根据用户ID获取所有子节点数据或是上级直属节点数据
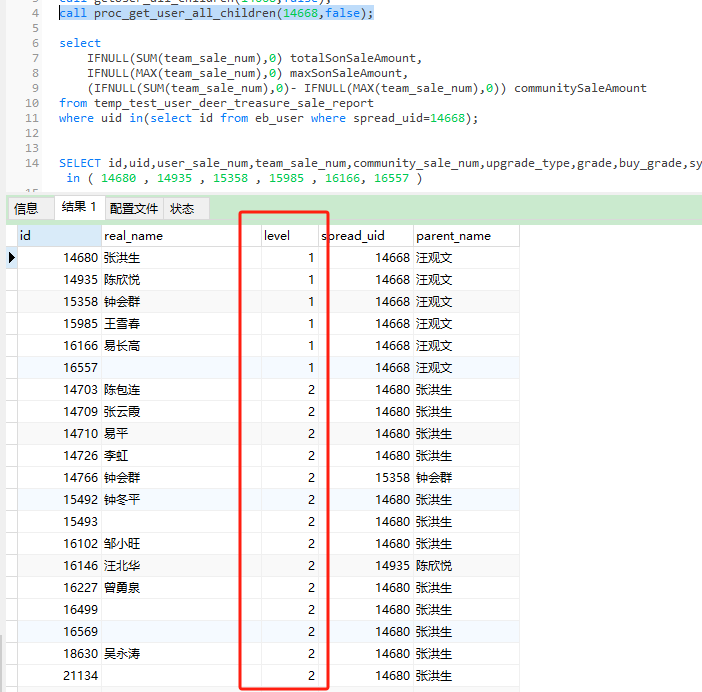
一、根据用户ID获取所有子节点,通过存储过程来实现
CREATE DEFINER=`crmeb`@`%` PROCEDURE `proc_get_user_all_children`(
IN rootUid INTEGER, -- 要查询的根用户ID
IN includeSelf BOOLEAN -- 是否包含自身(1=包含,0=不包含)
)
BEGIN
-- 声明变量
DECLARE current_level INT DEFAULT 0;
-- 创建临时表存储最终结果
DROP TEMPORARY TABLE IF EXISTS final_result;
CREATE TEMPORARY TABLE final_result (
id INT PRIMARY KEY,
level INT COMMENT '层级深度',
spread_uid INT COMMENT '直接上级ID'
) ENGINE=InnoDB;
-- 创建临时表存储当前层级的用户
DROP TEMPORARY TABLE IF EXISTS current_level_users;
CREATE TEMPORARY TABLE current_level_users (
id INT PRIMARY KEY
) ENGINE=Memory;
-- 创建临时表存储下一层级的用户
DROP TEMPORARY TABLE IF EXISTS next_level_users;
CREATE TEMPORARY TABLE next_level_users (
id INT PRIMARY KEY,
spread_uid INT
) ENGINE=Memory;
-- 初始化:添加根节点(如果选择包含自身)
IF includeSelf THEN
INSERT INTO final_result
SELECT id, 0, spread_uid
FROM eb_user
WHERE id = rootUid;
END IF;
-- 初始化当前层级(根节点的直接下级)
INSERT INTO current_level_users
SELECT id
FROM eb_user
WHERE spread_uid = rootUid AND id != IF(includeSelf, -1, rootUid);
-- 将直接下级加入结果集
INSERT INTO final_result
SELECT u.id, 1, u.spread_uid
FROM eb_user u
WHERE u.spread_uid = rootUid AND u.id != IF(includeSelf, -1, rootUid);
-- 循环处理每一层级(广度优先遍历)
WHILE EXISTS (SELECT 1 FROM current_level_users) DO
SET current_level = current_level + 1;
-- 清空下一层级临时表
TRUNCATE TABLE next_level_users;
-- 查找当前层级用户的直接下级
INSERT INTO next_level_users
SELECT u.id, u.spread_uid
FROM eb_user u
JOIN current_level_users c ON u.spread_uid = c.id
WHERE u.id NOT IN (SELECT id FROM final_result);
-- 将新找到的子节点添加到结果表
INSERT INTO final_result
SELECT id, current_level + 1, spread_uid
FROM next_level_users;
-- 准备处理下一层级
TRUNCATE TABLE current_level_users;
INSERT INTO current_level_users
SELECT id FROM next_level_users;
END WHILE;
-- 返回最终结果
SELECT
r.id,
u.real_name, -- 假设表中有real_name字段
r.level,
r.spread_uid,
p.real_name AS parent_name -- 上级用户名
FROM final_result r
JOIN eb_user u ON r.id = u.id
LEFT JOIN eb_user p ON r.spread_uid = p.id
ORDER BY r.level, r.id;
-- 清理临时表
DROP TEMPORARY TABLE IF EXISTS final_result;
DROP TEMPORARY TABLE IF EXISTS current_level_users;
DROP TEMPORARY TABLE IF EXISTS next_level_users;
END
测试结果,如下:
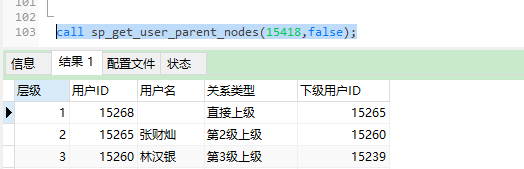
二、根据用户ID获取用户所有上级直属节点,用存储过程实现,如下:
CREATE PROCEDURE sp_get_user_parent_nodes(
IN base_user_id INT, -- 要查询的基础用户ID
IN include_self BOOLEAN -- 是否包含自己(1=包含,0=不包含)
)
BEGIN
-- 创建临时结果表(优化结构)
DROP TEMPORARY TABLE IF EXISTS user_parent_nodes;
CREATE TEMPORARY TABLE user_parent_nodes (
node_level INT NOT NULL COMMENT '节点层级(0=自己,1=直接上级...)',
user_id INT NOT NULL,
real_name VARCHAR(100),
parent_id INT,
is_root_node BOOLEAN DEFAULT FALSE,
PRIMARY KEY (user_id),
KEY idx_level (node_level)
) ENGINE=InnoDB;
-- 变量初始化
SET @current_user := base_user_id;
SET @current_level := 0;
SET @continue := 1;
-- 如果包含自己,先添加自己
IF include_self THEN
INSERT INTO user_parent_nodes
SELECT
0 AS node_level,
id AS user_id,
real_name,
spread_uid AS parent_id,
CASE WHEN spread_uid IS NULL THEN TRUE ELSE FALSE END AS is_root_node
FROM eb_user
WHERE id = base_user_id;
END IF;
-- 使用WHILE循环向上追溯
WHILE @continue = 1 DO
-- 获取当前用户的直接上级信息
INSERT INTO user_parent_nodes
SELECT
@current_level + 1 AS node_level,
parent.id AS user_id,
parent.real_name,
parent.spread_uid AS parent_id,
CASE WHEN parent.spread_uid IS NULL THEN TRUE ELSE FALSE END AS is_root_node
FROM eb_user current
JOIN eb_user parent ON current.spread_uid = parent.id
WHERE current.id = @current_user
ON DUPLICATE KEY UPDATE node_level = LEAST(node_level, @current_level + 1);
-- 检查是否插入成功
IF ROW_COUNT() = 0 THEN
-- 没有上级,标记当前用户为根节点(如果是第一次处理)
UPDATE user_parent_nodes
SET is_root_node = TRUE
WHERE user_id = @current_user AND is_root_node = FALSE;
SET @continue := 0;
ELSE
-- 获取新插入的上级ID
SELECT user_id INTO @current_user
FROM user_parent_nodes
WHERE node_level = @current_level + 1
LIMIT 1;
-- 检查是否已存在(防止循环引用)
IF @current_user IN (
SELECT user_id FROM user_parent_nodes
WHERE node_level < @current_level + 1
) THEN
SET @continue := 0;
END IF;
SET @current_level := @current_level + 1;
END IF;
END WHILE;
-- 返回最终结果(按层级排序)
SELECT
node_level AS '层级',
user_id AS '用户ID',
real_name AS '用户名',
CASE
WHEN node_level = 1 THEN '直接上级'
WHEN is_root_node THEN '顶级节点'
ELSE CONCAT('第', node_level, '级上级')
END AS '关系类型',
parent_id AS '下级用户ID'
FROM user_parent_nodes
WHERE node_level > 0 OR include_self = 1
ORDER BY node_level;
-- 清理临时表
DROP TEMPORARY TABLE IF EXISTS user_parent_nodes;
END
测试结果,如下: