iperf2 vs iperf3:UDP 发包逻辑差异与常见问题
1. 问题引入
在日常网络测试中,大家经常会遇到这样的情况:iperf3 -u -c -b 1000M
结果显示:实际带宽只有 600~800 Mbps,远低于我们设置的 1000 Mbps。
于是问题来了:
- 是链路本身达不到 1Gbps?
- 还是 iperf3 没有按指令发足够多的 UDP 报文?
很多人会因此怀疑测试结果不准确。其实这并不是链路坏了,而是 iperf3 UDP 模式的设计决定了它不会“强行灌包”。
2. 根本原因
造成这种现象的核心原因在于 iperf2 与 iperf3 的 UDP 发包逻辑不同:
- iperf2:强调“尽量贴合目标速率”。如果系统调度落后,会突发补发欠账的包,看起来速率接近 -b,但链路抖动大,丢包率可能高。
- iperf3:强调“真实统计”。如果系统调度落后,就直接跳过“欠账”,只统计实际发出的字节数。结果可能低于 -b,但数值更真实,能反映链路的实际可用带宽。
换句话说:
- iperf2 更像“压测工具” → 灌满链路,测试设备极限。
- iperf3 更像“测量工具” → 精确统计,反映真实可用速率。
3. 发包逻辑对比
3.1 关键变量与基本公式
- 目标带宽:B_target(bit/s),由 -b 指定
- UDP 载荷长度:L_payload(Byte),由 -l 指定
- 每包比特数:P_bits = L_payload * 8
- 期望包速率:pps = B_target / P_bits(包/秒)
- 理想包间隔:Δt = 1 / pps = P_bits / B_target(秒)
注意:iperf 的带宽统计通常以应用层负载为准(即 payload 大小),不含 UDP/IP/L2 头部;但链路“线速”会受实际报文总大小(含各层头部、IFG 等)影响。
示例(-b 1,000,000,000,-l 1470):
- P_bits = 1470 * 8 = 11760
- pps ≈ 1e9 / 11760 ≈ 85,034 包/秒
- Δt ≈ 11.76 μs/包 这意味着:用户态要在 每 11.76 μs 精准触发一次 sendto(),对普通 OS 调度精度是非常苛刻的。
3.2 iperf2:允许“追赶”的节奏(更像压测)
思路
- 以累计目标字节数为节拍参考:target_bytes(now) = B_target * elapsed
- 如果当前已发送字节 sent_bytes < target_bytes(now),则立即、连续多次 sendto() 直到追上进度
- 这样会出现突发补发(burst),让统计值更贴近 -b,但链路侧抖动与丢包风险更高
流程
- 周期性计算“理论上应该发出的累积字节数”
- 如果“欠账”,就循环 sendto() 补发到“应发进度”
- 否则按节拍 sleep_until()
- 统计以“发送成功的字节数/窗口时间”为准(更接近目标,但存在突发)
伪代码
// iperf2-style UDP pacing (pseudo)
init_clock();
uint64_t sent_bytes = 0;
const uint64_t pkt_bytes = L_payload;
const double Bps = B_target / 8.0;while (running) {double elapsed = now_seconds_since_start();double should_send_bytes = Bps * elapsed;// 欠账就追赶:可能一次性 send 多包while (sent_bytes + pkt_bytes <= should_send_bytes) {int rc = sendto(sock, buf, L_payload, 0, ...);if (rc < 0) {if (errno == EAGAIN || errno == EWOULDBLOCK) break; // socket 滑窗/队列满// 其它错误按需处理break;}sent_bytes += rc;}// 适度小睡,避免忙等sleep_until(elapsed + small_delta);
}
效果与代价
- 更容易“报表接近 -b”
- 可能把欠账一次性灌入内核/NIC 队列 → 链路侧看到 burst、抖动、甚至丢包上升
3.3 iperf3:不追赶的“到点发一包”(更像测量)
思路
- 以下一次发送的绝对时间戳为节拍:next_send_time
- 到点就发一包;如果因调度/阻塞落后了,不会补发欠账,而是顺延到新的节拍
- 统计“实际成功发出的字节数/真实时间”,因此当系统跟不上节拍时,显示带宽会低于 -b
流程
- 预先计算 Δt,设置 next_send_time = start + Δt
- 若 now < next_send_time → 睡到点;到点后只发一包
- 若 now >= next_send_time(落后)→ 不补发欠账,直接把 next_send_time 顺延(常见做法是 next_send_time = now + Δt 或者按步进递增,落后太多时会跳过若干节拍)
- 统计“实际发出去的字节/时间窗口”,更接近真实可用能力
伪代码
// iperf3-style UDP pacing (pseudo)
struct timespec next = start_time + Δt;
uint64_t sent_bytes = 0;while (running) {struct timespec now = clock_gettime(CLOCK_MONOTONIC);if (now < next) {sleep_until(next); // 到点再发}// 到点只发一包,不追赶int rc = sendto(sock, buf, L_payload, 0, ...);if (rc > 0) {sent_bytes += rc;} else {if (errno == EAGAIN || errno == EWOULDBLOCK) {// socket 满了,说明系统跟不上节拍,不补发,直接顺延} else {// 其它错误按需处理}}// 计算下一个节拍;若落后较多,常见做法是直接“与 now 对齐”:now = clock_gettime(CLOCK_MONOTONIC);if (now > next + Δt) {// 说明错过多个节拍,直接对齐,避免累积补发next = now + Δt;} else {next = next + Δt;}
}
// 统计:实际成功发出的字节 / 真实窗口时间(不会“强行贴合 -b”)
效果与代价
- 更真实地反映“系统+内核+NIC”整体可用发包能力
- 当节拍跟不上目标时,显示带宽显著低于 -b(这是特性,不是 bug)
3.4 行为差异:一个“欠账”场景
- 设定 Δt = 11.76 μs,next_send_time = t0 + Δt
- 某次调度抖动导致 now = t0 + 100 μs 才醒来
- iperf2:计算“应发 N 包”,立即循环 sendto() 补发到应发进度(burst)
- iperf3:只发一包,然后把 next_send_time 挪到 now + Δt(或按步进顺延),不补发落下的 N−1 包
3.5 时序图
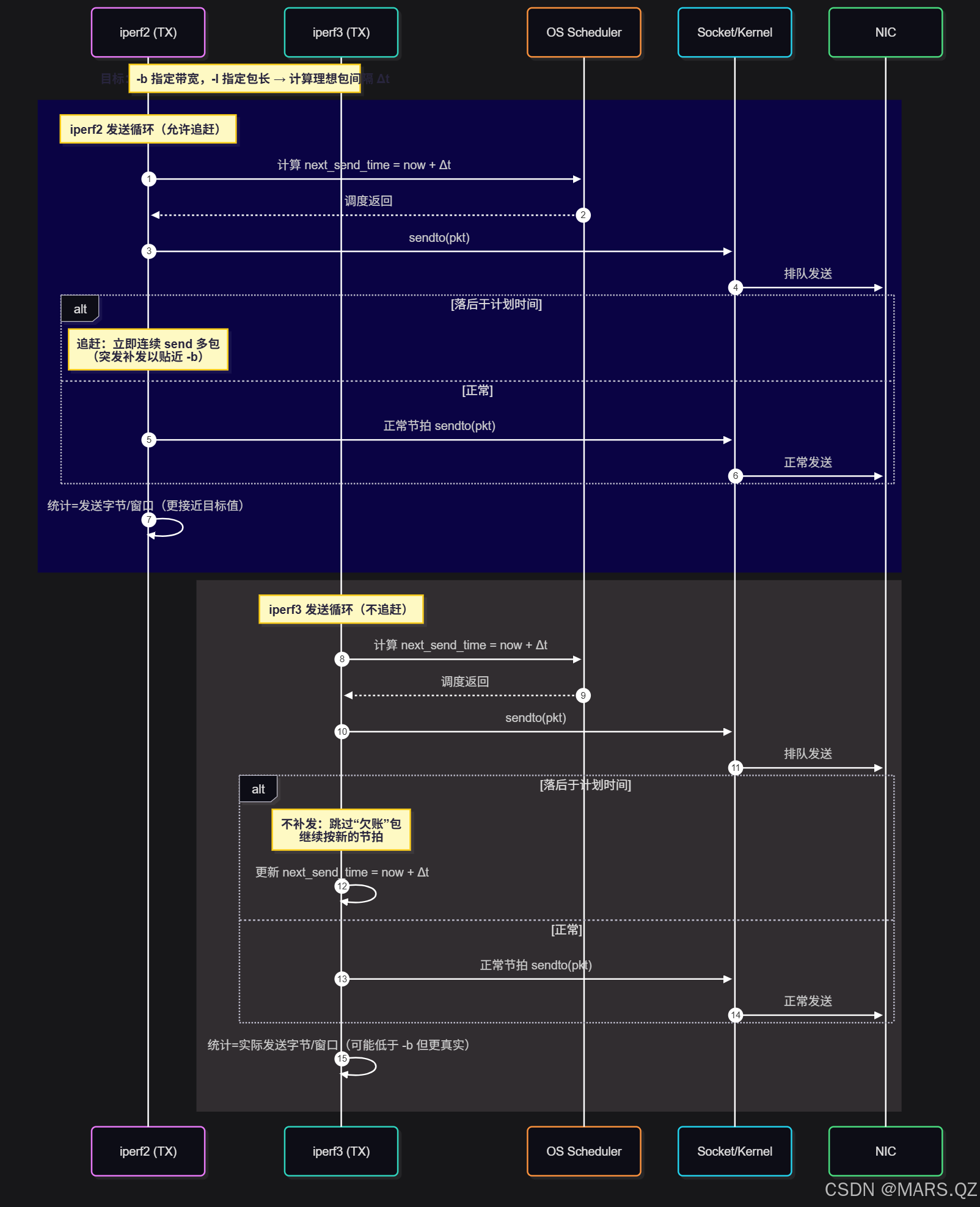
4. 伪代码对比
// iperf2 (简化示意)
for (;;) {target += pkt_bytes;while (sent < target) sendto(pkt); // 允许“追赶”补发(可能突发)sleep_until(next_time);next_time += Δt;
}// iperf3 (简化示意)
for (;;) {if (now < next_time) sleep_until(next_time);sendto(pkt); // 到点才发,不补发“欠账”next_time += Δt; // 落后就顺延,不追赶
}
// 统计= 实际成功发送字节 / 时间窗口(不强行贴合 -b)5. UDP 模式调优 Checklist
- 提高 socket buffer:
iperf3 -u -b 1000M -l 1470 --sndbuf 1M
- 绑定 CPU,减少调度抖动:
taskset -c 1 iperf3 -u ...
- 调大内核参数:
sysctl -w net.core.wmem_max=4194304sysctl -w net.core.rmem_max=4194304
- 测试高带宽场景建议:
- 真实性能评估 → 用 iperf3
- 极限压力测试 → 可对比 iperf2
6. 常见 FAQ
Q: iperf3 为什么我指定了 -b 1000M,结果只有 700Mbps?
- 并不是链路坏了,而是 iperf3 不会补发落后的包。
- 这正是它的“真实统计”特性,结果反映的是 你机器实际能发出的速率,而不是强行贴合 -b。
Q: 如何区分瓶颈在 CPU 还是 NIC?
- CPU 瓶颈:单核 100% 占用,速率上不去。
- NIC 瓶颈:CPU 占用不高,但速率稳定在某个物理极限(如千兆口 ~940Mbps)。
Q: 如果我只想“灌满链路”,该怎么做?
- 可以用 iperf2,它会追赶补发,更适合做极限压力测试。