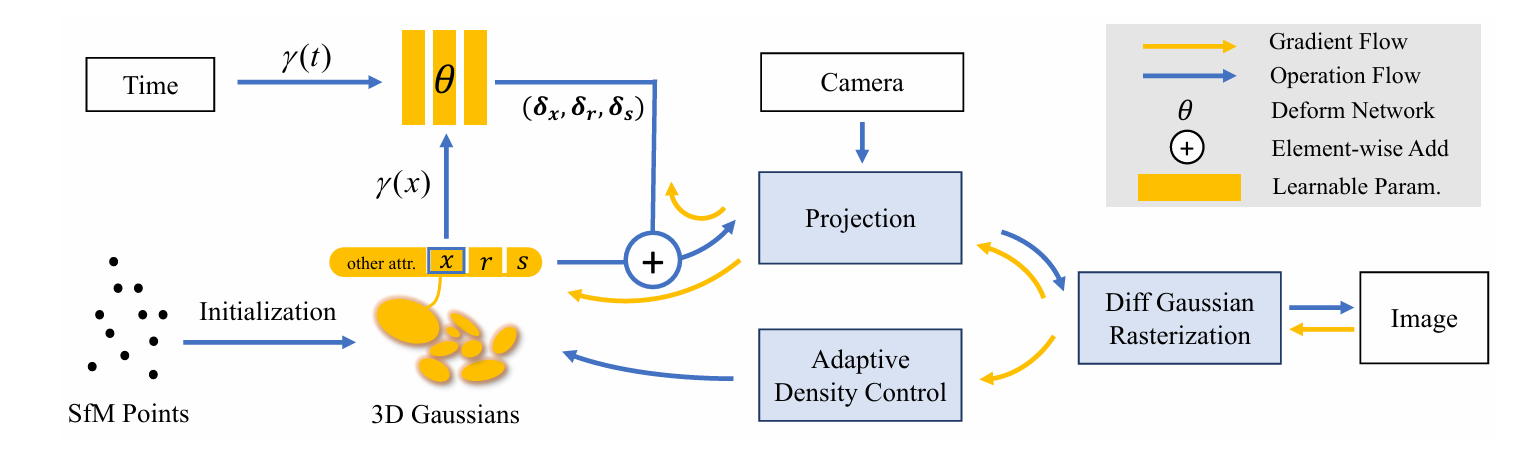
-
采样一帧(含时刻 ttt 与相机姿态)。
-
编码输入:
+ detached 的
(canonical 高斯中心)。
-
变形场输出
,得到时刻位置
。
-
3DGS 栅格化渲染该时刻的高斯集合
-
计算重建损失并反传:
-
热身阶段:只更新 canonical;
-
联合阶段:同时更新 canonical 与变形 MLP,并周期性 densify/prune。
-
-
AST:训练期间对 ttt 注入退火高斯噪声(早抑制、晚放开)。
常见问答(FAQ)
Q:为什么要把时间高频交给编码而不是 MLP 自己学?
A:带 ReLU/SiLU 的 MLP 有谱偏置,天然更擅长低频。Fourier 编码把高频“预制”成基底,线性组合就能表达,拟合更轻松、训练更稳。
Q:AST 会不会让细节学不回来?
A:不会。σ\sigmaσ 退火至 0 后,正则自动消失;且你已经有稳定的 canonical 结构做锚点,后期细节会逐步补齐。
Q:和 4DGS 相比的最直接收益?
A:参数共享与数据效率。canonical 把“形体”集中、变形场只学“运动”;训练与推理都更可控,泛化也更自然。
结语
把动态拆成“静态形体 + 时变位移”,再用 AST 做一条“先稳后细”的时间通道,是这套 Deformable 3DGS 的精髓。它既保留了 3DGS 的高效渲染,又以低成本引入了动态建模能力:
先学好“身架子”,再教它“怎么动”。