工程论文: TORL: Scaling Tool-Integrated RL
论文链接:
[2504.13958] ToolRL: Reward is All Tool Learning Needs
1. Introduction
这篇论文试图解决如何通过强化学习直接从基础模型训练大型语言模型,使其能够自主地利用计算工具来增强推理能力的问题。传统的推理方法主要依赖纯自然语言处理方式(如思维链,Chain-of-Thought, CoT),在面对复杂的计算任务时往往表现不佳。尽管已有研究探索了通过代码生成模型来弥补这一差距,但大多数现有方法依赖于监督式微调(Supervised Fine-Tuning, SFT),限制了模型对工具使用策略的探索,且难以实现最优策略的发现。
论文提出的框架TORL(Tool-Integrated Reinforcement Learning)旨在克服这些限制,通过直接从基础模型开始进行强化学习,使模型能够通过广泛的探索发现最优的工具使用策略,从而在复杂的数学问题解决等任务中实现显著的性能提升。
2. Method
2.1 构建数据集
BASE DATASET: NuminaMATH (Li et al., 2024), MATH (Hendrycks et al., 2021), and DeepScaleR (Luo et al., 2025)
从奥林匹克数学竞赛问题中构建了一个高质量的数据集,数据集处理流程如下:
- 去除证明类问题和验证标准模糊的问题, 因为证明类问题通常需要更复杂的逻辑和推理;
- 通过LIMR(Less is More for RL scaling)技术提取了具有平衡难度分布的高质量样本。
最终数据集包含28,740个问题,为模型训练提供了坚实基础。
2.2 TORL框架设计
TORL框架不依赖于监督式微调(SFT),而是直接从基础模型开始进行强化学习(RL)。这使得模型能够在不受限的探索中发现最优的工具使用策略,而不是局限于人类设计的模式。
TORL结合了工具集成推理(TIR),允许模型在推理过程中生成代码,并通过代码解释器执行这些代码来获得计算结果。这一过程是迭代的,模型会根据代码执行的反馈调整推理路径,从而动态地选择合适的推理策略。
多次调用LLM进行循环交互流程
Step 1. 命令LLM先进行自然语言的推理, 然后输出代码块包裹的代码块, 参考如下:
```python
(.*?) # 代码内容
```output
Step 2. 一旦检测到闭合标记(如“```output”或三反引号结束),立即调用 API 的终止生成命令,自动中断接下来的 token 流或停止生成。
Step 3. 把运行结果插回上下文 → 触发下一轮生成

2.3 奖励规则设计
基于答案的奖励规则
- 正确答案: +1
- 错误答案: -1
基于代码可执行性的奖励规则
- 可执行代码: 0
- 不可执行代码: -0.5
3. Experiment
训练
所有强化学习实验均在 veRL 框架(Sheng 等,2024)下进行,使用 Sandbox Fusion 作为代码解释器。我们采用 GRPO 算法(Shao 等,2024),将 rollout batch size 设置为 128,并为每个问题生成 16 个样本。为了增强模型的探索能力,所有实验中都省略了 KL loss,同时将温度设置为 1。
我们选择 Qwen-2.5-Math(Yang 等,2024)系列模型作为强化学习的基础模型。为了最大化效率,默认的调用次数 C 设置为 1。此外,在默认实验中,仅保留答案正确性奖励(Answer Correctness Reward),并未引入代码可执行性奖励(Code Executability Reward)。
评估结果
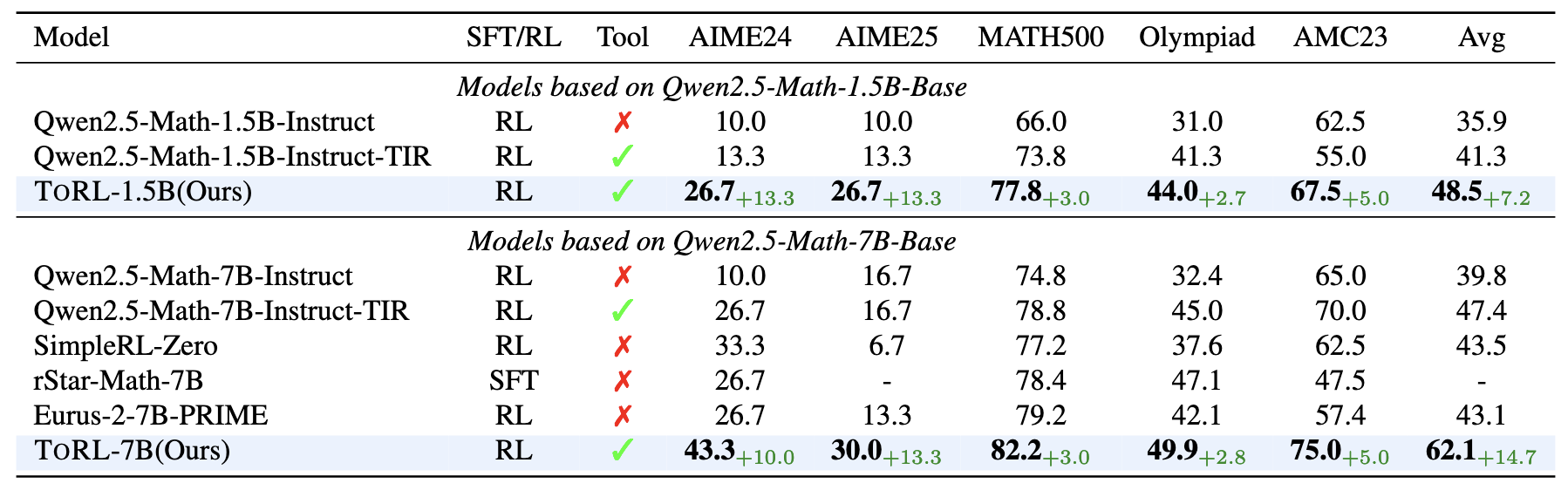
4. Conclusion
我们提出的 TORL 能够让 LLM 通过强化学习将工具整合到推理中,超越预定义的工具使用限制。我们的研究结果表明,TORL 的性能大幅提升,推理能力不断增强,这凸显了 TORL 在推进 LLMs 复杂推理方面的潜力。