K8s 实战:六大核心控制器
Kubernetes 控制器(Controller)是实现 Pod 自动化管理的核心组件,通过预设规则自动维持 Pod 的期望状态(如数量、版本、运行节点等)。本文基于实验场景,详细解析 ReplicaSet、Deployment、DaemonSet、Job、CronJob、StatefulSet 六大控制器的功能逻辑、配置原理及实际应用场景。
一、Replicaset
核心功能
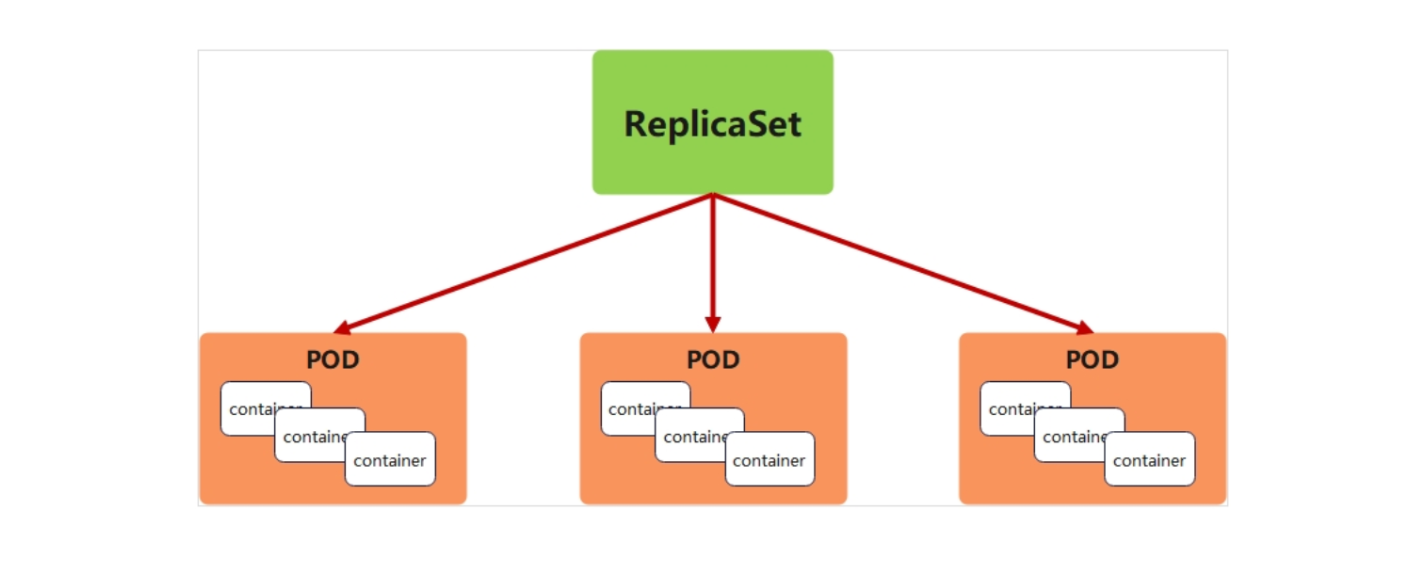
ReplicaSet(副本集)的核心作用是维持指定数量的 Pod 副本始终运行,通过标签选择器关联 Pod,当 Pod 因故障删除、标签变更等原因数量不足时,自动创建新 Pod 补齐,是保障无状态应用高可用的基础控制器。
kubectl create deployment replicaset --image myapp:v1 --dry-run=client -o yaml > replicaset.yml
vim replicaset.yml
###############
apiVersion: apps/v1
kind: ReplicaSet # 明确资源类型为 ReplicaSet
metadata:labels:app: replicasetname: replicaset
spec:replicas: 2 # 期望维持 2 个 Pod 副本selector:matchLabels:app: replicaset # 标签选择器:只管理带"app: replicaset"标签的Podtemplate:metadata:labels:app: replicaset # 新Pod会带上此标签,与选择器匹配spec:containers:- image: myapp:v1name: myapp
###############
kubectl apply -f replicaset.yml replicas: 2:核心参数,指定目标 Pod 数量(生产环境根据负载需求设置,如 6 个副本应对高并发)。
selector.matchLabels 与 template.metadata.labels:必须一致,否则 ReplicaSet 无法识别并管理自己创建的 Pod(标签是 K8s 中资源关联的 "身份证")。
查看Pod,初始为2个(如replicaset-qfbrw、replicaset-8h6gh)
Pod 数量稳定为 2 个,与replicas配置一致

验证 "故障自愈":删除 Pod 后自动重建
删除掉一个 pod,会自动建立新的 pod
kubectl delete pods replicaset-qfbrw 现象:被删除的 Pod 会快速重建,新 Pod 名称不同但标签一致,总数量仍为 2 个。 原理:ReplicaSet 通过控制器循环(Controller Loop)持续对比 "实际 Pod 数量" 与 "期望数量",发现差异后立即调谐(创建新 Pod)。

验证 "标签关联":修改标签后自动补齐
pod 的个数是根据标签决定的,修改一个 pod 的标签,则原标签 pod 数变少,会自动建立新 pod 补齐
kubectl label pods replicaset-8h6gh app=haha --overwrite # 将一个Pod的标签改为"app: haha"
kubectl get pods --show-labels现象:原标签为 "app: replicaset" 的 Pod 只剩 1 个,ReplicaSet 会立即创建新 Pod 补齐至 2 个。 原理:标签是 ReplicaSet 识别 Pod 的唯一依据,修改标签后,原 Pod 脱离管理范围,ReplicaSet 会按模板创建新 Pod 维持期望数量。

适用场景
无状态应用的基础副本管理(如 Web 服务、API 节点),确保服务不中断。
配合 Deployment 使用(Deployment 通过管理 ReplicaSet 实现更高级的版本控制)。
二、Deployment
核心功能
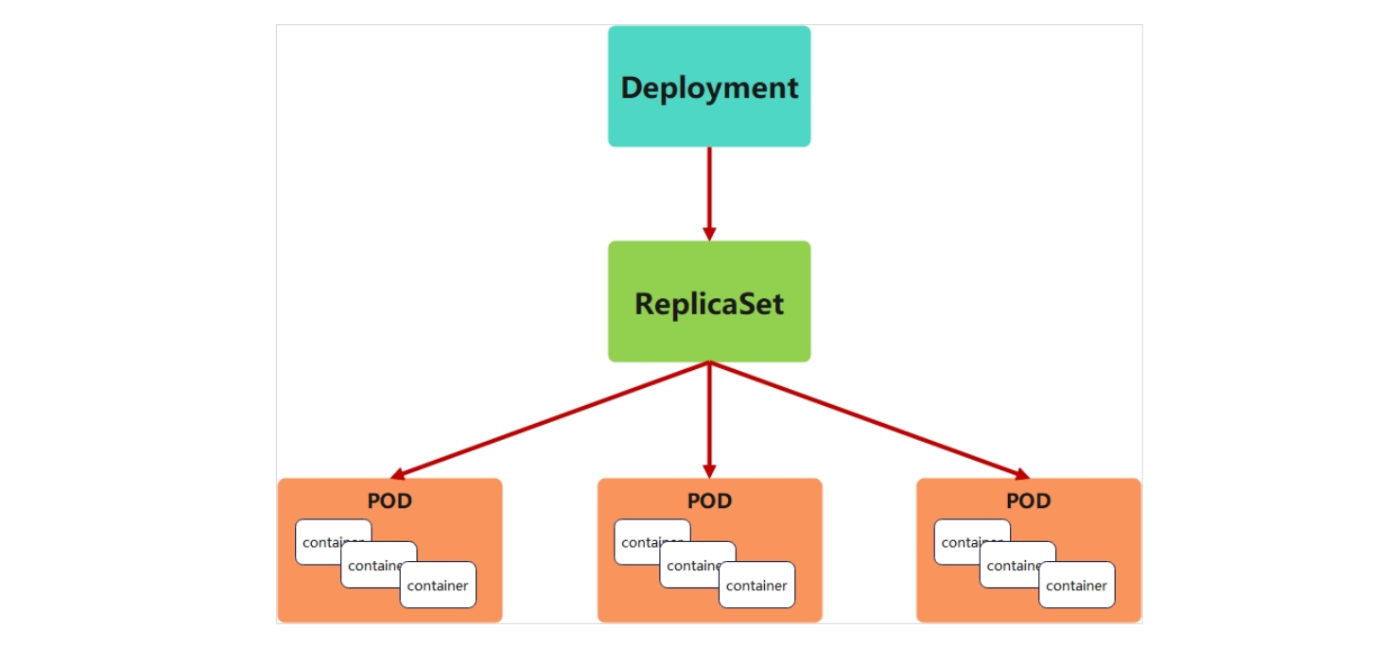
Deployment 基于 ReplicaSet 构建,除了维持 Pod 数量,还提供版本更新、回滚、滚动更新策略等高级功能,是生产环境部署无状态应用的首选控制器。
2.1.版本更新与回滚
vim deployment.yml
##############
apiVersion: apps/v1
kind: Deployment
metadata:labels:app: deploymentname: deployment
spec:replicas: 4 # 维持 4 个 Pod 副本selector:matchLabels:app: deploymenttemplate:metadata:labels:app: deploymentspec:containers:- image: myapp:v1 # 初始镜像版本name: myapp
##############
kubectl apply -f deployment.yml
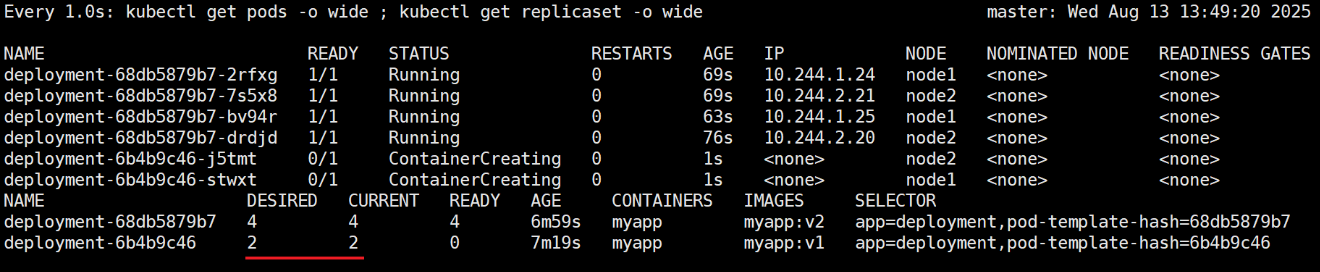
kubectl get pods -o wide
kubectl get replicaset -o wide会生成一个ReplicaSet(如deployment-7f9f654d9)管理4个Pod
原理:Deployment 不直接管理 Pod,而是通过创建 ReplicaSet 实现间接管理(每个版本对应一个 ReplicaSet)。

curl 10.244.1.8
vim deployment.yml
##############
apiVersion: apps/v1
kind: Deployment
metadata:labels:app: deploymentname: deployment
spec:replicas: 4selector:matchLabels:app: deploymenttemplate:metadata:labels:app: deploymentspec:containers:- image: myapp:v2 # 从 v1 改为 v2name: myapp
##############
kubectl apply -f deployment.yml # 应用更新
kubectl get pods -o wide
kubectl get replicaset -o wide会生成新ReplicaSet(如deployment-6b8d7f54)
现象:新 ReplicaSet 逐步创建 v2 版本 Pod,旧 ReplicaSet 逐步删除 v1 版本 Pod,过程中总 Pod 数量保持 4 个。 优势:滚动更新(Rolling Update)确保服务不中断,用户无感知版本切换。

curl 10.244.2.11 # v2 版本
2.2.滚动更新策略
vim deployment.yml
############
apiVersion: apps/v1
kind: Deployment
metadata:labels:app: deploymentname: deployment
spec:minReadySeconds: 5 # 新 Pod 创建后,等待 5 秒确认就绪再继续更新replicas: 4strategy:rollingUpdate:maxSurge: 2 # 最多可超出期望副本数的数量(4+2=6个)maxUnavailable: 0 # 更新过程中不可用的 Pod 数量不能超过 0(确保服务 100% 可用)selector:matchLabels:app: deploymenttemplate:metadata:labels:app: deploymentspec:containers: - image: myapp:v1 # 从 v2 改为 v1name: myapp
############kubectl apply -f deployment.yml
kubectl get pods -o wide
kubectl get replicaset -o widemaxSurge: 2:控制更新速度,允许同时创建 2 个新 Pod(避免一次性创建过多占用资源)。
maxUnavailable: 0:适用于对可用性要求极高的场景(如支付服务),确保更新时始终有 4 个可用 Pod。
minReadySeconds: 5:防止新 Pod 刚启动就被判定为 "就绪"(可能存在初始化延迟),等待 5 秒确认稳定后再继续更新。

2.3.暂停与恢复
kubectl rollout pause deployment deployment # 暂停更新
vim deployment.yml
##############
apiVersion: apps/v1
kind: Deployment
metadata:labels:app: deploymentname: deployment
spec:minReadySeconds: 5replicas: 4strategy:rollingUpdate:maxSurge: 2maxUnavailable: 0selector:matchLabels:app: deploymenttemplate:metadata:labels:app: deploymentspec:containers:- image: myapp:v2 # 从 v1 改为 v2name: myapp
##############
kubectl apply -f deployment.yml # 配置不会立即生效
kubectl rollout history deployment deployment # 查看历史,无新版本记录

kubectl rollout resume deployment deployment # 恢复更新
现象:暂停期间的配置修改会在恢复后一次性生效。 适用场景:灰度发布验证 —— 先更新部分 Pod,观察无异常后再恢复更新全量 Pod,降低风险。


核心价值
版本化管理:每个更新生成新 ReplicaSet,支持快速回滚(kubectl rollout undo)。
精细化控制:通过滚动更新策略平衡更新速度与服务可用性。
三、DaemonSet
核心功能
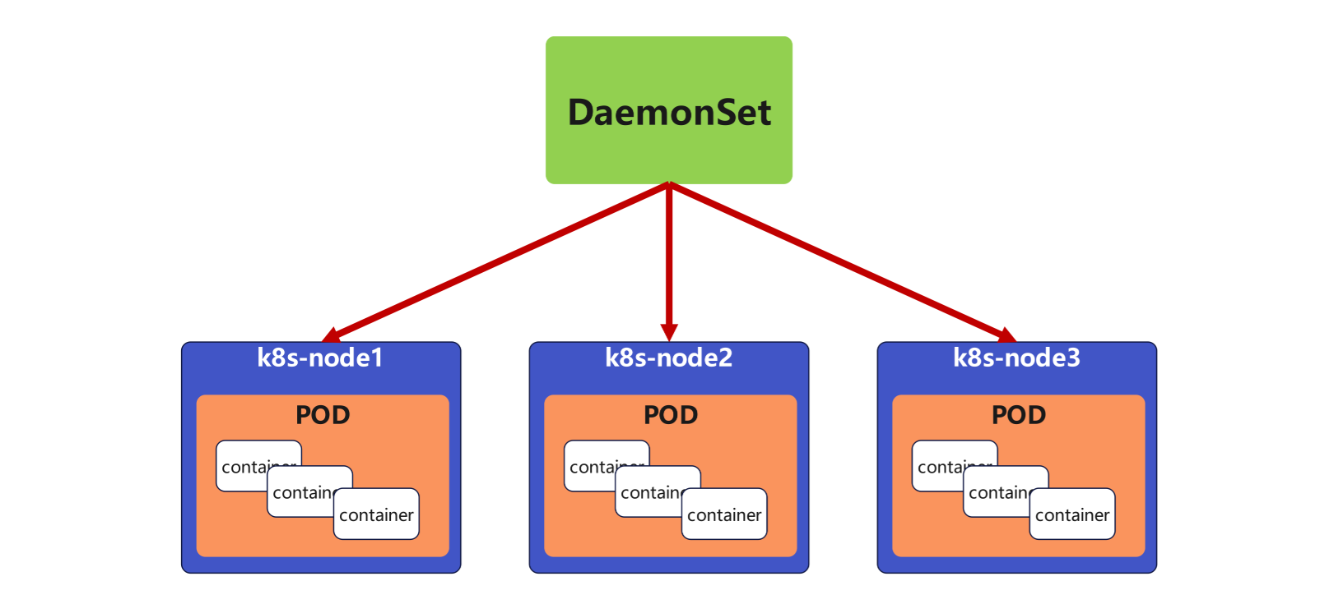
DaemonSet 确保集群中每个节点(或匹配规则的节点)都运行一个相同的 Pod,新节点加入集群时自动部署 Pod,节点移除时自动删除 Pod,适合运行节点级服务。
vim daemonset.yml
############
apiVersion: apps/v1
kind: DaemonSet
metadata:labels:app: daemonsetname: daemonset
spec:selector:matchLabels:app: daemonsettemplate:metadata:labels:app: daemonsetspec:tolerations: # 容忍节点污点(如 master 节点的 NoSchedule 污点)- effect: NoScheduleoperator: Existscontainers:- image: myapp:v1name: myapp
############关键配置解读:
无 replicas 参数:Pod 数量由集群节点数决定(每个节点 1 个)。
tolerations:K8s 节点可能设置 "污点"(Taint)阻止 Pod 调度(如 master 节点默认不允许普通 Pod 运行),此配置允许 DaemonSet 的 Pod 在有污点的节点上运行(确保每个节点都能部署,如监控代理需覆盖 master 节点)。
kubectl apply -f daemonset.yml
kubectl get pods -o wide现象:每个节点上都有一个 DaemonSet 的 Pod,新加入的节点会自动出现该 Pod。

适用场景
日志收集:如部署 Fluentd、Logstash 到每个节点,收集本地日志。
监控代理:如部署 Prometheus Node Exporter,采集节点 CPU、内存数据。
网络插件:如 Calico、Flannel,需在每个节点运行网络代理。
四、job
核心功能
Job 用于运行一次性任务(完成后自动终止),支持指定任务完成次数、并行数,失败时可重试,适合批处理、数据迁移等场景。
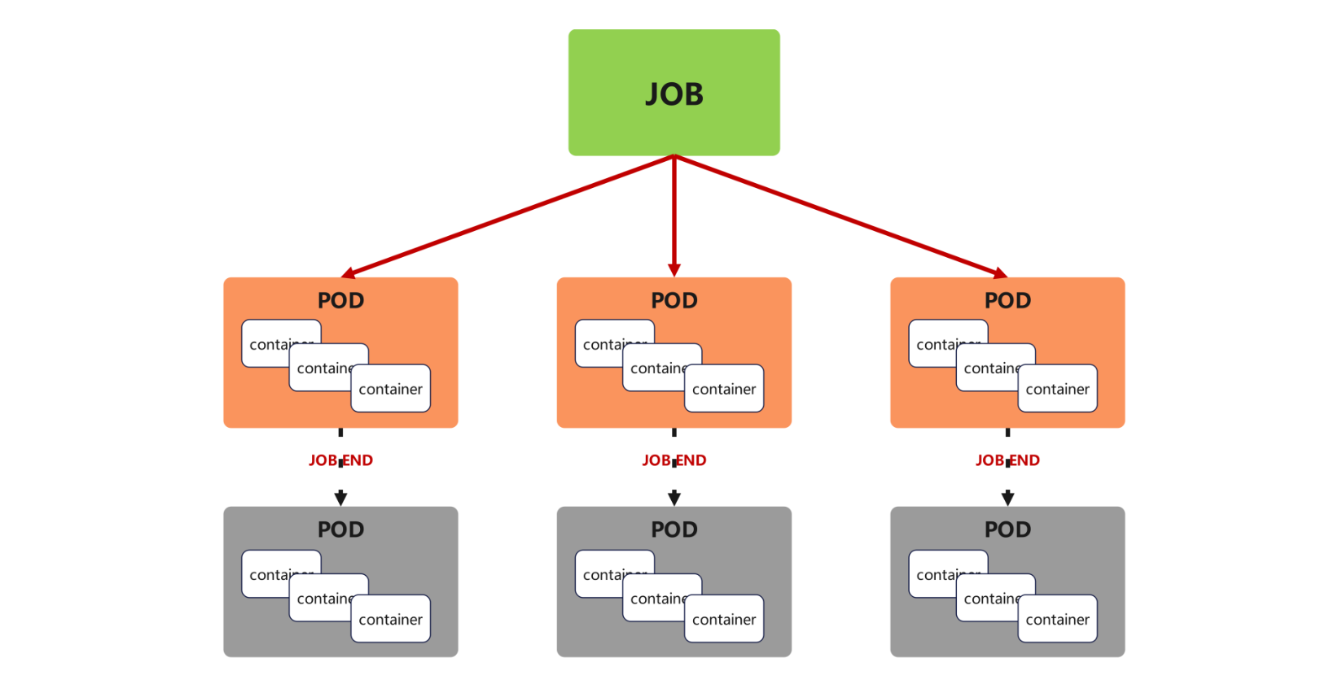
vim job.yml
##########
apiVersion: batch/v1
kind: Job
metadata:name: job-example
spec:completions: 6 # 任务总完成次数(需成功运行 6 次)parallelism: 2 # 并行运行的 Pod 数量(同时启动 2 个)backoffLimit: 4 # 失败重试次数(最多重试 4 次)template:spec:restartPolicy: Never # 任务失败后不重启 Pod(由Job重新创建新Pod)containers:- image: perl:5.34.0name: job-example command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"] # 计算 π 的 2000 位小数(示例任务)
##########会看到 2 个 Pod 同时运行,陆续完成后总成功数为 6
现象:任务完成后,Pod 状态变为 Completed,Job 状态显示 Successful: 6

适用场景
数据备份 / 迁移:如一次性从 MySQL 迁移数据到 PostgreSQL。
批量计算:如离线数据分析、图片处理。
五、Cronjob
核心功能
CronJob 基于 Job 实现周期性任务调度(类似 Linux 的 crontab),支持按时间规则(如每小时、每天)重复执行任务,适合定时备份、日志清理等场景。
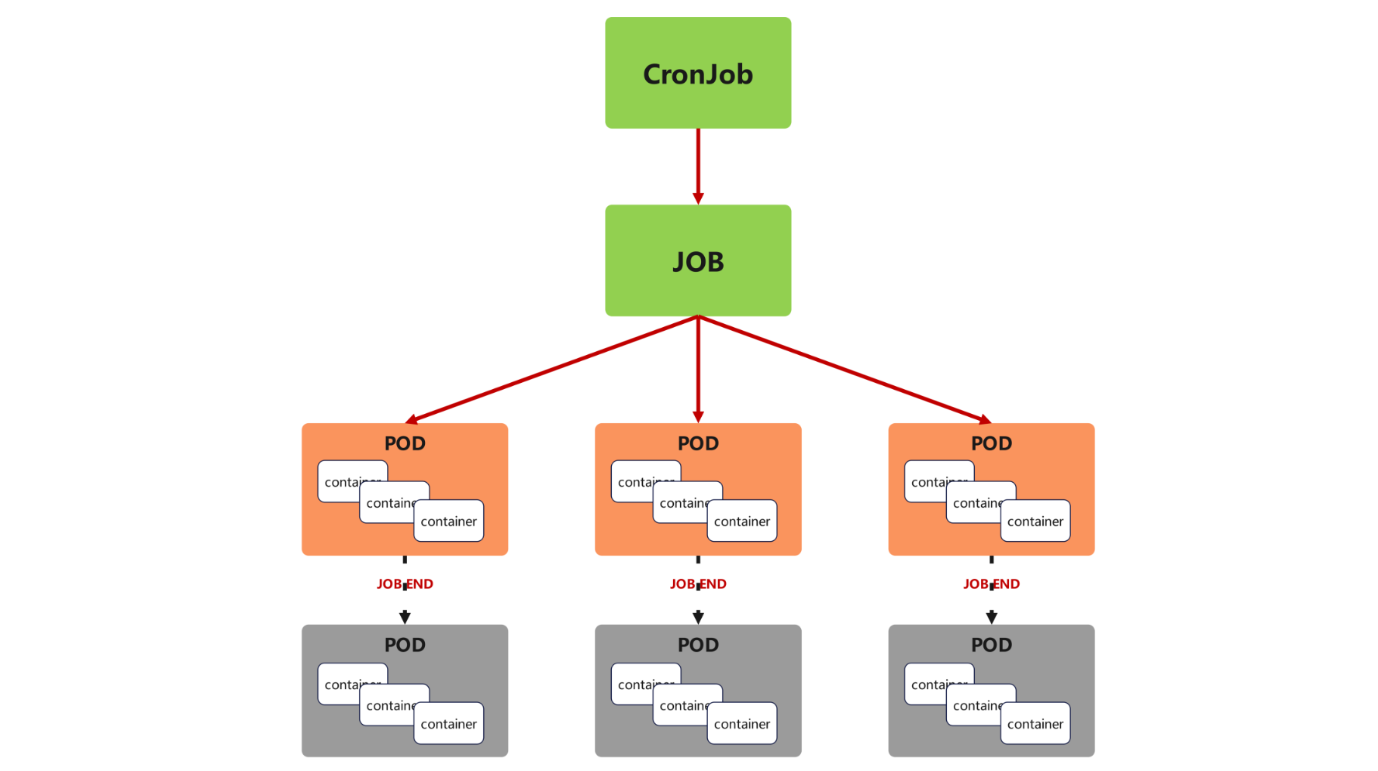
kubectl create cronjob cronjob-example --image myapp:v1 --schedule "* * * * *" --dry-run=client -o yaml > cronjob.ymlvim cronjob.yml
#############
apiVersion: batch/v1
kind: CronJob
metadata:name: cronjob-example
spec:schedule: '* * * * *' # Cron表达式:每分钟执行一次(测试用)jobTemplate: # 任务模板(定义每次执行的Job配置)metadata:name: cronjob-examplespec:template:metadata:spec:containers:- image: busyboxname: cronjob-examplecommand: - /bin/sh- -c- date; echo Hello from the Kubernetes cluster # 输出当前时间和信息restartPolicy: OnFailure # 任务失败时重启容器(而非创建新Pod)
#############kubectl apply -f cronjob.yml
kubectl get pods -o wide整点运行:每分钟会生成一个新 Pod

执行后状态变为 Completed

查看日志,会输出当前时间和 "Hello..."
现象:按 Cron 规则周期性创建 Pod,任务完成后自动终止

适用场景
定时备份:如每天凌晨 2 点备份数据库。
日志清理:如每周一删除 7 天前的日志文件。
健康检查:如每小时执行一次接口探测,异常时告警。
六、StatefulSet
核心功能
StatefulSet 用于部署有状态应用(如数据库、分布式系统),与无状态控制器的核心区别是:
Pod 名称固定且有序(如 web-0、web-1,而非随机字符串);
结合无头服务(Headless Service)提供稳定的网络标识(DNS 名称固定);
支持稳定存储(重建 Pod 后仍能挂载原存储卷)。
kubectl create service clusterip web --clusterip="None" --dry-run=client -o yaml > service.yml # 创建无头服务
vim service.yml
###############
apiVersion: v1
kind: Service
metadata:labels:app: webname: web
spec:clusterIP: None # 无头服务:不分配 ClusterIP,仅提供 DNS 解析selector:app: webtype: ClusterIP
###############
kubectl apply -f service.yml 作用:为 StatefulSet 的 Pod 提供稳定的 DNS 解析。每个 Pod 的 DNS 名称格式为 {pod-name}.{service-name}.{namespace}.svc.cluster.local(如 web-0.web.default.svc.cluster.local),即使 Pod 重建(IP 变化),DNS 名称仍不变。
kubectl create deployment web --image myapp:v1 --dry-run=client -o yaml > web.yml # 创建 statufulset 控制器,因为不能直接 create,所以先生成 deployment 控制器再修改文件vim web.yml
###############
apiVersion: apps/v1
kind: StatefulSet
metadata:labels:app: webname: web
spec:serviceName: web # 关联上述无头服务replicas: 2 # 2个有序Pod(web-0、web-1)selector:matchLabels:app: webtemplate:metadata:labels:app: webspec:containers:- image: myapp:v1name: myapp
###############
kubectl apply -f web.yml 测试:
生成 web-0、web-1 两个 Pod,名称固定。删除 web-0 pod,会自动建立一个同名的 pod,但是 IP 会变化,便于集群内部解析,有状态的解析,例如:mysql 的主从同步,就是典型的有状态的服务,需要知道 master 的 IP,所以通过 statufulset 联合无头服务,就可以解析出 IP。
kubectl delete pods web-0现象:Pod 重建后名称不变,通过无头服务的 DNS 仍可解析到新 IP。
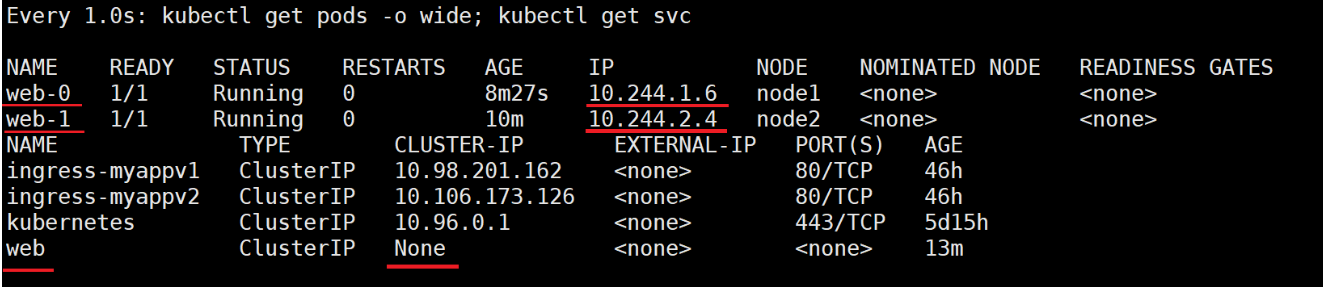
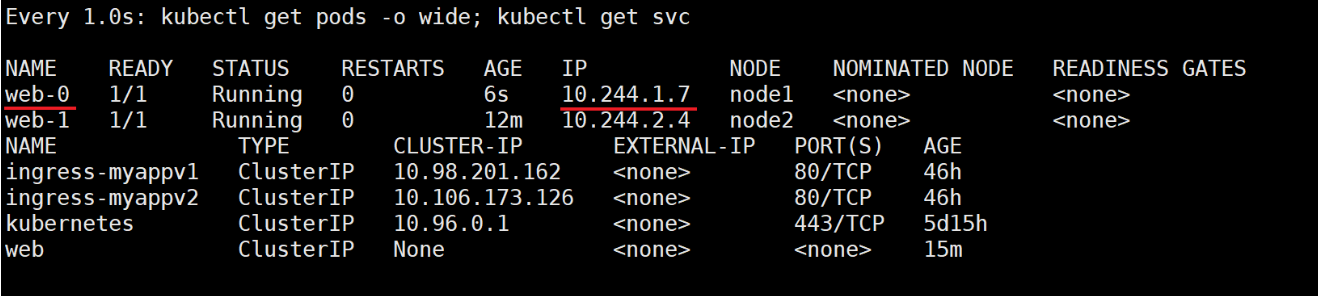
测试:
查看域名解析结果
dig web.default.svc.cluster.local. @10.96.0.10
dig web-0.web.default.svc.cluster.local. @10.96.0.10

适用场景
数据库集群:如 MySQL 主从(master-0、slave-1,需固定标识通信)。
分布式系统:如 ZooKeeper、Kafka(节点间依赖固定名称 / IP 通信)。
七、总结
控制器选择指南
| 控制器 | 核心特性 | 典型应用场景 | 关键优势 |
|---|---|---|---|
| ReplicaSet | 维持固定数量 Pod 副本 | 无状态应用基础部署 | 简单可靠,确保服务不中断 |
| Deployment | 版本更新、回滚、滚动策略 | Web 服务、API 节点(需频繁迭代) | 支持无感知更新,故障可快速回滚 |
| DaemonSet | 每个节点运行一个 Pod | 日志收集、监控代理、网络插件 | 自动覆盖全节点,新节点无缝接入 |
| Job | 一次性任务,支持并行与重试 | 数据迁移、批量计算 | 任务完成自动终止,失败可重试 |
| CronJob | 周期性任务调度 | 定时备份、日志清理 | 按时间规则自动执行,无需人工干预 |
| StatefulSet | 固定名称 / 网络标识,支持稳定存储 | 数据库、分布式系统(如 MySQL、Kafka) | 保障有状态应用的标识与数据稳定性 |
通过合理选择控制器,可实现 Kubernetes 集群中各类应用的自动化、高可用管理,大幅降低运维成本。