redis 全局命令、数据结构和内部编码、单线程架构
欢迎拜访:雾里看山-CSDN博客
本篇主题:redis 全局命令、数据结构和内部编码、单线程架构
发布时间:2025.8.10
隶属专栏:redis

目录
- 基本的全局命令
- keys
- exists
- del
- expire
- ttl
- type
- 数据结构和内部编码
- redis的单线程架构
- 引出单线程模型
- 为什么单线程还能这么快
基本的全局命令
redis 本质是通过键值对进行存储的,不同的点在于键值对中的值可能是各种数据结构,但是对于键的处理,有一些通用的命令。
特别说明: redis的命令是不区分大小写的。
keys
功能: 用来查询当前服务器匹配的 key
通过一些特殊符号来描述key的模样,匹配上述模样的key就可以被查出来。
语法:
KEYS pattern
匹配方式:
h?llo匹配hello,hallo和hxlloh*llo匹配hllo和heeeelloh[ae]llo匹配hello和hallo但不匹配hilloh[^e]llo匹配hallo , hbllo , ...但不匹配helloh[a-b]llo匹配hallo和hbllo
命令有效版本: 1.0.0 之后
时间复杂度: O(N)
返回值: 匹配 pattern 的所有 key。
示例:
redis> MSET firstname Jack lastname Stuntman age 35
"OK"
redis> KEYS *name*
1) "firstname"
2) "lastname"
redis> KEYS a??
1) "age"
redis> KEYS *
1) "age"
2) "firstname"
3) "lastname"
特别注意:
keys命令的时间复杂度是O(N)。
在生产环境上,一般都会禁止使用keys命令,尤其是keys *(查询redis中的所有key!!!)。
在生产环境中可能会存在好多key,而redis只是一个单线程的服务器,执行keys的时间非常长,就使redis的服务器被阻塞了,无法给其他用户提供服务。这样的后果是很严重的!!!
redis经常用于做缓存,挡在mysql的前面,是替mysql负重前行的人。万一redis因为keys *命令被阻塞了,其他查询redis的操作就超时了,这些请求就会直接查询数据库,mysq突然l收到大量的请求,很有可能就挂了,这直接就会让整个系统瘫痪了!!!
exists
功能: 判断某个key是否存在
语法:
EXISTS key [key ...]
因为redis的客户端和服务器是通过网络进行通信的,这势必会影响redis的速度,所以redis的很多命令支持一次操作多个数据。
命令有效版本: 1.0.0 之后
时间复杂度: O(1)
redis在组织这些
key的时候,就是按照哈希表的方式来组织的
redis 支持很多数据结构 => 指的是一个value可以是一些复杂的数据结构,
- redis 自身的这些键值对,是通过哈希表的方式来组织的
- redis 具体到某个值,又可以是一些数据结构
返回值: key 存在的个数。
示例:
redis> SET key1 "Hello"
"OK"
redis> EXISTS key1
(integer) 1
redis> EXISTS nosuchkey
(integer) 0
redis> SET key2 "World"
"OK"
redis> EXISTS key1 key2 nosuchkey
(integer) 2
del
功能: 删除指定的 key。
语法:
DEL key [key ...]
命令有效版本: 1.0.0 之后
时间复杂度: O(1)
返回值: 删除掉的 key 的个数。
示例:
redis> SET key1 "Hello"
"OK"
redis> SET key2 "World"
"OK"
redis> DEL key1 key2 key3
(integer) 2
expire
功能: 为指定的 key 添加秒级的过期时间(Time To Live TTL)
语法:
EXPIRE key seconds
命令有效版本: 1.0.0 之后
时间复杂度: O(1)
返回值: 1 表示设置成功。0 表示设置失败。
示例:
redis> SET mykey "Hello"
"OK"
redis> EXPIRE mykey 10
(integer) 1
redis> TTL mykey
(integer) 10
补充:
expire 的单位是秒,这在计算机中是一个很长的时间。
与
expire相对的还有一个命令,那就是pexpire,该命令与expire使用方法一致,只是pexpire的过期时间是以毫秒为单位的。
ttl
功能: 获取指定 key 的过期时间,秒级。
语法:
TTL key
命令有效版本: 1.0.0 之后
时间复杂度: O(1)
返回值: 剩余过期时间。-1 表示没有关联过期时间,-2 表示 key 不存在。
示例:
redis> SET mykey "Hello"
"OK"
redis> EXPIRE mykey 10
(integer) 1
redis> TTL mykey
(integer) 10
补充:
ttl同样有一个毫秒级的命令:pttl,和ttl的差异也仅是时间单位上面的差别。
type
功能: 返回 key 对应的数据类型。
语法:
TYPE key
命令有效版本: 1.0.0 之后
时间复杂度: O(1)
返回值: none , string , list , set , zset , hash and stream 。
示例:
redis> SET key1 "value"
"OK"
redis> LPUSH key2 "value"
(integer) 1
redis> SADD key3 "value"
(integer) 1
redis> TYPE key1
"string"
redis> TYPE key2
"list"
redis> TYPE key3
"set"
数据结构和内部编码
type 命令实际返回的就是当前键的数据结构类型,它们分别是:string(字符串)、list(列表)、hash(哈希)、set(集合)、zset(有序集合),但这些只是 Redis 对外的数据结构。
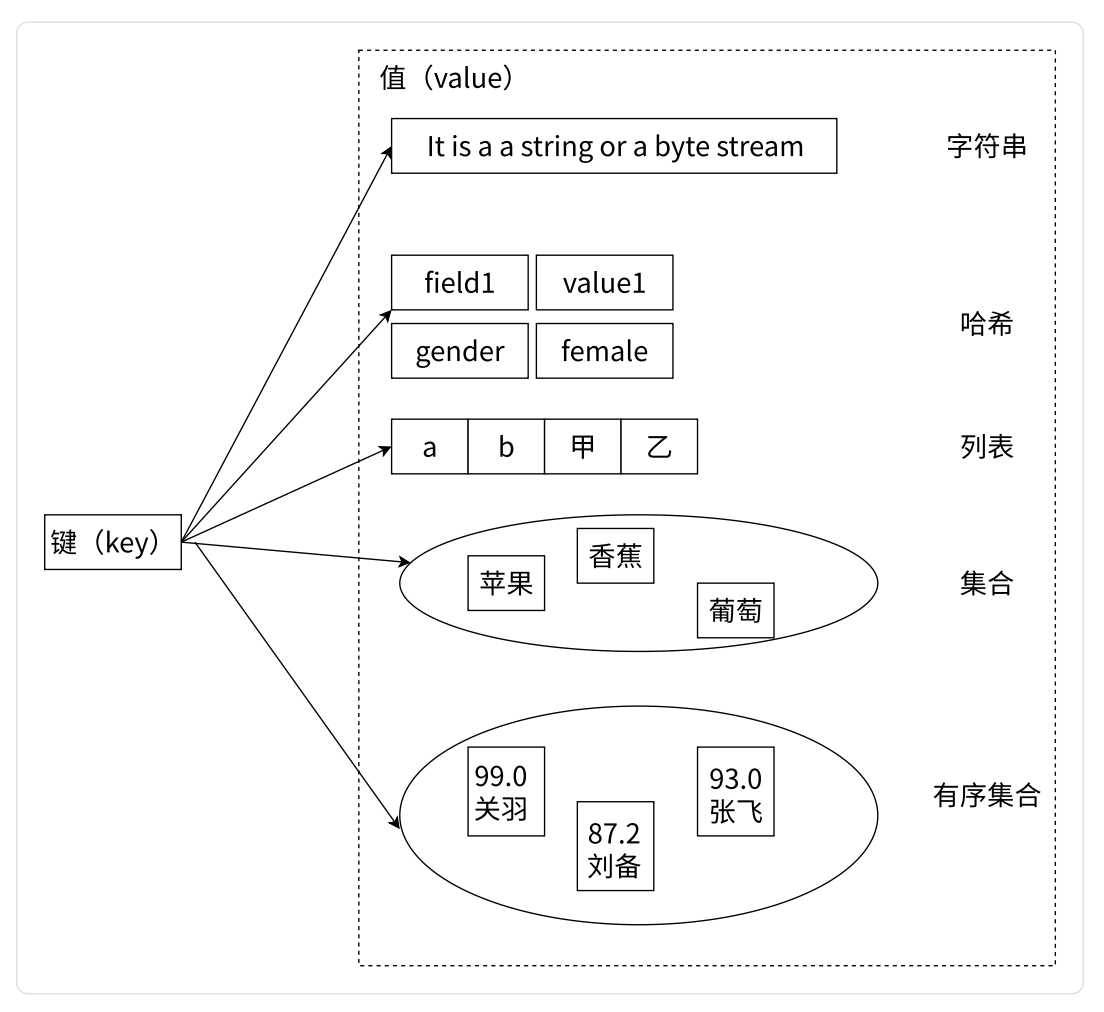
redis底层在实现这些数据结构的时候,会在源码层面,针对上述的实现进行特定的优化(内部的具体实现的编码方式会有变化),来达到 节省时间/空间 的效果。
redis 承诺,现在我这有个hash表,你进行 查询,插入,删除 操作,都保证O(1),但是,这个背后的实现,不一定就是一个标准的hash表,可能在特定场景下,使用别的数据结构实现,但是仍然保证时间复杂度符合承诺。
数据结构: redis 承诺给你的,也可以理解成数据类型
编码方式: redis内部底层的实现
同一个数据类型,背后可能的编码实现方式是不同的,会根据特定场景优化(以redis5.0为例,后续版本可能会更改)
| 数据类型 | 内部编码 |
|---|---|
| string | raw int embstr |
| hash | hashtable ziplist |
| list | linkedlist ziplist |
| set | hashtable intset |
| zset | skiplist ziplist |
可以看到每种数据结构都有至少两种以上的内部编码实现,例如 list 数据结构包含了 linkedlist 和ziplist 两种内部编码。同时有些内部编码,例如 ziplist,可以作为多种数据结构的内部实现,可以通过 object encoding 命令查询内部编码:
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> lpush mylist a b c
(integer) 3
127.0.0.1:6379> object encoding hello
"embstr"
127.0.0.1:6379> object encoding mylist
"quicklist"
redis会根据当前的实际情况去选择内部的编码方式,自动适应的,不需要记住什么时候使用哪种编码方式,了解其思想即可。
Redis 这样设计有两个好处:
- 可以改进内部编码,而对外的数据结构和命令没有任何影响,这样一旦开发出更优秀的内部编码,无需改动外部数据结构和命令,例如 Redis 3.2 提供了
quicklist,结合了ziplist和linkedlist两者的优势,为列表类型提供了一种更为优秀的内部编码实现,而对用户来说基本无感知。 - 多种内部编码实现可以在不同场景下发挥各自的优势,例如
ziplist比较节省内存,但是在列表元素比较多的情况下,性能会下降,这时候 Redis 会根据配置选项将列表类型的内部实现转换为linkedlist,整个过程用户同样无感知。
redis的单线程架构
Redis 使用了单线程架构来实现高性能的内存数据库服务,我们首先通过多个客户端命令调用的例子说明 Redis 单线程命令处理机制,接着分析 Redis 单线程模型为什么性能如此之高,最终给出为什么理解单线程模型是使用和运维 Redis 的关键。
引出单线程模型
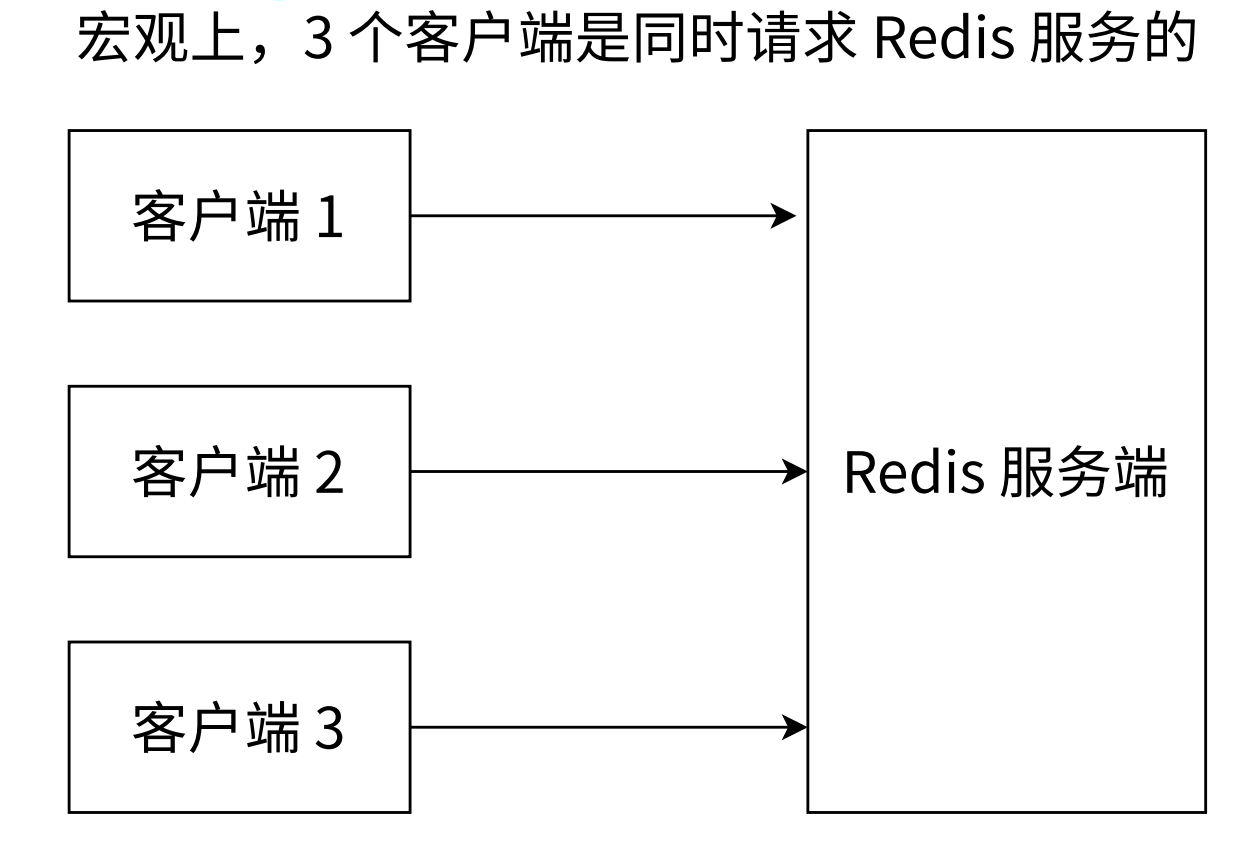
现在开启了三个 redis-cli 客户端同时执行命令。
客户端 1 设置一个字符串键值对:
127.0.0.1:6379> set hello world
客户端 2 对 counter 做自增操作:
127.0.0.1:6379> incr counter
客⼾端 3 对 counter 做自增操作:
127.0.0.1:6379> incr counter
我们已经知道从客户端发送的命令经历了: 发送命令、 执行命令、 返回结果三个阶段,其中我们重点关注第 2 步。我们所谓的 Redis 是采用单线程模型执行命令的是指:
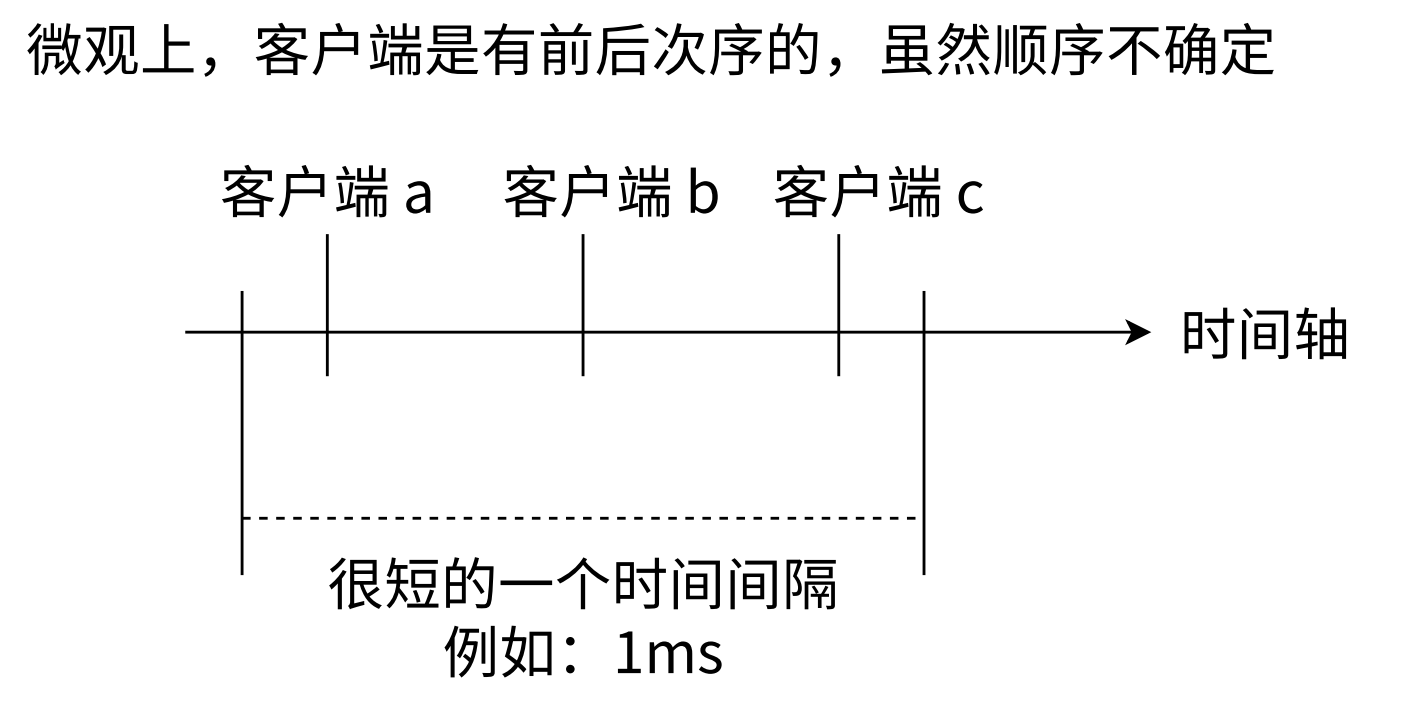
虽然三个客户端看起来是同时要求 Redis 去执行命令的,但微观角度,这些命令还是采用线性方式去执行的,只是原则上命令的执行顺序是不确定的,但一定不会有两条命令被同步执行。
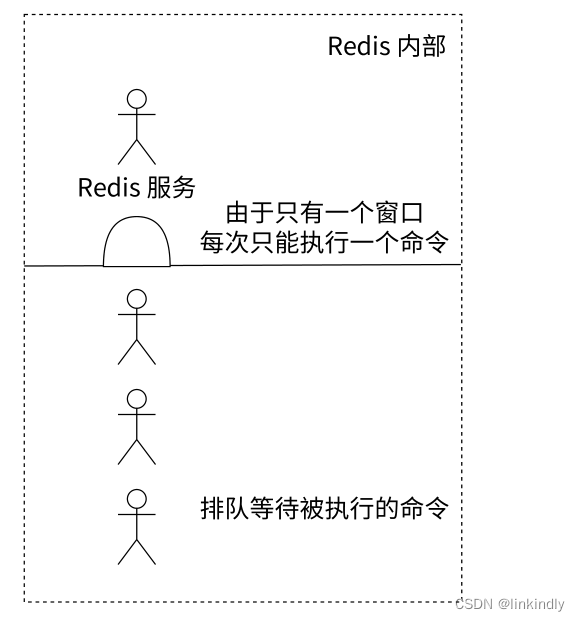
可以想象 Redis内部只有一个服务窗口,多个客户端按照它们达到的先后顺序被排队在窗口前,依次接受 Redis 的服务,所以两条 incr 命令无论执行顺序,结果一定是 2,不会发生并发问题,这个就是 Redis 的单线程执行模型。
redis的单线程模型:
为什么单线程还能这么快
特别强调:
redis只使用一个线程,处理所有的命令请求。
这并不代表redis服务器进程内部真的只有一个线程,其实也有多个线程,多个线程是在处理网络io
通常来讲,单线程处理能力要比多线程差,例如有 10 000 公斤货物,每辆车的运载能力是每次200 公斤,那么要 50 次才能完成;但是如果有 50 辆车,只要安排合理,只需要依次就可以完成任务。那么为什么 Redis 使用单线程模型会达到每秒万级别的处理能力呢?可以将其归结为三点:
- 纯内存访问。Redis 将所有数据放在内存中,内存的响应时长大约为 100 纳秒,这是 Redis 达到每秒万级别访问的重要基础。
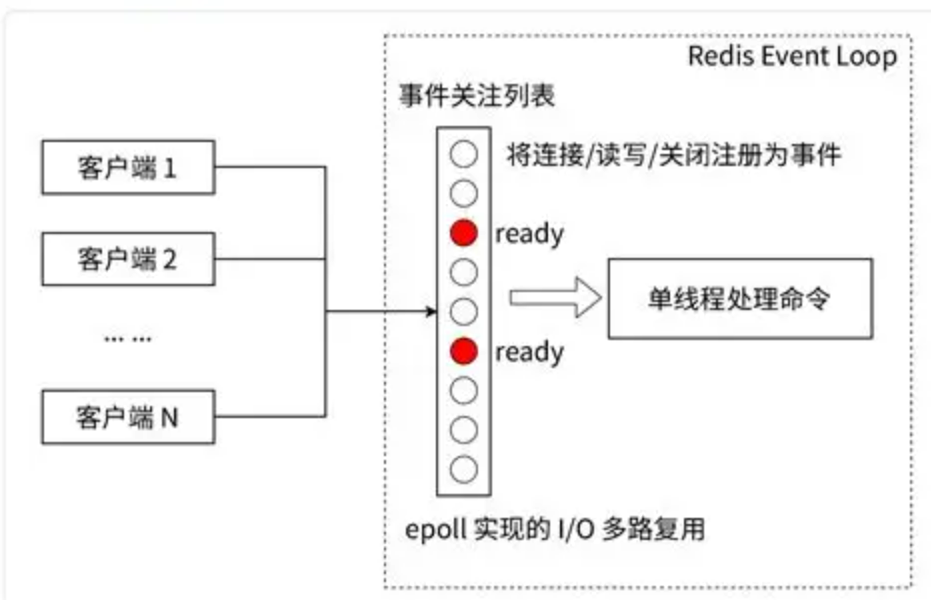
- 非阻塞 IO。Redis 使用 epoll 作为 I/O 多路复用技术的实现,再加上 Redis 自身的事件处理模型将 epoll 中的连接、读写、关闭都转换为事件,不在网络 I/O 上浪费过多的时间,如图下图所示。
- 单线程避免了线程切换和竞态产生的消耗。单线程可以简化数据结构和算法的实现,让程序模型更简单;其次多线程避免了在线程竞争同一份共享数据时带来的切换和等待消耗。
虽然单线程给 Redis 带来很多好处,但还是有一个致命的问题:对于单个命令的执行时间都是有要求的。
如果某个命令执行过长,会导致其他命令全部处于等待队列中,迟迟等不到响应,造成客户端的阻塞,对于 Redis 这种高性能的服务来说是非常严重的,所以 Redis 是面向快速执行场景的数据库。
redis能够用使用单线程模型很好的工作,原因在于redis的核心业务逻辑都是短平快的,不太消耗cpu资源也就不太吃多核了。
⚠️ 写在最后:以上内容是我在学习以后得一些总结和概括,如有错误或者需要补充的地方欢迎各位大佬评论或者私信我交流!!!