FP16 和 BF16
FP16 和 BF16介绍
FP16 和 BF16 是两种不同的 16位浮点数精度格式,主要用于深度学习训练和推理中的数值计算,以节省内存和计算资源。以下是它们的详细解释和区别:
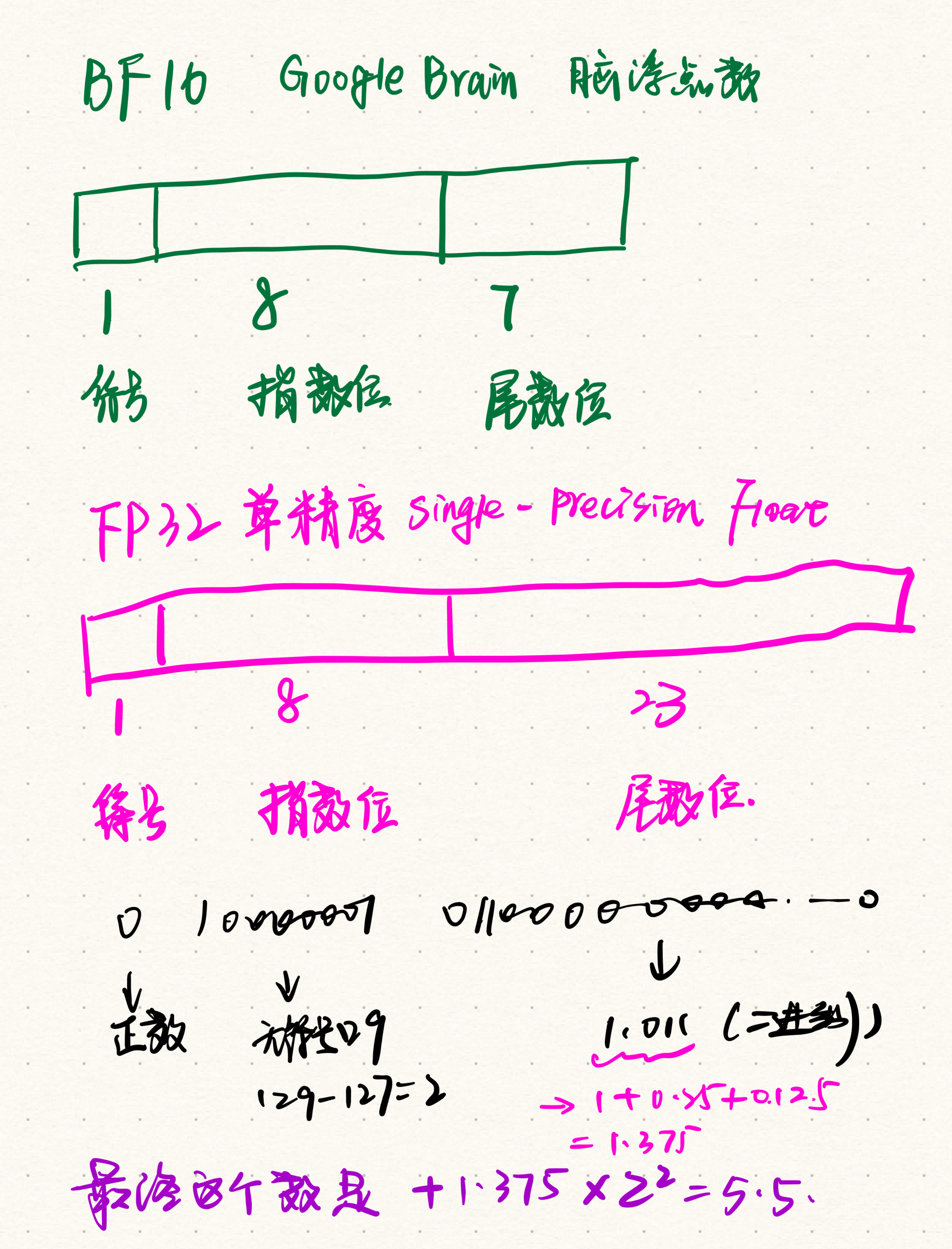
1. FP16(Half Precision, 16-bit Floating Point)
全称:IEEE 754-2008 标准中的 16位浮点数(Float16)。
结构:
1位 符号位(Sign)
5位 指数位(Exponent)
10位 尾数位(Mantissa/Fraction)
动态范围:约 5.96×10−85.96×10−8 到 6550465504。
特点:
节省内存(比FP32减少50%),适合计算密集型任务(如GPU推理)。
缺点:指数位较少(5位),动态范围有限,在训练中容易因梯度值过小(下溢出)或过大(上溢出)导致数值不稳定,通常需要配合混合精度训练(Mixed Precision)使用(如NVIDIA的AMP)。
2. BF16(Brain Floating Point, BFloat16)
全称:由Google Brain提出的 16位脑浮点数(BFloat16)。
结构:
1位 符号位(Sign)
8位 指数位(Exponent)
7位 尾数位(Mantissa/Fraction)
动态范围:与FP32一致(约 1.18×10−381.18×10−38 到 3.39×10383.39×1038)。
特点:
指数位与FP32相同(8位),牺牲尾数精度换取更大的动态范围,更适合深度学习训练。
硬件支持:Intel(Xeon CPUs)、NVIDIA(Ampere架构GPU如A100)、TPU等。
无需复杂的混合精度技术即可稳定训练。
3. 核心区别
| 特性 | FP16 | BF16 |
|---|---|---|
| 指数位 | 5位(范围小) | 8位(与FP32一致) |
| 尾数位 | 10位(精度较高) | 7位(精度较低) |
| 动态范围 | 较小(易溢出) | 与FP32相同(更稳定) |
| 典型用途 | 推理、混合精度训练 | 训练(尤其硬件支持时) |
4. 为什么深度学习需要它们?
FP16:适合推理(对精度要求较低),需注意溢出问题。
BF16:更适合训练,因其动态范围大,能直接替代FP32的指数部分,减少数值不稳定。
硬件适配:新一代GPU(如NVIDIA Ampere)和TPU对BF16有原生支持,效率更高。
总结
选择FP16还是BF16取决于任务和硬件支持:
推理场景:FP16更常见(节省资源)。
训练场景:BF16逐渐成为主流(尤其在大模型中)。
微调一个大模型,该选用哪一种精度?
1. 基座模型的精度是否影响微调?
有关系,但并非绝对绑定。基座模型的权重精度(如FP32/FP16/BF16)会影响微调的初始状态,但微调时可以选择不同的精度格式(需注意兼容性):
如果基座模型是FP32:微调时转为FP16/BF16通常没问题(需缩放学习率)。
如果基座模型是BF16:建议微调时保持BF16(避免精度转换损失)。
如果基座模型是FP16:需谨慎,FP16的动态范围较小,可能不适合直接微调(尤其是大模型)。
2. FP16 vs BF16 在微调中的选择
| 场景 | FP16 | BF16 |
|---|---|---|
| 硬件支持 | 广泛支持(NVIDIA/AMD GPU) | 需较新硬件(Ampere GPU、TPU、Intel CPU) |
| 数值稳定性 | 易溢出(需混合精度/梯度缩放) | 更稳定(动态范围大,接近FP32) |
| 内存占用 | 与BF16相同(比FP32节省50%) | 与FP16相同 |
| 适用阶段 | 推理或小规模微调 | 大模型微调的首选(尤其LLM、多模态模型) |
推荐选择:
优先BF16(如果硬件支持):
大模型微调通常需要更大的动态范围(如梯度更新时的数值波动),BF16的8位指数能避免FP16的溢出问题,减少调试成本。FP16仅限特定场景:
如果硬件不支持BF16,或微调任务非常轻量(如小参数量模型、短时间微调),可用FP16+混合精度(需监控梯度溢出)。
3. 实际微调中的注意事项
(1)与基座模型精度的对齐
理想情况:微调精度与基座模型一致(如基座是BF16,微调也用BF16)。
若基座是FP32,微调时转为BF16通常比FP16更安全(因指数位与FP32一致)。
例外:如果基座模型本身用FP16训练(罕见),需额外测试微调时的数值稳定性。
(2)硬件兼容性
NVIDIA GPU:
支持FP16(Pascal架构及以上)。
支持BF16(Ampere架构及以上,如A100、RTX 30/40系列)。
其他硬件:TPU、Intel Sapphire Rapids CPU等对BF16有优化。
(3)学习率与优化器
BF16/FP16的梯度范围与FP32不同,需调整学习率(通常更小)或使用自适应优化器(如AdamW)。
FP16可能需要梯度裁剪(Gradient Clipping)和损失缩放(Loss Scaling)。
(4)监控与调试
检查梯度溢出:在FP16中更常见,训练时需监控
NaN或异常损失值。日志记录:记录权重和梯度的分布(如TensorBoard),确保数值健康。
4. 典型工作流示例
以微调LLaMA-2(基座模型通常为BF16)为例:
确认硬件:使用A100/H100 GPU或TPU(支持BF16)。
加载模型:直接以BF16精度加载基座模型。
微调配置:
优化器:AdamW(学习率比FP32更小,如
1e-5)。混合精度:无需(BF16本身已足够稳定)。
监控:检查梯度是否正常,避免权重溢出。
总结
在微调(Fine-tuning)大模型时,精度格式的选择(FP16/BF16)需要结合基座模型的原始精度、硬件支持、训练稳定性以及任务需求来综合考虑。以下是关键因素和具体建议:
首选BF16:大模型微调的主流选择,尤其基座模型本身是BF16/FP32时。
FP16备用:仅在硬件不支持BF16或轻量微调时使用,需配合混合精度技术。
基座模型精度:尽量保持一致,若不一致需测试稳定性(FP32→BF16通常安全,FP16→BF16需谨慎)。
最终建议在实际任务中用小批量数据试跑,对比两种精度的收敛性和稳定性。
混合精度技术具体怎么训练?
混合精度训练(Mixed Precision Training)是一种通过组合不同数值精度(如FP16和FP32)来加速深度学习训练并减少显存占用的技术,同时保持模型的训练稳定性。其核心思想是“用FP16加速计算,用FP32保持精度”。以下是其具体实现和工作原理的详细说明:
1. 为什么需要混合精度?
FP16的问题:
动态范围小:容易发生梯度下溢出(接近0时舍入为0)或上溢出(超出范围变为
NaN)。精度损失:尾数位较少,对小幅值权重/梯度更新不敏感。
解决方案:
用FP16存储权重、激活值和梯度,加速计算。
用FP32维护一份“主权重副本”(Master Weights)用于梯度更新,避免精度损失。
2. 混合精度训练的关键步骤
以下是典型的混合精度训练流程(以NVIDIA的AMP为例):
(1)模型初始化
主权重(Master Weights):以FP32格式初始化模型参数。
计算副本:同步创建FP16格式的模型副本,用于前向和反向传播。
(2)前向传播(FP16)
输入数据转换为FP16。
模型计算(矩阵乘法、卷积等)全部使用FP16,加速运算。
输出损失值:保持FP16或FP32(根据实现不同)。
(3)反向传播(FP16)
计算梯度时使用FP16,显存占用减少50%。
梯度可能溢出:FP16的梯度值过小会被舍入为0(下溢出),过大则变为
NaN(上溢出)。
(4)梯度裁剪与损失缩放(Loss Scaling)
损失缩放(Loss Scaling):
在计算损失函数后,将损失值乘以一个缩放因子(如
S=1024),放大梯度值,避免下溢出。反向传播后,梯度会同步放大
S倍,再通过optimizer.step()更新前除以S恢复实际值。自动调整缩放因子:监控梯度是否存在
NaN,动态调整S(如NVIDIA的AMP库)。
梯度裁剪(Gradient Clipping):防止放大后的梯度爆炸。
(5)权重更新(FP32)
FP32主权重更新:
将FP16的梯度转换为FP32,用于更新FP32的主权重。
更新后的FP32权重再转换为FP16,用于下一轮计算。
优化器状态:如Adam的动量(momentum)和方差(variance)通常用FP32存储。
3. 混合精度训练的实现方式
(1)手动实现
需要手动管理FP16/FP32的转换、损失缩放和梯度裁剪(代码复杂,易出错)。
示例代码片段:
model = model.float() # 主权重FP32
model_half = model.half() # FP16计算副本optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
scaler = torch.cuda.amp.GradScaler() # 自动损失缩放for input, target in data:optimizer.zero_grad()with torch.cuda.amp.autocast(): # 自动转换为FP16计算output = model_half(input)loss = loss_fn(output, target)scaler.scale(loss).backward() # 缩放损失并反向传播scaler.step(optimizer) # 更新FP32主权重scaler.update() # 调整缩放因子(2)自动混合精度(AMP)
使用框架提供的工具(如PyTorch的
AMP、TensorFlow的MixedPrecision)自动化流程:# PyTorch AMP model = model.cuda() optimizer = torch.optim.Adam(model.parameters()) scaler = torch.cuda.amp.GradScaler()for input, target in data:optimizer.zero_grad()with torch.cuda.amp.autocast():output = model(input)loss = loss_fn(output, target)scaler.scale(loss).backward()scaler.step(optimizer)scaler.update()
4. 混合精度 vs 纯BF16训练
| 特性 | 混合精度(FP16+FP32) | 纯BF16训练 |
|---|---|---|
| 显存占用 | 比FP32节省约50% | 同FP16(节省50%) |
| 计算速度 | 比FP32快(依赖Tensor Core) | 同FP16 |
| 数值稳定性 | 需损失缩放和梯度裁剪 | 更稳定(动态范围接近FP32) |
| 硬件要求 | 支持FP16的GPU(如Pascal+) | 需支持BF16(Ampere+、TPU) |
| 适用场景 | 旧硬件或FP16优化的模型 | 新硬件大模型训练 |
5. 实际应用建议
优先尝试纯BF16(如果硬件支持):
无需混合精度,动态范围大,调试更简单(如H100/A100/TPU)。
旧硬件或FP16优化模型:
使用混合精度(FP16+FP32),启用AMP自动管理。
调试技巧:
监控梯度中
NaN的出现频率。初始缩放因子(
scaler)可设为2^10(1024),根据训练动态调整。如果损失不下降,可能是梯度下溢出(尝试增大缩放因子)。
总结
混合精度训练通过FP16计算+FP32存储,在速度和显存之间取得平衡,而BF16因其更大的动态范围逐渐成为新硬件的首选。选择哪种技术取决于硬件支持和模型需求。对于微调大模型,若硬件允许,直接使用BF16是更简单的方案;若受限,则需依赖混合精度技术。