python数据结构和算法(3)
线性结构的存储方式
- 线性表:价格元素顺序的存放在一块连续的存储区域例,元素的顺序关系由它们的存储顺序自然表示
- 链表:将元素放在 通过链接构造起来的一系列存储块中,存储块是非连续的
顺序表
顺序表元素顺序的存放在一块连续的存储区里,存储方式有
- 一体式结构:地址和数据在一起
- 分离式结构:地址和数据是分开的
一体式存储方式
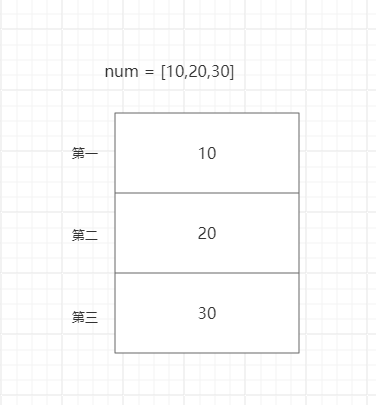
如图所示,假设num列表首元素的地址是0x11,由于列表所有的数据都是整型,大小都为4个字节,偏移量为4,因此
第一个元素 10 : 通过 0x11 偏移 4 * 0 个字节可以找到
第二个元素 20 :通过 0x11 偏移 4 * 1 个字节可以找到
第三个元素 30 :通过 0x11 偏移 4 * 2 个字节可以找到
由此可以总结出,超找数据的公式: 0x11 偏移 4 * (n-1) 个字节
分离式存储
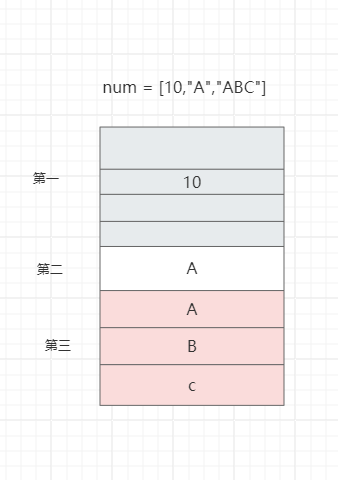
如图所示,假设num列表首元素的地址是0x11,由于列表中数据大小不固定,偏移量也不确定,无法通过偏移的方式查找。
虽然数据的的大小不固定,但是地址的大小为4个字节是固定的,所以我们可以不存储数据,而存储地址
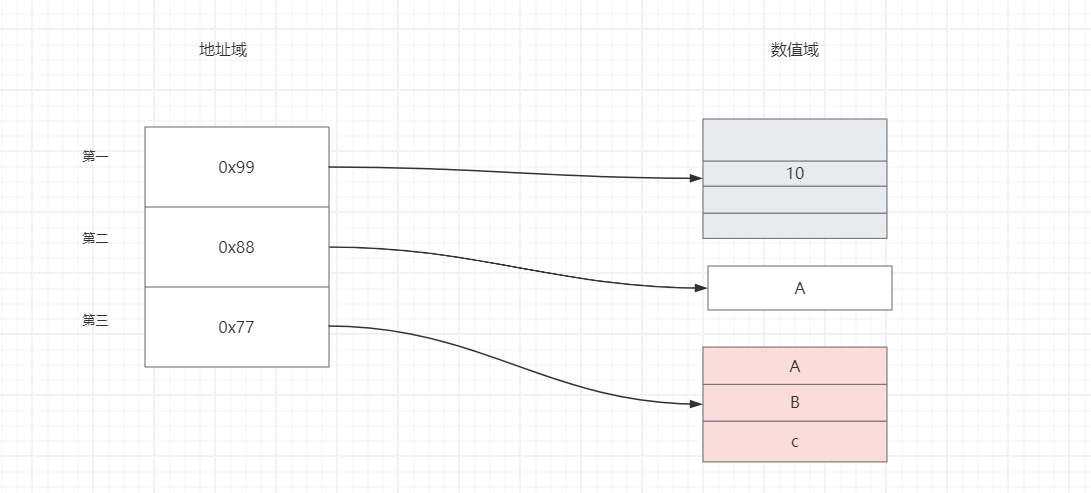
无论是一体式存储还是分离式存储,顺序表在获取数据的时候,直接通过下标偏移就可以找到数据所在空间的地址,而无序遍历后才可以获取地址,所以顺序表在获取地址操作时的时间复杂度为 O ( 1 ) O(1) O(1)
顺序表的存储结构
顺序表的完整信息包括两部分
- 数据区
- 信息区:即元素存储区的容量和当前表中已有的元素个数
顺序表的扩充
数据区更换存储可能构建更大的区域时,有两种扩充策略
- 每次扩充增加固定数目的存储位置,如每次扩充增加10个元素位置,这种策略可称为线性增长,特点是节省空间,但是扩充操作频繁,操作次数多
- 每次扩充容量加倍,如每次扩充增加一倍存储空间,特点是减少了扩充操作的执行次数,但可能会浪费空间资源,以空间换时间,推荐使用这种方式
元素存储区的替换
- 一体式存储的顺序表存储在连续的空间,则只能整体搬迁,即信息区和数据区都改变
- 分离式存储的顺序表可以只整体更换数据区,信息区的链接更新即可
顺序表的操作
增加元素
顺序表增加元素的三种方式
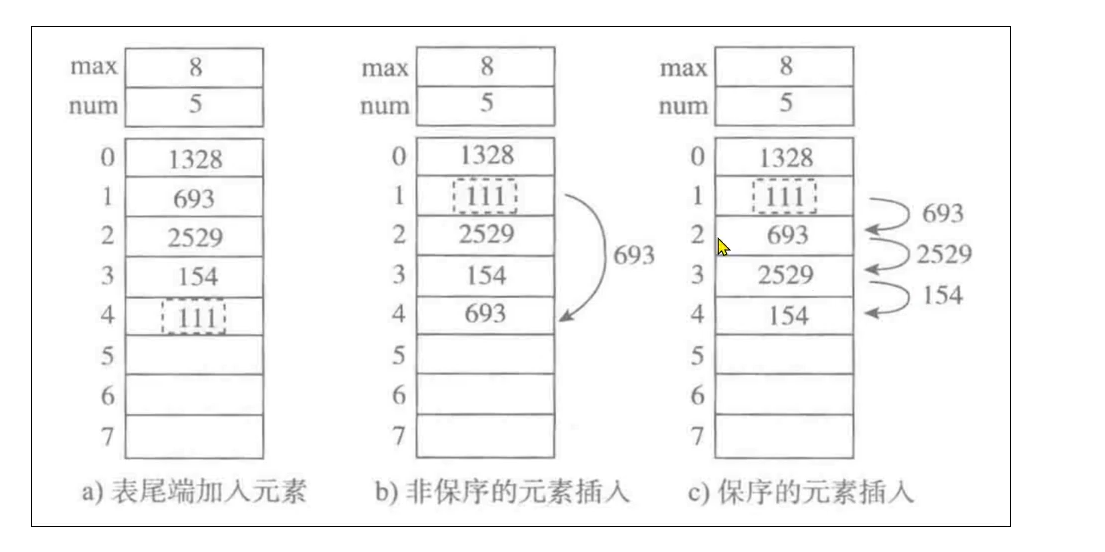
- 尾部加入元素,时间复杂度为 O ( 1 ) O(1) O(1)
- 非保序的加入元素,时间复杂度为 O ( 1 ) O(1) O(1)
- 保序的元素加入,时间复杂度为 O ( n ) O(n) O(n)
删除元素
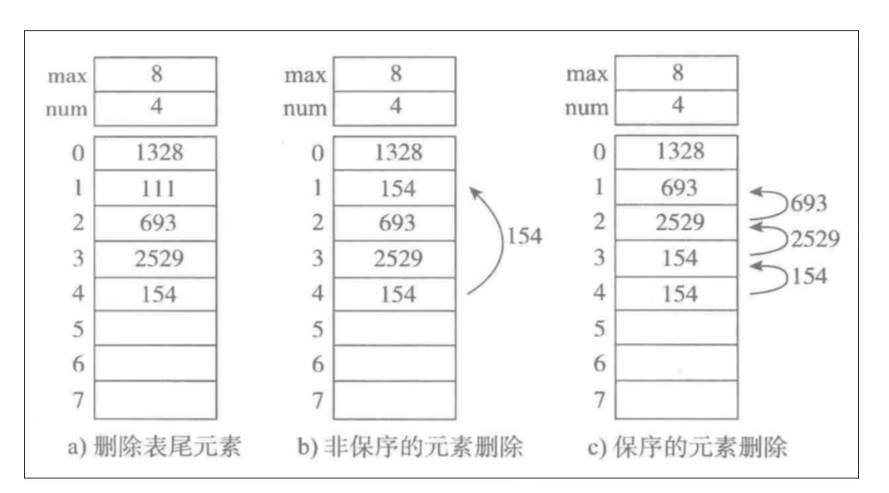
- 删除尾部元素,时间复杂度为 O ( 1 ) O(1) O(1)
- 非保序的元素删除,时间复杂度为 O ( 1 ) O(1) O(1)
- 保序的元素删除,时间复杂度为 O ( n ) O(n) O(n)
链表
顺序表存储方式的不足
顺序表存储时需要连续的内存空间,当要扩充顺序表示会出现以下两种情况
- 内存充足时容易找到连续的内存空间
- 内存不足时,不易找到连续的内存空间,完成不了空间扩充
链表结构
单向链表
单项链表是链表的一种形式,每个节点包含两个域:元素域和链接域
其中链接域中存放下一个节点的地址,最后一个节点的链接域则存储空值None
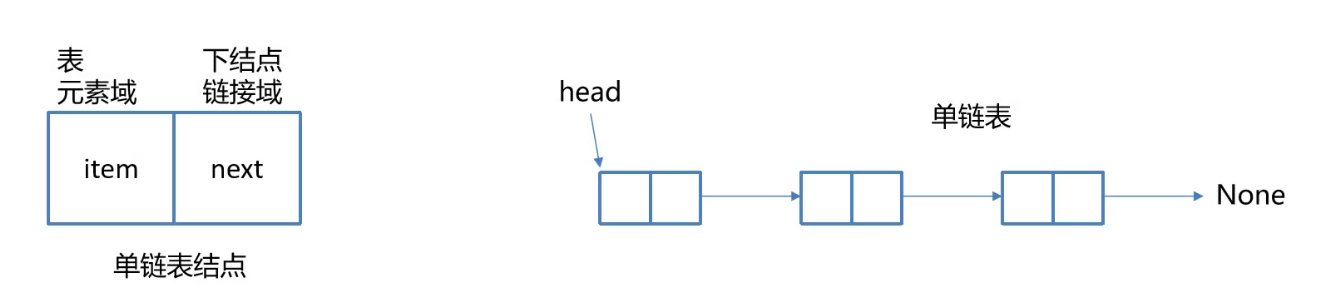
- 表元素域item用来存放具体的数据
- 链接域next用来存放下一个节点的地址
- 变量head 指向链表的头结点(首节点)位置,从head出发能找到表中的任意节点
链表的代码实现
分类
- 单向链表:节点有1个元素域(数值域) 和 1个链接域(地址域) 组成,每个节点的链接域都指向下个节点的地址,最后一个节点的地址域为None
- 单向循环列表:节点有1个元素域(数值域) 和 1个链接域(地址域) 组成,每个节点的链接域都指向下个节点的地址,最后一个节点的地址域为第一个节点的地址
- 双向链表:节点有1个元素域(数值域) 和 2个链接域(地址域) 组成,每个节点的前链接域指向上个节点的地址,每个节点的后链接域指向下个节点的地址,第一个节点的前链接域和最后一个后链接域为None
- 双向循环链表:节点有1个元素域(数值域) 和 2个链接域(地址域) 组成,每个节点的前链接域指向上个节点的地址,每个节点的后链接域指向下个节点的地址,第一个节点的前链接域指向最后一个节点的地址, 最后一个后链接域指向第一个节点的地址
单向链表实现
# 1. 创建SigleNode类,充当节点类,有元素域和链接域
class SingleNode:def __init__(self, item):self.item = itemself.next = None# 2. 创建SingleLinkList类,充当链表类,有头节点class SingleLinkedList(object):# 初始化属性,用head属性 指向链表的头节点def __init__(self,node=None):self.head = node# 判断链表是否为空def is_empty(self):return self.head is None# 链表长度def length(self):#记录当前节点cur = self.head# 记录链表长度count = 0while cur is not None:count += 1cur = cur.nextreturn count# 遍历链表def travel(self):# 记录当前节点cur = self.headwhile cur is not None:print(cur.item, end=" ")cur = cur.nextprint("") # 头部添加元素def add(self,item):# 创建新节点node = SingleNode(item)# 将新节点的链接域next指向头节点,即_head指向的位置node.next = self.head# 将链表的头_head指向新节点self.head = node# 尾部添加元素def append(self,item):# 创建新节点node = SingleNode(item)# 先判断链表是否为空,若是空链表,则将_head指向新节点if self.is_empty():self.head = node# 若不为空,则找到尾部,将尾节点的next指向新节点else:cur = self.headwhile cur.next is not None:cur = cur.nextcur.next = node# 指定位置添加元素def insert(self,pos,item):# 若指定位置pos为第一个元素之前,则执行头部插入if pos <= 0:self.add(item)# 若指定位置超过链表尾部,则执行尾部插入elif pos > (self.length()-1):self.append(item)# 找到指定位置else:node = SingleNode(item)count = 0# pre用来指向指定位置pos的前一个位置pos-1,初始从头节点开始移动到指定位置pre = self.headwhile count < (pos-1):count += 1pre = pre.next# 先将新节点node的next指向插入位置的节点node.next = pre.next# 将插入位置的前一个节点的next指向新节点pre.next = node# 删除节点def remove(self,item):cur = self.headpre = Nonewhile cur is not None:# 找到了指定元素if cur.item == item:# 如果第一个就是删除的节点 if not pre: self.head = cur.nextelse:# 将删除位置前一个节点的next指向删除位置的后一个节点pre.next = cur.nextbreakelse:# 继续按链表后移节点pre = curcur = cur.next# 查找节点是否存在def search(self,item):cur = self.headwhile cur is not None: if cur.item == item: return Trueelse:cur = cur.nextreturn False
对比
链表失去了顺序表随机读取的优点,由于增加了节点的链接域,空间开销比较大,但是对存储空间的是使用要相对灵活