[论文阅读] 人工智能 + 软件工程 | ReCode:解决LLM代码修复“贵又慢”!细粒度检索+真实基准让修复准确率飙升
ReCode:解决LLM代码修复“贵又慢”!细粒度检索+真实基准让修复准确率飙升
论文信息
- 原标题:ReCode: Improving LLM-based Code Repair with Fine-Grained Retrieval-Augmented Generation
- 主要作者:Yicong Zhao(复旦大学)、Shisong Chen(华东师范大学)、Jiacheng Zhang(复旦大学)、Zhixu Li*(中国人民大学,通讯作者)
- 研究机构:复旦大学计算机科学与人工智能学院、华东师范大学上海人工智能教育研究院、中国人民大学信息学院&智能治理学院
- APA引文格式:Zhao, Y., Chen, S., Zhang, J., & Li, Z. (2025). ReCode: Improving LLM-based Code Repair with Fine-Grained Retrieval-Augmented Generation. arXiv preprint arXiv:2509.02330.
- 论文链接:https://arxiv.org/pdf/2509.02330
一段话总结
为解决现有基于LLM的代码修复方法“训练/推理成本高”“传统检索增强(RAG)质量低”“对分布外(OOD)缺陷适应性差”的痛点,研究者提出ReCode——一款融合“算法感知检索”(用LLM预测代码算法类型缩小检索范围)与“双视图编码”(分别处理文本描述和代码结构)的细粒度检索增强框架;同时构建真实代码基准RACodeBench(基于用户提交的错误-修复代码对)替代合成数据。实验表明,ReCode在RACodeBench及6个竞争性编程数据集(如AtCoder、CodeChef)上,相比best-of-N、self-repair等基线,不仅实现更高修复准确率(如GPT-4o-mini测试通过率达41.06%),还将推理成本降低3-4倍(如AtCoder达35%通过率仅需4次LLM调用)。
思维导图
研究背景
如果你用过GitHub Copilot这类AI编程工具,可能会惊叹LLM在生成代码时的“聪明”——但当代码出了bug(比如循环边界错、逻辑漏判),让LLM修复时,问题就暴露了:
首先,训练成本太高。要让LLM擅长修代码,要么用大量人工标注的“错误-修复”代码对训练(标注费贵到离谱),要么持续微调——但微调后模型可能“忘”了之前的技能(这叫“灾难性遗忘”),比如刚学好修Python bug,就不会修C++了。
其次,推理成本不低。现有修复方法要么生成多个候选代码选最优(比如best-of-N,要调用LLM8-32次),要么多轮迭代修(比如self-repair,先找错再改,调用次数更多),相当于“反复问AI同一个问题直到对”,又慢又费资源。
更头疼的是传统检索增强(RAG)不好用。为了让LLM“参考旧案例”,传统RAG会把“问题描述+错误代码”合并成一个向量检索——这就像“在图书馆找书只看封面”:比如要修“找数组最小正整数”的代码(错误是循环里的判断条件错),传统RAG可能没抓到“循环结构”这个关键,找回来的案例跟当前bug不匹配,反而帮倒忙。
最后,应对陌生bug很弱。如果遇到训练时没见过的缺陷(比如没学过的动态规划边界错),LLM就像“没见过这道题的学生”,只能瞎蒙,修复率骤降——这就是“分布外(OOD)缺陷”问题。
简单说,现有方法要么“贵得用不起”,要么“笨得不好用”,急需一个“又便宜又聪明”的方案。
创新点
ReCode的核心亮点就在于“针对性解决上述痛点”,有三个关键创新:
-
算法感知检索:先“分类”再找案例
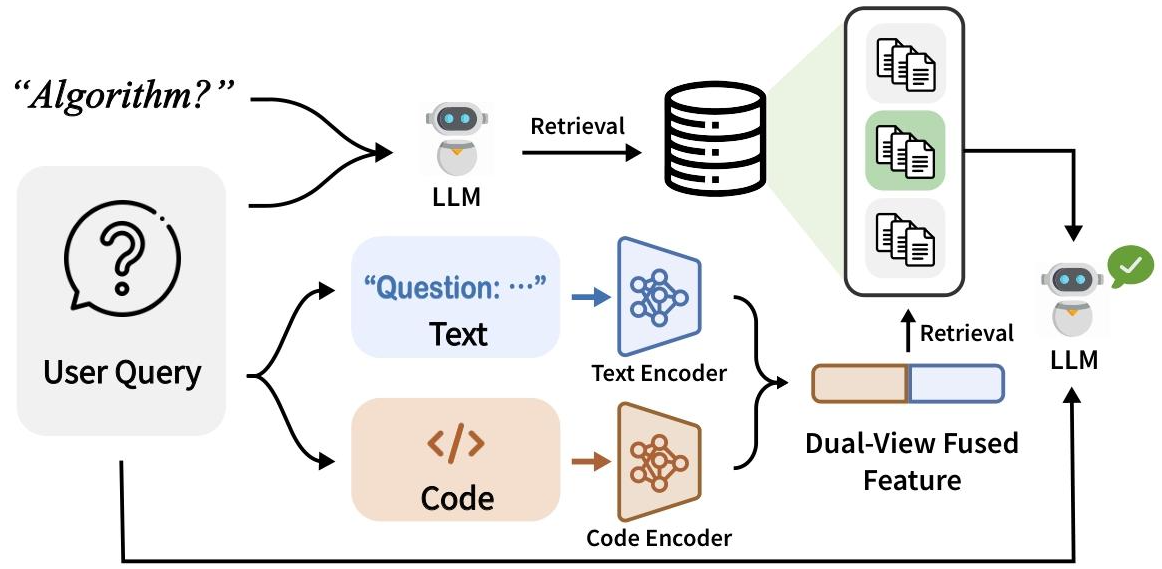
传统RAG是“全库乱找”,ReCode先用LLM分析输入代码的“算法类型”(比如是贪心、动态规划还是二分查找),甚至支持“多标签”(比如代码里既有图遍历又有贪心),然后只在对应“算法子库”里检索——相当于“先按学科找书架,再挑书”,大幅提升案例相关性。 -
双视图编码:分开处理“文字”和“代码”
传统RAG把“问题描述(文字)”和“错误代码(代码)”揉成一个向量,导致代码的语法结构被忽略。ReCode用两个专用编码器:- 文本编码器(bge-m3):抓“问题要做什么”(比如“找最小正整数”);
- 代码编码器(OASIS-code-1.3B):抓“代码结构错在哪”(比如“循环里num>0&num<minPos的判断错”);
再融合两者特征——相当于“既看题目要求,又看代码细节”,检索精度翻倍。
-
真实基准RACodeBench:告别“假数据”
之前的代码修复基准多是“人工造的bug”(比如故意改个变量名),跟真实开发场景差太远。RACodeBench直接用Codeforces用户提交的真实代码:每个案例都有“问题描述+错误代码+正确代码+测试用例+错误标注”,甚至标了“改了哪几行”(diff)——让评估结果更贴近真实使用场景。 -
准确率与效率双赢:不做“选择题”
很多方法要么为了准确率牺牲效率(比如多轮迭代),要么为了效率放弃准确率(比如单轮生成)。ReCode通过“精准检索+少次调用”,做到“调用8次LLM的效果,比别人调用16次还好”,真正实现“又快又准”。
研究方法和思路、实验方法
一、ReCode框架工作流程(分6步)
- 输入分解:把用户查询拆成“自然语言问题描述”(比如“找数组最小正整数”)和“错误代码”(比如循环判断错的代码);
- 双视图编码:
- 文本编码器(bge-m3)处理问题描述,输出“语义向量”;
- 代码编码器(OASIS-code-1.3B)处理错误代码,输出“结构向量”;
- 融合两个向量,得到“细粒度特征向量”;
- 算法类型预测:用LLM分析错误代码,输出1个或多个算法标签(比如“贪心算法”);
- 定向检索:根据算法标签,在“算法子库”中找最匹配“细粒度特征向量”的案例(每个案例含“问题+错误代码+正确代码”);
- Prompt构建:把检索到的案例和用户输入拼接成Prompt(比如“参考这个贪心算法的修复案例,修下面的代码:XXX”);
- 生成修复代码:把Prompt输入LLM,生成满足所有测试用例的正确代码。
二、实验设计细节
1. 实验数据
| 数据类型 | 具体内容 |
|---|---|
| 分布内数据集 | RACodeBench(基于Codeforces真实提交,含错误-修复对、测试用例、错误标注) |
| OOD数据集 | 6个竞争性编程数据集:AtCoder(800题)、CodeChef(2.4k题)、HackerRank(720题)、HackerEarth(1k题)、GeeksforGeeks(680题)、Aizu(1.8k题) |
2. 模型选择
| 模块 | 模型名称 | 作用 |
|---|---|---|
| 文本编码 | bge-m3 | 处理问题描述,生成语义向量 |
| 代码编码 | OASIS-code-1.3B | 处理错误代码,生成结构向量 |
| 推理生成 | GPT-4o-mini、Gemini-1.5-Flash、Gemma-2-9B/27B、DeepSeek系列 | 生成修复代码 |
3. 评估指标
- 测试通过率:所有问题的“平均测试用例通过比例”(比如某问题有10个测试用例,最优候选过了8个,贡献0.8);
- 严格准确率:“通过所有测试用例的问题比例”(只有候选过了所有测试用例,才算1分)。
4. 基线对比
- best-of-N:生成N个候选代码,选最优(N=8/32,采样温度1.0保证多样性);
- self-repair:多轮迭代(先找错再改,调用次数和ReCode一致)。
主要成果和贡献
一、核心实验结果(用表格更清晰)
1. 分布内性能(RACodeBench,N=8次LLM调用)
| 模型类型 | 模型名称 | 测试通过率(%)- best-of-N | 测试通过率(%)- self-repair | 测试通过率(%)- ReCode | 严格准确率(%)- ReCode |
|---|---|---|---|---|---|
| 开源模型 | Gemma-2-9B | 23.34 | 22.67 | 26.07 | 16.67 |
| 开源模型 | Gemma-2-27B | 24.96 | 22.74 | 29.83 | 19.17 |
| 开源模型 | DeepSeek-Coder-V2-Instruct | 31.54 | 33.08 | 40.47 | 28.75 |
| 闭源模型 | GPT-4o-mini | 31.09 | 34.79 | 41.06 | 30.41 |
2. 推理成本对比(AtCoder数据集,GPT-4o-mini)
| 测试通过率目标(%) | LLM调用次数 - best-of-N | LLM调用次数 - self-repair | LLM调用次数 - ReCode |
|---|---|---|---|
| 35.0 | 11 | 15 | 4 |
| 35.5 | 12 | 15 | 5 |
| 36.0 | 16 | 19 | 6 |
3. OOD性能(以GPT-4o-mini为例,N=32次调用)
| OOD数据集 | 测试通过率(%)- best-of-N | 测试通过率(%)- self-repair | 测试通过率(%)- ReCode |
|---|---|---|---|
| AtCoder | 33.2 | 34.5 | 37.8 |
| CodeChef | 30.1 | 31.8 | 35.2 |
| HackerRank | 32.5 | 33.9 | 36.7 |
二、研究贡献(3点核心价值)
- 方法创新:提出ReCode框架,首次将“算法感知检索”与“双视图编码”结合,解决传统RAG在代码修复中的缺陷,为LLM代码修复提供“低成本高准确率”的新范式;
- 数据创新:构建RACodeBench基准,填补“真实场景代码修复评估”的空白,让后续研究能更精准地验证方法有效性;
- 实践价值:实验证明ReCode在开源/闭源LLM上均有效,且推理成本低,可直接落地到真实开发工具(如IDE插件、AI编程助手)。
三、开源资源说明
- 目前论文未公开ReCode框架的开源代码及RACodeBench完整数据集,但明确说明数据来源于Codeforces用户公开提交,可基于Codeforces API及论文描述的“半自动化标注流程”复现知识库与基准。
关键问题
1. ReCode是如何解决传统RAG“检索质量低”的核心问题的?
传统RAG的问题是“统一编码+全库检索”:把文字和代码揉成一个向量,忽略代码结构;且不区分算法类型,导致案例不匹配。ReCode用两点解决:一是“双视图编码”,分开处理文字(抓语义)和代码(抓结构),再融合细粒度特征;二是“算法感知检索”,先预测代码的算法类型,只在对应子库检索,从“乱找”变成“精准找”。
2. RACodeBench相比之前的合成基准,优势在哪里?
之前的合成基准是“人工造bug”(比如故意改变量名、删分号),和真实开发中的“逻辑错”(比如循环边界、动态规划状态转移错)差距大。RACodeBench的优势:① 数据来自真实用户提交,bug类型更贴近实际;② 每个案例含完整测试用例,能精准验证修复正确性;③ 有细粒度错误标注和代码diff,方便分析修复效果;④ 与检索知识库严格分区,避免数据污染。
3. ReCode为什么能在OOD场景(比如没见过的数据集)表现好?
因为ReCode依赖“算法类型”而非“具体数据分布”:比如在Codeforces上学了“贪心算法修循环错”,到AtCoder遇到同样算法类型的bug,即使数据集不同,也能通过“算法感知检索”找到匹配案例。而传统方法依赖训练时的静态数据,遇到OOD场景就“没见过”,修复率骤降。
4. ReCode的“算法感知检索”为什么要支持多标签?
因为真实代码往往融合多种算法:比如一道题既要“图遍历”找路径,又要“贪心算法”选最优路径。如果只标一个算法标签,会漏掉关键案例;多标签设计能覆盖这种复杂场景,让检索到的案例更全面,修复更准确。
5. ReCode如何平衡“修复准确率”和“推理成本”?
传统方法要么靠“多调用LLM”提准确率(比如best-of-N调用32次),要么靠“少调用”降成本(比如单轮调用)。ReCode的关键是“精准检索”:通过算法感知和双视图编码,让LLM“参考1个高质量案例,比参考10个低质量案例效果还好”——比如调用8次LLM的准确率,比best-of-N调用16次还高,实现“少调用、高准确”。
总结
ReCode针对现有LLM代码修复“高成本、低检索质量、OOD适应性差”的痛点,提出融合“算法感知检索”与“双视图编码”的细粒度检索增强框架,同时构建真实基准RACodeBench。实验表明,在RACodeBench及6个OOD竞争性编程数据集上,ReCode相比best-of-N、self-repair等基线,不仅显著提升修复准确率(开源/闭源LLM均适用),还将推理成本降低3-4倍。该研究为LLM代码修复提供了“低成本、高泛化、贴近真实场景”的新方案,其设计思路(算法感知、双视图编码)也为其他代码智能任务(如代码生成、错误检测)提供了参考,具有重要的理论与实践价值。