C++ STL简介:构建高效程序的基石
0. 引言
在现代软件开发领域,C++语言凭借其强大的性能和灵活性占据着重要地位。而C++标准模板库(Standard Template Library,简称STL)作为C++标准库的核心组件,更是开发者手中不可或缺的利器。它犹如一座知识宝库,通过容器、算法、迭代器、仿函数、适配器和分配器这六大核心组件,运用精妙的模板技术,将代码的通用性与复用性发挥到极致,极大地提升了软件开发效率,优化了软件质量。
从本质上来说,STL的设计理念体现了泛型编程(Generic Programming)的思想,它使得开发者可以编写与具体数据类型无关的代码,从而实现高度的代码复用。这种设计不仅减少了重复劳动,还提高了代码的可维护性和可扩展性。
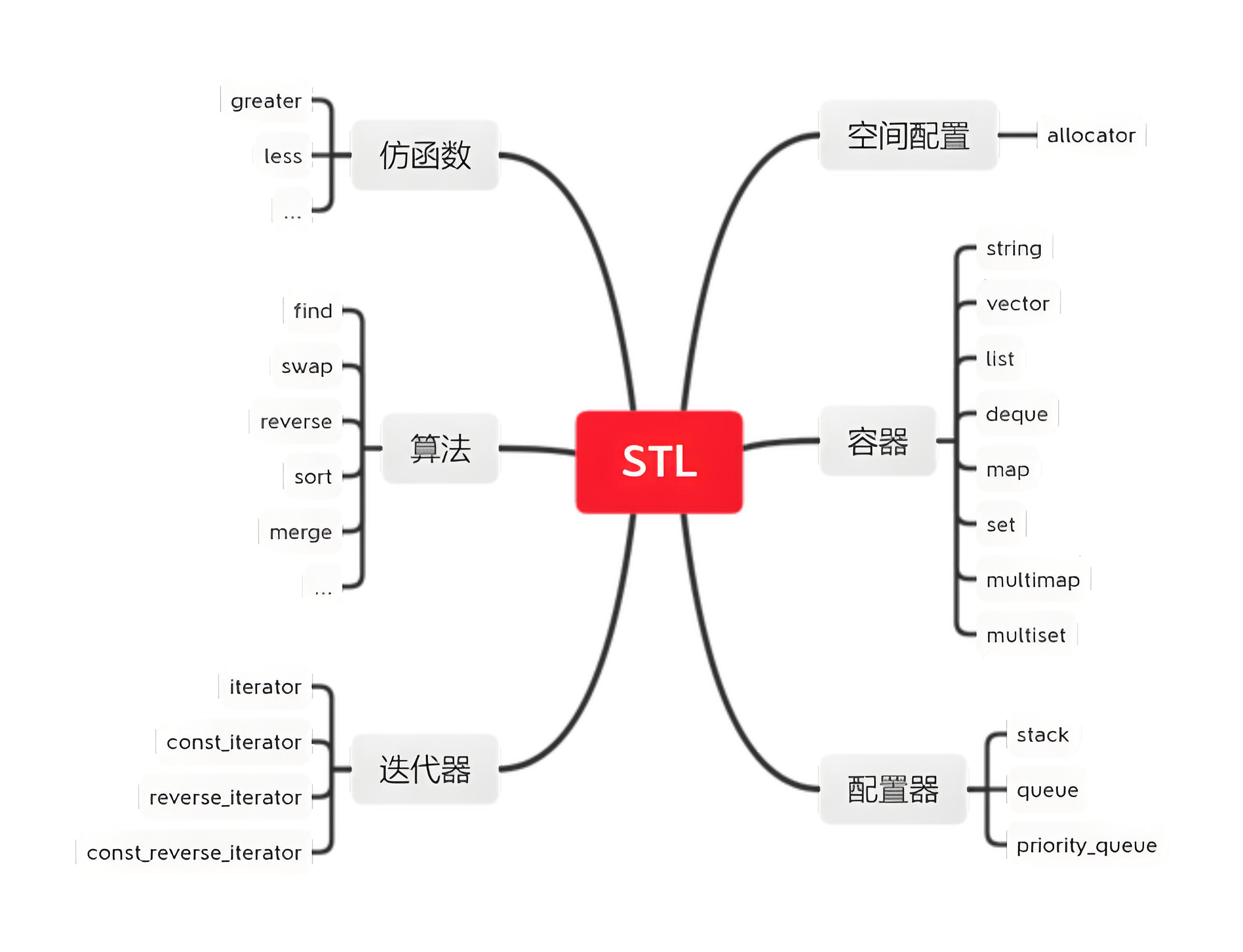
在此呢咱们只是简单介绍一下,至于理解的咱们要结合具体代码和情况来说明,理论与实践相结合才能更好的学习与理解,欲知具体如何,且听后续分解
1. 容器:数据的智能存储方案
容器是STL中用于存储数据的类模板,它根据不同的数据存储和访问需求,提供了多样化的实现方式。根据存储结构和特性,容器主要分为序列式容器和关联式容器两大类。
1.1 序列式容器
序列式容器以线性顺序存储元素,主要包括vector、list和deque。
vector(动态数组):作为最常用的序列式容器之一,vector在内存中采用连续存储的方式,这使得它支持高效的随机访问。通过下标操作,开发者可以快速定位和获取元素,这种特性在需要频繁访问元素的场景中尤为重要。例如,在处理大规模数值计算时,vector能够快速完成遍历和运算。此外,vector还具备自动内存管理功能,能够根据数据增长自动调整大小。不过,当vector容量不足需要扩容时,会经历重新分配内存、复制数据的过程,这在数据量较大时会带来一定的性能开销。
list(双向链表):list采用双向链表结构,这种结构使得插入和删除操作非常高效。在链表的任意位置插入或删除元素时,只需修改相关节点的指针,无需像vector那样移动大量数据。然而,由于链表结构的特性,list不支持随机访问(如[ ]),访问元素时需要从链表一端开始逐个遍历,这在需要频繁随机访问元素的场景中效率较低。例如,在游戏对象管理系统中,如果需要频繁根据索引查找对象,list就不是一个理想的选择。
deque(双端队列):deque结合了vector和list的部分优点,它不仅支持在两端快速插入和删除元素,还能实现随机访问。在处理需要频繁在队列两端进行操作的场景,如任务调度队列时,deque表现出色。不过,相比vector,deque的内存管理更为复杂,随机访问的效率也略低。
1.2 关联式容器
关联式容器基于键值对存储和管理数据,主要包括map和set。
map(映射):map以键值对的形式存储数据,其内部通常采用红黑树等平衡二叉搜索树实现,这使得通过键查找对应值的操作能够在对数时间复杂度内完成。在实际应用中,当需要快速建立数据映射关系时,map非常有用。例如,在学生信息管理系统中,可以将学生学号作为键,学生详细信息作为值存储在map中,方便快速查询。
set(集合):set用于存储不重复的元素,同样基于平衡二叉搜索树实现。在插入元素时,set会自动对元素进行排序,保证集合中的元素始终有序。在需要保证元素唯一性且有序的场景下,set是理想的选择。例如,在统计文本中不重复单词时,将单词插入set中,set会自动去除重复并按序存储。
2. 算法:数据处理的高效工具
有了存储数据的容器后,对数据进行各种处理就成为必然需求。STL提供了丰富的算法模板,涵盖查找、排序、遍历、修改等常见的数据处理操作。这些算法的一大特点是独立于具体的数据结构,通过迭代器与容器进行交互,从而实现了高度的通用性。
以排序算法为例,std::sort是STL中广泛使用的排序算法,它采用内省排序(Introsort),结合了快速排序、堆排序和插入排序的优点。无论是vector、deque等序列式容器,还是存储自定义数据类型的容器,只要定义了合适的比较规则,std::sort都能高效完成排序任务。例如,在一个存储商品结构体的vector中,可以定义按照商品价格从低到高的比较规则,std::sort就能据此进行排序。
除了排序,std::find用于在容器中查找特定元素,std::for_each可以对容器中的每个元素执行指定操作。这些算法极大地简化了开发者的工作,避免了重复编写复杂的数据处理逻辑,提高了代码的可维护性和可复用性。
3. 迭代器:容器与算法的桥梁
迭代器是一种特殊的对象,其行为类似于指针,在STL中起着至关重要的作用。它为算法提供了一种统一、标准的访问容器元素的方式,就像一座桥梁,连接起容器和算法。迭代器支持解引用、递增等操作,使得算法能够以相同的逻辑处理不同类型的容器。
不同类型的容器提供了不同类型的迭代器,包括输入迭代器、输出迭代器、前向迭代器、双向迭代器和随机访问迭代器等。每种迭代器都定义了特定的操作集合,以适应不同算法的需求。例如,vector支持随机访问迭代器,这使得std::sort等需要频繁随机访问元素的算法能够高效运行;而list仅支持双向迭代器,虽然不适合某些依赖随机访问的算法,但在插入和删除操作中能够发挥高效性能。
4. 仿函数:灵活的行为定制工具
仿函数(Functors),也称为函数对象,是一种特殊的类或结构体,它重载了函数调用运算符()。从使用形式上看,仿函数和普通函数类似,但它具有更高的灵活性,可以保存内部状态,并在运行时动态改变行为。在STL中,仿函数常用于为算法提供特定的操作逻辑。
例如,在使用std::sort进行排序时,默认是升序排列。如果需要降序排列,可以自定义一个仿函数:
struct CompareDescending {bool operator()(const int& a, const int& b) const {return a > b;}
};
然后在调用std::sort时传入这个仿函数:
std::vector<int> numbers = { 5, 3, 1, 4, 2 };
std::sort(numbers.begin(), numbers.end(), CompareDescending());
这样,std::sort就会按照降序对vector中的元素进行排序。仿函数的存在使得STL算法能够适应更多复杂的业务需求,增强了代码的灵活性和扩展性。
5. 适配器:接口的转换器
适配器在STL中扮演着接口转换器的角色,它可以将一个类或对象的接口转换为另一个接口,使其能够与其他组件协同工作。STL中的适配器主要包括容器适配器、迭代器适配器和函数适配器。
容器适配器:以现有容器为基础,改变其接口以满足特定需求。例如,stack和queue就是典型的容器适配器,它们默认基于deque实现,也可以指定其他支持相应操作的容器作为底层容器。stack提供后进先出(LIFO)的操作接口,queue提供先进先出(FIFO)的操作接口,通过容器适配器,开发者无需从头实现栈和队列的数据结构,提高了开发效率。
迭代器适配器:可以修改迭代器的行为。例如,std::reverse_iterator是一种迭代器适配器,它可以将普通迭代器反转,使得算法能够以逆序的方式遍历容器。
函数适配器:用于修改函数或仿函数的接口。例如,std::bind函数适配器可以将函数或仿函数的某些参数绑定为固定值,生成一个新的可调用对象,增加了函数和算法使用的灵活性。
6. 分配器:内存的管理者
分配器负责STL容器中内存的分配和释放,是容器与底层内存管理机制之间的桥梁。默认情况下,STL容器使用标准的内存分配器,基于operator new和operator delete来分配和释放内存。但在某些特殊场景下,开发者可能需要自定义分配器。
例如,在内存资源有限的嵌入式系统中,为了避免频繁的内存碎片,可以自定义一个内存池分配器。这种分配器预先分配一块较大的内存空间作为内存池,容器需要内存时从池中分配,释放时归还到池,而不是直接释放回操作系统。此外,自定义分配器还可以用于实现内存日志记录、性能分析等功能。
7. STL的优势与应用场景 *
C++ STL的优势主要体现在以下几个方面:
- 高度复用:通过模板技术,STL实现了代码的高度复用。开发者无需为不同数据类型重复编写类似的数据结构和算法代码,大大提高了开发效率。
- 性能卓越:STL经过大量严格测试和精心优化,性能表现出色,稳定性高,能够应对各种复杂应用场景。
- 易于使用:STL提供了统一、标准的接口,降低了学习和使用门槛,使得开发者能够快速上手。
在实际开发中,STL的应用场景非常广泛:
- 数据处理:在数据分析、科学计算等领域,
vector和各种算法可以高效处理大规模数据。 - 游戏开发:
list和deque常用于管理游戏对象序列和特效队列,利用其高效的插入删除和随机访问特性。 - 网络编程:在网络服务器开发中,
map和set可以用于管理连接信息和资源分配。
C++ STL以其强大的功能、高度的通用性和出色的易用性,成为C++开发者不可或缺的工具。熟练掌握STL的使用,不仅能够提高编程效率,编写出更加简洁、高效、健壮的代码,还能为复杂项目开发提供坚实的技术支持。
看到这里,相信你已经对STL有所了解了,具体一篇两篇说不清道不白,咋能一口吃成个胖子呢你说对吧哈哈哈。
话说大家的五一假期怎么样呢——包过得好啊😎😎😎
给大家放一张自己觉得拍的最绝的夜景~~~咱们下期再见咯
