大数据下的分页通用架构设计:从随机IO到顺序IO
摘要
在数据量爆炸式增长的时代,高效分页成为每个系统必须面对的挑战。本文从存储介质IO特性出发,深入剖析分页性能瓶颈的本质,系统性地提出四种通用设计模式,并结合Elasticsearch、MySQL、ClickHouse等主流数据库的实践案例,给出可落地的混合架构方案。
一、分页问题的本质(随机IO vs 顺序IO)
1、随机IO分页(传统分页)
典型实现:
SELECT * FROM orders ORDER BY create_time LIMIT 1000000,10;工作流程:
- 通过索引定位到第一条记录(1次随机IO)
- 顺序扫描前100万条记录(顺序IO)
- 丢弃前100万条记录
- 返回需要的10条记录
IO特征:
- 需要先访问索引(随机IO)
- 然后扫描大量无关数据(顺序IO)
- 整体呈现随机-顺序混合模式
2、顺序IO分页(优化分页)
典型实现:
-- 书签分页
SELECT * FROM orders
WHERE create_time >= '2023-01-01' AND id > 12345
ORDER BY create_time, id
LIMIT 10;工作流程:
- 通过索引定位到起始位置(1次随机IO)
- 纯粹顺序扫描后续10条记录
- 立即返回结果
IO特征:
- 仅需1次索引访问(随机IO)
- 后续完全顺序读取
- 整体呈现1次随机+N次顺序模式
3、核心差异对比
| 特征 | 随机IO分页 | 顺序IO分页 |
| IO模式 | 随机访问索引+顺序扫描丢弃数据 | 1次随机访问+纯粹顺序读取 |
| 数据利用率 | 低(大量数据被扫描后丢弃) | 高(仅读取目标数据) |
| 跳页能力 | 支持任意跳页 | 仅支持顺序翻页 |
| 性能衰减 | 随OFFSET增大线性下降 | 性能稳定 |
| 典型场景 | 需要随机访问任意页码 | 无限滚动/连续浏览 |
| 存储压力 | 产生大量临时数据 | 无额外存储开销 |
二、通用设计模式
2.1 模式矩阵
| 模式 | 核心思想 | 适用场景 | 支持跳页 | 支持深度分页 | 典型案例 |
| 游标分页 | 记住最后记录位置 | 无限滚动 | ❌ | ✅ | Twitter动态流 |
| 时间分片 | 按时间维度分治 | 时序数据 | ✅ | ✅ | 电商订单查询 |
| 预计算 | 提前生成分页映射 | 固定条件筛选 | ✅ | ✅ | 商品多维度过滤 |
| 混合架构 | 分层组合策略 | 复杂业务场景 | ✅ | ✅ | 金融交易系统 |
2.2 混合架构设计
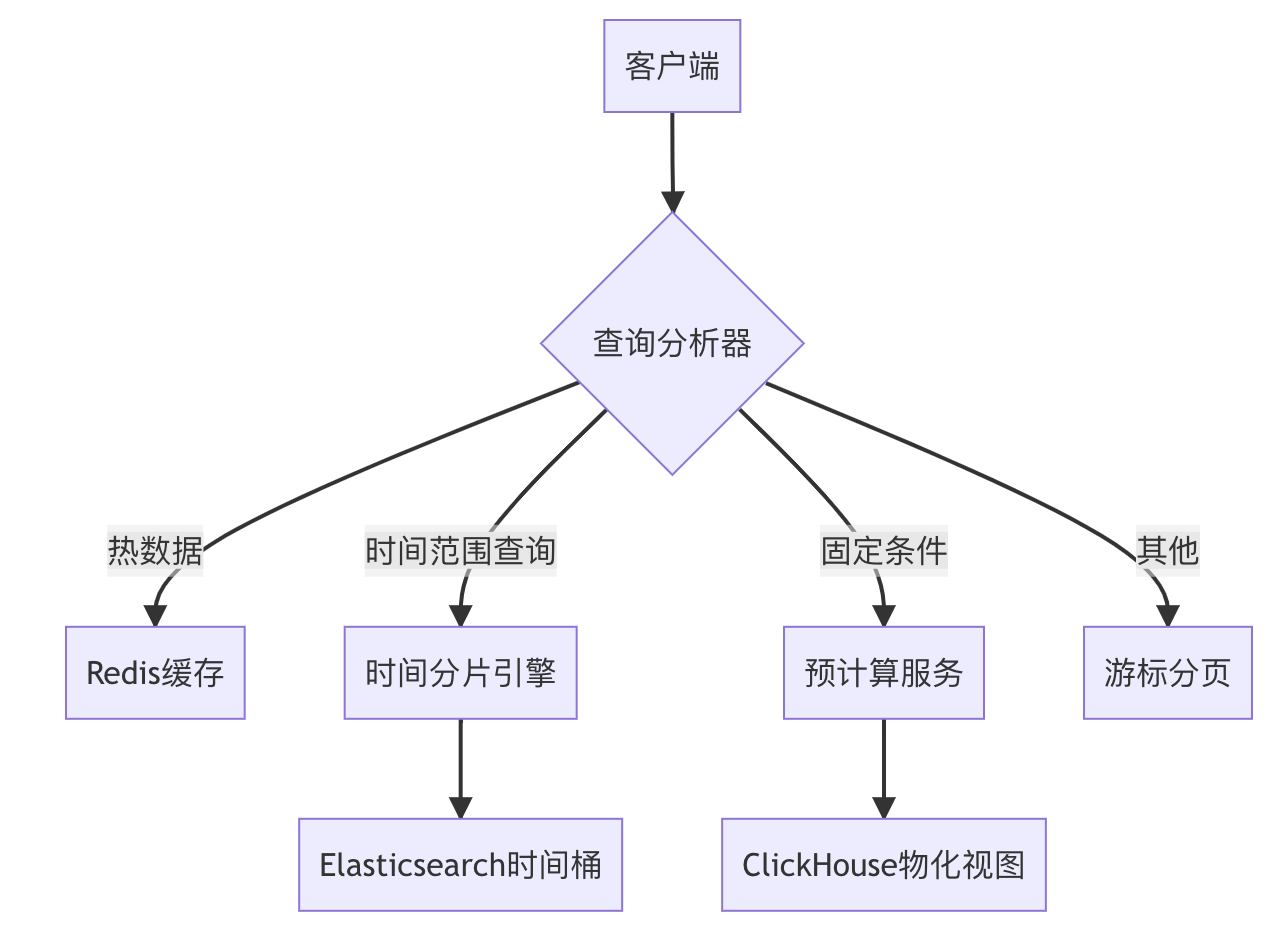
三、游标分页详解
3.1 MySQL实现
-- 第一页
SELECT * FROM orders ORDER BY id LIMIT 10;-- 后续页(记住最后一条记录的id=123)
SELECT * FROM orders WHERE id > 123 ORDER BY id LIMIT 10;3.2 Elasticsearch实现
{"size": 10,"sort": [{"timestamp": "asc"}, {"_id": "asc"}],"search_after": [ // 游标值数组1630000000000, // 上一页最后记录的timestamp值"abc123" // 上一页最后记录的_id值]
}3.3 ClickHouse实现
-- ClickHouse游标分页(基于组合条件)
SELECT * FROM orders
WHERE (date, id) > ('2023-01-01', 1000) -- 多字段游标条件
ORDER BY date, id -- 排序字段必须与WHERE条件一致
LIMIT 10; -- 页大小/* 执行过程解析:
1. 先按date和id的复合索引定位起始位置
2. 按主键顺序扫描后续数据块
3. 返回满足条件的10条记录
*/四、时间分片详解
4.1、MySQL分区表
CREATE TABLE orders (id BIGINT,order_time DATETIME,...
) PARTITION BY RANGE (TO_DAYS(order_time)) (PARTITION p202301 VALUES LESS THAN (TO_DAYS('2023-02-01')),PARTITION p202302 VALUES LESS THAN (TO_DAYS('2023-03-01'))
);-- 按精确时间范围查询(自动分区裁剪)
SELECT * FROM orders
WHERE order_time BETWEEN '2023-02-15 00:00:00' AND '2023-02-15 23:59:59'
ORDER BY order_time DESC
LIMIT 100;/* 执行计划分析:
1. 通过WHERE条件中的时间范围,MySQL会自动排除不相关的分区
2. 使用idx_create_time索引快速定位数据
3. 仅扫描p202302分区内的数据块
*/4.2、Elasticsearch时间桶
支持深度分页下的跳页,见博客:「原创」Elasticsearch深度分页:时间分桶动态定位算法实战
4.3、ClickHouse分区表
-- ClickHouse时间分片表示例
CREATE TABLE time_shard_orders (`event_time` DateTime CODEC(Delta, LZ4), -- 时间分片键,必须放在首位`order_id` UInt64,`user_id` UInt32,`amount` Decimal(18, 2),`status` Enum8('created'=1, 'paid'=2, 'shipped'=3),-- 索引配置INDEX user_idx user_id TYPE bloom_filter GRANULARITY 3,-- 必须按时间分片键排序-- 分区策略:按月分区(根据数据量可调整)
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/time_shard_orders', '{replica}')
PARTITION BY toYYYYMM(event_time) -- 按年月分区
ORDER BY (event_time, order_id) -- 必须包含时间分片键
TTL event_time + INTERVAL 1 YEAR -- 自动过期旧数据
SETTINGS index_granularity = 8192; -- 根据查询模式调整-- 基础时间分片查询
SELECT toStartOfHour(event_time) AS hour_time, -- 按小时聚合count() AS order_count,sum(amount) AS total_amount
FROM time_shard_orders
WHERE -- 关键时间范围条件(利用分区裁剪)event_time BETWEEN '2023-06-01 00:00:00' AND '2023-06-01 23:59:59'AND status = 'paid'
GROUP BY hour_time
ORDER BY hour_time五、预计算方案
5.1 商品筛选案例
-- 预计算表
CREATE TABLE product_filters (category VARCHAR(50),price_range VARCHAR(20),page_num INT,product_ids JSON,PRIMARY KEY (category, price_range, page_num)
);-- 查询时直接获取
SELECT product_ids FROM product_filters
WHERE category='electronics' AND price_range='100-500' AND page_num=3;六、实战案例:电商订单系统混合查询架构
6.1、需求背景分析
随着XX电商平台业务快速发展,订单系统面临三大核心挑战:
- 数据规模:日均订单量突破100万,历史数据超10亿条
- 查询复杂度:需支持16种组合查询条件
- SLA要求:热数据P99响应时间≤300ms,历史数据≤1s
6.2、架构设计图解
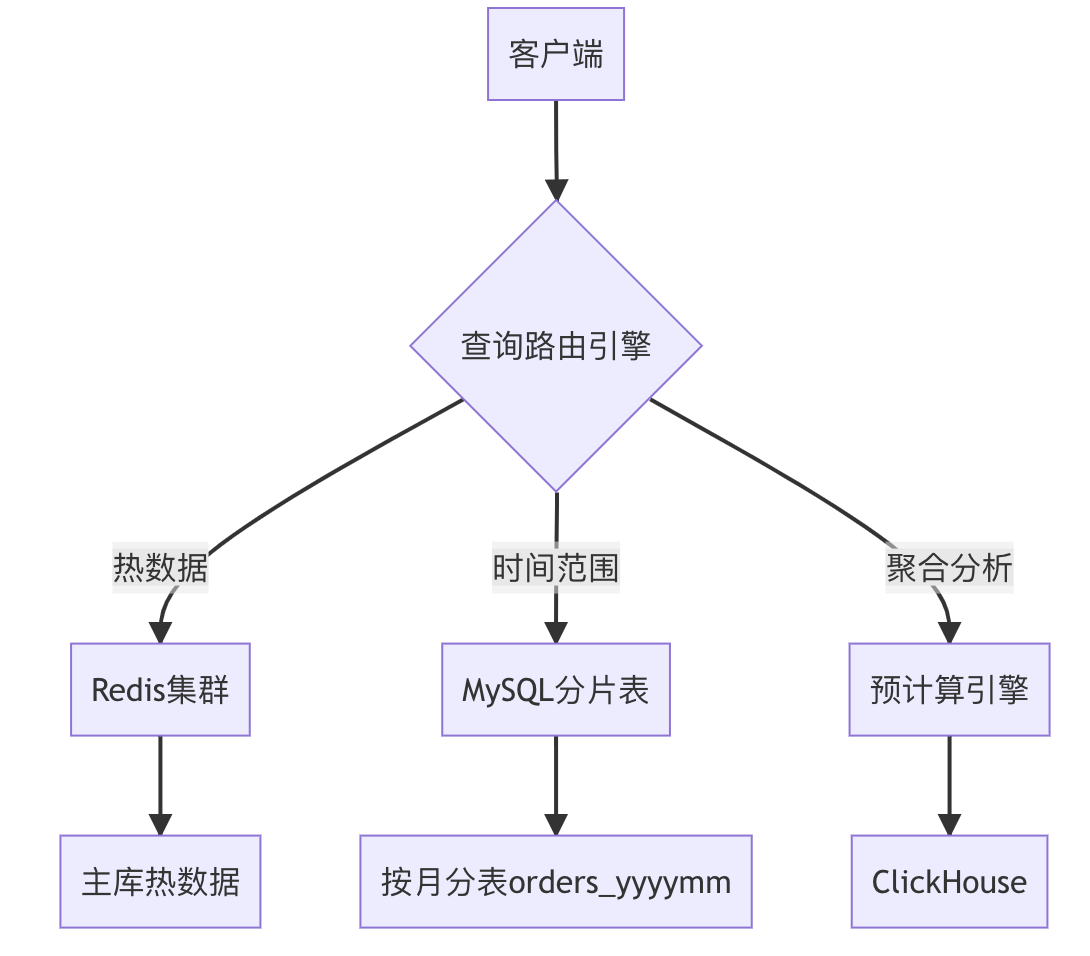
6.3、Java核心实现
6.3.1、查询路由服务
public PageResult<Order> routeQuery(QueryParam param) {if (isHotData(param)) {return cacheFirstQuery(param); }if (needShard(param)) {return parallelShardQuery(param);}return defaultCursorQuery(param);
}6.3.2、动态分片处理
List<String> getQueryShards(LocalDate start, LocalDate end) {return Stream.iterate(start.withDayOfMonth(1), date -> date.plusMonths(1)).limit(Months.between(start, end) + 1).map(date -> "orders_" + date.format(YYYYMM)).collect(Collectors.toList());
}七、决策建议
- 优先规避跳页:前端改为“仅支持上下页翻页”或限制翻页深度(如只展示前100页)
- 必须支持跳页时:
- 热数据:SSD+缓存+书签定位
- 冷数据:时间分桶+并行预加载
- 极端深度跳页:考虑离线预生成分页快照(如ClickHouse的物化视图)
通过混合架构平衡顺序IO与随机IO,可在保证80%常规分页性能的同时,将跳页性能损耗控制在30%以内。实际选择需权衡业务需求与硬件成本。
关键结论
- 性能差距:在SSD上,顺序IO吞吐量可达随机IO的100倍
- 设计铁律:任何高效分页方案的本质都是将随机IO转化为顺序IO
- 实践路径:
- 游标化(牺牲跳页能力)
- 预排序(空间换时间)
- 分片预计算(如时间分桶)