从文本树到结构化路径:解析有限元项目架构的自动化之道
在现代科学计算与工程仿真领域,有限元方法(Finite Element Method, FEM)作为解决复杂偏微分方程的核心工具,其软件实现往往涉及庞大的代码库与精细的模块划分。一个典型的有限元项目,如名为 feon 的框架,其设计不仅依赖于坚实的数学基础,更需要清晰、可维护的代码结构。当我们面对一段以树形结构呈现的项目目录描述时,如何从中自动提取出所有文件与文件夹的完整路径,不仅是一项实用的工程任务,更是一次对代码组织逻辑与自动化思维的深入探索。
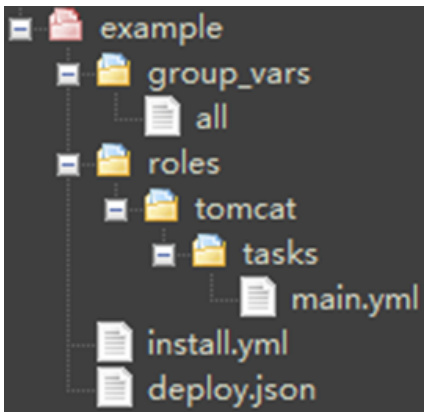
设想这样一个场景:你接手了一个尚未配备完善构建系统的有限元项目,仅有一段由 tree 命令生成的文本输出,描述了其目录层级。这段文本如下:
feon/
├── base.h
├── base.cpp
├── mesh.h
├── mesh.cpp
├── tools.h
├── tools.cpp
├── derivation/
│ ├── base.h
│ ├── dElement.h
│ ├── integration.h
│ └── lagrange.h
├── ffa/
│ ├── element.h
│ ├── node.h
│ ├── solver.h
│ └── system.h
└── sa/├── element.h├── node.h├── solver.h├── system.h├── post_process.h└── draw2d.h
这段看似简单的文本,实则蕴含了整个项目的拓扑结构。每一行代表一个节点,节点名称后若带有 /,则表示其为目录 DDD;若带有 `.h$ 或 .cpp.cpp.cpp 等扩展名,则为源文件 FFF。更重要的是,节点之间的父子关系由缩进深度决定,而连接符号 ├──├──├── 与 └──└──└── 则用于视觉上区分同一层级中的非末尾项与末尾项。要从这种非结构化的文本中还原出完整的路径体系,必须设计一种能够识别缩进层级、维护当前路径栈、并正确判断节点类型的解析机制。
在 PythonPythonPython 中,我们可以通过字符串处理与栈结构的结合来实现这一目标。核心思想是:利用缩进层级模拟文件系统的目录树遍历过程。每一级缩进通常对应 444 个空格,因此我们可以通过计算前缀空格数除以 444 来确定当前行的层级深度 LLL。通过维护一个路径栈 S=[s0,s1,...,sk−1]S = [s_0, s_1, ..., s_{k-1}]S=