DiT中的 Adaptive Layer Normalization (adaLN) 讲解
DiT
论文:Scalable Diffusion Models with Transformers (ICCV 2023, Oral)
DiT的论文细节可以读原论文,推荐知乎:扩散模型解读 (一):DiT 详细解读,那么在 transformer 替换 Unet中,有个核心的改动,就是 adaLN。
即以下的DiT Block with adaLN-Zero
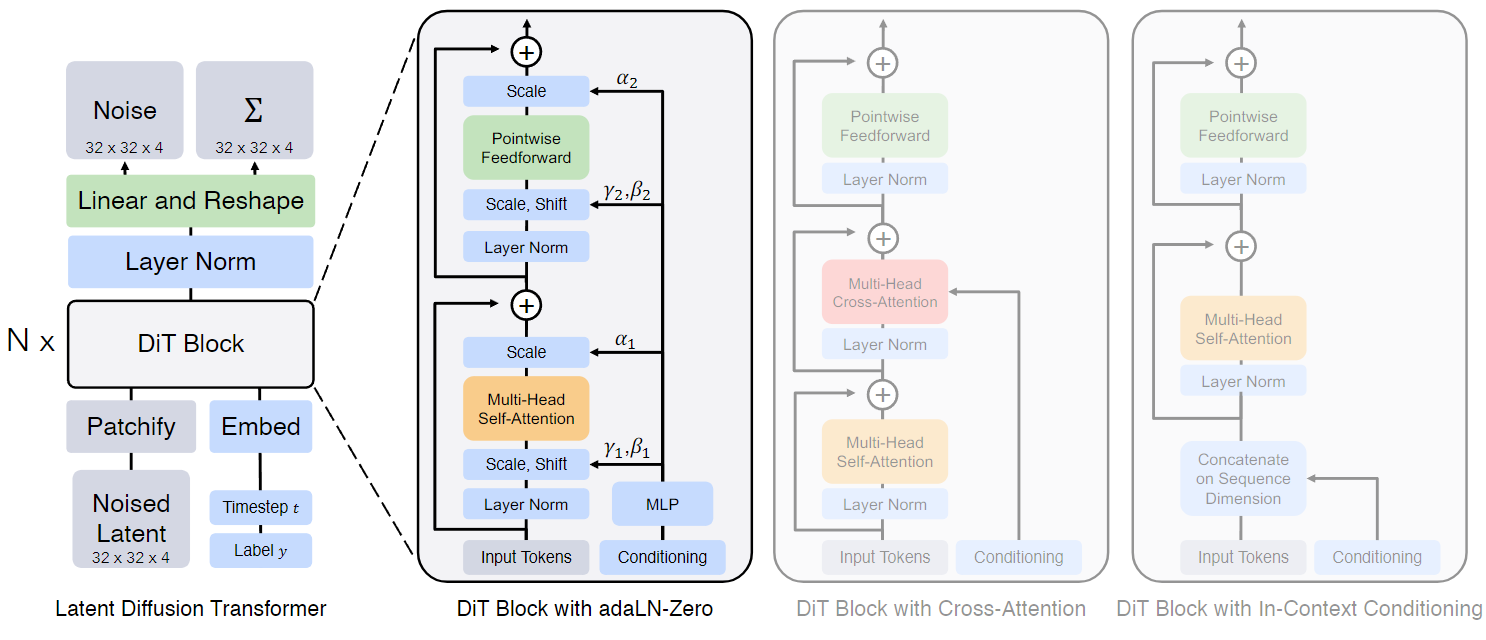
首先,Dit 基本沿用了 transformer 的一般结构,即 transformer 就是 input -> layer_norm -> multi-head-att -> layer_norm -> feedforward 结构,但是由于 DiT 是用于扩散模型,所以会涉及到 timestep 和 label 的输入,所以这块需要考虑如何把这两个信息进行融合到 transformer 里面来。
常见的几种信息融合的办法
简单总结一下几种常见的信息融合的办法:
- concat 或者 add:
fused = torch.cat([vector_a, vector_b], dim=1) - attention 加权或者 cross-att:一个序列作为Query,另一个作为Key/Value。
attention_weights = torch.softmax(torch.matmul(vector_a, vector_b.T), dim=-1)
fused = torch.matmul(attention_weights, vector_b)
- 门控(Gated Fusion)
gate * transformed + (1 - gate) * a
- 条件归一化(Conditional Normalization)
那么,DiT 这篇论文经过实验,验证了 adaLN 这种方式最好,具体 adaLN 是啥呢?我们来看一下
Layer Normalization 和 Adaptive Layer Normalization
参考自:https://zhuanlan.zhihu.com/p/698014972


More
值得注意的是,Dit 这个任务是根据分类lable重建图像,所以使用的 adaLN 机制,其实后续一些如果有 text context作为control信息时,为了效果更好可能还是要使用 cross-attention 的方式来提高效果。
更具体地,两者的差别可以大致总结如下:

