Hive【Hive架构及工作原理】


✨博客主页: https://blog.csdn.net/m0_63815035?type=blog
💗《博客内容》:.NET、Java.测试开发、Python、Android、Go、Node、Android前端小程序等相关领域知识
📢博客专栏: https://blog.csdn.net/m0_63815035/category_11954877.html
📢欢迎点赞 👍 收藏 ⭐留言 📝
📢本文为学习笔记资料,如有侵权,请联系我删除,疏漏之处还请指正🙉
📢大厦之成,非一木之材也;大海之阔,非一流之归也✨


目录
- 前言
- 一、Hive的基本概念
- 1.1Hive的交互方式
- 1.2Hive与数据库的比较
- 1.3Hive的优缺点
- 1.4Hive的应用场景
- 1.5思考题
- 二、Hive架构
- 2.1Hive架构概述
- 2.1.1客户端提交SQL
- 2.1.2Beeline的安全性
- 2.1.3使用JDBC和ODBC连接Hive
- 2.2元数据存储
- 2.3客户端安全性
- 2.4HDFS与Hive集成
- 三、Driver的工作流程
- 四、Hive的工作原理
前言
Hive 的前生属于 Facebook,用于解决海量结构化数据的统计分析,现在属于 Apache 软件基金会。Hive 是一个构建在Hadoop之上的数据分析工具(Hive 没有存储数据的能力,只有使用数据的能力),底层由 HDFS 来提供数据存储,可以将结构化的数据文件映射为一张数据库表,并且提供类似 SQL的査询功能,本质就是将 HQL 转化成 MapReduce 程序。说白了 Hive 可以理解为一个将 SOL转换为 MapReduce 程序的工具,甚至更近一步说, Hive 就是一个 MapReduce 客户端.
总结:交互方式采用 SOL,元数据存储在 Derby或 MySOL,数据存储在 HDFS,分析数据底层实现是 MapReduce,执行程序运行在 YARN 上。
一、Hive的基本概念
1.Hive的Logo:形状像蜂巢,由Hadoop的头部和蜜蜂的尾部组成,代表Hive搭建在Hadoop的HDFS之上。
2.Hive的本质:是一个计算框架,提供类似SQL的查询功能,将SQL转换为MapReduce程序。
3.Hive的历史:由Facebook开发并开源贡献给Apache,用于处理海量数据。

1.1Hive的交互方式
1.Hive的交互方式:通过SQL进行交互,类似于SQL Boy。
2.原数据存储:存储在Hadoop的HDFS中,文件形式存在。
3.底层计算框架:默认使用MapReduce,但可替换为Tez或Spark。
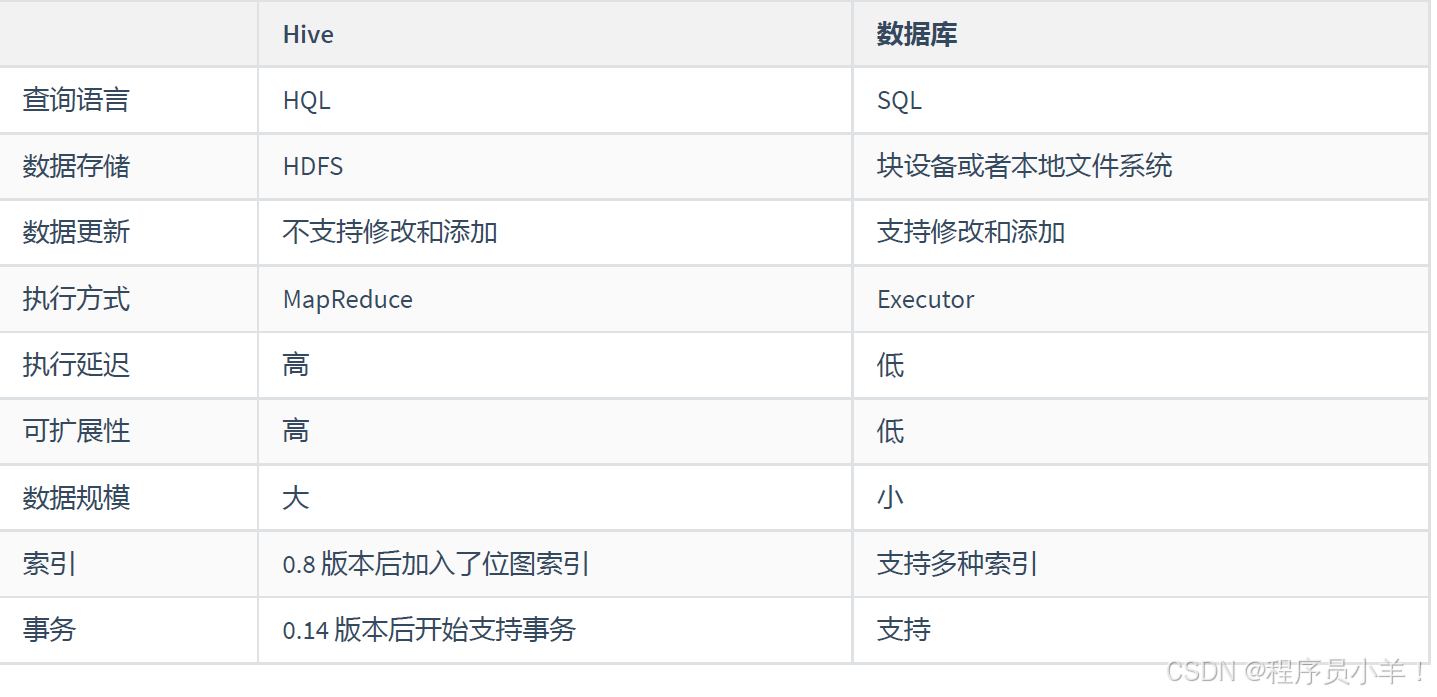
1.2Hive与数据库的比较
1.数据存储:Hive数据存储在HDFS中,不支持修改和添加;数据库支持CRUD操作。
2.执行延迟:Hive执行延迟高,适用于离线处理;数据库执行延迟低,适用于实时处理。
3.可扩展性:Hive具有较高的可扩展性,支持底层计算引擎的替换;数据库可扩展性较低。
4.数据规模:Hive适用于海量数据处理;数据库适用于小规模数据。
1.3Hive的优缺点
1.优点:学习成本低,减少开发人员学习Java等语言的时间。
2.缺点:SQL表达能力有限,复杂查询优化困难;底层基于MapReduce,执行延迟高,不适合交互式查询。
1.4Hive的应用场景
1.日志分析:通过Hive进行海量日志数据的离线分析。
2.离线数仓:构建离线数据仓库,处理海量结构化数据。
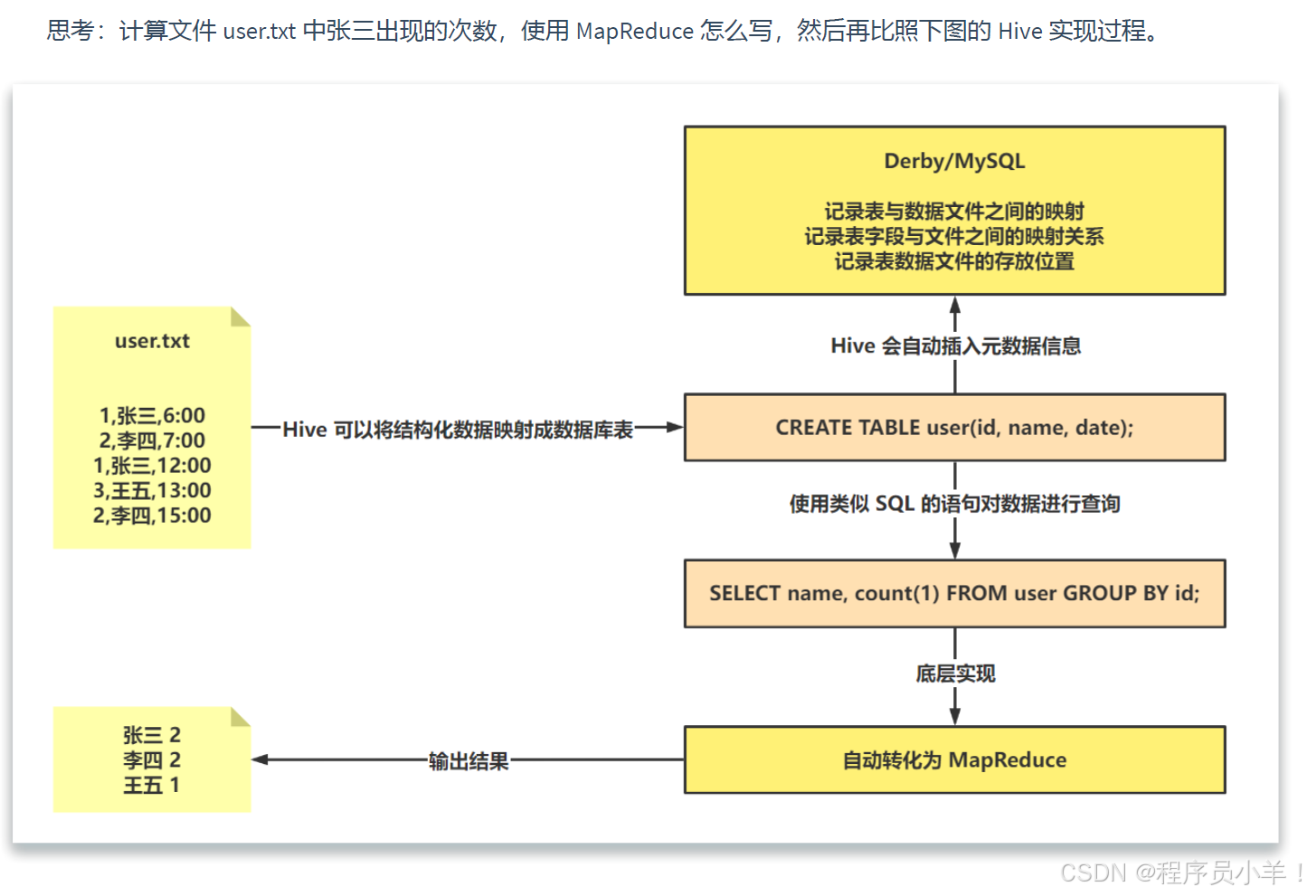
1.5思考题
二、Hive架构
2.1Hive架构概述
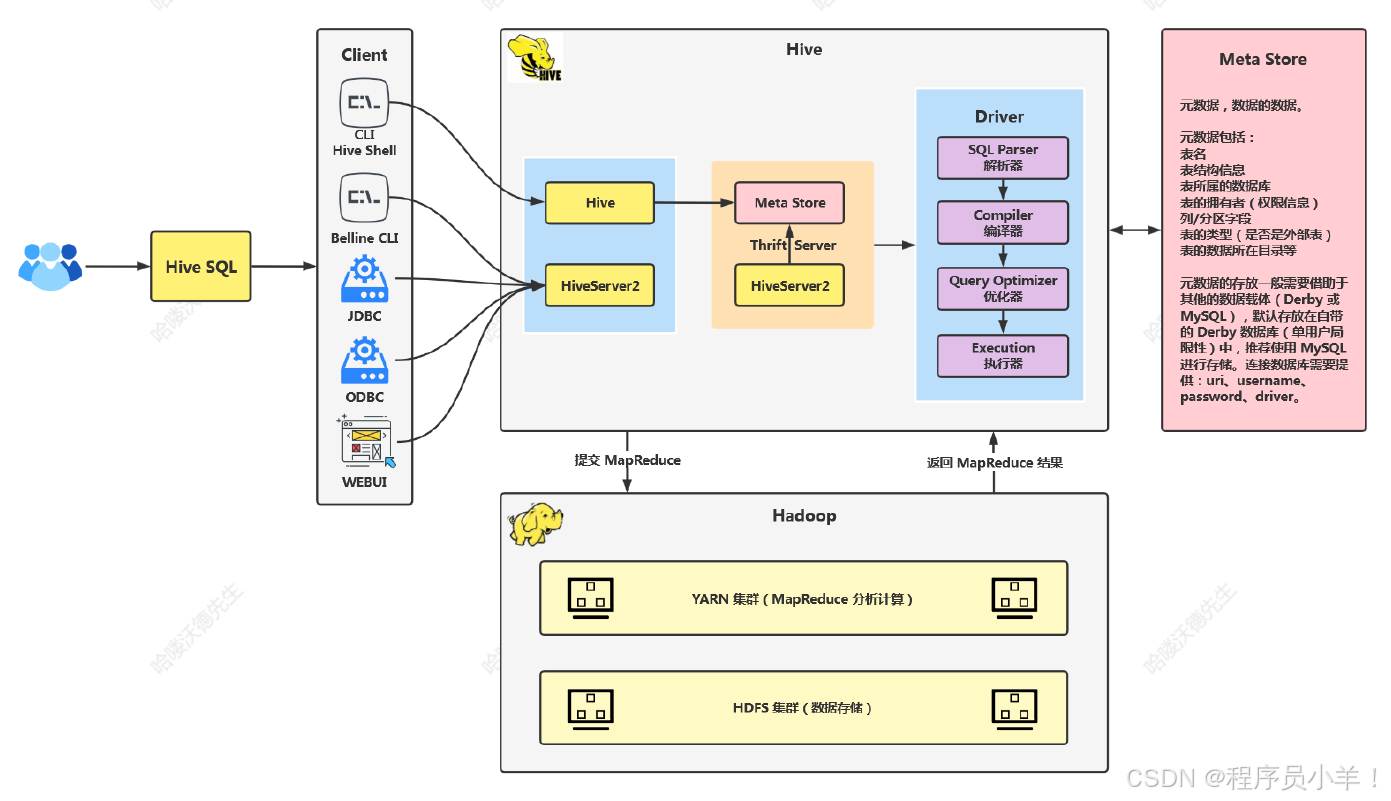
1.Hive架构重要组成部分为Driver。
2.架构图简单,无需详细拆解。

2.1.1客户端提交SQL
1.大数据程序员通过客户端提交SQL。
2.Hive提供Shell界面,可直接在界面中编写和执行SQL。
3.Beeline是一个第三方工具,可用于提交SQL到Hive。
2.1.2Beeline的安全性
1.Beeline起到转发作用,保护底层的Hive。
2.通过Beeline连接,不容易被攻击者直接获取Hive核心信息。
3.Beeline使用了一层额外的加密和转发,增加了安全性。
2.1.3使用JDBC和ODBC连接Hive
1.使用JAVA代码和C语言代码通过JDBC和ODBC连接Hive。
2.可通过IDEA等工具添加Hive相关依赖,使用JDBC代码连接。
3.Hive提供了Web UI,可通过HTTP协议访问。
2.2元数据存储
1.元数据存储表名、列名、字段映射等信息。
2.学习环境中,Hive使用自带的Derby数据库存储元数据。
3.生产环境中,推荐使用外部数据库如MySQL、PostgreSQL等存储元数据。
2.3客户端安全性
1.客户端连接元数据时需要输入用户名、密码、URL等信息。
2.不安全的客户端可能导致敏感信息泄露,被攻击者利用。
3.Hive提供了安全的连接方式,如Hive over 2,增加了连接的安全性。
2.4HDFS与Hive集成
1.HDFS存储Hive的数据文件。
2.Hive通过元数据与HDFS集成,找到数据文件的映射关系。
3.解析、编译、优化和执行等步骤将SQL转换为MapReduce任务在YARN集群上执行。
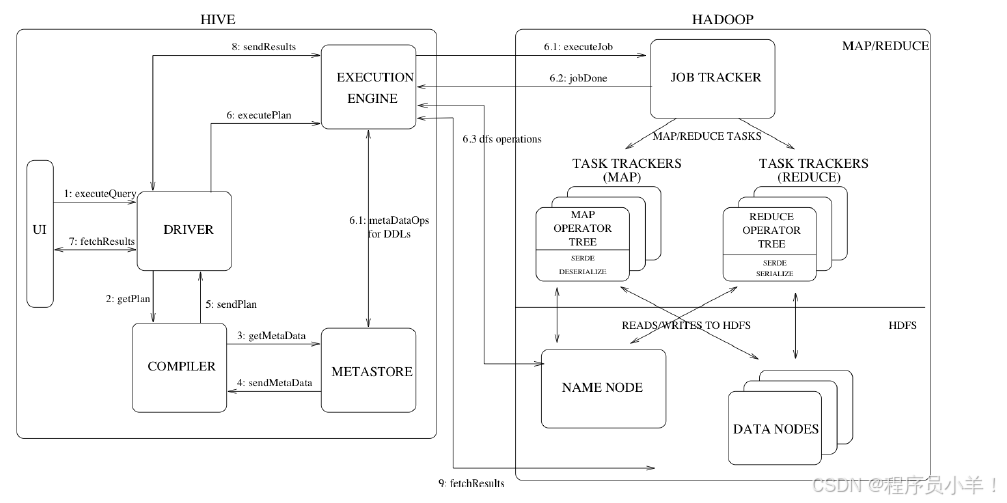
三、Driver的工作流程
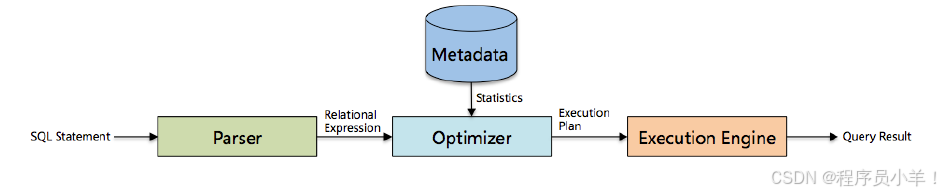
1.Driver包含解析器、编译器、优化器和执行器四大核心组件。
2.解析器校验表名和列名是否存在。
3.编译器将SQL编译成执行语法树。
4.优化器进行基于规则(RBU)和基于代价(CPU)的优化。
5.执行器将优化后的SQL转换为MapReduce任务在YARN集群上执行。
四、Hive的工作原理
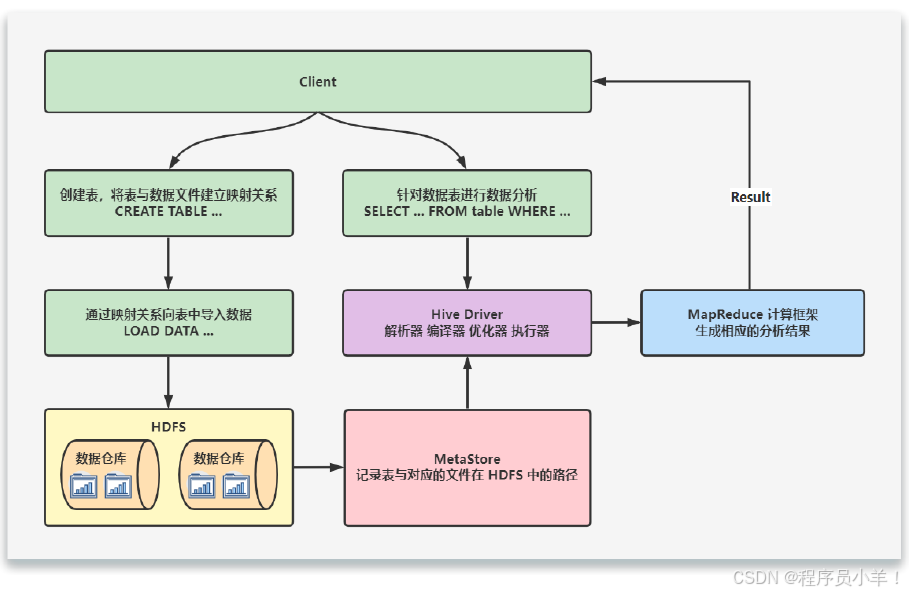
当创建表的时候,需要指定 HDFS 文件路径,表和其文件路径会保存到Metastore,从而建立表和数据的映射关系。当数据加载入表时,根据映射获取到对应的 HDFS 路径,将数据导入。
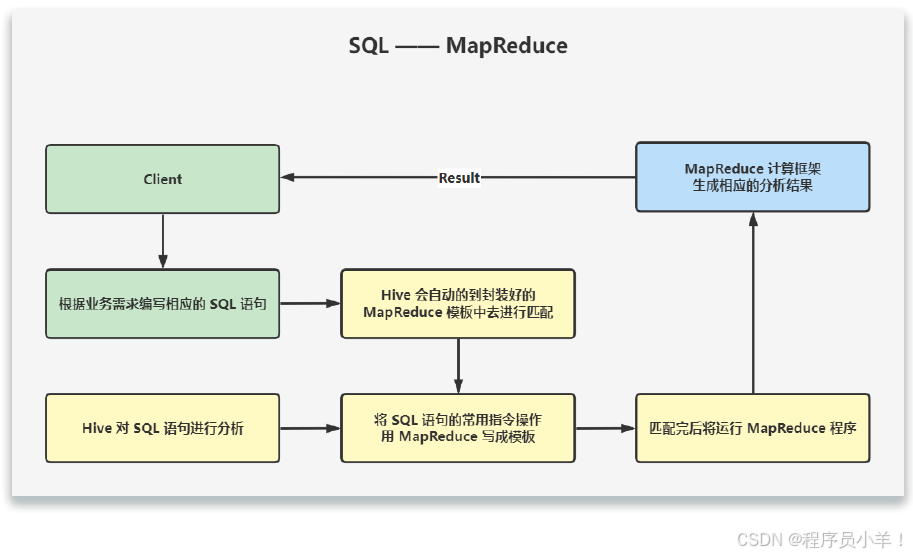
用户输入SQL后,Hive 会将其转换成 MapReduce 或者 Spark 任务,提交到 YARN 上执行,执行成功将返回结果。

今天这篇文章就到这里了,大厦之成,非一木之材也;大海之阔,非一流之归也。感谢大家观看本文
