【重建技巧】Urban Scene Reconstruction-LoD细节提升

主页:Robust and Efficient 3D Gaussian Splatting for Urban Scene Reconstruction
暨南大学城市级场景LoD工作,使用了类似block gaussian的分块技巧以及很多现有可以增加模型质量、训练效率的技巧,这篇工作带给我们很多训练城市场景的经验。
abstract
我们提出了一种新型框架,能够实现城市级场景的快速重建与实时渲染,同时有效抵御多视角采集中的外观变异问题。该框架采用以下创新设计:首先通过基于可见度的图像选择策略进行场景分区并行训练,显著提升训练效率;其次引入可控细节层次(LoD)机制,在用户定义的资源预算下精准调控高斯密度分布,兼顾训练效率与视觉保真度;再者设计外观变换模块,在消除图像间外观差异负面影响的同时支持灵活调整。此外,我们整合深度正则化、尺度正则化和抗锯齿等增强模块来提升重建精度。实验结果表明,本方法在城市级场景重建任务中,无论在效率还是质量方面均显著优于现有技术方案。
1. Introduction
城市级场景重建在自动驾驶[13,27]、城市规划[25]和数字孪生[6]等领域具有关键作用,已成为研究热点。最新提出的3D高斯泼溅(3DGS)[8]采用显式3D椭圆高斯体表征场景,既能实现基于图像集的高保真重建,又支持实时渲染。
3DGS利用高效光栅化实现快速重建与实时渲染。但其显式表征会随场景规模增大导致空间复杂度上升,例如重建MipNeRF360[1]中_Bicycle_这样的360°无界户外场景需要超600万高斯体,在24GB GPU上超过1100万高斯体就会出现内存溢出(OOM)。虽然增大内存可暂时缓解OOM问题,但过量高斯体会加重光栅化负担并延长训练时间,使实时渲染难以实现。
城市级数据集通常具有更复杂的采集条件限制[3,21,41]。时间因素(如昼夜、季节)、天气模式和传感器配置的差异会导致同一物体出现显著外观差异。此外还经常捕捉到行人车辆等瞬态元素。3DGS[8]容易通过引入仅对齐极少数训练视角的冗余高斯基元来过度拟合这些局部变化,但这些冗余高斯体在新视角渲染时会呈现漂浮伪影和结构不一致,严重影响重建质量。
为此,我们提出专为城市场景重建设计的新型高效鲁棒3DGS方法。基于原始3DGS框架,我们在各阶段引入多项改进以实现高效高质量重建与实时渲染。
提升重建效率:我们扩展Block-NeRF[41],提出基于可见度的图像选择机制以减少数据预处理冗余(3.2节)。同时改进致密化策略,将计算资源集中于各分区内部,避免无关区域冗余计算(3.3节)。为实现有限资源下的实时渲染,提出新型自底向上LOD生成策略,每层级在预设预算内构建并继承前一层级,有效控制训练资源消耗。该策略在保持优于剪枝/压缩方法质量的同时显著提升效率。渲染时采用LOD切换策略动态选择层级,实现有限资源下的实时性能(3.4节)。
提升重建质量:设计外观变换模块学习消除图像间物体外观差异的影响,重建完成后支持灵活调整场景外观且不影响渲染速度。此外提出尺度和深度正则化来减少漂浮物和伪影(3.5节)。
实验表明本方法在重建质量、资源效率和渲染速度上均超越现有方法,可实现任意规模城市场景重建。主要贡献包括:
- 提出基于可见度的数据划分策略和分区优先致密化方法
- 设计可控LOD生成策略实现有限资源下的动态LOD选择与实时渲染
- 开发细粒度外观变换模块,在保持实时性的同时增强对图像间外观差异的鲁棒性
2. Related Works
Block-NeRF[41]和Mega-NeRF[42]采用人工分治策略;Switch-NeRF[57]改用可学习门控网络;BungeeNeRF[45]通过动态添加模块实现多细节层级渐进重建。但这些NeRF类方法在渲染速度和重建质量上仍存在明显局限。
近期有工作将3DGS扩展至大规模场景。Grendel-GS[56]依赖多GPU解决资源限制;VastGaussian[16]采用分治策略结合CNN色彩变换,但未解决实时渲染问题;Hierarchical-3DGS[9]和CityGaussian[18]引入LOD策略,但缺乏训练阶段的资源控制机制,依赖后处理压缩和精细调参,在大型场景中不可避免地导致质量下降。
3. Method
3.1. Preliminary

3.2 Scene and Data Division
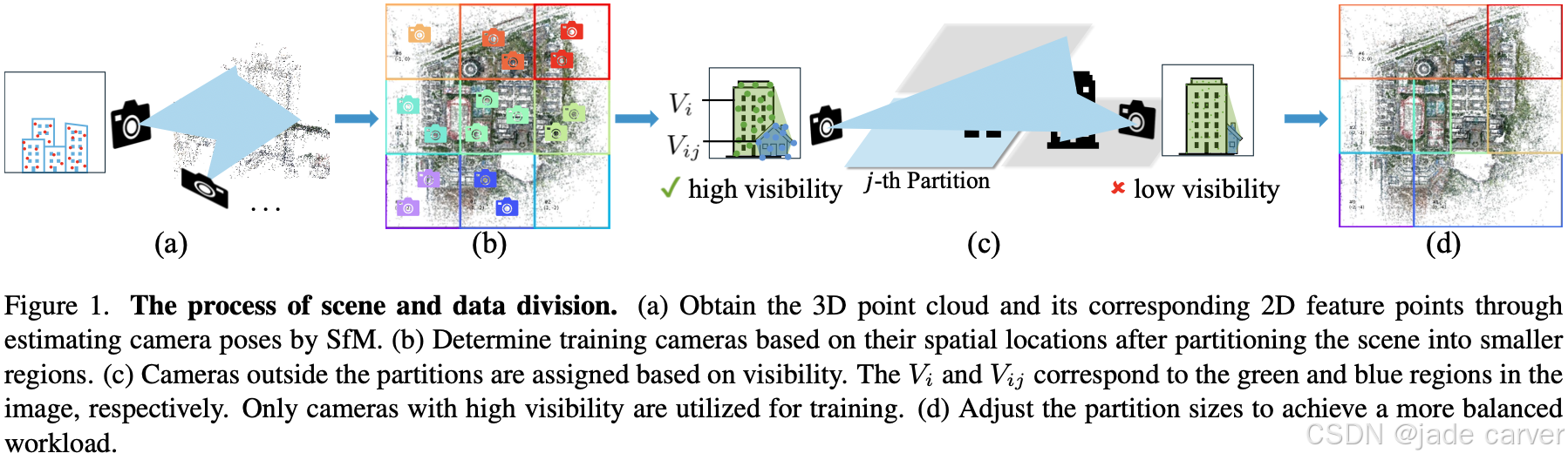
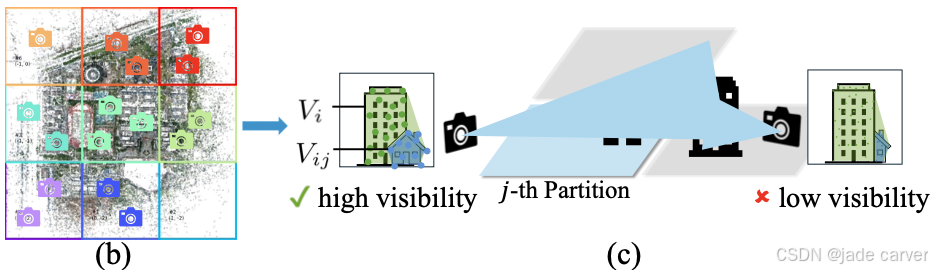
我们对场景进行水平分区,并将训练图像分配至对应分区。初始分配基于图像空间位置:当图像![]() 的位置落在第j个分区的边界框内时,即被分配至该分区。对于位于边界框外的图像,我们基于其相对于分区的点可见性计算结果来确定分配关系,该策略如图1所示。
的位置落在第j个分区的边界框内时,即被分配至该分区。对于位于边界框外的图像,我们基于其相对于分区的点可见性计算结果来确定分配关系,该策略如图1所示。
3.2.1. Point-based Visibility
可见度的计算基于三维点云及其与二维特征点的关联关系,两者均通过运动恢复结构(SfM)技术生成。假定已经按照空间位置均匀的把稀疏点云进行了分块。
对于未选中的图像![]() ,首先把稀疏点云投影到
,首先把稀疏点云投影到![]() 的图像平面上(注意是从点云按照相机pose投影出来的一个离散点图片,不是原图像
的图像平面上(注意是从点云按照相机pose投影出来的一个离散点图片,不是原图像![]() ),然后计算图片上离散点围成的凸包面积为Vi:仔细观察下图,楼和小房子对应的点围成了一个凸包,这个就是点云通过pose投射到图像平面上点围出来的凸包,而且可以看到凸包是把楼和房子全部围住的,不是规则的楼+房子的形状,另外注意这个图中,楼和房子的轮廓是作者为了解释清楚按照而图片描出来的!点云投影不可能把边界都投的这么完美!
),然后计算图片上离散点围成的凸包面积为Vi:仔细观察下图,楼和小房子对应的点围成了一个凸包,这个就是点云通过pose投射到图像平面上点围出来的凸包,而且可以看到凸包是把楼和房子全部围住的,不是规则的楼+房子的形状,另外注意这个图中,楼和房子的轮廓是作者为了解释清楚按照而图片描出来的!点云投影不可能把边界都投的这么完美!


随后利用图像![]() 的二维特征点与三维点之间的对应关系,提取出投影图中对应的、第j个分区内的特征点,进而计算这些特征点的凸包面积Vij。最终,可见度通过Vij与Vi的比值确定。这里暂时称比值为图像
的二维特征点与三维点之间的对应关系,提取出投影图中对应的、第j个分区内的特征点,进而计算这些特征点的凸包面积Vij。最终,可见度通过Vij与Vi的比值确定。这里暂时称比值为图像![]() 在区块j中对应的可见度,显然可见度如果高于一定阈值,那么图像
在区块j中对应的可见度,显然可见度如果高于一定阈值,那么图像![]() 就属于该区块。
就属于该区块。
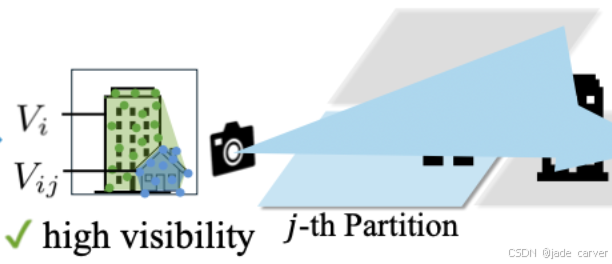
由于特征点本身具备遮挡感知特性,该方法仅考虑可见区域,从而有效避免冗余图像选择,在相同训练迭代次数下实现更高质量的重建效果。比如,下图中该图片对应的相机位置在前面那张图的另外一侧,所以,按照规矩计算的、在分块j中的可见度较低,故分块j中不应该包含此图。
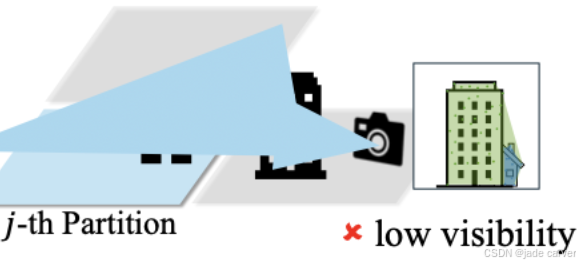
总体来说,这个过程是基于点云凸包面积计算可见度,以确定图像及其pose信息是否包含于某一个区块。对比于之前的block gaussian里基于单个图像对应的点中 属于某一个分块的点的数量、与单个图像所有对应点数量的比值计算该图像是否属于该区块的方法类似。
不同的是block gaussian整体的分块过程是基于一个二叉树的。

3.2.2. Partition Rebalancing
在实际应用中,中心分区通常比边缘分区包含更多高可见度图像,这会导致工作量分配不均。为解决该问题,我们在基于可见度的数据划分后进行分区大小调整:将图像过少的分区与最小的相邻分区合并,而对图像过多的分区则进行细分。该过程循环迭代,直至图像分布达到相对均衡状态。
3.3In-Partition Prioritized Densification


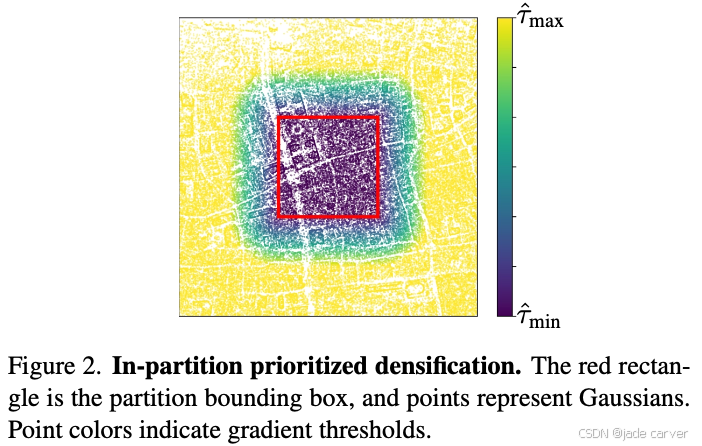

2. 为什么会导致分区内高斯体外溢?
补偿机制示意图
分区边界
├─ 分区内(正常优化)
│ ├─ 高斯体A(拟合不足)
│ └─ 高斯体B(已收敛)
└─ 分区外(高阈值τ_high)└─ 高斯体C(被抑制优化)

3.4. Controllable Level-of-detail
原始3DGS的致密化策略[8]缺乏资源约束机制,难以适用于城市级场景。为此,我们扩展了工作[20]的可控致密化策略,采用自底向上的方式生成多级细节层次(LOD),同时严格遵循预设资源限制。在渲染阶段,系统动态选择适当的细节层级,从而确保高效的实时渲染性能。
3.4.1. Controllable Detail Level Generation

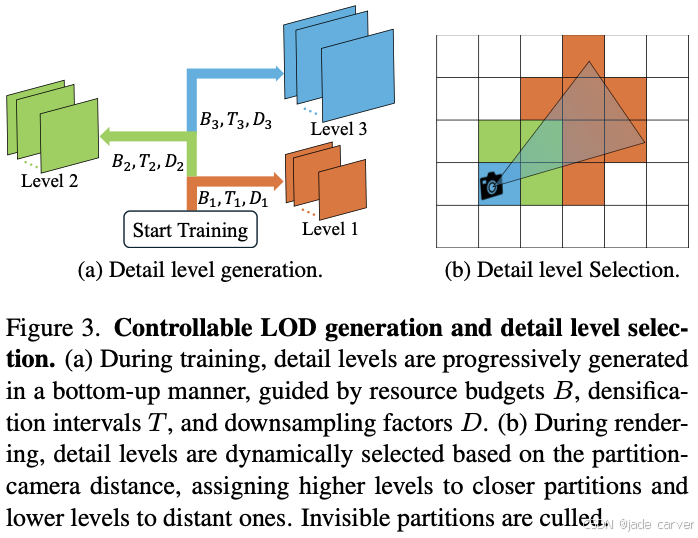
3.4.2 细节层级选择策略
在渲染阶段,我们采用CityGaussian[18]提出的分区级细节选择方案(如图3b所示)。为优化渲染效率,同时引入StopThePop[31]的基于图块剔除机制,自动忽略贡献度较低的高斯体。
3.5. Quality Enhancements
3.5.1节设计的外观变换模块通过特征解耦实现了对图像外观变化的鲁棒适应;其次,针对局部过拟合和伪影问题,3.5.2节与3.5.3节分别提出了基于尺度约束和深度一致性的双重正则化方法;进一步地,3.5.4节采用频域感知的抗锯齿技术显著提升了高频细节的保真度;最后,3.5.5节开发的瞬态物体滤除机制有效消除了行人、车辆等非静态要素的干扰。这套组合方案从特征表达、几何优化、渲染增强三个维度协同提升了重建质量。
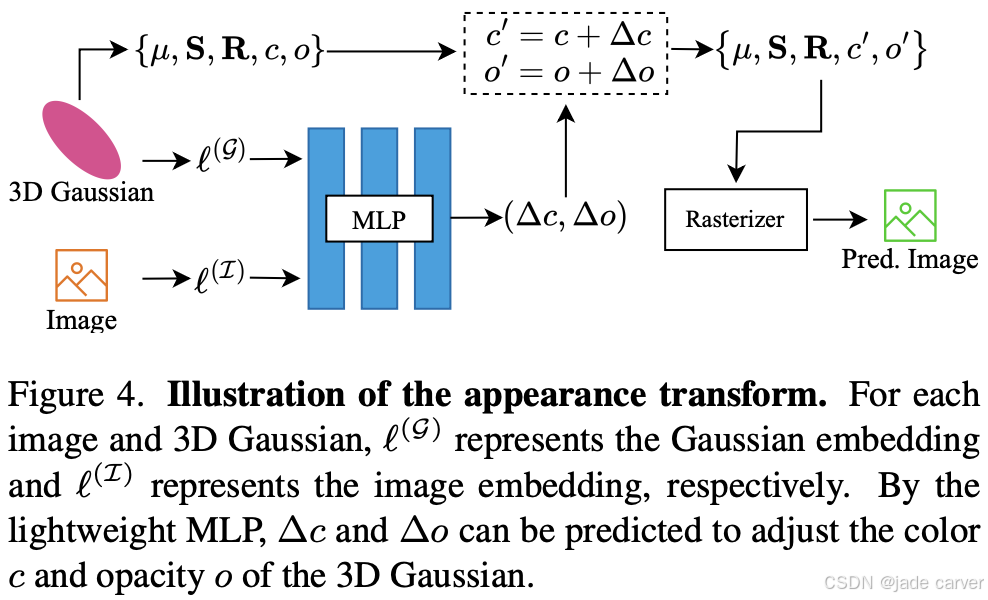
3.5.1. Appearance Transform Module
3DGS[8]在处理训练图像外观差异时易产生漂浮伪影,现有方法如NeRF-W[21]和SWAG[5]通过仅向图像分配嵌入来缓解外观不一致性,但限制了灵活性并导致次优结果。我们提出细粒度外观变换模块,其创新性体现在:

如图4所示,这些embedding嵌入通过轻量级MLP处理,以预测每个高斯的颜色和透明度偏移,从而实现精确且可适应的外观调整。该方法增强了对不一致性的鲁棒性,消除了漂浮伪影,并支持重建后的外观编辑。一旦计算完成,只要图像嵌入保持不变,这些偏移量就可在后续帧中重复使用,确保不会增加额外的渲染成本。

3.5.2. Scale Regularization
在优化过程中,我们频繁观察到尺度异常的高斯体,例如超过场景尺寸或形成高度各向异性形状的情况。这些异常会导致相机旋转时因排序倒置[31]而产生严重伪影。为解决此问题,我们引入包含两个组件的尺度正则化:最大约束防止过度增长,比例约束保持合理形状。该正则化有效抑制了尺度异常引起的伪影,提升了渲染结果的稳定性和一致性。
最大约束限制高斯体尺度的上限,防止其增长至不合理值:

3.5.3. Depth Regularization
受DNGaussian[12]启发,我们采用Depth Anything V2[47]从RGB图像预测细粒度深度图,并通过SfM点云对齐实际深度。训练过程中交替使用文献[12]提出的硬深度与软深度正则化方法,其中深度损失Ld定义为渲染深度与估计深度之间的L1误差。该方案有效抑制了漂浮伪影,显著提升了视觉真实感。
DNGaussian[12]通过动态切换两种正则化实现优势互补:


3.5.4. Anti-aliasing and Detail Enhancement
为提升渲染质量,我们整合了Mip-Splatting[53]的抗锯齿技术,并采用AbsGS[51]以增强细节表现。这两项改进有效降低了渲染伪影,显著提高了视觉保真度。
3.5.5. Transient Objects Removal
在实际数据采集中,瞬态物体(如行人、车辆)的存在不可避免。这些瞬态物体会在重建场景中引入视觉伪影,严重影响最终重建质量。为此,我们采用开放世界目标检测模型Grounding dino 1.5[34]识别这些瞬态物体的2D边界框,并将其作为语义分割模型Sam 2[32]的提示信息以生成细粒度掩模。
3.6. Loss of Individual Partition Training

4. Experiments
4.1 实验设置


4.2 实验结果
我们提出的方法与四种现有方法进行了对比:Switch-NeRF[57]、CityGaussian[18]、Hierarchical-3DGS[9]和3DGS[8]。定量结果汇总于表1。
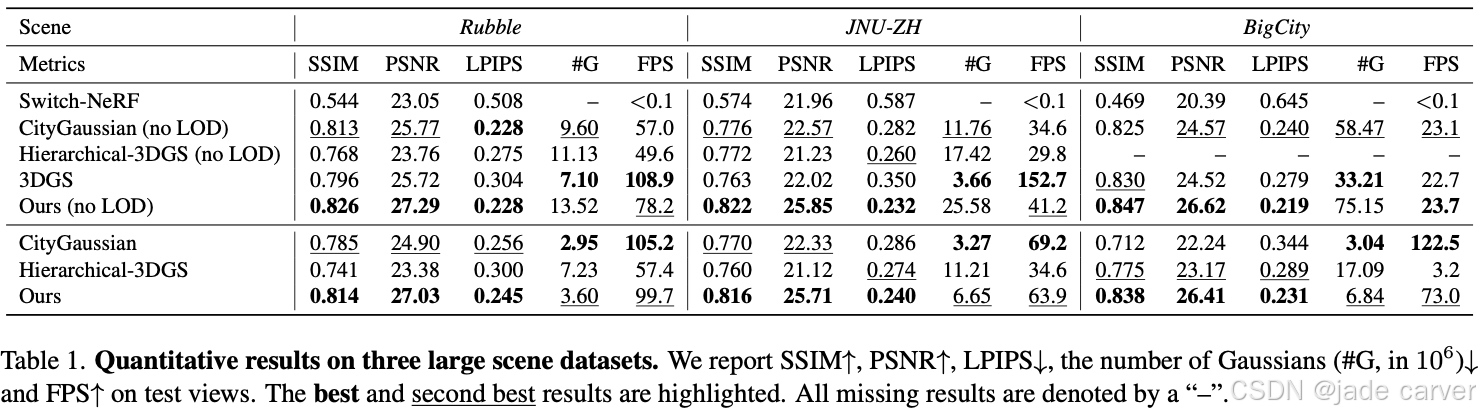

效率指标分析:
| 指标 | 表现特性 |
|---|---|
| 高斯体数量(#G) | 虽非最小值,但保持在合理范围内(24GB显存可实时渲染),且可通过调整LOD预算B进一步降低 |
| 帧率(FPS) | 无明显下降,始终保持前两名,完全满足实时性要求 |
| LOD效益 | 启用LOD后#G显著减少,FPS大幅提升,而质量损失极小 |

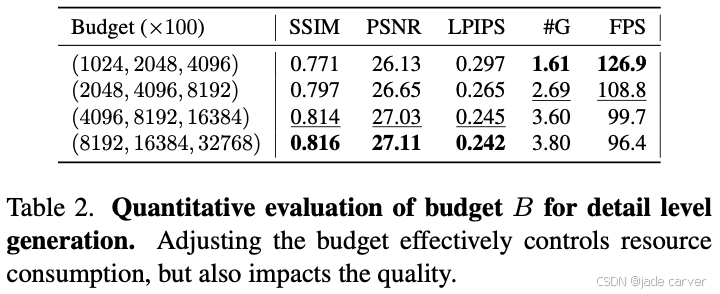
4.3 细节层级生成分析
我们在Rubble场景上进行了不同预算值B对细节层级生成影响的实验研究,结果如表2所示:

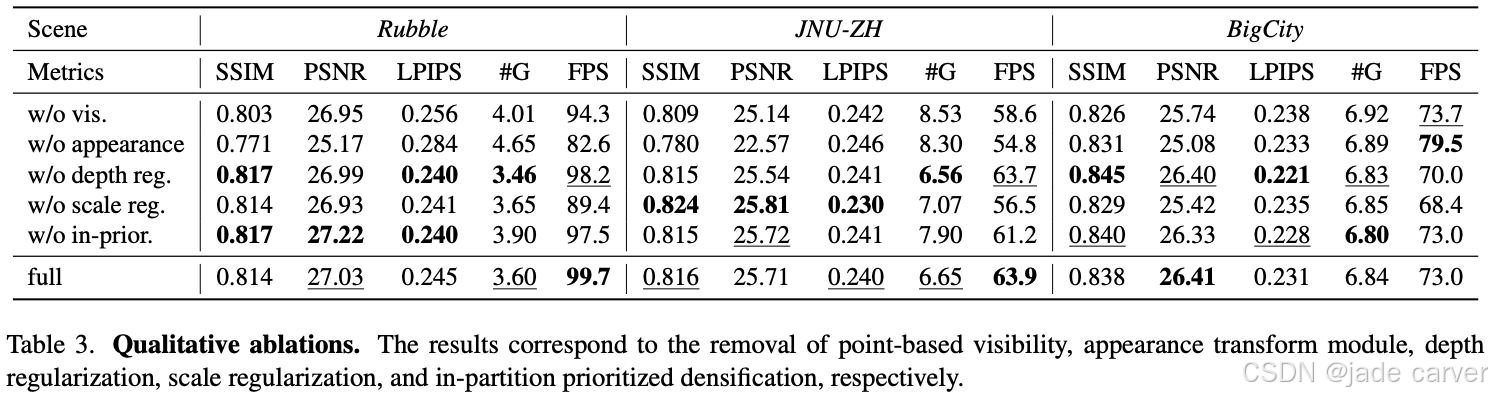
4.4. Ablation Study
Appearance Transform Module对质量提升贡献最大(权重系数建议≥0.2),深度/尺度正则化主要改善视觉稳定性,分区策略是加速训练的关键。

5. Conclusion
我们提出了一种专为城市级场景重建设计的鲁棒高效3D高斯泼溅方法。通过场景分区与基于可见度的图像选择机制,实现了有限资源下的可扩展重建;可控细节层级(LOD)策略提供了精准的资源调控与实时渲染能力;细粒度外观变换模块与尺度正则化技术显著提升了视觉一致性与编辑灵活性。
方法的不足之处在于,依赖于外部运动恢复结构(SfM)提供的相机位姿,位姿噪声或误差会直接影响重建质量——这一效应在超大场景中尤为显著。此外,现有LOD切换机制采用非增量式设计,导致存储与计算开销增加。