数据结构——优先级队列(PriorityQueue):一文解决 Top K 问题!
目录
1.优先级队列
2. 堆的概念
3. 堆的存储方式
4. 堆的创建
4.1 向下调整
4.2 堆的创建
4.3 堆的插入
4.4 堆的删除
5.用堆模拟实现优先级队列
6.常用接口的介绍
6.1 PriorityQueue 的特性
6.2 PriorityQueue 的方法
7. Top K问题
1.优先级队列
队列是一种先进先出的数据结构,这种数据类型每次元素的入队和出队都只能分别在队尾和队头进行,但在一些情况,人们并不需要队列的第一个元素,需要操作的数据可能带有优先级,所以在出队的时候,可能需要优先级更高的元素先出队列。比如外卖派单系统,平台需要快速分配最近的订单,此时需要根据距离的远近优先分配,这个时候优先级就是距离。
优先级队列,它并不是队列队列,不满足先进先出的条件,可以把它理解为一个堆,堆顶元素就是放优先级更高的元素,在加入元素时,堆的状态也要根据新加元素来判断调整优先级元素,而不是单单的指队列的队头或者队尾元素 。所以,优先级队列满足两个基本操作,一是返回最高优先级对象,二是添加新的对象。
2. 堆的概念
如果一个关键码的集合 K = {k0, k1, k2, k3, ..., kn - 1},把它的所有元素按照完全二叉树的顺序存储方式存储在一个一维数组中,并满足 Ki <= K2i + 1 且 Ki <= K2i + 2(或:Ki >= K2i + 1 且 Ki >= K2i + 2) ,称为小堆(或:大堆)。根节点是所有节点最小的堆叫做最小堆或小根堆,根节点是所有节点最大的堆叫做最大堆或大根堆。
堆的性质:
- 堆的一棵完全二叉树
- 堆中的节点的值一定不大于或不小于其父亲节点的值
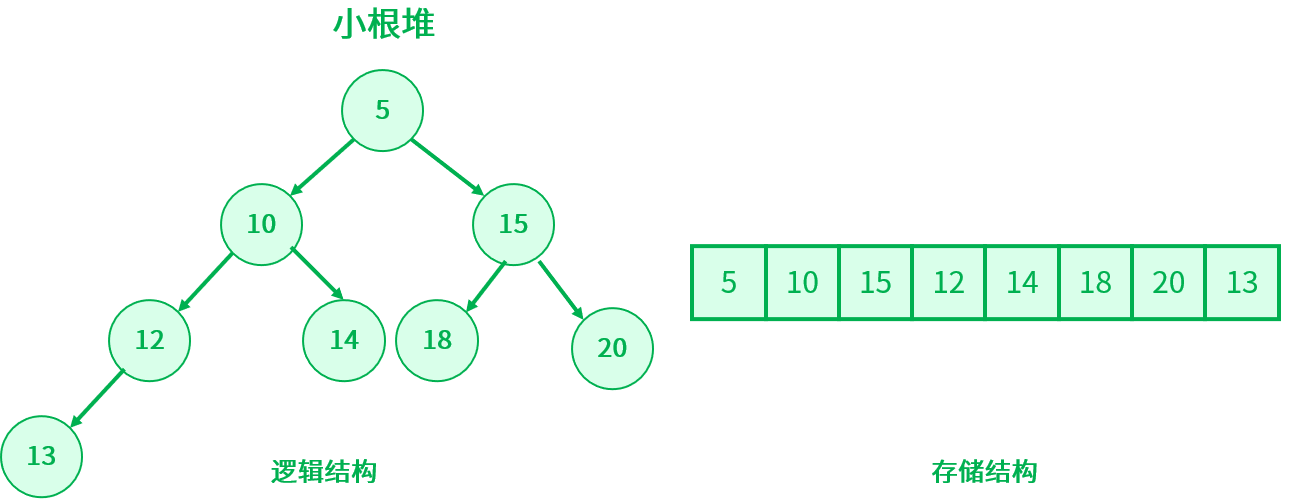
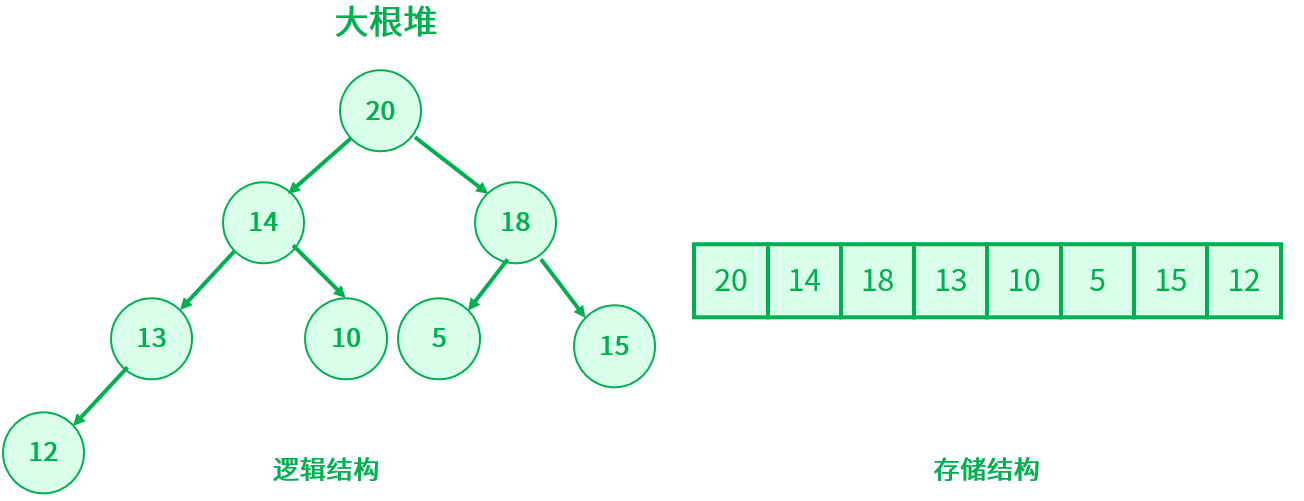
3. 堆的存储方式
堆是一棵完全二叉树,所有可以采用层序遍历的方式进行高效存储。
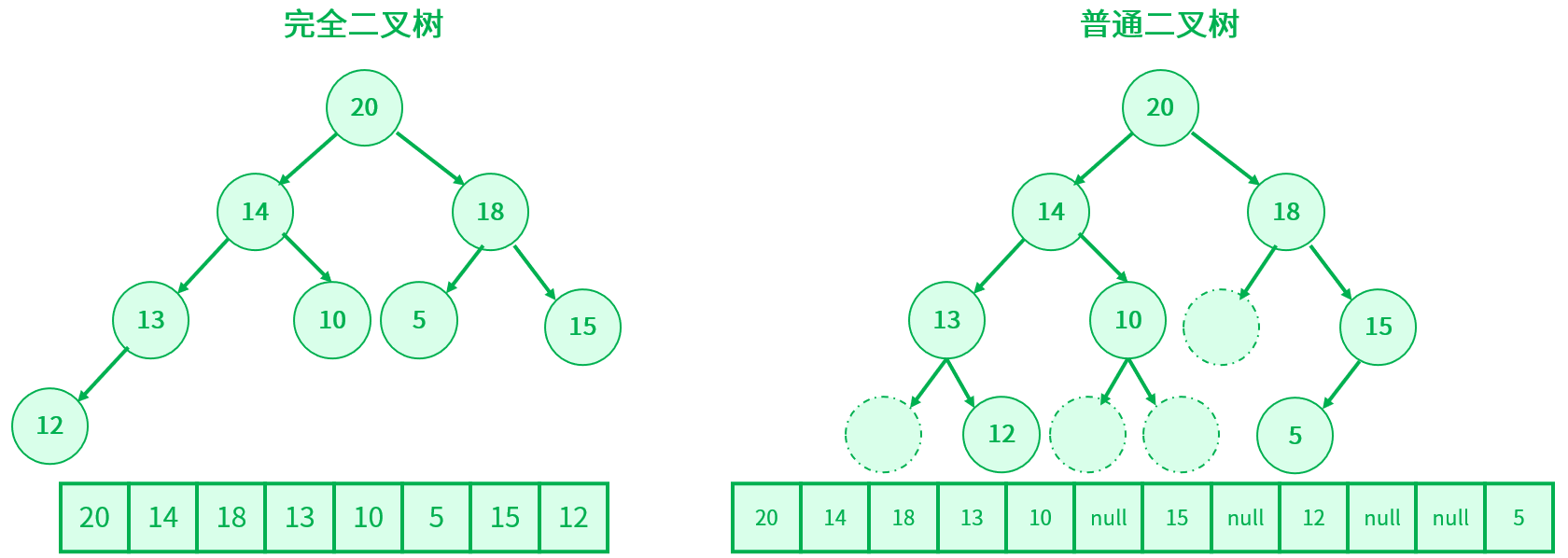
对于普通的二叉树,并不适用顺序方式进行存储,为了更好地还原二叉树,空间就需要存储二叉树的空节点,这样会导致空间利用率降低。
如果定义根节点的下标从 0 开始,即 i 是数组的下标,那么对于任一节点 i ,它的双亲节点下标是 ( i - 1 ) / 2 ( i != 0),左孩子节点下标是 2 * i + 1 ( 2 * i + 1 < 节点个数),右孩子节点下标是 2 * i + 2 ( 2 * i + 2 < 节点个数)。
4. 堆的创建
4.1 向下调整
对于给定一个集合{1,20,15,18,16,12,13,8,9},怎么把它建成一个大根堆呢?
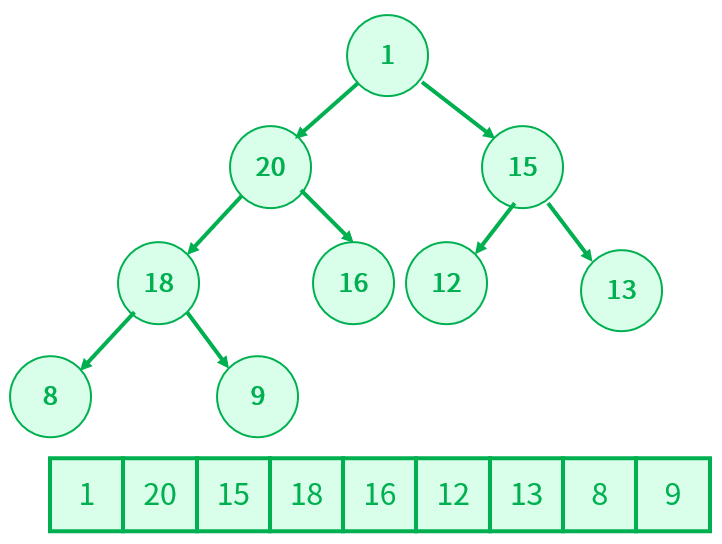
观察可以发现,这个数组集合除了根节点外,其余节点已经基本满足大根堆的条件,这个时候只需要把根节点向下调整。
步骤(这里是建大根堆):
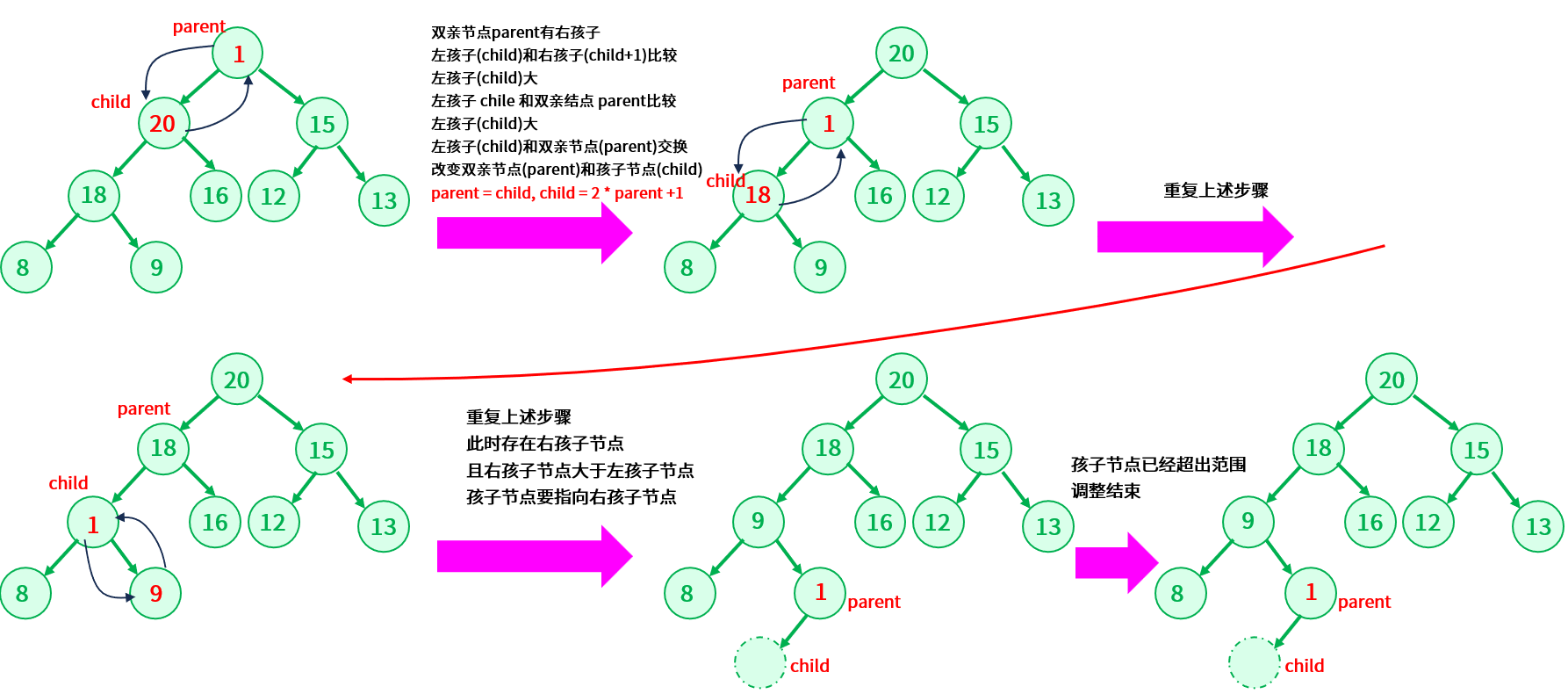
假设根节点设为 parent 用来标记需要调整的节点,child 标记根节点的左孩子(根据完全二叉树可以知道如果根节点存在孩子节点,那么一定拥有左孩子),孩子节点 child 不能大于数组长度,即 child < size,则有:
- 如果 parent 的左孩子存在,并且判断是否存在右孩子,如果没有右孩子,则 parent 和左孩子节点比较,如果 parent < child,进行交换,否则不交换;如果有右孩子,左孩子和右孩子作比较,找到它们的最大值,然后再比较孩子节点和双亲节点的大小,如果满足双亲结点小于孩子节点,进行交换,否则不交换;
- 不论是否交换,比较过后,双亲节点 parent 都要指向较小的值,然后继续向下调整,即 parent = child,child = 2 * parent + 1;
- 重复上述步骤,知道调整比较到最后一个叶子节点位置
这种比较是次数是根据二叉树的高度来确定,所有它的时间复杂度是0(log N)。
4.2 堆的创建
上述例子是在基本有序的情况下,只需要小幅度调整就可以完成。那么对于普通的序列{1,9,8,12,16,13,15,20,17},怎么才能把它创建成一个大根堆呢?
对这个序列初始化堆如下:
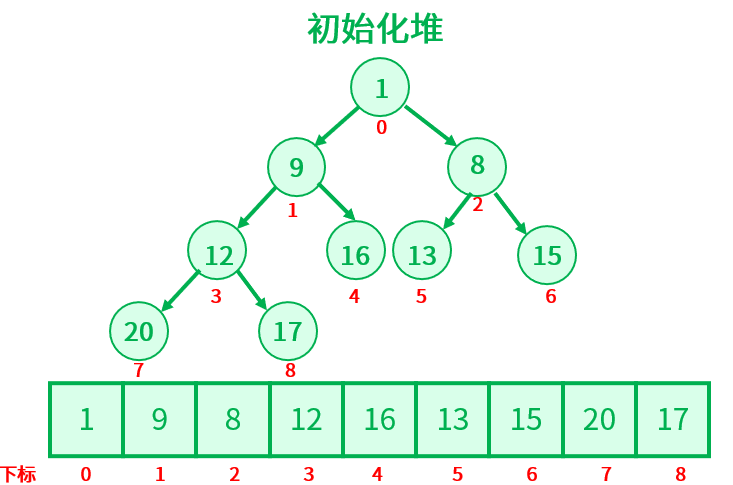
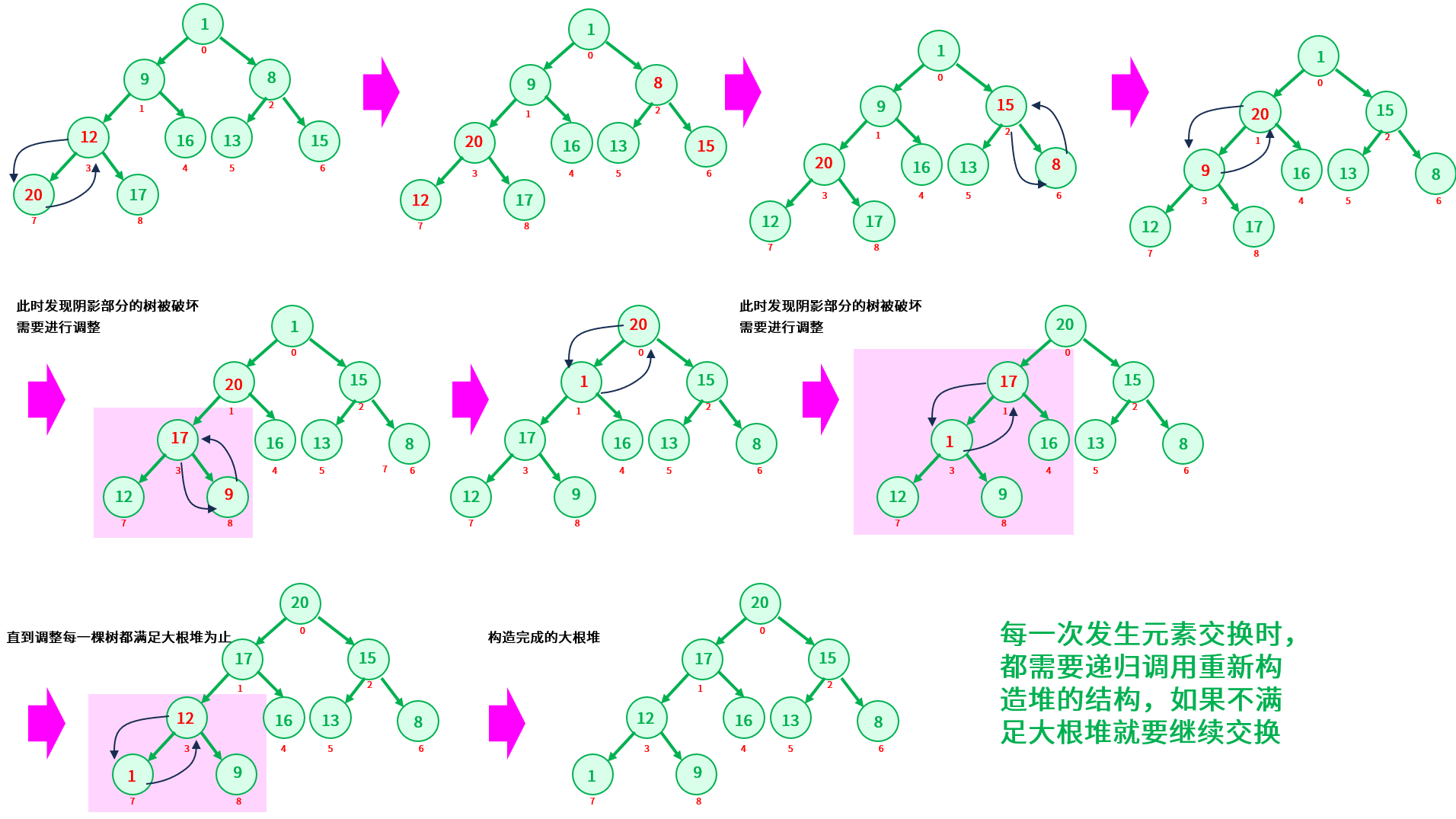
要解决这个问题,就要找到最后一个非叶子节点的下标,最后一个非叶子节点也就是最后一个叶子节点的的双亲结点,然后和它的左右孩子作比较,如果双亲结点小于孩子节点,就做交换,交换后检查被交换的子树,如果被交换的子树结构被破坏,需要递归下沉调整,最后再找上一个非叶子节点,重复上述步骤,直到调整到根节点为止。
代码:
public class Heap {public int[] elem;public int usedSize;//堆的元素个数public Heap() {this.elem = new int[10];//初始化数组大小}//创建堆public void createHeap(int[] array) {for (int i = 0; i < array.length; i++) {elem[i] = array[i];usedSize++;}//usedSize - 1 是最后一个节点的下标,for (int parent = (usedSize - 1 - 1) / 2; parent >= 0; parent--) {shiftDown(parent , usedSize);}}//交换public void swap(int[] elem , int i , int j) {int tmp = elem[i];elem[i] = elem[j];elem[j] = tmp;}//向下调整private void shiftDown(int parent,int usedSize) {int child = 2 * parent + 1;//标记左孩子的位置while (child < usedSize) {//if里面的条件不能交换,比较先判断右孩子节点是否存在if (child + 1 < usedSize && elem[child] < elem[child + 1]) {//如果有右孩子并且右孩子大于左孩子,更改孩子的位置child++;}if (elem[parent] < elem[child]) {//如果双亲节点小于孩子节点,交换swap(elem , child , parent);//交换后更新双亲结点和孩子节点parent = child;child = 2 * parent + 1;} else {//如果双亲结点大于孩子节点,不需要做交换break;}}}
}4.3 堆的插入
如果要在下面这棵树插入一个 25 的节点的节点,应该怎么操作呢?
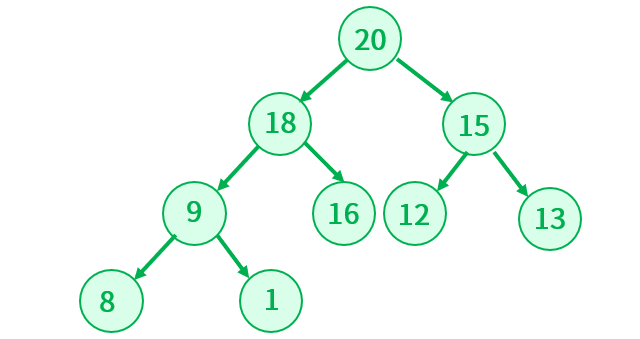
上面的二叉树,根据层序遍历的结果就是 20,18,15,9,16,12,13,8,1,其底层是数组实现的,要插入元素是25,观察 25 比任何元素都大,那是不是把所有的元素后移一位,任何 25 插入到第一个位置就行呢?也就是:
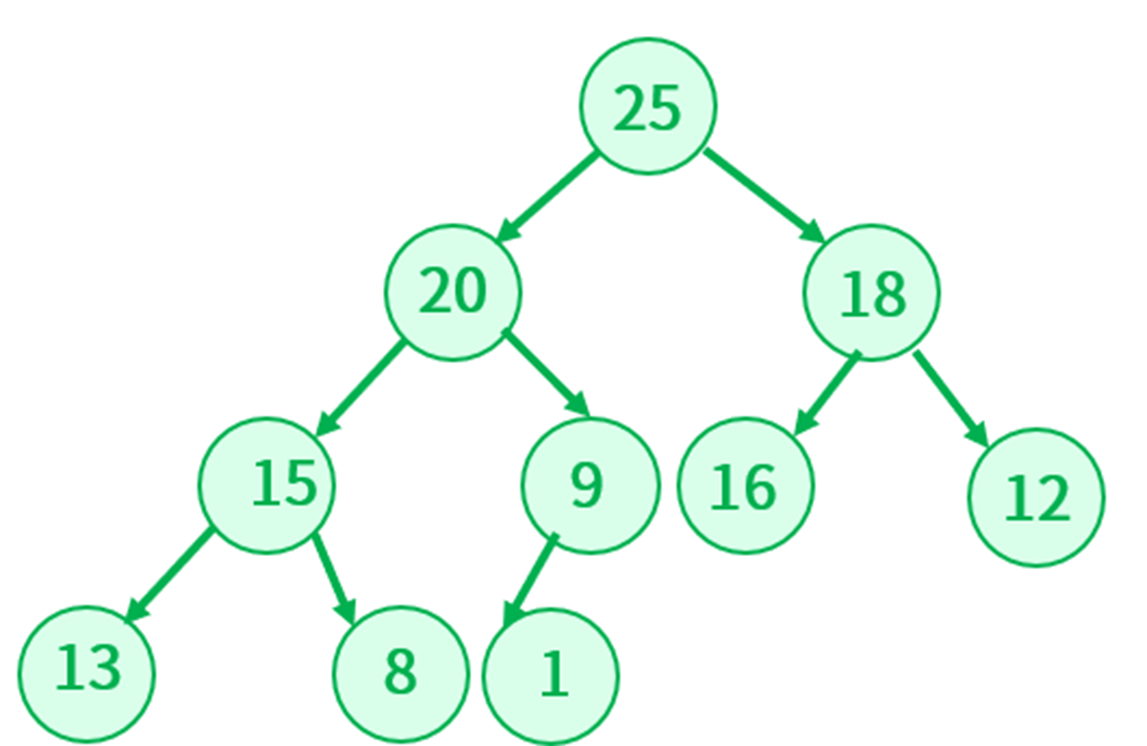
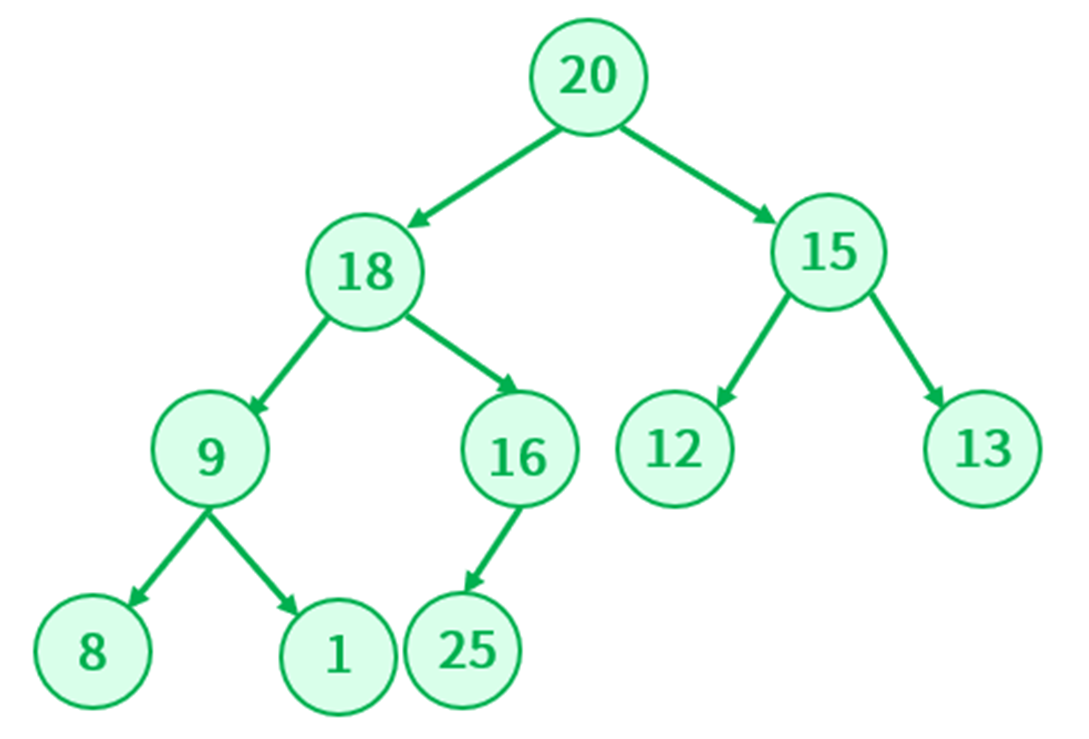
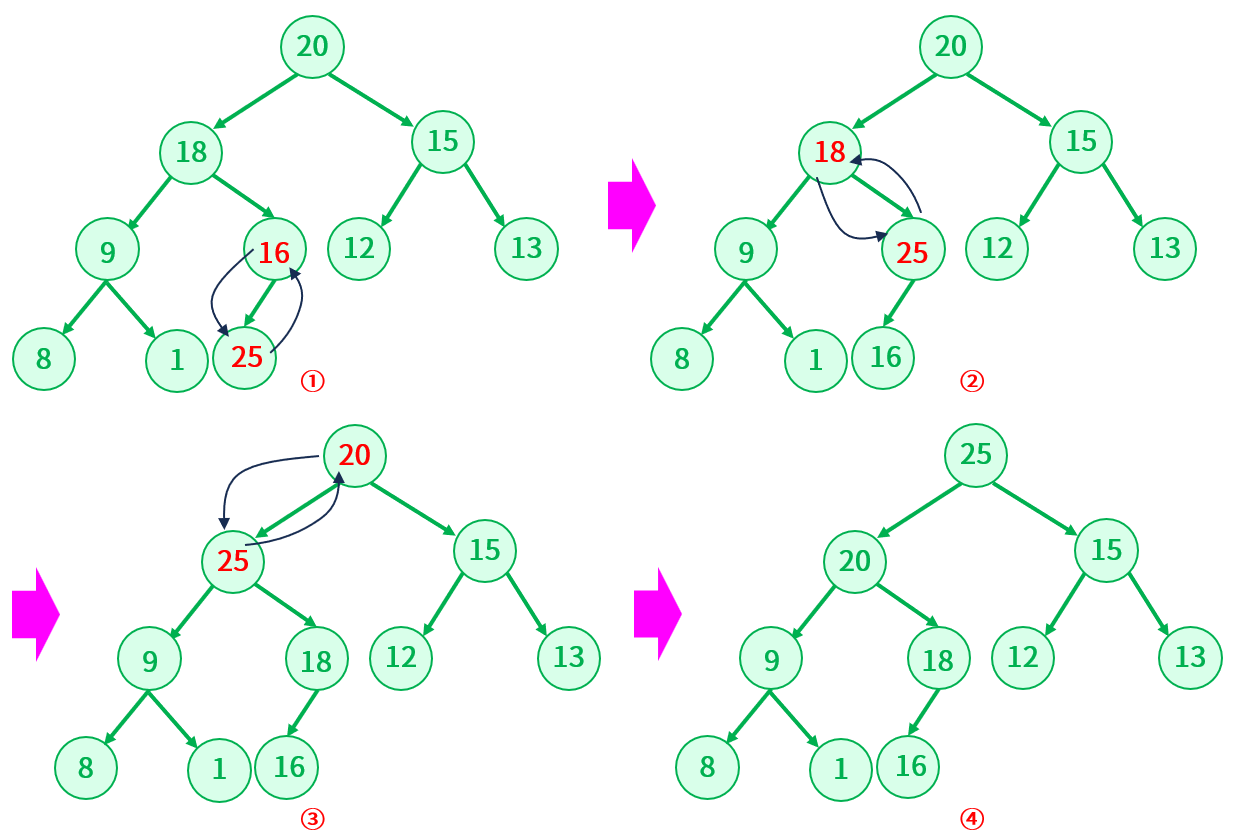
如果这么操作之后,那么这个堆就不再是大根堆了,很明显不符合。可以换一个角度思考,既然堆是完全二叉树,那么新插入的元素就紧接着最后应该元素追加就好了(也就是堆的末尾),然后把这个新加入的节点和它的双亲节点作对比,如果比双亲节点大,那么就进行交换,然后更新这个新加入节点的下标,直到和根节点左比较为止
所以,堆的插入应该要满足:
- 把新加的元素放入堆的末尾,虽然堆的本质是二叉树,但是它是根据数组来实现的,所以在末尾追加时先判断数组是否已满
- 将新加的元素节点进行向上调整,直到满足堆的性质
代码:
//新增元素后也要满足大根堆public void offer(int val) {if (isFull()) {//如果满,扩容this.elem = Arrays.copyOf(elem , 2 * elem.length);}elem[usedSize] = val;//在末尾追加shiftUp(usedSize);//调用向上调整usedSize++;//元素个数加1}//向上调整,新增的元素位置为孩子节点private void shiftUp(int child) {int parent = (child - 1) / 2;//找到双亲节点while (parent >= 0) {if (elem[parent] < elem[child]) {//孩子节点大于双亲节点,进行交换swap(elem , child , parent);child = parent;parent = (child - 1) / 2;} else {//如果孩子节点不大于双亲节点,则说明新加的元素在末尾追加时,就已经满足大根堆的性质break;}}}//判满public boolean isFull() {return usedSize == elem.length;}
4.4 堆的删除
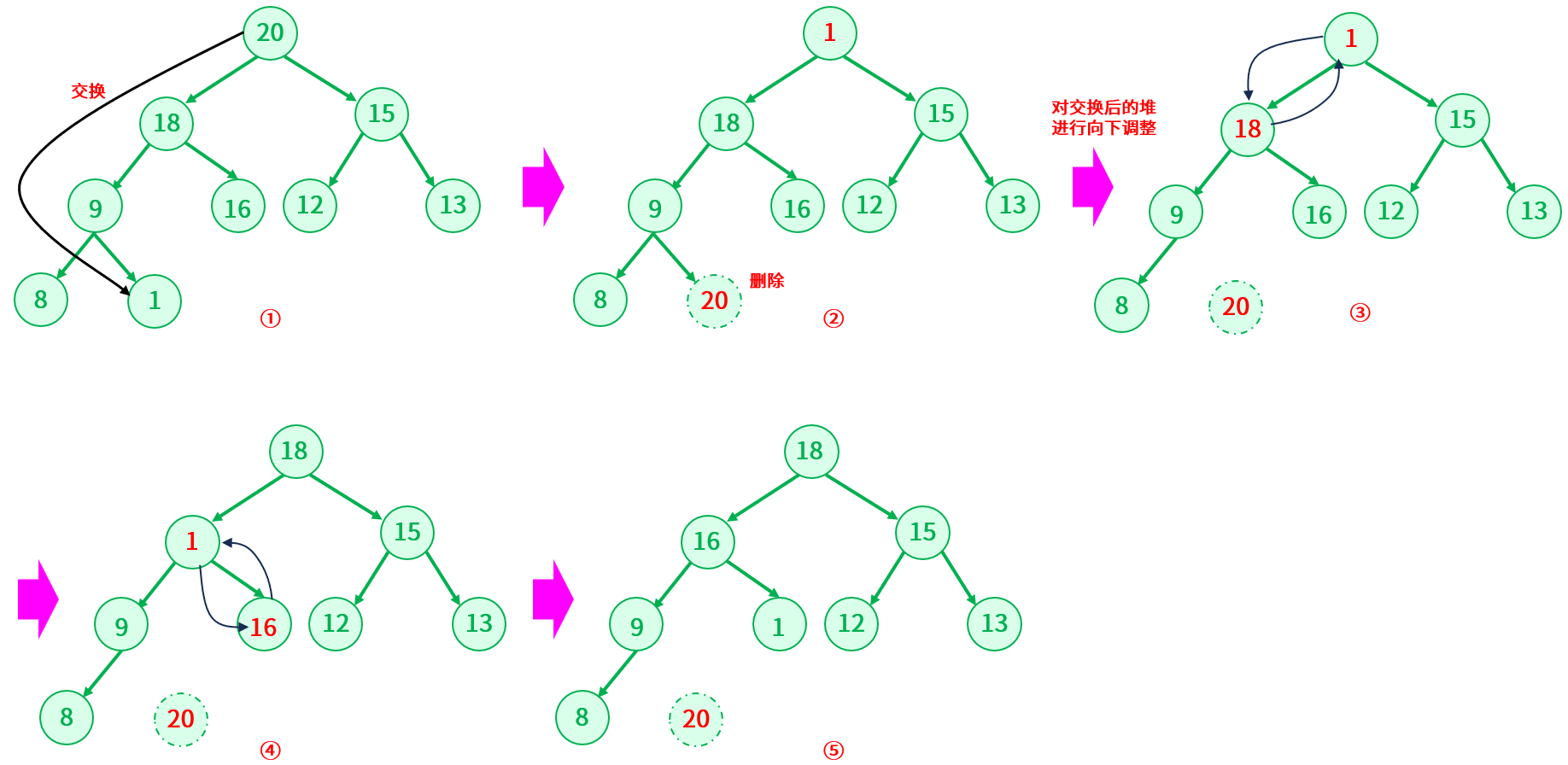
堆的删除,删除的是堆顶元素,这也正是设计堆的原因,希望在第一个元素就可以找到优先级更高的元素。查看元素时,查看的也是堆顶元素。如何实现呢?
堆的删除并不能说像链表一样删除头节点,改变头节点的指向,在这里也就是后面的元素依次往前挪,这样是不行的,因为也会破坏堆的结构。其实可以先想一下删除后的结果:堆的元素个数一定会减 1 ,那么只需要把原本的堆中最后一个元素的位置和堆顶元素的位置交换一下,此时对交换后的堆顶元素发生向下调整,就可以完成操作。
代码:
//删除元素,删除之后也要满足大根堆public int poll() {checkEmpty();//判断是否为空int val = elem[0];swap(elem , 0 , usedSize-1);shiftDown(0 , usedSize-1 );usedSize--;return val;}public boolean isEmpty() {return usedSize == 0;}//判断是否为空,如果空就没有元素可以删public void checkEmpty() throws EmptyException{if (isEmpty()) {throw new EmptyException("数组为空!!!");}}//查看堆顶元素public int peek() {checkEmpty();return elem[0];}
5.用堆模拟实现优先级队列
实现优先级队列,其实就是创建堆的过程。
6.常用接口的介绍
6.1 PriorityQueue 的特性
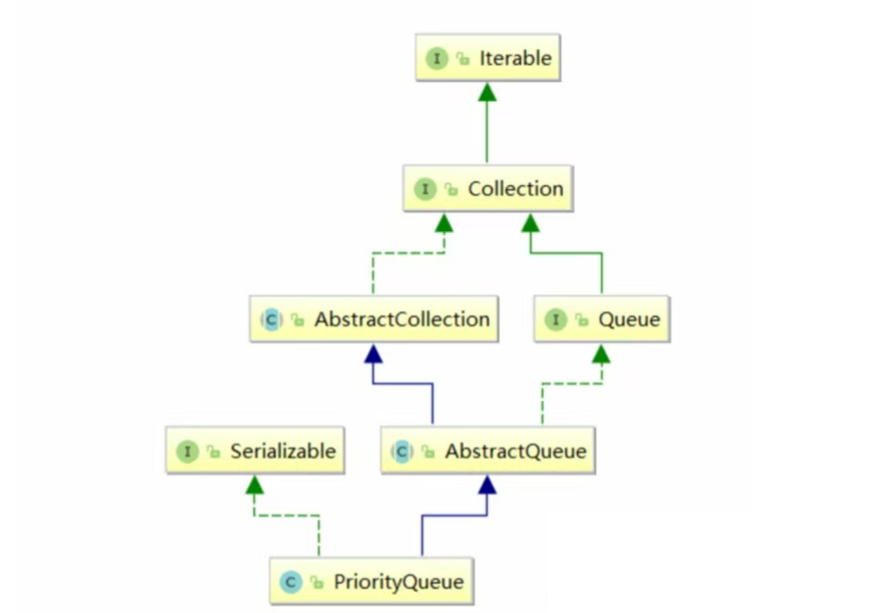
Java集合框架提供了 PriorityQueue 和 PriorityBlockingQueue 两种类型的优先级队列, PriorityQueue 是线程不安全的, PriorityBlockingQueue 是线程安全的。在这里主要了解 PriorityQueue。
注意事项:
1. PriorityQueue 中的元素是需要可以比较大小的,如果插入的对象不能比较大小,就会抛出 ClassCastException 异常

2. 不能插入 null 对象,否则会抛出 NullPointerException

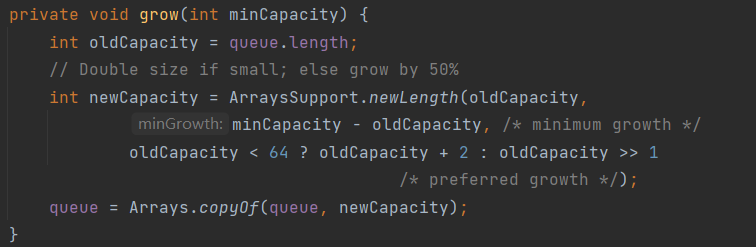
3. 没有容量限制,可以插入任意多个元素,其内部自动扩容(源码如下)并且从源码中可以看出,在优先级队列中,如果容量小于 64 时,扩容是 2 倍扩容,如果容量大于 64 时,按照 1.5 倍扩容
4. 插入和删除的时间复杂度都是O(log N)
5. PriorityQueue 底层是的数据结构是堆,并且默认情况下是最小堆/小根堆,即堆顶元素是最小的元素
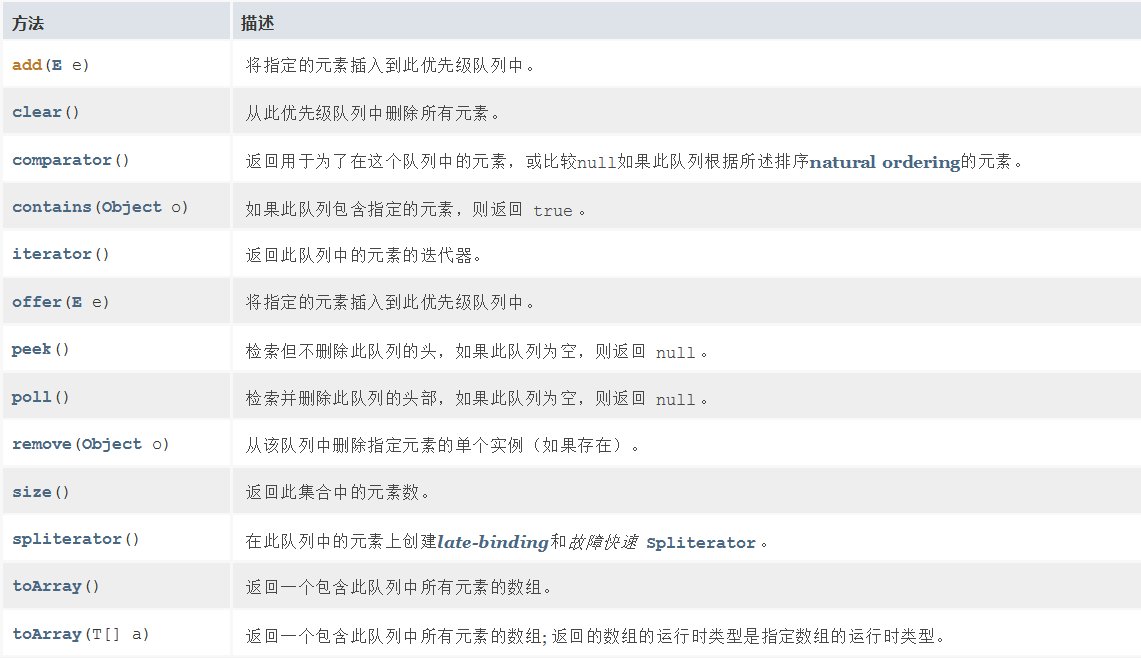
6.2 PriorityQueue 的方法
构造方法:

常用方法:
7. Top K问题
Top K问题通常指从一个数据集中找出前 K 个最大(或最小)的元素,或出现频率最高(或最低)的 K 个元素。
想要找到一组数据中前 K 个最大(或最小)的元素,或出现频率最高(或最低)的 K 个元素,一种非常暴力的解法就是对这组数组进行排序,然后找到前 K 个元素即可,但是如果数据量非常大的时候,想要把所有数据一下子全部加载到内存的时候,可能无法实现。这时候就可以用堆的方式来解决。但还要一个问题,既然建立堆,那是把所有的数据都建立成堆吗?如果数据非常庞大,那肯定也建立不起来,所以最好的方法就是把这组数据的前 K 个元素建立成堆,然后遍历剩下的 N - K 个元素和堆顶元素作比较,是要较大值还是较小值,根据需求而定。
已经知道了用堆可以解决这类问题,但是在解决之前还有一个问题要解决。就是堆是用来排序的,有大根堆和小根堆,如果要找前 K 个最小的元素,是建立大根堆还是小根堆呢?仔细想想堆的性质,如果是建立小根堆,那么堆顶元素永远是最小值,建立小根堆的目的是堆顶元素就是优先级较高的元素,想要求前 K 个最小的元素,但是当一个剩下的 N- K 个元素和堆顶做比较时,可能比堆顶元素大,但是否比除了堆顶元素之外的元素小,这个情况是没办法判断的,因为堆只能瞄到堆顶元素。所以如果要找前 K 个最小的元素,应该建立大根堆。
建立大堆后,遍历剩下的 N - K个元素和堆顶元素作比较,如果比堆顶元素还小,遍历到符合条件的元素加入,把堆顶元素删除,直到遍历整组数据结束。
总结:
求前 K 个最大元素,建立小根堆
求前 K 个最小元素,建立大根堆
最小 K 个数 :
代码(求前K个最小元素):
//自定义实现一个比较接口类,因为PriorityQueue默认是升序,即建立的是小根堆,与题意要求相反,所以需要重新定义比较接口
class IntCom implements Comparator<Integer> {@Overridepublic int compare(Integer o1 , Integer o2) {return o2.compareTo(o1);}
}
public class Main {public static int[] smallestK(int[] arr, int k) {int[] ret = new int[k];if(arr == null || k == 0){return ret;}//方法:建立一个大小为K的大根堆,然后遍历N-K个元素,PriorityQueue<Integer> priorityQueue = new PriorityQueue<>(k , new IntCom());//调用比较方式//把前K个元素建立大根堆for (int i = 0; i < k; i++) {priorityQueue.offer(arr[i]);}//遍历剩下的N - K个元素for (int i = k; i < arr.length; i++) {int peekVal = priorityQueue.peek();//看堆顶元素的值if (arr[i] < peekVal) {//如果遍历的元素小于堆顶元素,堆顶元素删除,新元素加入priorityQueue.poll();priorityQueue.offer(arr[i]);}}//走到这里,说明现在的堆中所有元素就是需要的前K个最小元素//堆新堆进行遍历,因为要返回前K个最小的元素for (int i = 0; i < k; i++) {ret[i] = priorityQueue.poll();}Arrays.sort(ret);return ret;}public static void main(String[] args) {int[] array = {1 , 9 , 15 , 36 , 66 , 88 , 99 , 42 , 8 , 7};int[] ret = smallestK(array , 3);for (int num : ret) {System.out.print(num + " ");}}
}输出结果:

(感谢阅读,文章较长,如有错误,还望指正!撒花❀❀❀)