lambda的惰性求值方法与及早求值方法
一、前言
上一篇在最后小永哥提到一个求值方法的概念,本次解释一下这两个概念。
二、详细说明
2.1、外部迭代和内部迭代
在开始求值方法解释之前,咱们先简单看一个案例,统计出所在的是北京的人员数量。
@Testpublic void forTest(){List<Person> personList = initPersonData();//统计在地址是北京的人数int count = 0;for (Person person : personList) {if(StringUtils.equals(person.getCity(),"北京")){count++;}}System.out.println(count);}private List<Person> initPersonData(){Person p1 = new Person();p1.setName("王虎");p1.setCity("北京");Person p2 = new Person();p2.setName("张三");p2.setCity("北京");Person p3 = new Person();p3.setName("李四");p3.setCity("天津");Person p4 = new Person();p4.setName("布隆");p4.setCity("南京");Person p5 = new Person();p5.setName("胡子");p5.setCity("南京");Person p6 = new Person();p6.setName("成武");p6.setCity("上海");Person p7 = new Person();p7.setName("柳屋");p7.setCity("上海");Person p8 = new Person();p8.setName("石方");p8.setCity("广州");List<Person> personsList = CollUtil.newArrayList();personsList.add(p1);personsList.add(p2);personsList.add(p3);personsList.add(p4);personsList.add(p5);personsList.add(p6);personsList.add(p7);personsList.add(p8);return personsList;}上次我们也提到过,这种for循环可读性差,代码量多,而且性能其实也低下,我们回忆一下这种for循环的原理-iterator,这种写法for (Person person : personList)其实只是语法糖,真正的运行的其实是通过判断iterator.hasNext()是否存在以及获取iterator.next()的方式完成的迭代。如下代码所示:
Iterator<Person> iterator = personList.iterator();while (iterator.hasNext()){Person person = iterator.next();if(StringUtils.equals(person.getCity(),"北京")){count++;}}从示例代码可以看出,循环其实是我们主动去调用iterator的方法完成的循环,这种由我们主动获取iterator,然后调用iterator的方式称之为外部迭代。
我们再回忆一下lambda的写法,为了明显一点,分为步完成,通过下面代码可以看到,我们先获取到了stream,然后调用stream的filter完成了过滤,最后再调用count统计了数量,整个过程都是在stream内部进行的,我们并没有显示的去进行循环操作,这种方式就是内部迭代。
Stream<Person> stream = personList.stream();Stream<Person> fs = stream.filter(p -> StringUtils.equals(p.getCity(), "北京"));long total = fs.count();System.out.println(total);2.2、惰性求值和及早求值
好了,外部迭代和内部迭代现象描述清楚了,从表象来看,stream这种方式实际上是分为筛选人员和计数两步,那么是不是说明进行了两次循环呢?确实,我也有这个疑问,我们想办法验证一下。
Stream<Person> stream = personList.stream();Stream<Person> fs = stream.filter(p -> {System.out.println("-------------------------------------");return StringUtils.equals(p.getCity(), "北京");});long total = fs.count();System.out.println(total);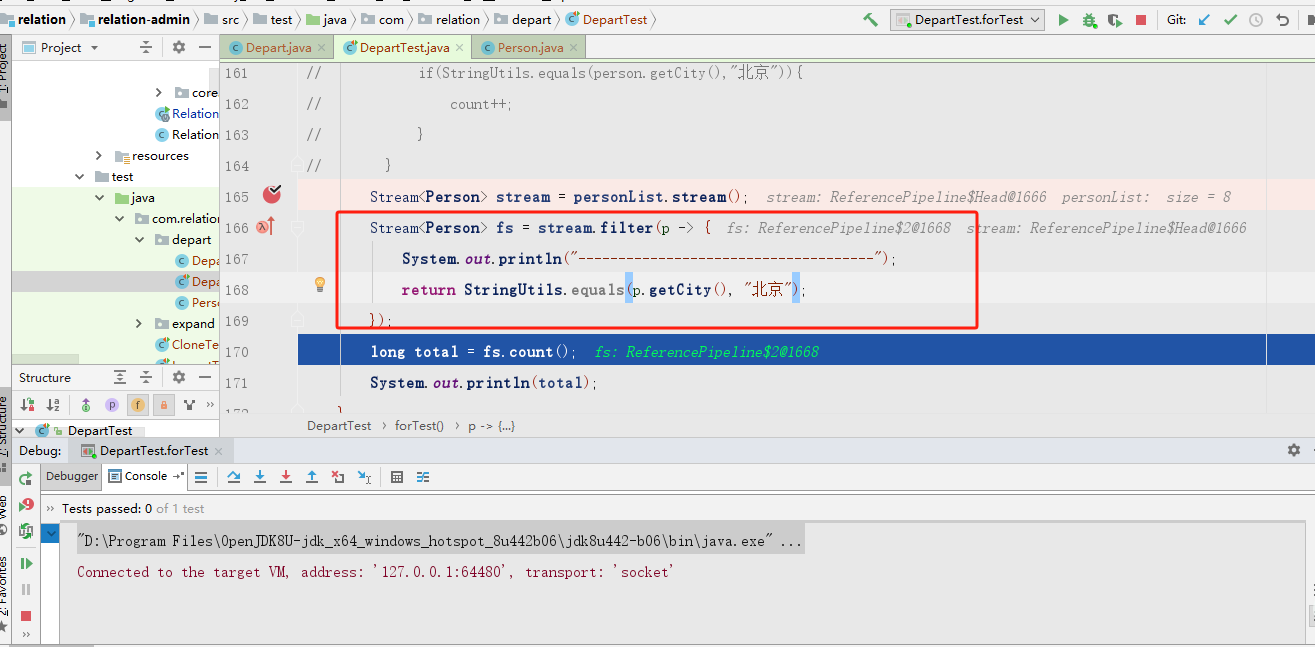
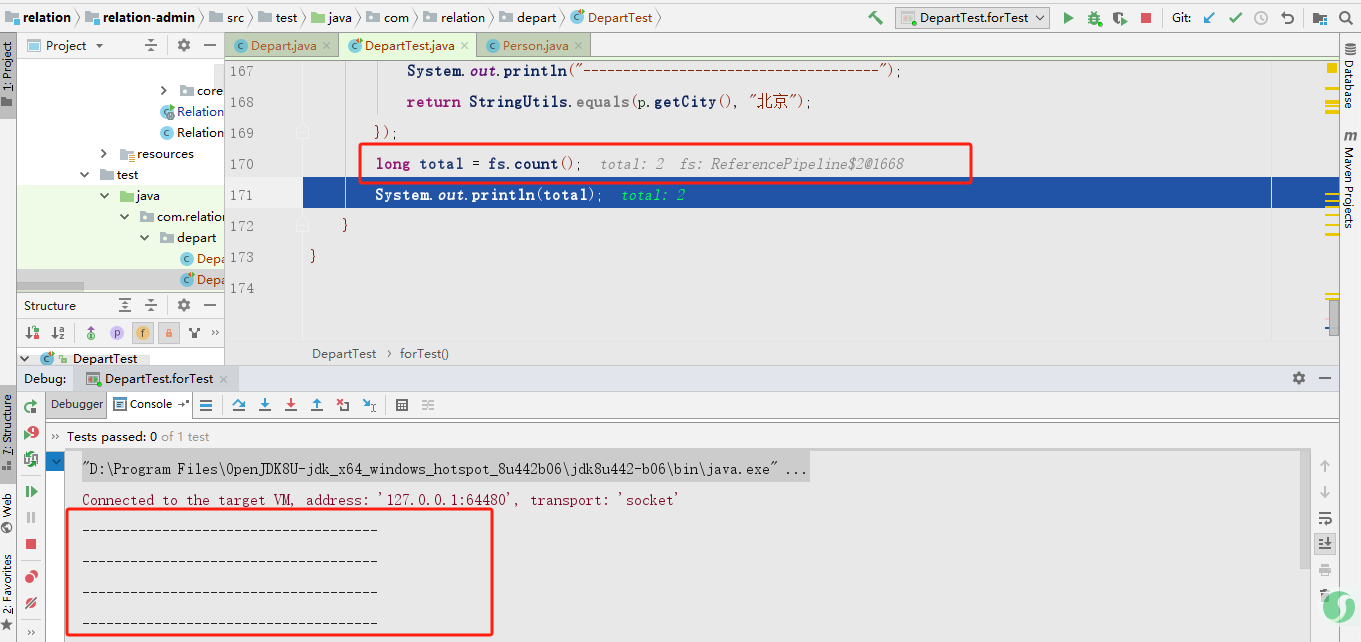
看到效果了吗?在截图1中,虽然已经执行了stream.filter,但实际上程序并未真正被执行,而是在调用count方法后才真正运行了程序。stream.filter底层只是对后续所要进行的操作进行了一个描述,就好比领导告诉我今天要完成的工作内容,事实上工作内容并没有完成,只是向我描述了要做什么,而count方法就是真正去根据这个描述去做实事了。这种方式和建造者模式很像,建造者模式也是前期进行一系列的操作和配置,但只有在最后一步才真正将对象构建出来。
我们可以总结了,像stream.filter这样只描述操作的方法,我们称之为惰性求值,而像count这样真正运行代码的方法,我们称之为及早求值。
那么还有哪些是惰性求值呢?比如说我们之前分享过的,像flatMap、filter、map、limit等等,都是惰性求值,而且大家发现没有,惰性求值都有一个特点,那就是返回值都是stream。
及早求值代表的就是真正能返回数据的方法,例如我们刚才提到的count、collect等就是及早求值。
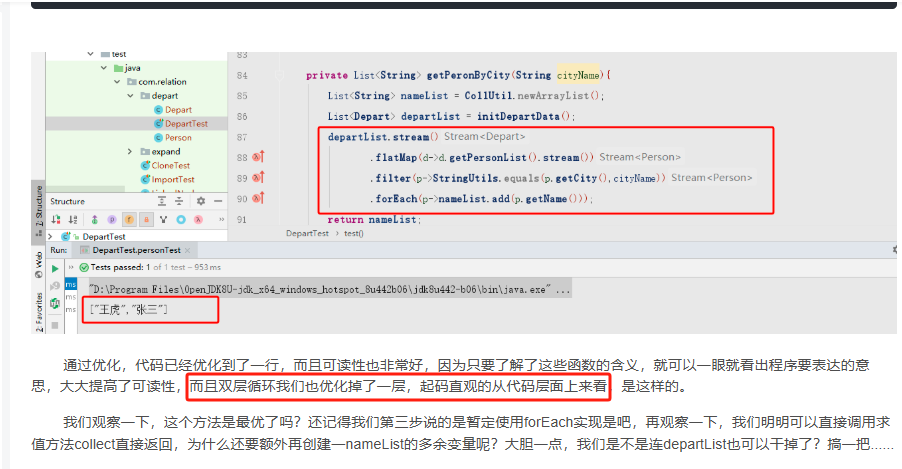
不知道大家还记得上期我说过,那个双层for循环优化了一层循环,当时我只是讲在直观代码层次来看是优化了一层,那么今天我们了解了惰性求值之后,就可以知道,其实就是优化了一层循环,因为惰性求值可以进行积累但并不会运行代码,只有在最后调用及早求值方法时才会迭代。
三、结语
本篇其实是上一篇的一个延伸,对上一篇遗留的一些问题进行了一些解释,希望可以对老铁们有帮助,谢谢大家,晚安........