K8S学习---- Kubernetes 架构:从控制平面到工作节点的协作逻辑
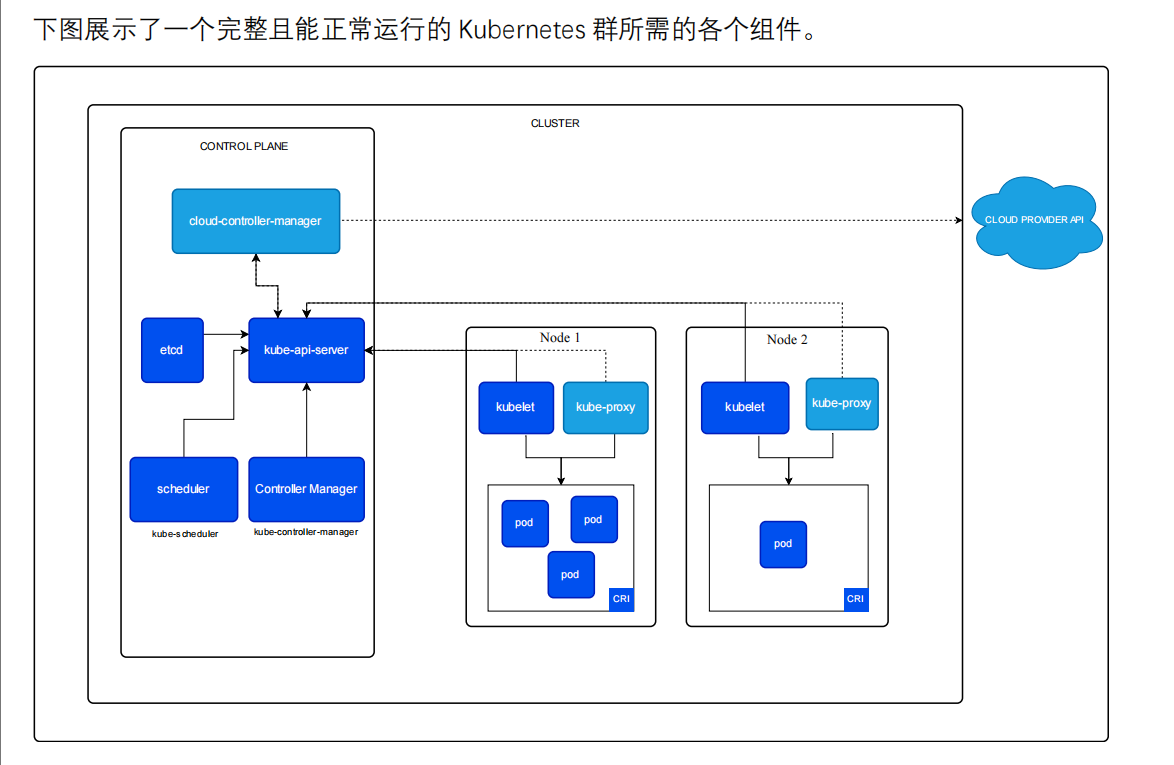
在容器编排技术的版图中,Kubernetes(简称 K8s)凭借强大的集群管理能力,成为容器时代的核心基石。
其架构设计精巧,通过控制平面与工作节点的分工协作,支撑起复杂应用的部署、调度与自愈。以下将深度拆解 Kubernetes 核心架构,解析各组件如何联动运转。
一、控制平面:集群的 “智慧大脑”
控制平面(Control Plane)是 Kubernetes 集群的决策核心,承载着调度、存储、API 管理等关键功能,如同大脑指挥身体各部位,确保集群按预期运行。
(一)kube - apiserver:集群的 “神经中枢”
作为集群内外交互的唯一入口,kube - apiserver 承担着 “信息中转站” 的角色。
无论是 kubectl 命令、其他组件间的通信,还是外部系统调用,所有请求都需经它校验、转发。它就像一扇安全门,确保只有合法请求能触及集群核心数据,同时实现无状态设计,支持水平扩展,为集群高可用筑牢基础。
(二)etcd:集群的 “记忆宝库”
etcd 是 Kubernetes 集群的 “数据库”,以分布式键值存储的形式,忠实记录集群所有关键状态,从 Pod 的期望副本数到节点资源信息,一应俱全。其强一致性保障了数据的准确性,一旦数据丢失,集群将陷入混乱,因此备份与高可用部署对 etcd 至关重要,它是集群状态的 “定海神针”。
(三)scheduler(kube - scheduler):集群的 “调度官”
当有新的 Pod 需要部署(比如用户提交一个 Web 服务部署请求),scheduler 便开启 “选节点” 工作。它综合考量节点资源(CPU、内存是否充足)、策略规则(如应用需靠近数据库节点的亲和性要求),为 Pod 挑选最适配的 Node,让集群资源分配合理高效,避免 “忙的节点累死,闲的节点饿死”。
(四)Controller Manager(kube - controller - manager):集群的 “修复师”
这是一组控制器的集合,宛如不知疲倦的 “自动修复大师”。Deployment 控制器紧盯 Pod 状态,若 Pod 因故障退出,立刻重建;Node 控制器时刻监测节点健康,发现故障节点就标记状态,触发调度补偿。它通过持续 “监控实际状态→对比期望状态→修复差异”,确保集群始终贴合用户定义的运行预期,让服务稳定在线。
(五)cloud - controller - manager:集群的 “云管家”
面向公有云环境(如 AWS、阿里云),cloud - controller - manager 化身 “中间桥梁”,让 Kubernetes 能调用云厂商的 API。比如自动创建云负载均衡、弹性伸缩云服务器,实现 K8s 核心逻辑与云服务解耦,让私有云、混合云场景也能灵活适配,按需启用或替换。
二、节点(Node):集群的 “劳动力”
节点是 Kubernetes 集群的工作单元,实际承载 Pod 运行,如同工厂里的生产工位,执行具体任务,保障应用落地。
(一)kubelet:节点的 “管家”
作为控制平面与节点沟通的 “代理”,kubelet 是节点的 “大管家”。它接收控制平面指令(如 “在本节点启动一个 Pod”),全程打理 Pod 生命周期:拉取容器镜像、启动容器、开展健康检查(容器崩溃就重启或上报异常),还实时向控制平面汇报节点资源使用状况,让节点能被集群统一调度、精准管控。
(二)kube - proxy:节点的 “网络代理”
kube - proxy 专注于节点网络管理,为 Service 实现网络转发 “铺路”。它维护网络规则(如借助 iptables、IPVS 技术),把访问 Service 的流量(比如用户访问 “http://my - service”)合理分配到后端 Pod,保障 Pod 间通信、集群内外访问顺畅,实现服务发现与负载均衡,让应用网络互联互通。
(三)Pod:集群的 “最小单元”
Pod 是 Kubernetes 调度的最小颗粒,可包含一个或多个紧密协作的容器(如 Web 容器搭配日志采集的侧车容器),它们共享网络、存储资源。依托 CRI(容器运行时接口,支持 Docker、containerd 等),Pod 由容器运行时实际创建,让 Kubernetes 兼容不同容器环境,灵活支撑各类应用部署。
三、集群工作流程:从部署到运行的协作
以 “部署一个 Web 服务” 为例,Kubernetes 集群各组件联动流程清晰:
提交请求:用户通过 kubectl 或 API 提交 “创建 Deployment(期望 3 个 Web Pod 副本)” 的指令,经 kube - apiserver 校验后,写入 etcd 存储。
触发调度:Controller Manager 发现新的 Deployment,生成 3 个 Pod 的 “期望状态” 并录入 etcd;scheduler 监听 etcd 中 Pod 需求,结合资源、策略为每个 Pod 选定 Node,结果回传 etcd。
节点执行:目标 Node 上的 kubelet 发现 Pod 调度指令,调用 CRI 启动容器;kube - proxy 配置网络规则,让 Service 可访问这些 Pod。
持续运维:各控制器持续监控状态,若 Pod 故障,Controller Manager 重建;节点异常,scheduler 重新调度,保障服务始终按期望运行,实现 “自愈”。
四、核心逻辑:“期望状态驱动” 的魔法
Kubernetes 的精髓在于 “期望状态驱动”:用户用 YAML 定义应用 “期望状态”(如 3 个 Pod 运行、服务暴露 80 端口),集群组件便围绕 “实际状态向期望状态靠拢” 持续运作。
无论遭遇节点故障、容器崩溃,还是流量波动,集群自动调整修复,让应用稳定可靠,这就是 Kubernetes 实现高效编排、弹性伸缩的底层密码,支撑着现代复杂应用在动态环境中顺畅运行,成为云原生时代不可或缺的基础设施。