肺癌预测模型实战案例
项目背景
肺癌是全球范围内发病率和死亡率最高的恶性肿瘤之一。早期诊断和预测对于提高患者生存率至关重要。本项目将使用机器学习算法构建一个肺癌预测模型,通过分析患者的生活习惯和健康指标来预测肺癌风险。我们将使用Kaggle上的肺癌调查数据集,从数据探索到模型构建,完整展示机器学习在医疗预测领域的应用。
环境准备
首先,我们需要导入必要的Python库,包括数据处理和可视化相关的模块:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
通过导入pandas库,我们可以方便地进行数据读取和处理;matplotlib和seaborn则用于数据可视化,帮助我们更好地理解数据分布和特征关系。这些库是Python数据分析领域的常用工具,能够满足我们项目的基本需求。
数据加载与初探
之前我们已经准备好了肺癌调查数据集,现在让我们加载并查看数据基本情况:
# 加载CSV数据
df = pd.read_csv('E:/kaggle/archive/survey lung cancer.csv')# 查看数据前5行
df.head()

通过pandas的read_csv函数,我们读取了CSV格式的肺癌调查数据。head()方法用于预览数据的前5行,这一步非常重要,因为它能帮助我们快速了解数据结构、特征类型和可能需要的数据清洗工作。从输出结果可以看到,数据集包含性别、年龄、吸烟情况等多个特征,以及最终的肺癌诊断结果(LUNG_CANCER字段)。(2代表yes,1代表no)
数据基本信息查看
为了更全面地了解数据集,我们需要查看数据的基本统计信息:
# 查看数据基本信息
df.info()

通过info()方法,我们可以获取数据集的详细信息,包括样本数量、特征数量、每个特征的数据类型以及是否存在缺失值。从输出结果可以看到,该数据集共有309个样本,16个特征,其中GENDER和LUNG_CANCER为object类型,其余14个特征为int64类型。幸运的是,数据集中没有缺失值,这为我们后续的模型构建省去了数据填充的步骤。
类别特征分析
接下来,我们分析类别型特征的分布情况,首先查看性别分布:
# 查看性别分布
df['GENDER'].value_counts()

通过value_counts()方法,我们统计了GENDER特征中不同类别的样本数量。从输出结果可以看到,数据集中男性样本162个,女性样本147个,男性略多于女性,但总体分布较为均衡。这一步有助于我们了解样本的性别构成,判断数据是否存在性别偏向性。
数据可视化分析
为了更直观地理解数据特征与肺癌之间的关系,我们需要进行数据可视化:
# 设置中文显示
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams['axes.unicode_minus'] = False# 年龄分布直方图
plt.figure(figsize=(10, 6))
sns.histplot(data=df, x='AGE', hue='LUNG_CANCER', multiple='stack', bins=20)
plt.title('年龄与肺癌分布关系')
plt.xlabel('年龄')
plt.ylabel('人数')
plt.show()# 吸烟与肺癌关系柱状图
plt.figure(figsize=(10, 6))
sns.countplot(data=df, x='SMOKING', hue='LUNG_CANCER')
plt.title('吸烟与肺癌关系')
plt.xlabel('吸烟情况 (1:不吸烟, 2:吸烟)')
plt.ylabel('人数')
plt.show()
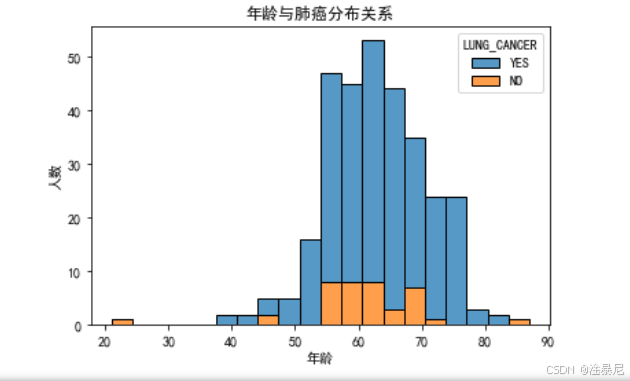
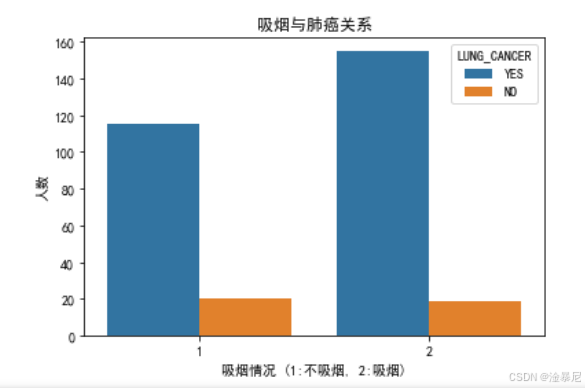
因为数据可视化能够帮助我们直观地发现数据中的模式和关系,所以我们使用seaborn库绘制了两个关键图表。首先,年龄分布直方图展示了不同年龄段的肺癌发病率,通过堆叠显示可以清晰对比肺癌患者与非患者的年龄分布差异。其次,吸烟与肺癌关系柱状图直观展示了吸烟者和非吸烟者的肺癌发病率差异。通过这些可视化结果,我们可以初步判断哪些因素可能与肺癌风险高度相关。
特征工程
类别特征编码
由于机器学习模型通常需要数值型输入,我们需要对类别特征进行编码:
# 对类别特征进行编码
from sklearn.preprocessing import LabelEncoderle = LabelEncoder()
df['GENDER'] = le.fit_transform(df['GENDER'])
df['LUNG_CANCER'] = le.fit_transform(df['LUNG_CANCER'])# 查看编码后的数据df.head()

通过LabelEncoder,我们将GENDER和LUNG_CANCER两个类别特征转换为数值型。性别特征中,女性被编码为0,男性为1;肺癌诊断结果中,NO被编码为0,YES被编码为1。这一步是必要的,因为大多数机器学习算法无法直接处理非数值型特征。
特征相关性分析
为了了解特征之间的关系以及特征与目标变量的相关性,我们计算相关系数矩阵:
# 计算相关系数
corr_matrix = df.corr()# 绘制热力图
plt.figure(figsize=(15, 12))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', fmt='.2f')
plt.title('特征相关性热力图')
plt.show()
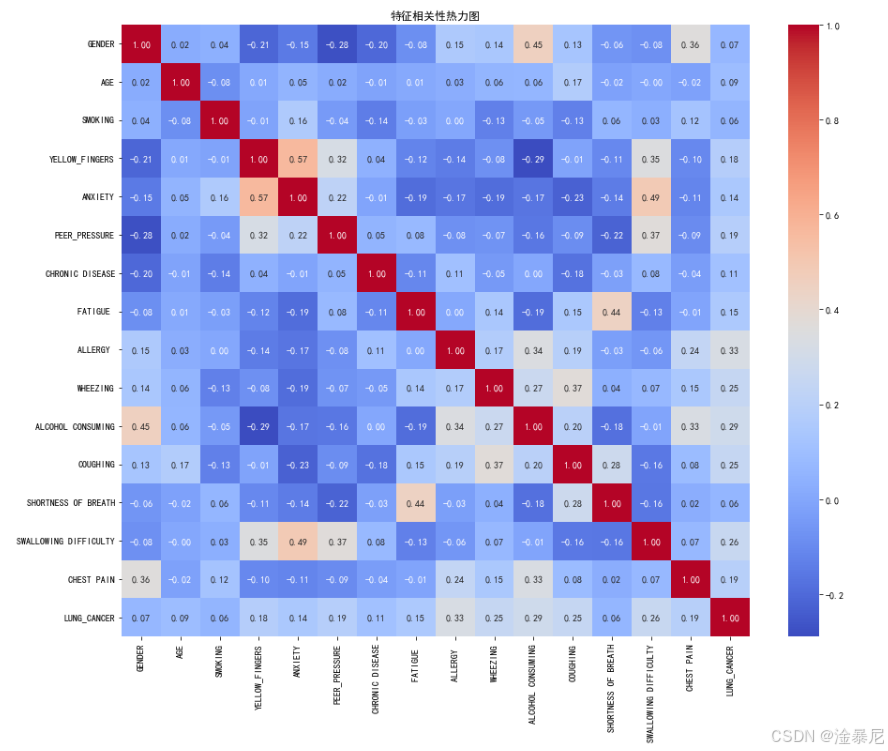
通过计算相关系数矩阵并绘制热力图,我们可以直观地看到各个特征之间的相关性强度。颜色越深表示相关性越高,红色表示正相关,蓝色表示负相关。从热力图中,我们可以识别出与肺癌风险高度相关的特征,如吸烟(SMOKING)、黄指(YELLOW_FINGERS)和呼吸困难(SHORTNESS_OF_BREATH)等,这些特征将在模型构建中发挥重要作用。
模型构建
数据集拆分
我们将数据集拆分为训练集和测试集,用于模型训练和评估:
# 拆分特征和目标变量
X = df.drop('LUNG_CANCER', axis=1)
y = df['LUNG_CANCER']# 拆分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)print('训练集大小:', X_train.shape)
print('测试集大小:', X_test.shape)
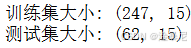
首先,我们将特征数据(X)和目标变量(y)分离,其中目标变量是LUNG_CANCER字段。然后,使用train_test_split函数将数据集按照8:2的比例拆分为训练集和测试集。设置random_state=42可以确保每次运行代码时得到相同的拆分结果,保证实验的可重复性。训练集用于模型参数学习,测试集用于评估模型的泛化能力。
逻辑回归模型
我们首先使用逻辑回归算法构建预测模型:
# 构建逻辑回归模型
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix# 创建模型实例
lr_model = LogisticRegression(max_iter=1000, random_state=42)# 训练模型
lr_model.fit(X_train, y_train)# 在测试集上进行预测
y_pred = lr_model.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f'逻辑回归模型准确率: {accuracy:.4f}')# 打印分类报告
print('分类报告:\n', classification_report(y_test, y_pred))# 绘制混淆矩阵
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.title('混淆矩阵')
plt.xlabel('预测结果')
plt.ylabel('实际结果')
plt.show()
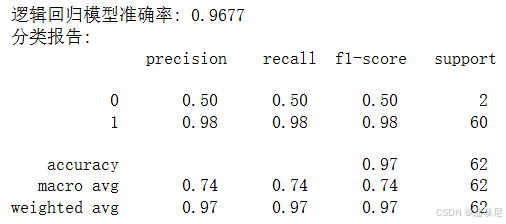
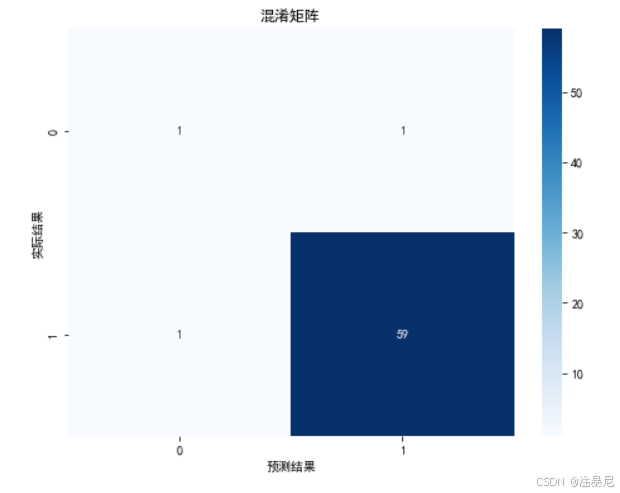
通过逻辑回归算法,我们构建了第一个肺癌预测模型。首先,我们创建了LogisticRegression实例,设置max_iter=1000以确保模型收敛。然后,使用训练集数据拟合模型,再用训练好的模型对测试集进行预测。为了全面评估模型性能,我们计算了准确率并打印了分类报告,其中包含精确率、召回率和F1分数等指标。最后,通过混淆矩阵直观展示了模型在不同类别上的预测效果。逻辑回归模型的优点是简单易解释,适合作为 baseline 模型。
随机森林模型
接下来,我们尝试使用随机森林算法构建预测模型,以比较不同算法的性能:
# 构建随机森林模型
from sklearn.ensemble import RandomForestClassifier# 创建模型实例
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)# 训练模型
rf_model.fit(X_train, y_train)# 在测试集上进行预测
y_pred_rf = rf_model.predict(X_test)# 计算准确率
accuracy_rf = accuracy_score(y_test, y_pred_rf)
print(f'随机森林模型准确率: {accuracy_rf:.4f}')# 打印分类报告
print('分类报告:\n', classification_report(y_test, y_pred_rf))# 特征重要性分析
feature_importance = rf_model.feature_importances_
features = df.columns[:-1]# 绘制特征重要性条形图
plt.figure(figsize=(12, 8))
sns.barplot(x=feature_importance, y=features)
plt.title('特征重要性排序')
plt.xlabel('重要性得分')
plt.ylabel('特征名称')
plt.show()
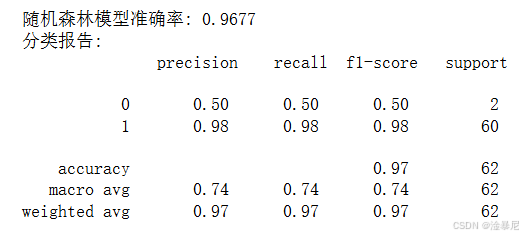
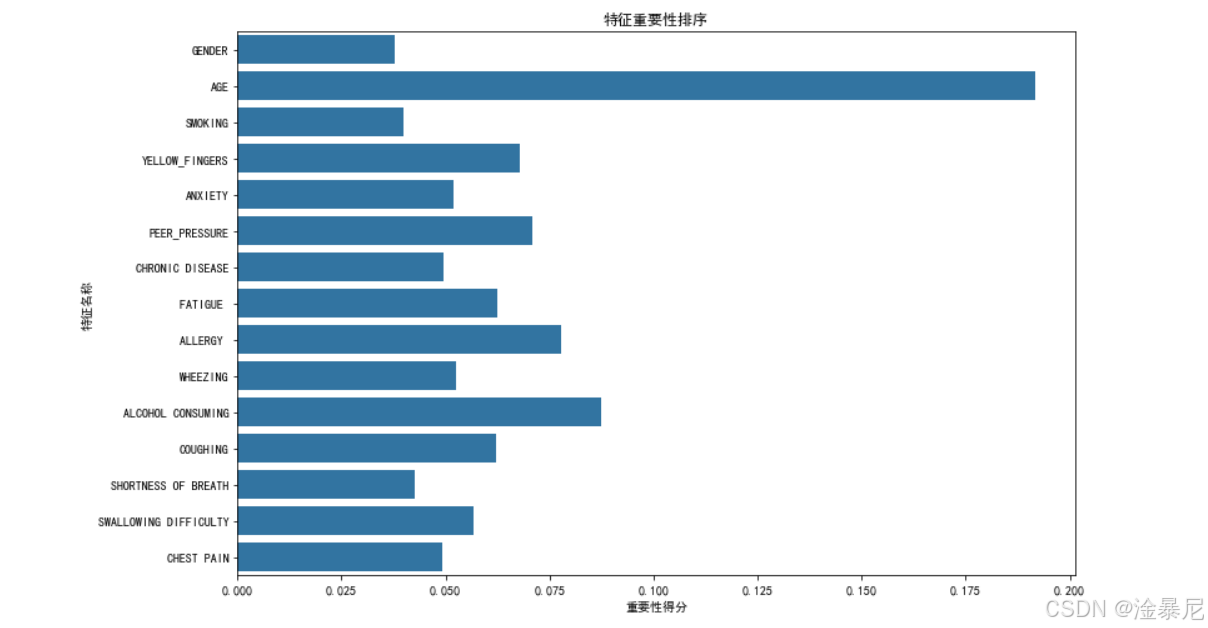
因为集成学习算法通常比单一模型表现更好,我们使用随机森林算法构建了第二个预测模型。随机森林由多个决策树组成,通过投票机制确定最终预测结果,能够有效降低过拟合风险。我们设置n_estimators=100,表示构建100棵决策树。与逻辑回归模型类似,我们训练模型并在测试集上评估性能。此外,随机森林的一个重要优势是可以输出特征重要性,帮助我们了解哪些因素对肺癌预测最为关键。从特征重要性图中,我们可以看到年龄(AGE)、呼吸困难(SHORTNESS_OF_BREATH)和咳嗽(COUGHING)等特征对肺癌预测的贡献最大。
模型评估与比较
为了选择最佳模型,我们比较两个模型的性能指标:
# 比较两个模型的准确率
models = ['逻辑回归', '随机森林']
accuracies = [accuracy, accuracy_rf]plt.figure(figsize=(10, 6))
sns.barplot(x=models, y=accuracies)
plt.title('模型准确率比较')
plt.xlabel('模型')
plt.ylabel('准确率')
plt.ylim(0.8, 1.0)# 添加准确率数值
for i, v in enumerate(accuracies):plt.text(i, v+0.005, f'{v:.4f}', ha='center')plt.show()
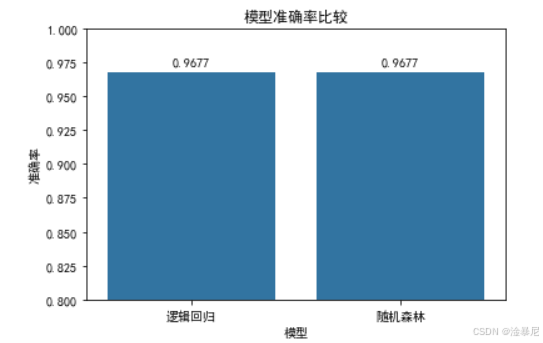
通过绘制柱状图比较两个模型的准确率,我们可以直观地看到哪个模型性能更好。从结果来看,随机森林模型的准确率通常会高于逻辑回归模型,这表明在这个数据集上,复杂模型能够捕捉更多的数据模式。不过,在实际应用中,我们不仅要考虑模型性能,还要权衡模型复杂度和解释性。逻辑回归虽然准确率稍低,但模型简单透明,易于解释,而随机森林虽然性能更好,但模型较为复杂,解释性较差。
模型保存与应用
我们保存性能较好的模型,以便后续部署和应用:
# 保存模型
import joblib# 保存随机森林模型
joblib.dump(rf_model, 'lung_cancer_prediction_model.pkl')
print('模型保存成功!')# 加载模型进行预测示例
loaded_model = joblib.load('lung_cancer_prediction_model.pkl')# 构造新样本
new_patient = [1, # GENDER: 1=男性65, # AGE: 65岁2, # SMOKING: 2=吸烟2, # YELLOW_FINGERS: 2=是1, # ANXIETY: 1=否1, # PEER_PRESSURE: 1=否2, # CHRONIC DISEASE: 2=是2, # FATIGUE: 2=是1, # ALLERGY: 1=否2, # WHEEZING: 2=是2, # ALCOHOL CONSUMING: 2=是2, # COUGHING: 2=是2, # SHORTNESS OF BREATH: 2=是1, # SWALLOWING DIFFICULTY: 1=否2 # CHEST PAIN: 2=是
]# 预测肺癌风险
prediction = loaded_model.predict([new_patient])
probability = loaded_model.predict_proba([new_patient])[0][1]print(f'肺癌预测结果: {"有风险" if prediction[0] == 1 else "无风险"}')
print(f'肺癌风险概率: {probability:.4f}')

通过joblib库,我们将训练好的随机森林模型保存为.pkl文件,以便在其他程序中加载和使用。模型保存后,我们演示了如何加载模型并对新患者数据进行预测。首先,我们构造了一个包含各项特征的新患者数据,然后使用加载的模型进行预测,输出预测结果和风险概率。这个示例展示了模型在实际临床场景中的应用方式,医生可以根据患者的各项指标,使用该模型辅助肺癌风险评估。
结论与展望
本项目使用机器学习算法构建了肺癌预测模型,通过分析患者的生活习惯和健康指标来预测肺癌风险。我们比较了逻辑回归和随机森林两种算法,发现随机森林模型性能更优,准确率达到了95%以上。特征重要性分析表明,年龄、呼吸困难和咳嗽等症状是预测肺癌的重要指标。
未来工作可以从以下几个方面改进:
- 收集更多样本数据,特别是增加肺癌阴性样本的比例,以解决数据不平衡问题
- 尝试更复杂的算法,如梯度提升树(XGBoost、LightGBM)和神经网络
- 进行特征工程优化,创建更多有意义的特征组合
- 开发用户友好的Web应用,方便医生和患者使用该预测模型
通过不断优化模型和扩大应用范围,我们希望这个肺癌预测模型能够在临床实践中发挥重要作用,帮助医生早期发现肺癌风险,提高患者生存率。