Dify-7: RAG 知识系统
RAG(检索增强生成)知识系统是 Dify 的核心组件,支持 AI 应用检索和利用外部知识。该系统管理从文档摄入到知识检索的全流程,支持不同索引技术、文档处理方法和检索策略。
RAG 知识系统采用 提取 - 转换 - 加载(ETL) 三阶段管道处理文档,并结合复杂的检索机制实现知识访问。
数据集管理
数据集结构
数据集是 RAG 知识系统的基本组织单元,每个数据集包含文档,文档被分割为段(segment)以进行索引和检索。
Dataset:作为 RAG 系统的顶层元数据管理单元,存储与 “文档集合” 相关的配置信息,是整个检索流程的基础配置入口。
| 数据集字段 | 类型 | 说明 |
|---|---|---|
| id | string | 唯一标识符 |
| name | string | 数据集名称 |
| description | string | 数据集描述 |
| indexing_technique | string | 索引技术(high_quality/economy) |
| embedding_model | string | 嵌入模型名称 |
| embedding_model_provider | json | 嵌入模型提供商配置 |
| retrieval_model | json | 检索模型的配置参数(如相似度阈值、top-k 数量) |
| built_in_field_enabled | boolean | 是否启用内置字段(如文档的 name、doc_form)。若启用,检索时会同时基于内置字段和内容。 |
Document:管理原始文档的基础信息,记录文档的 “物理属性” 和状态(如是否可用、是否完成索引)。
| 文档字段 | 类型 | 说明 |
|---|---|---|
| id | string | 唯一标识符 |
| dataset_id | string | 所属数据集 ID |
| name | string | 文档名称 |
| doc_form | string | 文档形式(text_model/qa_model/hierarchical_model) |
| indexing_status | string | 索引状态 |
| word_count | int | 文档字数统计 |
| enabled | bool | 是否启用(true/false)。若为 false,文档不会参与检索 |
| archived | bool | 是否归档 |
DocumentSegment:存储文档拆分后的 “基础处理单元”,是 RAG 中生成嵌入向量(Embedding)的最小单位
| 文档片段字段 | 类型 | 作用 |
|---|---|---|
id | string | 片段的全局唯一标识(UUID),用于关联 ChildChunk 的 segment_id。 |
document_id | string | 所属文档的 id(外键),表示该片段来自哪个文档。 |
dataset_id | string | 所属数据集的 id(外键),与文档的 dataset_id 一致(保证数据一致性)。 |
content | string | 片段内容(原始文本,如 “空调的额定电压为 220V…”),是生成嵌入向量的核心输入。 |
answer | string | 预生成答案(可选,如 “空调额定电压 220V”),用于直接返回给用户(若检索到该片段)。 |
status | string | 处理状态(如 “pending” 等待处理、“processed” 已生成向量、“error” 失败),用于跟踪片段处理进度。 |
enabled | bool | 是否启用。若为 false,该片段不会参与检索(即使已生成向量)。 |
index_node_id | string | 向量数据库中的节点 ID(如 Weaviate 的 _id),用于关联向量数据(检索时通过此 ID 定位向量)。 |
index_node_hash | string | 向量节点的哈希值(如 SHA-256),用于校验向量数据是否与 content 一致(防止数据篡改)。 |
ChildChunk:存储片段进一步拆分后的 “更细粒度单元”,当 Segment 内容过长(如超过嵌入模型的最大 token 限制),需拆分为多个 ChildChunk 分别生成向量。
| 子块表字段 | 类型 | 作用 |
|---|---|---|
id | string | 子块的全局唯一标识(UUID)。 |
segment_id | string | 所属片段的 id(外键),表示该子块来自哪个 Segment。 |
content | string | 子块内容,用于生成更细粒度的向量。 |
status | string | 处理状态(如 “pending” 等待处理、“embedded” 已生成向量、“failed” 失败)。 |
index_node_id | string | 向量数据库中的节点 ID(与 Segment 的 index_node_id 逻辑一致),用于关联子块向量。 |
index_node_hash | string | 子块向量的哈希值,用于校验数据一致性(与 Segment 的 index_node_hash 逻辑一致)。 |
数据集创建
通过 API 创建数据集时需传入名称、描述、索引技术和检索配置等参数:
POST /datasets
创建流程:
- 参数校验
- 创建数据集记录
- 配置嵌入模型(如需高质量索引)
- 设置检索配置
- 权限初始化
索引技术
系统支持两种核心索引技术:
| 技术 | 说明 | 向量数据库 | 嵌入模型 | 应用场景 |
|---|---|---|---|---|
| high_quality | 基于嵌入模型将文本转为向量 | 必需 | 必需 | 语义理解更强,处理复杂查询 |
| economy | 基于关键词的倒排索引 | 无需 | 无需 | 低资源消耗,精确关键词匹配 |
文档形式
文档可通过三种形式处理和索引:
| 形式 | 说明 | 索引方法 |
|---|---|---|
| text_model | 直接嵌入全文的默认文本形式 | 直接嵌入文档内容 |
| qa_model | 问答对形式 | 生成问答对并嵌入问题 |
| hierarchical_model | 父子块分层结构 | 创建包含父子块的层级结构 |
文档处理管道
处理管道遵循 ETL(提取 - 转换 - 加载) 模式:
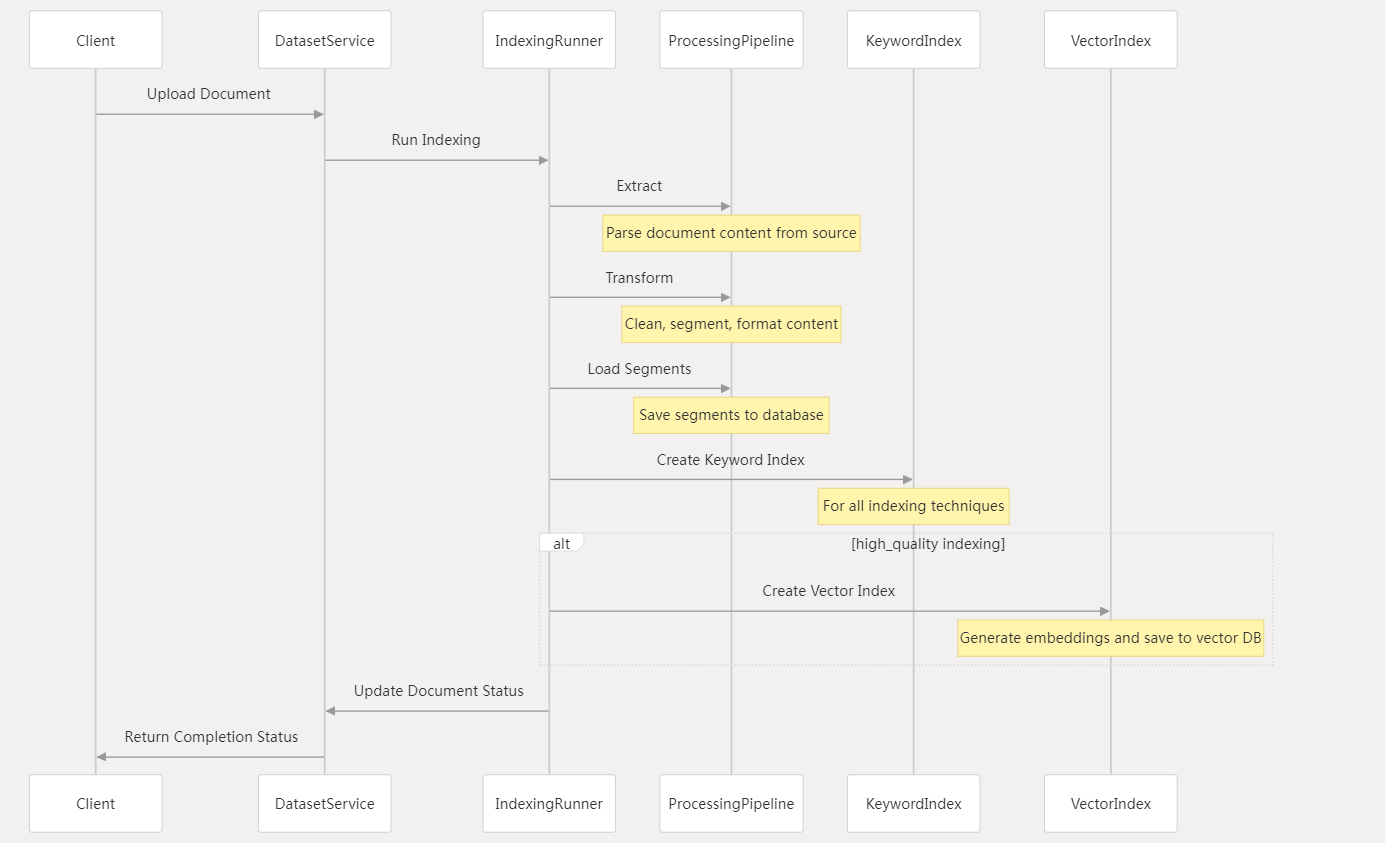
high_qualityeconomy是否上传文档运行索引索引技术提取内容清洗/分段/格式化保存段到数据库创建关键词索引是否高质量索引?生成嵌入并保存到向量数据库跳过向量索引更新文档状态返回完成状态
提取阶段(Extract)
处理不同数据源,将不同来源内容标准化为统一文本格式:
- 上传文件:解析 PDF、DOCX 等格式
- Notion 导入:提取 Notion 页面内容
- 网站爬取:提取爬取的网页内容
转换阶段(Transform)
处理步骤:
- 文本清洗:按规则去除空格、URL、邮箱等
- 分段:按配置规则将文档分割为块
- 分隔符(默认:
\n\n) - 最大令牌数(默认:1024)
- 块重叠令牌数(默认:50)
- 分隔符(默认:
- 格式化:根据文档形式(文本 / 问答 / 分层)准备索引数据
关键的分段参数:
- 分隔符:用于分割文本的字符序列(默认值:\n\n)
- 最大令牌数:每个文本段的最大令牌数量(默认值:1024)
- 块重叠:文本段之间的令牌重叠数量(默认值:50)
加载阶段(Load)
加载阶段:
1. 将文本段保存到数据库中;2. 为所有文档创建关键词索引;
3. 对于高质量索引,生成嵌入向量并将其存储到向量数据库中。
处理步骤:
- 为文本段创建数据库记录;
- 使用已配置的嵌入模型生成文本嵌入向量;
- 构建搜索索引(关键词索引和 / 或向量索引)。
检索系统
检索系统负责根据用户查询从索引数据集中查找相关信息。
检索方法
| 方法 | 说明 | 依赖 | 优势 |
|---|---|---|---|
| 语义搜索 | 基于向量相似度查找语义相关内容 | 嵌入模型、向量数据库 | 适合基于含义的查询 |
| 关键词搜索 | 精确关键词匹配 | 关键词索引 | 适合精确术语搜索 |
| 全文搜索 | 基于全文索引技术 | 全文索引 | 平衡查准率与查全率 |
| 混合搜索 | 结合多种方法 | 所有索引 | 综合性能最优 |
检索策略
支持两种核心策略:
- 单数据集检索:使用单个数据集和 AI 模型路由查询
- 多数据集检索:跨多个数据集搜索,支持权重和评分配置
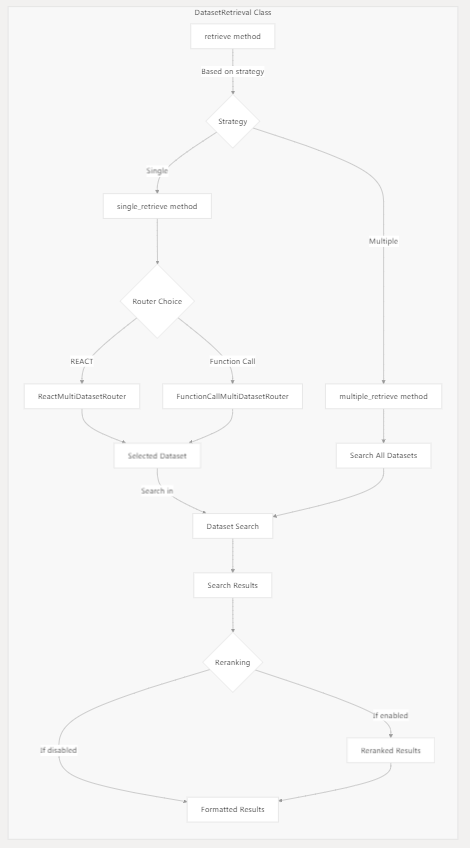
结果处理
- 格式化为文档上下文
- (可选)使用重排序模型重新排序
- 按相关性阈值过滤和评分
- 按相关性排序并返回调用方
与工作流集成
RAG 系统通过 知识检索节点 与 Dify 工作流系统集成:
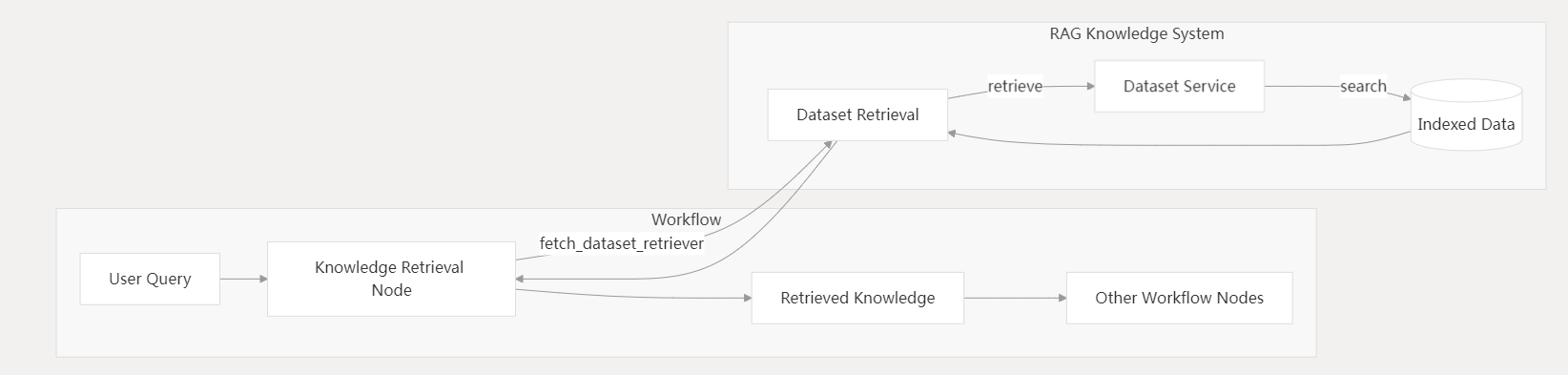
API 集成
服务 API 端点
RAG 知识系统提供了 RESTful API,以便与客户端应用程序集成:
| 端点 | 方法 | 描述 |
|---|---|---|
| /datasets | POST | 创建一个新的数据集 |
| /datasets | GET | 列出可用的数据集 |
| /datasets/{dataset_id} | GET | 获取数据集详情 |
| /datasets/{dataset_id} | POST | 更新数据集设置 |
| /datasets/{dataset_id} | DELETE | 删除一个数据集 |
| /datasets/{dataset_id}/document/create-by-text | POST | 从文本创建文档 |
| /datasets/{dataset_id}/document/create-by-file | POST | 从文件创建文档 |
| /datasets/{dataset_id}/documents/{document_id}/update-by-text | POST | 通过文本更新文档 |
控制台 API 端点
对于控制台内部使用,还存在以下额外的端点:
| 端点 | 方法 | 描述 |
|---|---|---|
| /console/datasets | 多种 | 控制台的数据集管理 |
| /console/datasets/{dataset_id}/documents | 多种 | 文档管理 |
| /console/datasets/{dataset_id}/documents/{document_id}/segments | 多种 | 文本段管理 |
速率限制与资源配额
系统实施了速率限制和配额强制管理措施,尤其是在云部署环境中:
知识检索速率限制
知识检索操作会实施速率限制:
knowledge_rate_limit = FeatureService.get_knowledge_rate_limit(tenant_id)
if knowledge_rate_limit.enabled:current_time = int(time.time() * 1000)key = f"rate_limit_{tenant_id}"redis_client.zadd(key, {current_time: current_time})redis_client.zremrangebyscore(key, 0, current_time - 60000)request_count = redis_client.zcard(key)if request_count > knowledge_rate_limit.limit:
资源限制
系统对各种资源实施了限制措施:
| 资源 | 描述 | 限制实施点 |
|---|---|---|
| 向量空间 | 限制嵌入存储量 | 在创建文档 / 进行索引期间 |
| 文档 | 限制文档数量 | 在上传文档期间 |
| 知识检索速率 | 限制检索频率 | 在进行知识检索期间 |