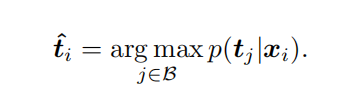ViLU: Learning Vision-Language Uncertainties for Failure Prediction
研究方向:Image Captioning
1. 论文介绍
本文提出ViLU(Vision-Language Uncertainties),一个用于学习视觉语言不确定性量化(UQ)和检测视觉语言模型故障的事后框架。
使用VLMs进行量化(UQ)的标准方法是最大概念匹配(MCM)分数(如果模型给某个类别分的概率最大,那就认为它最有可能是正确答案),但它存在根本性的缺陷:如果多个概念之间存在歧义,原始的最大概念最大化 (MCM) 可能会对错误的预测赋予较高的置信度,并且把模型对最可能类别的置信度作为可靠性指标。
如图所示,视觉语言模型(VLM)误将“爱斯基摩犬”图像分类为“西伯利亚雪橇犬”,而且高置信度得分阻止了错误的检测。

2. 方法介绍
2.1 在视觉语言模型上进行不确定性量化的方法学
采用一种事后方法,仅依赖于视觉和文本嵌入,设计不确定性量化度量。提供不确定性估计而无需修改内部表示、进行微调或依赖于训练期间使用的损失函数。
不确定性受视觉嵌入(低图像质量、模糊特征)、文本嵌入(定义概念难以区分)和跨模态(视觉嵌入和K个候选文本嵌入之间)交互的影响。学习一个全局不确定性表示uθ(⋅)(预测输入是否会被视觉语言模型误分类)来捕捉上述三种不确定性影响。不确定性模块二元分类任务表示:
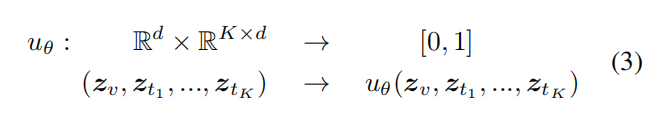
输入图像和K个候选文本嵌入表示,输出一个概率值,表示 VLM 的预测是否错误。
2.2 ViLU框架
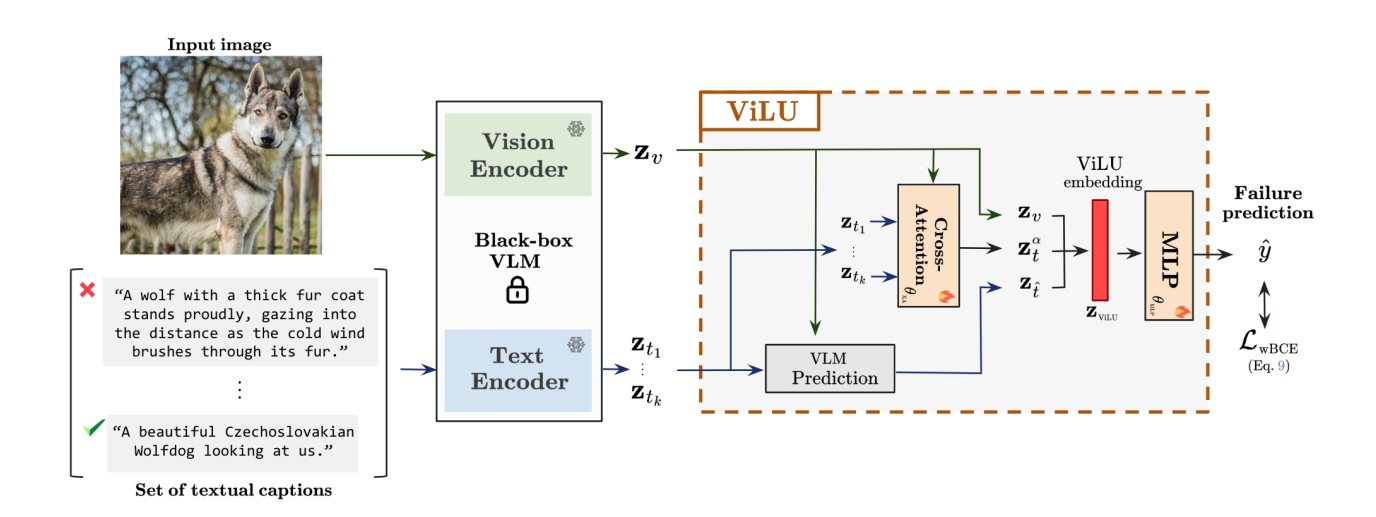
通过整合视觉嵌入()、预测文本嵌入(
)和跨注意力生成的特定于图像条件的文本表示(
),构建任务相关的联合不确定性表征。ViLU将失败预测建模为二元分类问题,采用加权交叉熵损失直接区分正确与错误预测,而非依赖损失预测,从而实现对预训练VLMs的黑盒式后处理。
2.3 训练过程
ViLU在训练和推理过程中同时处理图像-字幕任务和图像-标签任务
图像-标签任务:利用图像和K个目标类别确定图像的预测概念类别,形成一个与批次无关的预测流程。类别的文本表示通过文本模板获得(例如,“一张[类别]的照片”),得到一组固定的文本字幕 。适用于具有预定义标签的标准分类数据集。
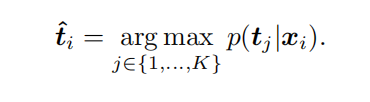
图像-字幕任务:为给定的输入图像分配最相似的字幕,利用图文对预测相应图像的字幕,