6.11 MySQL面试题 日志 性能 架构
日志文件是分成了哪几种?
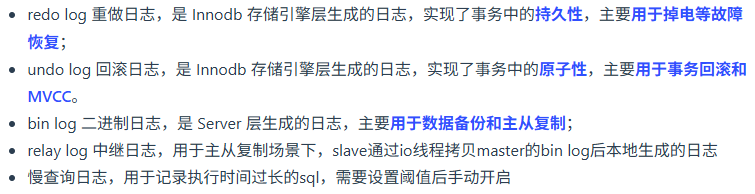
讲一下binlog
binlog 是追加写,写满一个文件,就创建一个新的文件继续写,不会覆盖以前的日志,保存的是全量的日志,用于备份恢复、主从复制;
binlog 有 3 种格式类型,分别是 STATEMENT(默认格式)、ROW、 MIXED
- STATEMENT:每一条修改数据的 SQL 都会被记录到 binlog 中,主从复制中 slave 端再根据 SQL 语句重现。但 STATEMENT 有动态函数的问题,比如你用了 uuid 或者 now 这些函数,你在主库上执行的结果并不是你在从库执行的结果,这种随时在变的函数会导致复制的数据不一致;
- ROW:记录行数据最终被修改成什么样了,缺点是每行数据的变化结果都会被记录,比如执行批量 update 语句,更新多少行数据就会产生多少条记录,使 binlog 文件过大。
- MIXED:包含了 STATEMENT 和 ROW 模式,它会根据不同的情况自动使用 ROW 模式和 STATEMENT 模式;
Undo log

有了undolog为啥还需要redolog呢?
Buffer Pool 是提高了读写效率没错,Buffer Pool 是基于内存的,而内存总是不可靠,断电会导致未落盘的数据丢失。
为了防止断电丢失,InnoDB 引擎就会先更新内存(同时标记为脏页),然后将本次对这个页的修改以 redo log 的形式记录下来。后续,InnoDB 引擎会在适当的时候,由后台线程将缓存在 Buffer Pool 的脏页刷新到磁盘里,这就是 WAL (Write-Ahead Logging)技术。
redo log是物理日志,记录了某个数据页做了什么修改,对 XXX 表空间中的 YYY 数据页 ZZZ 偏移量的地方做了AAA 更新。
MySQL 重启后,可以根据 redo log 的内容,将所有数据恢复到最新的状态。
- redo log 记录了此次事务「完成后」的数据状态,记录的是更新之后的值;
- undo log 记录了此次事务「开始前」的数据状态,记录的是更新之前的值;

能不能只用binlog不用relo log?

binlog 两阶段提交过程是怎么样的?
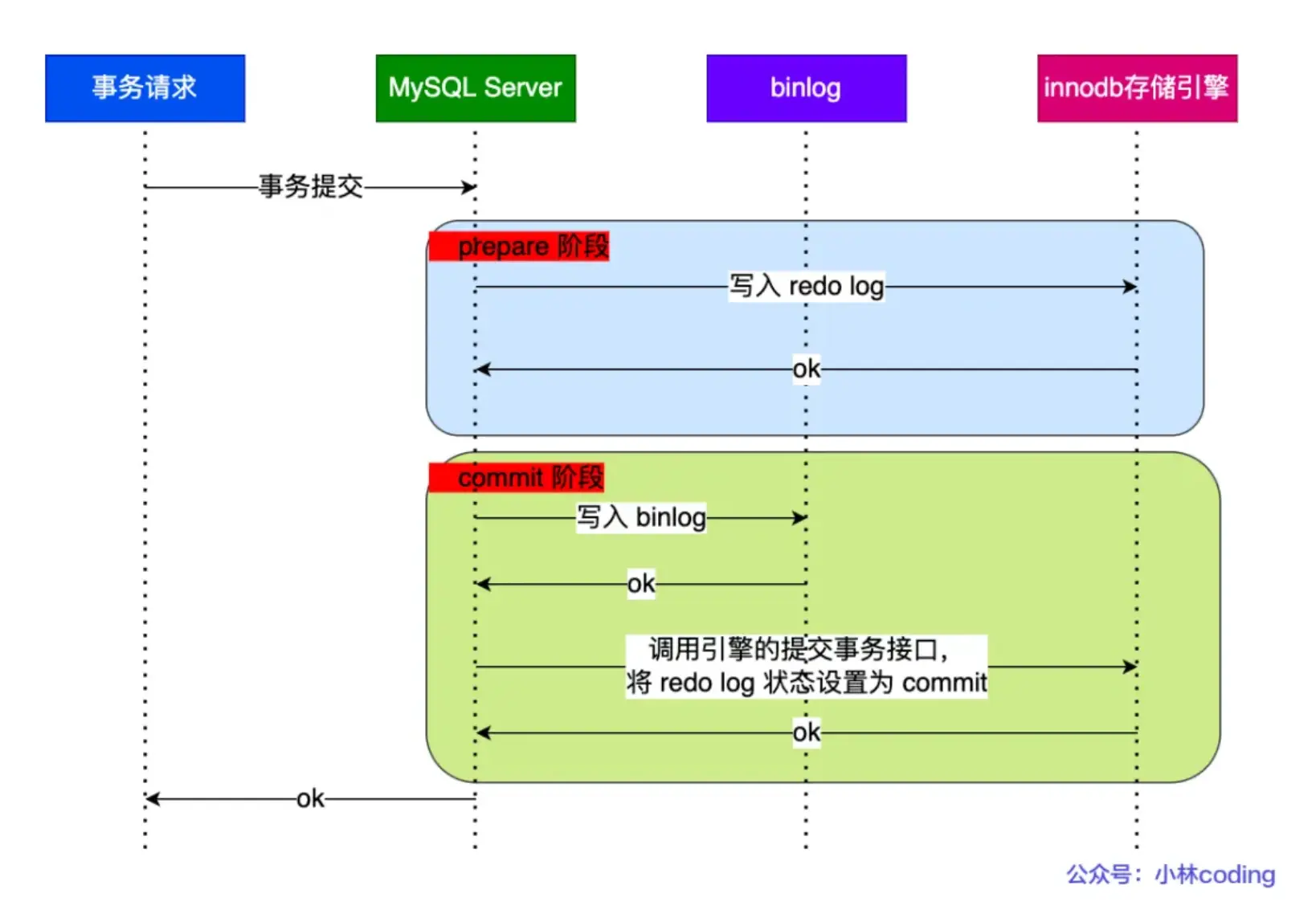
- prepare 阶段:将 XID(内部 XA 事务的 ID) 写入到 redo log,同时将redo log 对应的事务状态设置为 prepare,然后将 redo log 持久化到磁盘(innodb_flush_log_at_trx_commit = 1 的作用);
- commit 阶段:把 XID 写入到 binlog,然后将 binlog 持久化到磁盘(sync_binlog = 1 的作用),接着调用引擎的提交事务接口,将 redo log 状态设置为 commit,此时该状态并不需要持久化到磁盘,只需要 write 到文件系统的 page cache 中就够了,因为只要 binlog 写磁盘成功,就算 redo log 的状态还是prepare 也没有关系,一样会被认为事务已经执行成功;

update语句的具体执行过程是怎样的?

- 判断数据是否在buffer pool中
- 判断更新前后记录是否一样
- 开启事务 记录undo log
- 更新内容记录 记录redo log WAL技术
- 语句更新执行完成
- 记录binlog binlog cache 事务提交时刷盘
- 事务提交
为什么要写RedoLog,而不是直接写到B+树里面?
redolog 写入磁盘是顺序写,而 b+树里数据页写入磁盘是随机写,顺序写的性能会比随机写好
当执行一个更新操作时,Redo Log 会记录修改的数据页的地址和更新后的数据,而不是 SQL 语句本身。
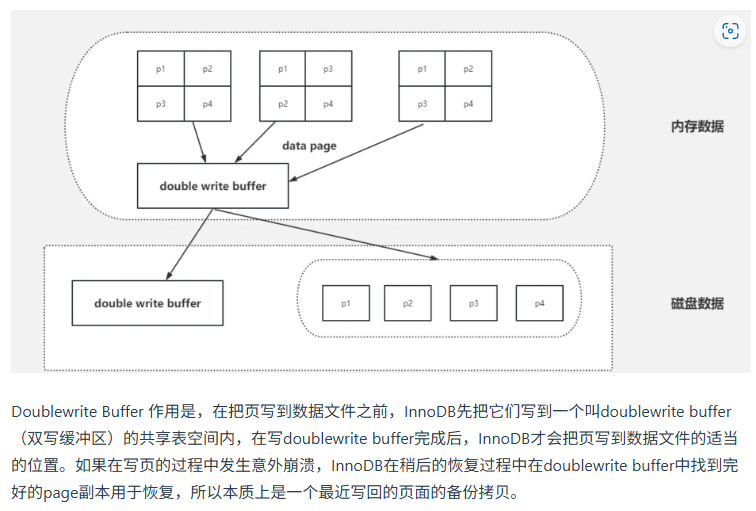
mysql 两次写(double write buffer)了解吗?


mysql的explain有什么作用?

- All 全表扫描
- index 全索引扫描
- range 范围索引扫描
- ref 非唯一索引扫描
- eq_ref 唯一索引扫描
- const 结果只有一条主键或唯一索引扫描
const 是与常量进行比较,查询效率会更快,而 eq_ref 通常用于多表联查中。

给你张表,发现查询速度很慢,你有那些解决方案
- 分析查询语句,是否存在索引未被利用的情况等,并根据相应情况对索引进行适当修改。
- 创建或优化索引,防止索引失效
- 查询优化:避免使用SELECT *,只查询真正需要的列;使用覆盖索引。最好通过冗余字段的设计,避免联表查询。
- 分页优化:针对 limit n,y 深分页的查询优化,可以把Limit查询转换成某个位置的查询
- 优化数据库表:如果单表的数据超过了千万级别,考虑是否需要将大表拆分为小表
- 使用缓存技术:引入缓存层,如Redis,存储热点数据和频繁查询的结果。对于读请求会选择旁路缓存策略,对于写请求会选择先更新 db,再删除缓存的策略
如果Explain用到的索引不正确的话,有什么办法干预吗?

MySQL主从复制了解吗

主从延迟都有什么处理方法?
强制走主库方案:对于大事务或资源密集型操作,直接在主库上执行,避免从库的额外延迟。
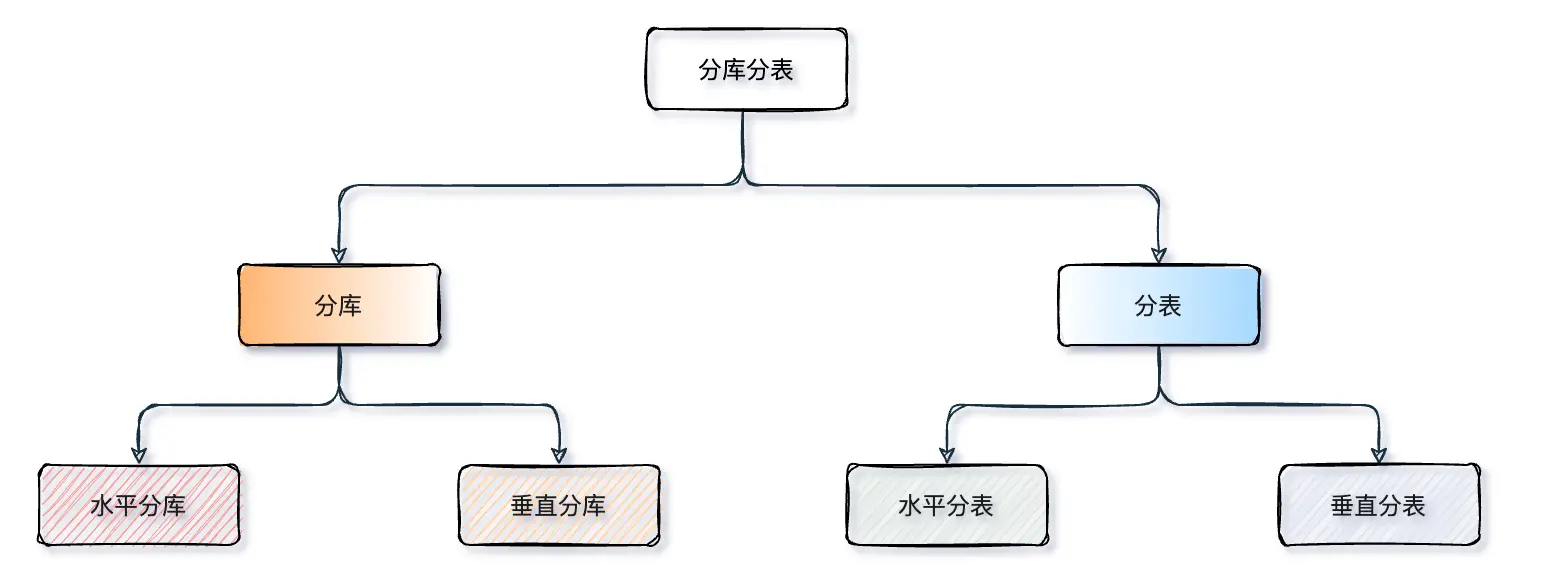
分表和分库是什么?有什么区别?