基于PPO的自动驾驶小车绕圈任务
1.任务介绍
任务来源: DQN: Deep Q Learning |自动驾驶入门(?) |算法与实现
任务原始代码: self-driving car
在上一篇使用了DDPG算法完成自动驾驶小车绕圈任务之后,继续学习了PPO算法,并将其用在该任务上。
最终效果:
PPO目前的调试效果用在此任务中,比不过DDPG算法,尤其是在转弯还是有些不流畅,后面还会继续调试。
2.调试记录
主要问题:遇到的第一个主要问题,就是小车始终拐弯拐不过去,学习不到正确的策略。
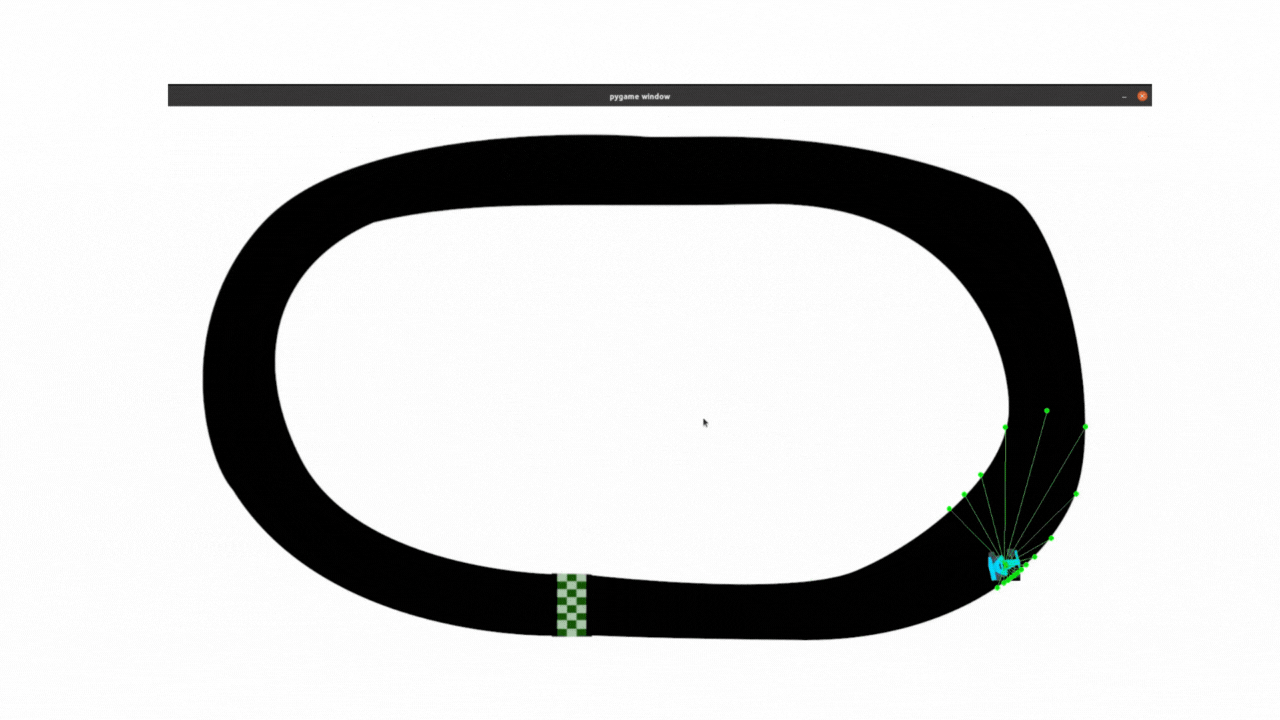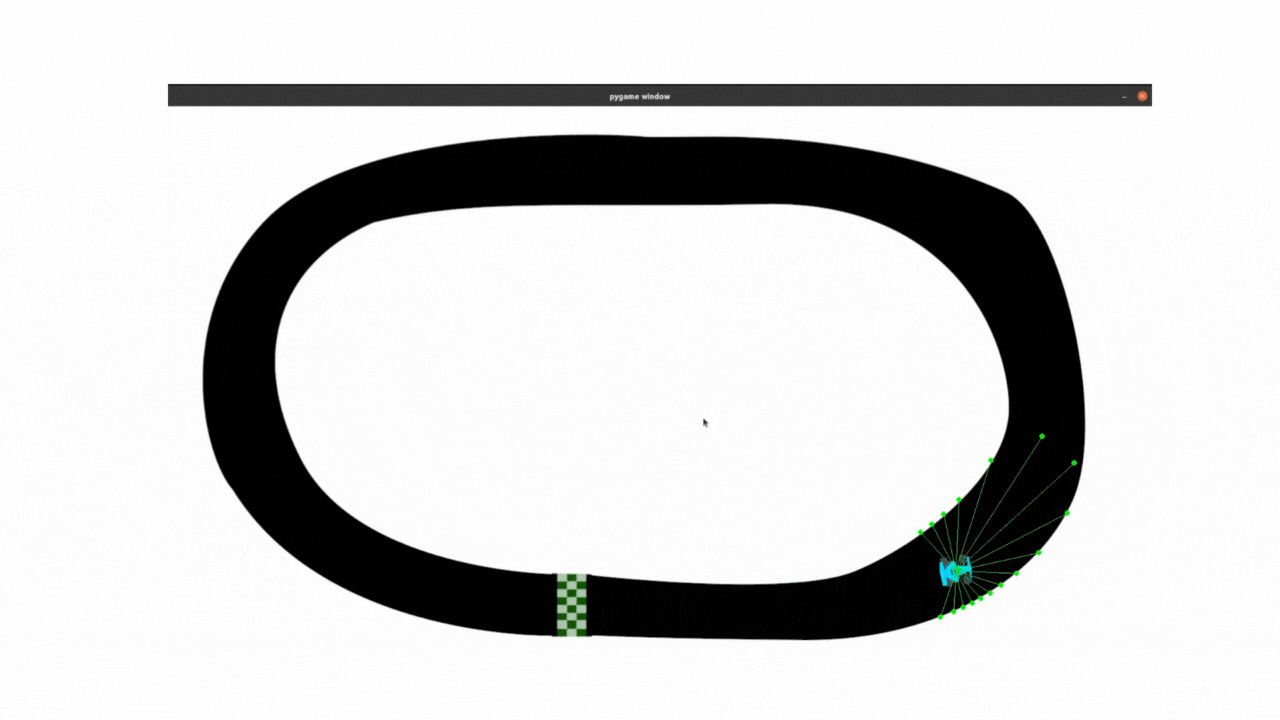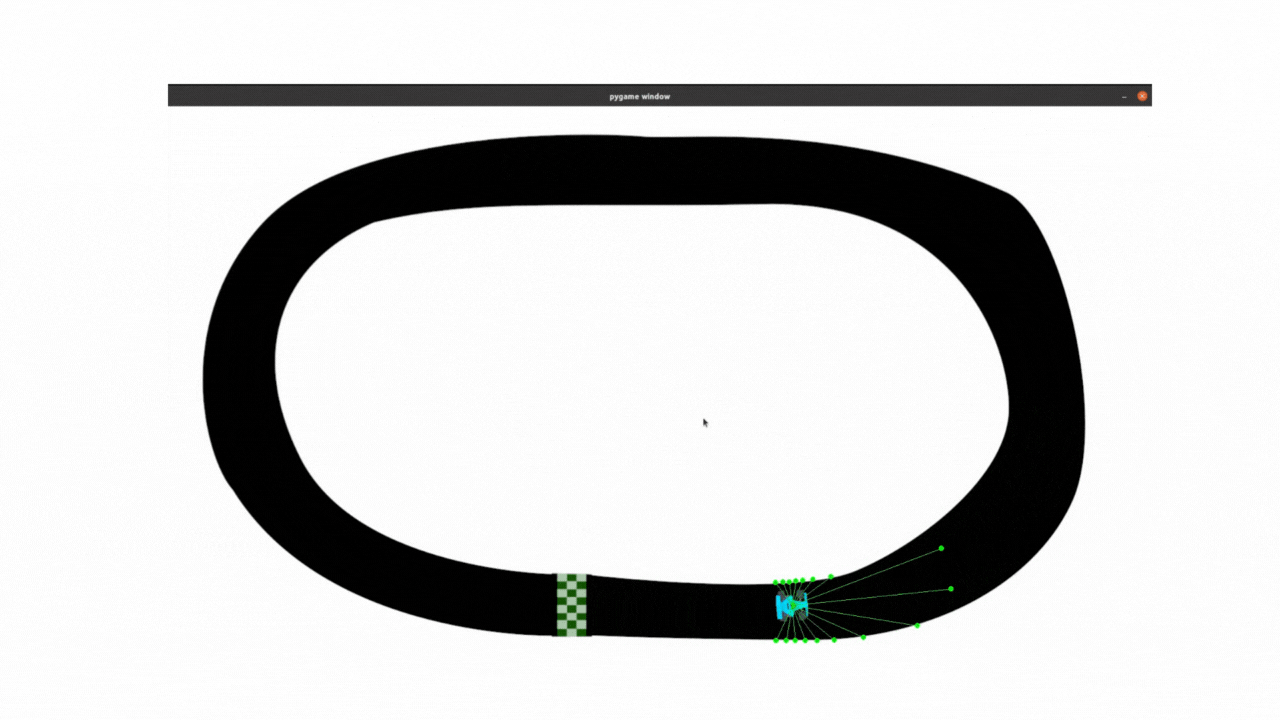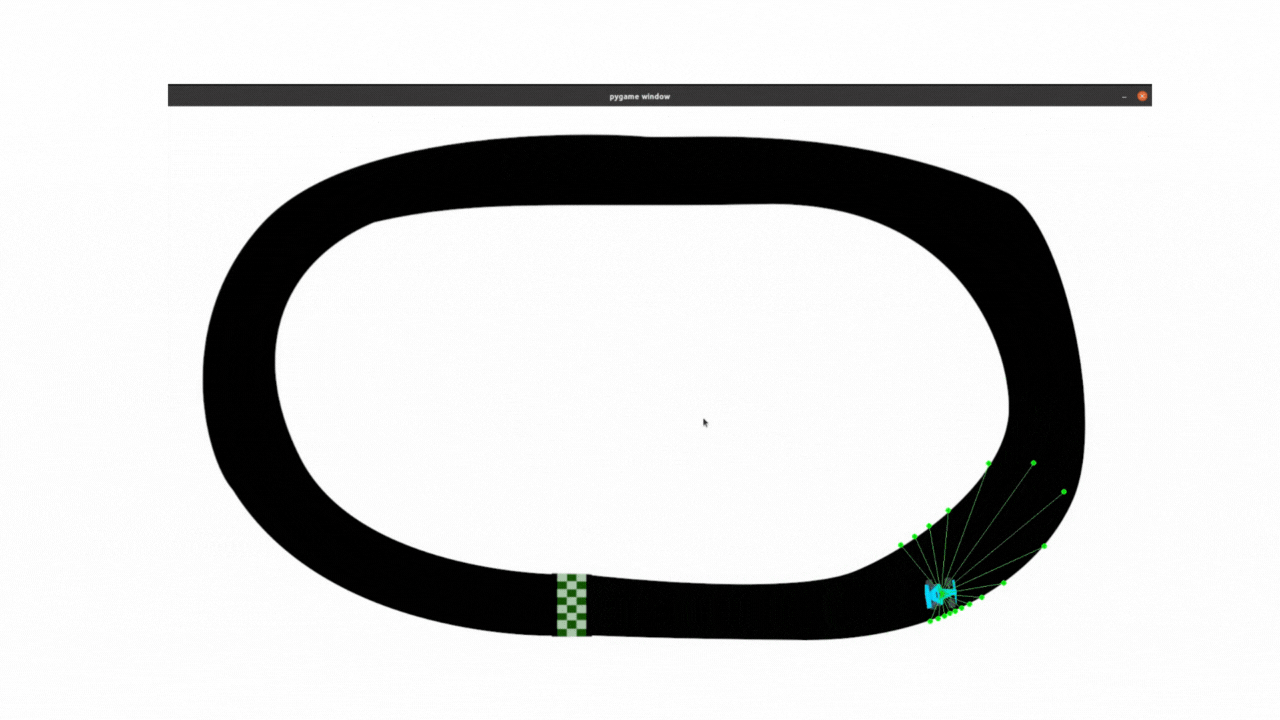
2.1 clip_epsilon和lr调整
记录:尝试调大和调小clip_epsilon以及学习率,发现都不能解决问题
2.2 调整critic_loss的权重
记录:尝试调大和调小critic_loss的权重,也不能解决问题
2.3 去掉advantages标准化
记录:通过打印actor_loss、critic_loss、total_loss,发现actor_loss的量级和critic_loss的量级压根不是一个量级的,由于actor_loss非常小,导致梯度下降极为缓慢,所以学习不到正确的策略。

然后通过排查发现,由于使用了advantages标准化策略,才导致的actor_loss变得极其小
整体来说小车是学习到了正确的策略的,跑了48小时是有的,但是有几个问题,一是小车在直道速度比较高,但是在过弯的时候会把车速下降到很低,几乎静止的状态,然后打方向,且训练很久之后依然还是这样;其他的看起来整体的avg_dists是在整体上升的,不过整体训练学习到正确的策略需要比较长的时间,基本上在episodes 250之后dist才越来越远的。
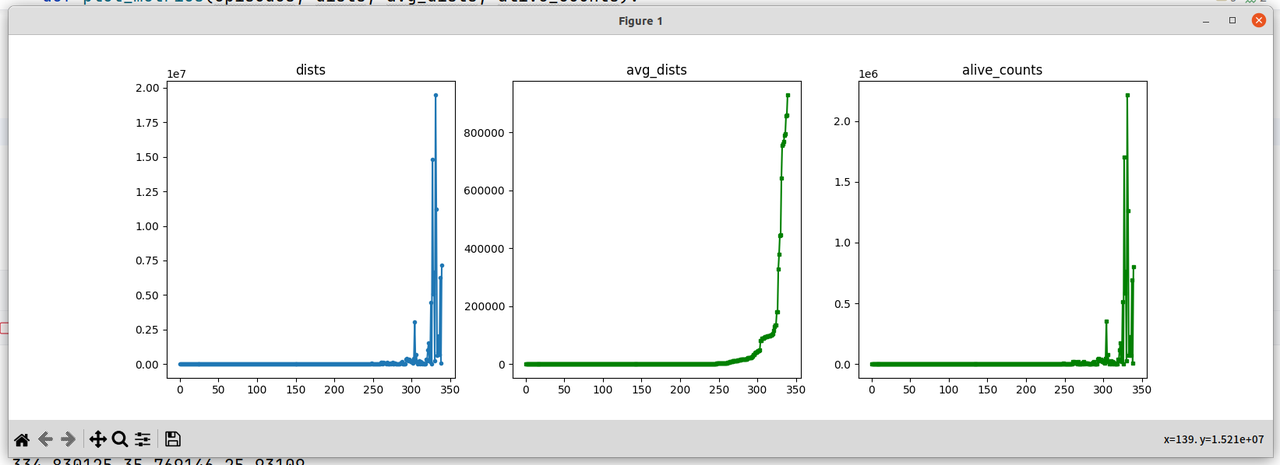
2.4 TrajectoryBuffer用完之后清空
torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 2.12 GiB. GPU 0 has a total capacity of 7.55 GiB of which 1.80 GiB is free. Including non-PyTorch memory, this process has 5.72 GiB memory in use. Of the allocated memory 5.03 GiB is allocated by PyTorch, and 585.83 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
记录:这是上面去掉advantages标准化训练到episodes 340的时候报的错,经过排查发现可能TrajectoryBuffer用完之后没有手动清空,导致内存泄漏
尝试代码:
class PPOAgent:def learn(self):...# 清空缓冲区self.buffer.clear()torch.cuda.empty_cache()def train():...# 清空临时Buffer并释放显存buffer.clear()del bufferagent.learn()...
现阶段主要问题:小车在直道速度比较高,但是在过弯的时候会把车速下降到很低,几乎静止的状态,然后打方向,连续性不太好。推断可能是后期探索不足导致的,所以后面主要围绕增加探索方向尝试。
2.5 actor网络结构改变
记录:尝试增加actor网络的层数以及神经元个数,发现都不能够解决问题;
2.6 增加熵正则化
记录:添加熵正则化的目的是鼓励探索,防止策略过早收敛;熵正则化项对应系数entropy_coef在经过一系列缩小放大的尝试之后,发现都没有效果;
尝试代码:
class PPOAgent:def learn(self):...mu, std = self.actor(batch_states.to('cpu'))dist = torch.distributions.Normal(mu, std)# entropy() 方法用于计算正态分布的熵。熵越大,表示分布的不确定性越高;熵越小,表示分布的不确定性越低。entropy = dist.entropy().mean()...entropy_loss = -self.entropy_coef * entropyactor_loss = actor_loss + entropy_loss......
2.7 actor采用动态标准差
记录:PPO算法代码最开始采用的是固定标准差方法,存在一些局限性,无法根据状态动态调整动作的探索强度(例如在直道加速、弯道减速时需不同标准差),所以小车在弯道部分探索不足,所以弯道会显得非常不连续;使用动态标准差之后弯道连续性有很大改善。
效果如下:能够看到使用动态标准差,增加探索率之后,小车整体过弯的流畅度是相较于之前有较大提升的,说明主要问题就是在标准差上,继续优化即可解决不流畅的问题
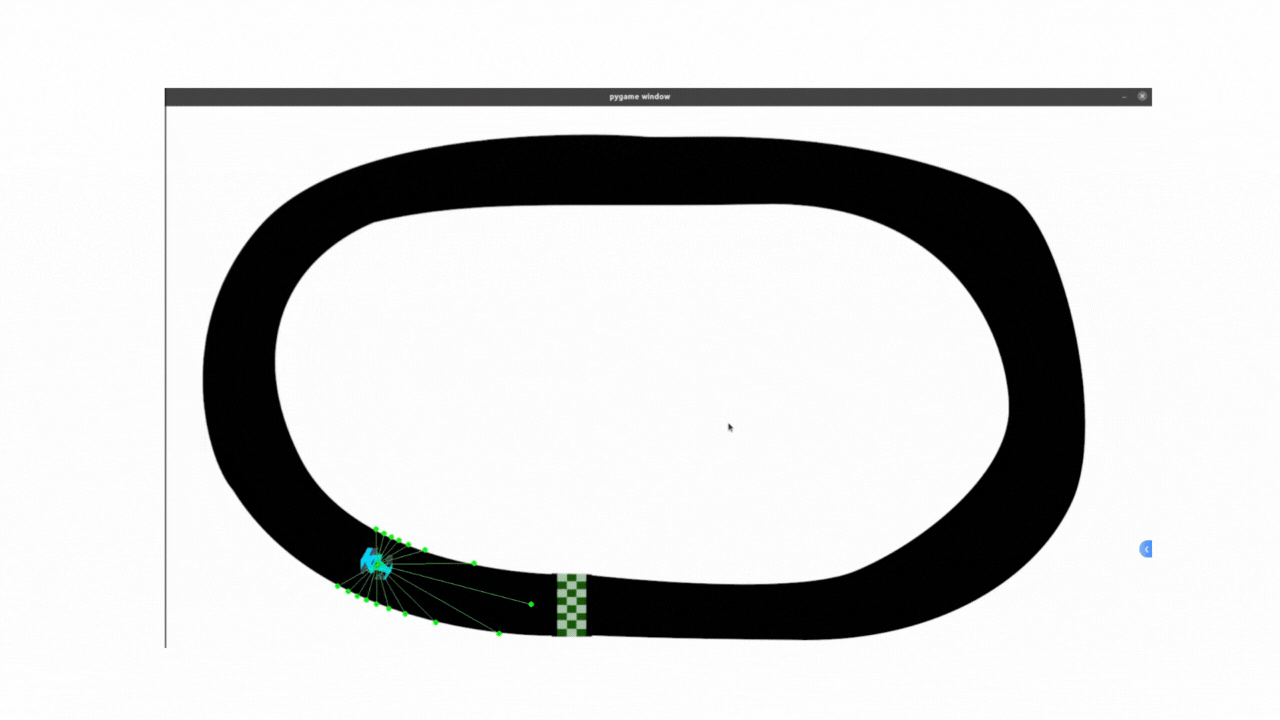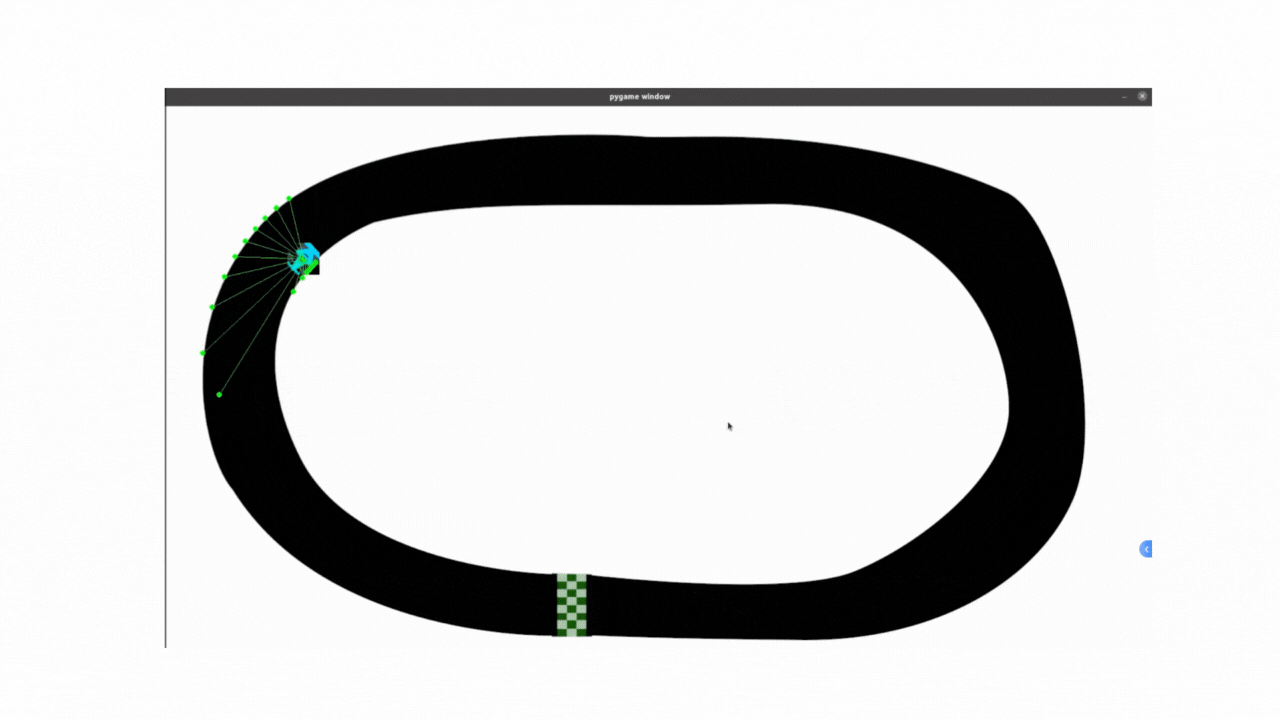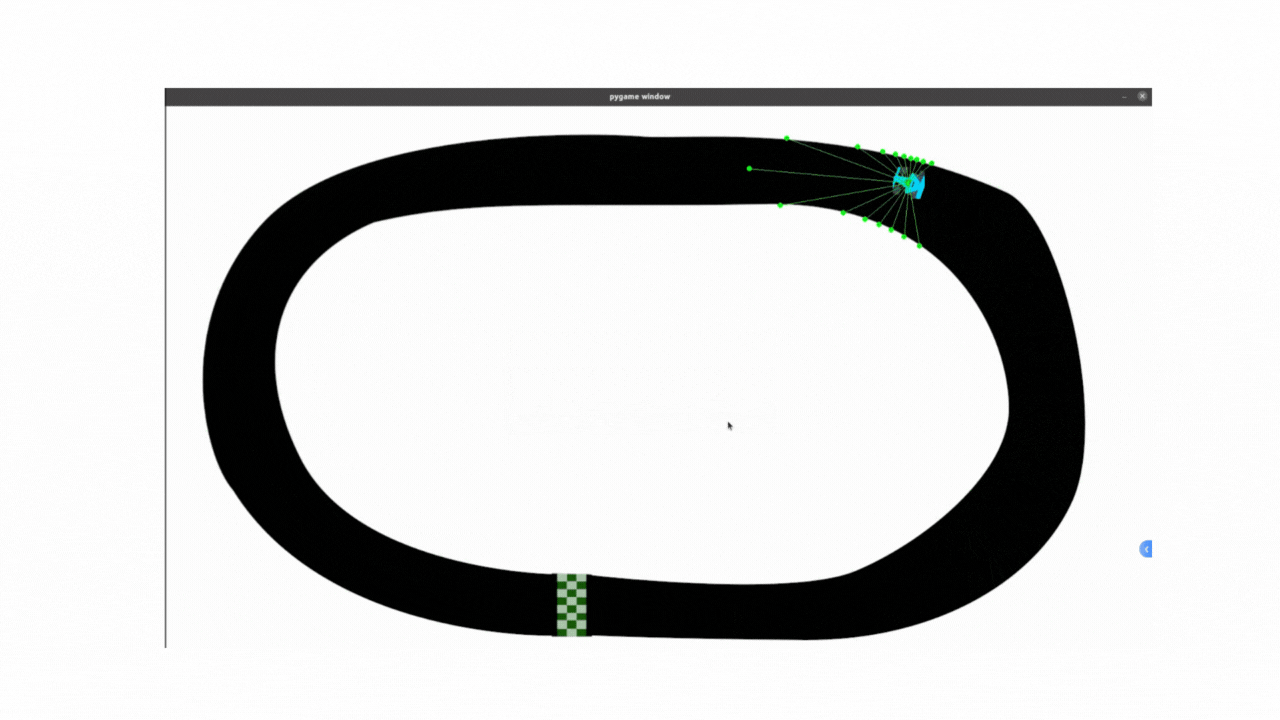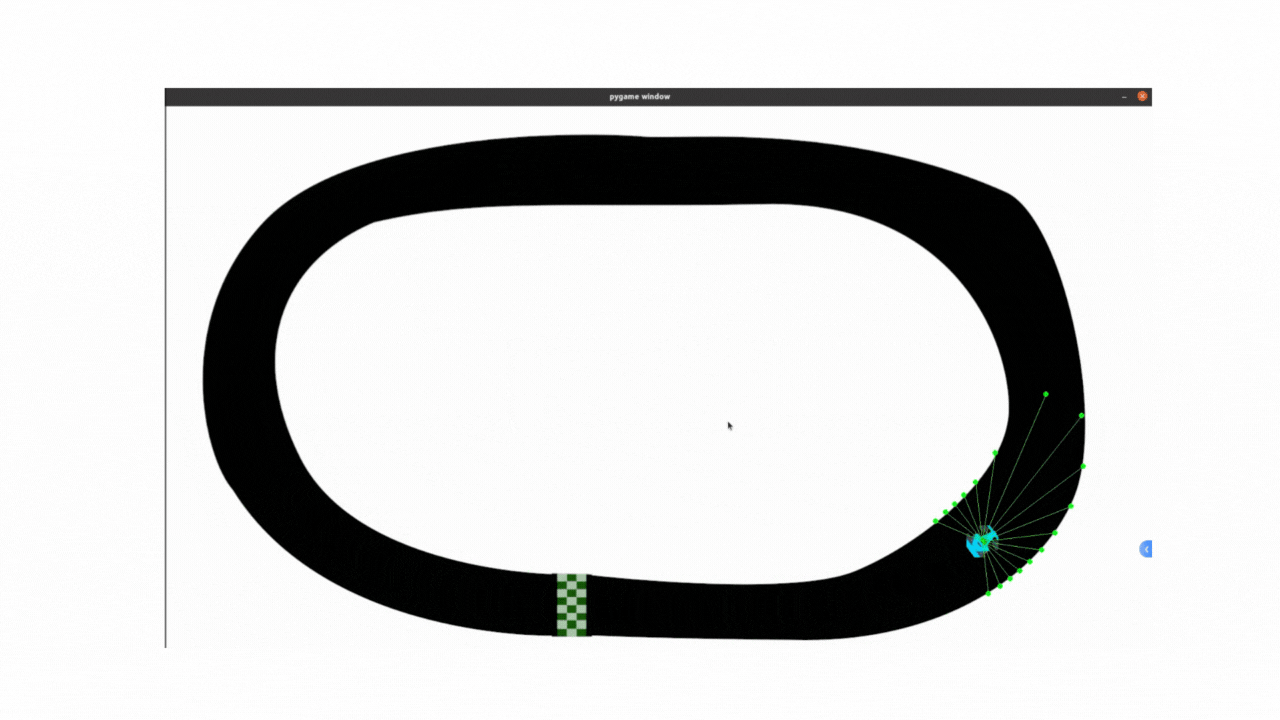
尝试代码:
class Actor(nn.Module):def __init__(self, input_dims, action_dim):...# 固定标准差# self.log_std = nn.Parameter(torch.zeros(action_dim)) # 对数标准差(可学习参数)# 动态标准差self.log_std = nn.Linear(256, action_dim) # 新增:动态生成log_std...def forward(self, state):...# 固定标准差# std = torch.exp(self.log_std) # 标准差# 动态标准差log_std = self.log_std(x) # 动态生成log_stdstd = torch.exp(log_std) # 保证标准差正数...
3.相比DDPG代码主要改进点
3.1 Actor网络更新
Actor网络主要是输出了两个值,一个均值一个标准差
class Actor(nn.Module):def __init__(self, input_dims, action_dim):super(Actor, self).__init__()self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")self.fc1 = nn.Linear(input_dims[0], 256)self.fc2 = nn.Linear(256, 256)self.mu = nn.Linear(256, action_dim) # 均值输出# 初始化最后一层权重为小值nn.init.orthogonal_(self.mu.weight, gain=0.01)nn.init.constant_(self.mu.bias, 0.0)# 固定标准差# self.log_std = nn.Parameter(torch.zeros(action_dim)) # 对数标准差(可学习参数)# 动态标准差self.log_std = nn.Linear(256, action_dim) # 新增:动态生成log_std# 初始化log_std层权重,限制初始标准差范围nn.init.orthogonal_(self.log_std.weight, gain=0.01)nn.init.constant_(self.log_std.bias, -1.0) # 初始log_std≈-1 → std≈0.36def forward(self, state):# print("state device: ", state.device)x = F.relu(self.fc1(state))x = F.relu(self.fc2(x))mu = torch.tanh(self.mu(x)) # 归一化到[-1,1]# 取exp是为了保证始终为正值,这个log_std是会随着反省传播自动学习更新的# 固定标准差# std = torch.exp(self.log_std) # 标准差# 动态标准差log_std = self.log_std(x) # 动态生成log_stdstd = torch.exp(log_std) # 保证标准差正数return mu, std
3.2 Critic网络变更
class Critic(nn.Module):def __init__(self, input_dims):super(Critic, self).__init__()self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")self.fc1 = nn.Linear(input_dims[0], 256).to(self.device)self.fc2 = nn.Linear(256, 256).to(self.device)self.v = nn.Linear(256, 1).to(self.device) # 状态价值输出def forward(self, state):x = F.relu(self.fc1(state))x = F.relu(self.fc2(x))return self.v(x)
3.3 ReplayBuffer替换为TrajectoryBuffer
class TrajectoryBuffer:def __init__(self):self.states = []self.actions = []self.log_probs = []self.rewards = []self.next_states = []self.dones = []def clear(self):self.states.clear()self.actions.clear()self.log_probs.clear()self.rewards.clear()self.next_states.clear()self.dones.clear()def store(self, state, action, log_prob, reward, next_state, done):self.states.append(state)self.actions.append(action)self.log_probs.append(log_prob)self.rewards.append(reward)self.next_states.append(next_state)self.dones.append(done)def get_all(self):return (torch.FloatTensor(np.array(self.states)),torch.FloatTensor(np.array(self.actions)),torch.FloatTensor(np.array(self.log_probs)),torch.FloatTensor(np.array(self.rewards)),torch.FloatTensor(np.array(self.next_states)),torch.FloatTensor(np.array(self.dones)))
3.4 DDPGAgent替换为PPOAgent
1.select_action由actor网络输出选择确定动作,变为actor网络输出概率分布,通过对概率分布选择随即动作;
class PPOAgent:def select_action(self, state):state = torch.FloatTensor(state).unsqueeze(0)mu, std = self.actor(state)# 创建一个均值为mu,标准差为std的高斯分布dist = torch.distributions.Normal(mu, std)action = dist.sample()# 为了在策略更新过程中使用,logπ_θ(a∣s)log_prob = dist.log_prob(action).sum(dim=1)return action.squeeze(0).detach().numpy(), log_prob.detach()
2.添加优势函数计算;
class PPOAgent:def compute_gae(self, rewards, values, dones, next_value):values = values.detach() # 分离梯度# 计算GAE优势估计advantages = []gae = 0next_value = next_value.detach().to(self.device)for t in reversed(range(len(rewards))):delta = rewards[t] + self.gamma * next_value * (1 - dones[t]) - values[t].item()gae = delta + self.gamma * self.gae_lambda * (1 - dones[t]) * gaeadvantages.insert(0, gae)next_value = values[t]advantages = torch.stack(advantages).to(self.device)return advantages.clone().detach().float()
3.learn函数实现;
class PPOAgent:def learn(self):# 从缓冲区获取所有轨迹数据states, actions, old_log_probs, rewards, next_states, dones = self.buffer.get_all()# 移至设备(GPU/CPU)states = states.to(self.device)actions = actions.to(self.device)old_log_probs = old_log_probs.to(self.device)rewards = rewards.to(self.device)next_states = next_states.to(self.device)dones = dones.to(self.device)# 计算优势估计(GAE)with torch.no_grad():values = self.critic(states).squeeze()next_value = self.critic(next_states[-1]).detach()advantages = self.compute_gae(rewards, values, dones, next_value)# 标准化优势,准化优势函数更多是工程上的实践,用于提高训练的稳定性,而非算法理论推导的必要步骤# advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-8)# 多轮优化for _ in range(self.epochs):# 随机打乱数据索引indices = torch.randperm(len(states))# 分批次训练for start in range(0, len(indices), self.batch_size):end = start + self.batch_sizebatch_idx = indices[start:end]# 提取批次数据batch_states = states[batch_idx]batch_actions = actions[batch_idx]batch_old_log_probs = old_log_probs[batch_idx]batch_advantages = advantages[batch_idx]# 计算新策略的对数概率mu, std = self.actor(batch_states.to('cpu'))dist = torch.distributions.Normal(mu, std)new_log_probs = dist.log_prob(batch_actions.to('cpu')).sum(dim=1)# 计算策略损失(剪切)ratio = torch.exp(new_log_probs.to(self.device) - batch_old_log_probs)surr1 = ratio * batch_advantagessurr2 = torch.clamp(ratio, 1 - self.clip_epsilon, 1 + self.clip_epsilon) * batch_advantagesactor_loss = -torch.min(surr1, surr2).mean()# 计算Critic损失curr_values = self.critic(batch_states).squeeze() # x *targets = batch_advantages.squeeze() + values[batch_idx].detach()critic_loss = F.mse_loss(curr_values, targets)# 总损失entropy = dist.entropy().mean()total_loss = actor_loss + 0.5 * critic_loss - self.entropy_coef * entropy # 调整熵系数# 反向传播与优化self.optimizer.zero_grad()total_loss.backward()torch.nn.utils.clip_grad_norm_(self.actor.parameters(), 0.5)torch.nn.utils.clip_grad_norm_(self.critic.parameters(), 0.5)self.optimizer.step()# 清空缓冲区self.buffer.clear()torch.cuda.empty_cache()
4.任务思考
1.select_action函数中log_prob = dist.log_prob(action).sum(dim=1),为什么要对多维情况进行求和?求和之后不会影响计算的准确性么?这为什么是可行的??
合理的,并且不会影响计算的准确性,原因如下:
2.在actor的forward中对 std 取指数操作不是会改变std实际的值么?它后续又被用在构建高斯分布上,如果值改变了,那其实它不就影响了高斯分布在sample时候的值,进而影响action的输出,这为什么是可行的?
- 探索与利用的平衡:通过调整std的值,可以在探索(exploration)和利用(exploitation)之间找到平衡。较大的std鼓励算法探索更多的动作空间,而较小的std则让算法更倾向于选择高奖励的动作。
- 自适应调整:std作为一个可学习参数,会在训练过程中通过梯度下降自动调整。算法会根据环境的反馈,学习到合适的std值,以平衡探索和利用。
- 指数函数的单调性:指数函数是单调递增的,因此 log_std 的变化可以直接反映在 std 上。这意味着优化过程可以有效地调整std的值,而不会出现非法值。
3.PPO算法中使用KL散度惩罚和使用clip截断两种方式各有什么优劣?
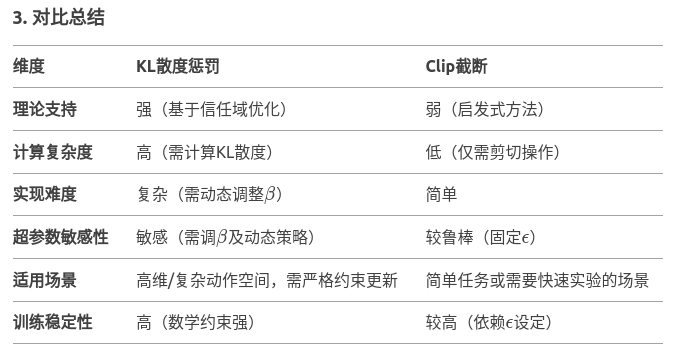
4.PPO算法在计算loss的时候,为什么使用使用total_loss = actor_loss + 0.5 * critic_loss?这个做法相对于分开对loss进行反响传播有什么优势?还有就是相加的时候为什么还对critic_loss取了0.5的权重?
总损失合并的优势:
(1) 统一优化过程
- 同步更新:Actor和Critic的参数在一次反向传播中同时更新,确保两者的优化步骤一致。若分开反向传播,可能出现梯度更新顺序或步长不一致的问题,导致训练不稳定。
- 计算效率:合并损失后,仅需一次前向传播和一次反向传播,减少计算开销。分开更新则需要两次独立的前向-反向过程,增加资源消耗。
(2) 梯度平衡
- 协同优化:Actor依赖Critic提供的价值估计(如优势函数),Critic依赖Actor生成的经验数据。合并损失可确保两者的参数更新协同进行,避免因单独更新导致的目标不一致。
对 critic_loss 赋予0.5权重的意义:
(1) 平衡损失量级
- 问题:Critic的损失(如价值函数误差)通常远大于Actor的损失(如策略梯度损失)。若不调整权重,Critic_loss可能主导总损失,导致Actor无法有效学习。
- 解决:通过乘以0.5(或其他系数),降低Critic_loss的权重,使两者的梯度贡献趋于平衡。
(2) 经验性调参
- 实验验证:在PPO的原始论文和后续实践中,发现0.5的权重能在多数任务中平衡Actor和Critic的学习速度。例如,OpenAI的官方实现和Stable Baselines库均采用类似设计。
- 任务适应性:对于某些任务,可能需要调整该系数(如0.2或0.8),但0.5是一个鲁棒的默认值。
(3) 正则化效果
- 防止过拟合:Critic_loss的权重降低可视为一种正则化手段,避免Critic网络过度拟合当前经验,提升泛化能力。
分开反向传播的潜在问题:
(1) 梯度冲突
- 不一致的优化方向:若Actor和Critic分开更新,两者的梯度方向可能冲突,导致参数震荡或收敛缓慢。
- 优化器状态干扰:自适应优化器(如Adam)的内部状态(如动量、二阶矩估计)会因多次反向传播而混乱。
(2) 实现复杂度
- 代码冗余:分开更新需分别调用 loss.backward() 和 optimizer.step(),增加代码复杂性和维护成本。
5.Actor和Critic的loss采用相加的方法,如何分别对Actor和Critic进行反向传播?也就是说,虽然Loss是相加的,但在反向传播时,是否能够独立更新各自的网络参数?另外,梯度更新的幅度是否基于总Loss,还是各自Loss?
(1) 计算梯度
- 总Loss的反向传播:调用 total_loss.backward(),PyTorch会自动计算总Loss对所有参与计算图的参数的梯度。
- 梯度分离:
- Actor参数的梯度仅来自 actor_loss。
- Critic参数的梯度仅来自 0.5 * critic_loss。
(2) 参数更新
- 优化器(如Adam)根据各参数的梯度独立更新:
- Actor的参数基于 actor_loss 的梯度更新。
- Critic的参数基于 0.5 * critic_loss 的梯度更新。
(3) 更新幅度由各自的Loss和权重决定
- Actor的更新幅度:完全由 actor_loss 的梯度决定,与 critic_loss 无关。
- Critic的更新幅度:由 0.5 * critic_loss 的梯度决定,相当于对Critic的梯度进行了缩放。
为什么可以分开更新?
(1) 参数独立性
- Actor和Critic通常是两个独立的网络,没有共享参数,因此它们的梯度在计算图中是天然分离的。
- PyTorch会自动追踪每个参数的梯度来源,确保梯度仅来自对应的Loss项。
(2) 计算图的隐式分离
即使Loss被合并,计算图中的梯度路径是独立的:
Actor的参数 → 仅通过 actor_loss 贡献梯度。
Critic的参数 → 仅通过 critic_loss 贡献梯度。
6.PPO算法中,什么情况下要对优势函数做标准化?什么情况下不需要?
一般来说,标准化是一个常用的技巧,但并不是绝对必须的。很多PPO的实现默认会进行标准化,因为它通常能带来更稳定的训练效果,尤其是在复杂或高方差的环境中。
需要标准化的场景:
- 高方差优势估计
- 问题特征:当使用多步优势估计(如GAE)或环境奖励稀疏时,优势值可能在不同时间步或不同轨迹间差异极大。
- 示例:
- 在Atari游戏中,某些关键动作(如躲避子弹)可能产生极高的优势值,而普通动作优势值较低。
- 稀疏奖励任务中,仅有少数时间步的优势值显著非零。
- 解决方案:标准化使所有优势值处于同一量级,防止策略被少数高优势样本主导。
- 多智能体或复杂动态环境
- 问题特征:多个智能体交互或环境动态复杂时,不同策略的交互可能导致优势值分布不稳定。
- 示例:在《星际争霸》多单位协同作战中,不同单位的动作优势值可能因战场局势剧烈波动。
- 解决方案:标准化平衡不同策略分支的更新幅度。
- 混合离散-连续动作空间
- 问题特征:当动作空间包含离散和连续动作时,不同动作类型的优势值范围可能差异显著。
- 示例:自动驾驶中,离散动作(换道)和连续动作(转向角度)的优势值量级不同。
- 解决方案:标准化统一不同动作类型的优势尺度。
不需要标准化的场景:
- 奖励函数经过严格归一化
场景特征:若环境的奖励函数在设计时已归一化到固定范围(如 r \in [-1, 1]r∈[−1,1]),优势值自然处于可控范围。
示例:标准化后的MuJoCo控制任务(如Ant-v3),奖励函数已缩放。 - 使用自适应优化器
场景特征:当优化器(如Adam)具备自适应学习率调整能力时,可部分抵消优势值的尺度差异。
示例:在简单连续控制任务(如Pendulum-v1)中,Adam优化器配合PPO默认参数通常无需标准化。 - 策略熵正则化较强
场景特征:若策略熵正则化系数(entropy_coeff)较大,策略的探索性增强,优势值差异的影响被削弱。
示例:在探索优先的任务(如Montezuma’s Revenge)中,高熵策略可替代标准化效果。
7.PPO算法的actor网络使用固定标准差和通过神经网络层动态生成标准差,两种方式各有什么优劣?



5.完整代码
调试过程中的一些代码保留着,以提些许思考
import pygame
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import mathWIDTH = 1920
HEIGHT = 1080
CAR_SIZE_X = 60
CAR_SIZE_Y = 60
BORDER_COLOR = (255, 255, 255, 255) # Color To Crash on Hit
current_generation = 0 # Generation counterclass Actor(nn.Module):def __init__(self, input_dims, action_dim):super(Actor, self).__init__()self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")self.fc1 = nn.Linear(input_dims[0], 256)self.fc2 = nn.Linear(256, 256)self.mu = nn.Linear(256, action_dim) # 均值输出# 初始化最后一层权重为小值nn.init.orthogonal_(self.mu.weight, gain=0.01)nn.init.constant_(self.mu.bias, 0.0)# 固定标准差# self.log_std = nn.Parameter(torch.zeros(action_dim)) # 对数标准差(可学习参数)# 动态标准差self.log_std = nn.Linear(256, action_dim) # 新增:动态生成log_std# 初始化log_std层权重,限制初始标准差范围nn.init.orthogonal_(self.log_std.weight, gain=0.01)nn.init.constant_(self.log_std.bias, -1.0) # 初始log_std≈-1 → std≈0.36def forward(self, state):# print("state device: ", state.device)x = F.relu(self.fc1(state))x = F.relu(self.fc2(x))mu = torch.tanh(self.mu(x)) # 归一化到[-1,1]# 取exp是为了保证始终为正值,这个log_std是会随着反省传播自动学习更新的# 固定标准差# std = torch.exp(self.log_std) # 标准差# 动态标准差log_std = self.log_std(x) # 动态生成log_std# log_std = torch.clamp(self.log_std(x), min=-5, max=5) # std ∈ [e^-5≈0.0067, e^2≈7.4]std = torch.exp(log_std) # 保证标准差正数return mu, stdclass Critic(nn.Module):def __init__(self, input_dims):super(Critic, self).__init__()self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")self.fc1 = nn.Linear(input_dims[0], 256).to(self.device)self.fc2 = nn.Linear(256, 256).to(self.device)self.v = nn.Linear(256, 1).to(self.device) # 状态价值输出def forward(self, state):x = F.relu(self.fc1(state))x = F.relu(self.fc2(x))return self.v(x)class TrajectoryBuffer:def __init__(self):self.states = []self.actions = []self.log_probs = []self.rewards = []self.next_states = []self.dones = []def clear(self):self.states.clear()self.actions.clear()self.log_probs.clear()self.rewards.clear()self.next_states.clear()self.dones.clear()def store(self, state, action, log_prob, reward, next_state, done):self.states.append(state)self.actions.append(action)self.log_probs.append(log_prob)self.rewards.append(reward)self.next_states.append(next_state)self.dones.append(done)def get_all(self):return (torch.FloatTensor(np.array(self.states)),torch.FloatTensor(np.array(self.actions)),torch.FloatTensor(np.array(self.log_probs)),torch.FloatTensor(np.array(self.rewards)),torch.FloatTensor(np.array(self.next_states)),torch.FloatTensor(np.array(self.dones)))class PPOAgent:def __init__(self, input_dims, action_dim, lr=3e-4, gamma=0.99,clip_epsilon=0.2, gae_lambda=0.95, epochs=4, batch_size=64):self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")self.actor = Actor(input_dims, action_dim)self.critic = Critic(input_dims)self.optimizer = optim.Adam([{'params': self.actor.parameters()},{'params': self.critic.parameters()}], lr=lr)self.gamma = gammaself.clip_epsilon = clip_epsilonself.gae_lambda = gae_lambdaself.epochs = epochsself.batch_size = batch_sizeself.buffer = TrajectoryBuffer()self.action_memory_for_end = []self.control_memory_for_end = []self.mem_cntr = 0self.actor_loss_value = []self.entropy_coef = 0.01def select_action(self, state):state = torch.FloatTensor(state).unsqueeze(0)mu, std = self.actor(state)# 创建一个均值为mu,标准差为std的高斯分布dist = torch.distributions.Normal(mu, std)action = dist.sample()# 为了在策略更新过程中使用,logπ_θ(a∣s)log_prob = dist.log_prob(action).sum(dim=1)return action.squeeze(0).detach().numpy(), log_prob.detach()def compute_gae(self, rewards, values, dones, next_value):values = values.detach() # 分离梯度# 计算GAE优势估计advantages = []gae = 0# next_value = next_value.detach().numpy()next_value = next_value.detach().to(self.device)for t in reversed(range(len(rewards))):delta = rewards[t] + self.gamma * next_value * (1 - dones[t]) - values[t].item()gae = delta + self.gamma * self.gae_lambda * (1 - dones[t]) * gaeadvantages.insert(0, gae)next_value = values[t]advantages = torch.stack(advantages).to(self.device)return advantages.clone().detach().float()def learn(self):# 从缓冲区获取所有轨迹数据states, actions, old_log_probs, rewards, next_states, dones = self.buffer.get_all()# 移至设备(GPU/CPU)states = states.to(self.device)actions = actions.to(self.device)old_log_probs = old_log_probs.to(self.device)rewards = rewards.to(self.device)next_states = next_states.to(self.device)dones = dones.to(self.device)# 计算优势估计(GAE)with torch.no_grad():# print("states: ", states.shape)values = self.critic(states).squeeze()next_value = self.critic(next_states[-1]).detach()advantages = self.compute_gae(rewards, values, dones, next_value)# 标准化优势,准化优势函数更多是工程上的实践,用于提高训练的稳定性,而非算法理论推导的必要步骤# advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-8)# 多轮优化for _ in range(self.epochs):# 随机打乱数据索引indices = torch.randperm(len(states))# 分批次训练for start in range(0, len(indices), self.batch_size):end = start + self.batch_sizebatch_idx = indices[start:end]# 提取批次数据batch_states = states[batch_idx]batch_actions = actions[batch_idx]batch_old_log_probs = old_log_probs[batch_idx]batch_advantages = advantages[batch_idx]# 计算新策略的对数概率mu, std = self.actor(batch_states.to('cpu'))dist = torch.distributions.Normal(mu, std)new_log_probs = dist.log_prob(batch_actions.to('cpu')).sum(dim=1)# 计算策略损失(剪切)ratio = torch.exp(new_log_probs.to(self.device) - batch_old_log_probs)surr1 = ratio * batch_advantagessurr2 = torch.clamp(ratio, 1 - self.clip_epsilon, 1 + self.clip_epsilon) * batch_advantagesactor_loss = -torch.min(surr1, surr2).mean()# 计算Critic损失curr_values = self.critic(batch_states).squeeze() # x *targets = batch_advantages.squeeze() + values[batch_idx].detach()critic_loss = F.mse_loss(curr_values, targets)# 总损失entropy = dist.entropy().mean()total_loss = actor_loss + 0.5 * critic_loss - self.entropy_coef * entropy # 调整熵系数# 反向传播与优化self.optimizer.zero_grad()total_loss.backward()torch.nn.utils.clip_grad_norm_(self.actor.parameters(), 0.5)torch.nn.utils.clip_grad_norm_(self.critic.parameters(), 0.5)self.optimizer.step()# 清空缓冲区self.buffer.clear()torch.cuda.empty_cache()class Car:def __init__(self, boundary_x, boundary_y, num_radar):# Load Car Sprite and Rotateself.sprite = pygame.image.load('car.png').convert() # Convert Speeds Up A Lotself.sprite = pygame.transform.scale(self.sprite, (CAR_SIZE_X, CAR_SIZE_Y))self.rotated_sprite = self.sprite# self.position = [690, 740] # Starting Positionself.position = [830, 920] # Starting Positionself.angle = 0self.angle_memory = []self.speed = 0self.speed_memory = []self.speed_set = False # Flag For Default Speed Later onself.center = [self.position[0] + CAR_SIZE_X / 2, self.position[1] + CAR_SIZE_Y / 2] # Calculate Centerself.radars = [[(0, 0), 60]] * num_radar # List For Sensors / Radarsself.drawing_radars = [] # Radars To Be Drawnself.current_lateral_min_dist = 60self.alive = True # Boolean To Check If Car is Crashedself.distance = 0 # Distance Drivenself.time = 0 # Time Passedself.width = 0self.height = 0self.boundary_x = boundary_xself.boundary_y = boundary_ydef draw(self, screen):screen.blit(self.rotated_sprite, self.position) # Draw Spriteself.draw_radar(screen) # OPTIONAL FOR SENSORSdef draw_radar(self, screen):# Optionally Draw All Sensors / Radarsfor radar in self.radars:position = radar[0]pygame.draw.line(screen, (0, 255, 0), self.center, position, 1)pygame.draw.circle(screen, (0, 255, 0), position, 5)def check_collision(self, game_map):self.alive = Truefor point in self.corners:# If Any Corner Touches Border Color -> Crash# Assumes Rectangleif game_map.get_at((int(point[0]), int(point[1]))) == BORDER_COLOR:self.alive = Falsebreakdef check_radar(self, degree, game_map):length = 0x = int(self.center[0] + math.cos(math.radians(360 - (self.angle + degree))) * length)y = int(self.center[1] + math.sin(math.radians(360 - (self.angle + degree))) * length)# While We Don't Hit BORDER_COLOR AND length < 300 (just a max) -> go further and furtherwhile not game_map.get_at((x, y)) == BORDER_COLOR and length < 300:length = length + 1x = int(self.center[0] + math.cos(math.radians(360 - (self.angle + degree))) * length)y = int(self.center[1] + math.sin(math.radians(360 - (self.angle + degree))) * length)# Calculate Distance To Border And Append To Radars List TODO: update dist calculatedist = int(math.sqrt(math.pow(x - self.center[0], 2) + math.pow(y - self.center[1], 2)))self.radars.append([(x, y), dist])def update(self, game_map):# Set The Speed To 20 For The First Time# Only When Having 4 Output Nodes With Speed Up and Downif not self.speed_set:self.speed = 10self.speed_set = Trueself.width, self.height = game_map.get_size()# Get Rotated Sprite And Move Into The Right X-Direction# Don't Let The Car Go Closer Than 20px To The Edgeself.rotated_sprite = self.rotate_center(self.sprite, self.angle)self.position[0] += math.cos(math.radians(360 - self.angle)) * self.speedself.position[0] = max(self.position[0], 20)self.position[0] = min(self.position[0], WIDTH - 120)# Increase Distance and Timeself.distance += self.speedself.time += 1# Same For Y-Positionself.position[1] += math.sin(math.radians(360 - self.angle)) * self.speedself.position[1] = max(self.position[1], 20)self.position[1] = min(self.position[1], WIDTH - 120)# Calculate New Centerself.center = [int(self.position[0]) + CAR_SIZE_X / 2, int(self.position[1]) + CAR_SIZE_Y / 2]# print("center: {}".format(self.center))# Calculate Four Corners# Length Is Half The Sidelength = 0.5 * CAR_SIZE_Xleft_top = [self.center[0] + math.cos(math.radians(360 - (self.angle + 30))) * length,self.center[1] + math.sin(math.radians(360 - (self.angle + 30))) * length]right_top = [self.center[0] + math.cos(math.radians(360 - (self.angle + 150))) * length,self.center[1] + math.sin(math.radians(360 - (self.angle + 150))) * length]left_bottom = [self.center[0] + math.cos(math.radians(360 - (self.angle + 210))) * length,self.center[1] + math.sin(math.radians(360 - (self.angle + 210))) * length]right_bottom = [self.center[0] + math.cos(math.radians(360 - (self.angle + 330))) * length,self.center[1] + math.sin(math.radians(360 - (self.angle + 330))) * length]self.corners = [left_top, right_top, left_bottom, right_bottom]# Check Collisions And Clear Radarsself.check_collision(game_map)self.radars.clear()# From -90 To 120 With Step-Size 45 Check Radarfor d in range(-120, 126, 15): # -90,-45,0,45,90zself.check_radar(d, game_map)def get_data(self):# Get Distances To Borderreturn_values = [0] * len(self.radars)self.current_lateral_min_dist = 60for i, radar in enumerate(self.radars):return_values[i] = radar[1] / 300.0if radar[1] < self.current_lateral_min_dist:self.current_lateral_min_dist = radar[1]angle_rad = np.deg2rad(self.angle)return_values = return_values + [self.current_lateral_min_dist / 30,np.clip(self.speed / 20.0, 0.0, 1.0),np.sin(angle_rad), np.cos(angle_rad)]return return_valuesdef is_alive(self):# Basic Alive Functionreturn self.alivedef get_reward_optimized333(self, action, done):# 居中性奖励lateral_reward = max((self.current_lateral_min_dist / 60 - 0.4) * 2, 0.0)# action输出转角奖励steer_reward = 0.0if abs(action[0].item()) >= 2.5:steer_reward = -0.2 * abs(action[0].item()) + 0.5# 速度奖励speed_reward = 0.0if self.speed < 12.0:speed_reward = 0.05 * self.speed - 0.6elif self.speed >= 16.0:speed_reward = -0.15 * self.speed + 2.4# 速度基础speed_base_reward = self.speed / 15.0# 转角连续性angle_discount = 1.0if len(self.angle_memory) >= 5:self.angle_memory = self.angle_memory[1:]self.angle_memory.append(action[0].item())aaa = [0] * 4if len(self.angle_memory) >= 5:for i in range(1, 5):aaa[i - 1] = self.angle_memory[i] - self.angle_memory[i - 1]bbb = [0] * 3for j in range(1, 4):bbb[j - 1] = 1 if aaa[j - 1] * aaa[j] < 0 else 0if sum(bbb) >= 3 and lateral_reward > 0.0:angle_discount = 0.8total_reward = lateral_reward * angle_discount * speed_base_reward + speed_reward + steer_reward# print("total_reward: ", total_reward)total_reward = max(-1.0, min(total_reward, 1.0))# return total_rewardreturn total_reward if ~done else -1.0def rotate_center(self, image, angle):# Rotate The Rectanglerectangle = image.get_rect()rotated_image = pygame.transform.rotate(image, angle)rotated_rectangle = rectangle.copy()rotated_rectangle.center = rotated_image.get_rect().centerrotated_image = rotated_image.subsurface(rotated_rectangle).copy()return rotated_imagedef train():pygame.init()screen = pygame.display.set_mode((WIDTH, HEIGHT))game_map = pygame.image.load('map.png').convert() # Convert Speeds Up A Lotclock = pygame.time.Clock()num_radar = 17agent = PPOAgent(input_dims=[num_radar + 4], action_dim=2, lr=0.0005, gamma=0.99,clip_epsilon=0.2, gae_lambda=0.95, epochs=4, batch_size=128)scores = []average_scores = []distance = []average_distance = []alive_counts = []average_alive_counts = []actor_loss_values = []average_actor_loss = []n_games = 2000for i in range(n_games):car = Car([], [], num_radar)done = Falsescore = 0observation = car.get_data()alive_count = 0buffer = TrajectoryBuffer()while not done:action, log_prob = agent.select_action(observation)if len(agent.action_memory_for_end) >= 4:agent.action_memory_for_end = agent.action_memory_for_end[1:]agent.action_memory_for_end.append([round(action[0].item(), 2), round(action[1].item(), 2)])car.angle += action[0].item()car.angle = car.angle % 360car.speed = min(max(car.speed + action[1].item(), 0.0), 20.0)if len(agent.control_memory_for_end) >= 4:agent.control_memory_for_end = agent.control_memory_for_end[1:]agent.control_memory_for_end.append([round(car.angle, 2), round(car.speed, 2)])screen.blit(game_map, (0, 0))car.update(game_map)car.draw(screen)pygame.display.flip()clock.tick(60)done = not car.is_alive()observation_, reward = car.get_data(), car.get_reward_optimized333(action, done)buffer.states.append(observation)buffer.actions.append(action)# buffer.log_probs.append([log_prob[0][0].item(), log_prob[0][1].item()])buffer.log_probs.append(log_prob.item())buffer.rewards.append(reward)buffer.next_states.append(observation_)buffer.dones.append(float(done))observation = observation_score += rewardalive_count += 1# print(alive_count)agent.mem_cntr += 1# agent.buffer = bufferagent.buffer.states = buffer.states.copy()agent.buffer.actions = buffer.actions.copy()agent.buffer.log_probs = buffer.log_probs.copy()agent.buffer.rewards = buffer.rewards.copy()agent.buffer.next_states = buffer.next_states.copy()agent.buffer.dones = buffer.dones.copy()# 清空临时Buffer并释放显存buffer.clear()del bufferagent.learn()# 记录平均scorescores.append(score)avg_score = np.mean(scores[-100:])average_scores.append(avg_score)# 记录平均distancedistance.append(car.distance)avg_distance = np.mean(distance[-100:])average_distance.append(avg_distance)# 记录平均alive_countsalive_counts.append(alive_count)avg_alive_count = np.mean(alive_counts[-100:])average_alive_counts.append(avg_alive_count)# 记录平均actor_loss# actor_loss_values.append(agent.actor_loss_value)# avg_actor_loss = np.mean(actor_loss_values[-100:])# average_actor_loss.append(avg_actor_loss)avg_actor_loss = 0# 打印当前学习率(调试用)# current_actor_lr = agent.actor_lr_scheduler.get_last_lr()[0]# current_critic_lr = agent.critic_lr_scheduler.get_last_lr()[0]current_actor_lr = 0current_critic_lr = 0print(f'episode: {i}, score= {round(score, 2)}, actor_lr= {current_actor_lr},'f' critic_lr= {current_critic_lr}, dist= {round(car.distance, 2)}'f' avg_dist= {round(avg_distance, 2)}, avg_score= {round(avg_score, 2)},'f' avg_actor_loss= {round(avg_actor_loss, 2)}, alive_count= {alive_count},'f' mem_cntr= {agent.mem_cntr}')print("------action_memory_for_end: ", agent.action_memory_for_end)print("------control_memory_for_end: ", agent.control_memory_for_end)plt.subplot(1, 3, 1)plt.plot([i for i in range(0, n_games)], average_scores)plt.title("average_scores")plt.subplot(1, 3, 2)plt.plot([i for i in range(0, n_games)], average_distance)plt.title("average_distance")plt.subplot(1, 3, 3)plt.plot([i for i in range(0, n_games)], average_alive_counts)plt.title("average_alive_counts")plt.show()if __name__ == '__main__':train()