阿里云Ubuntu 22.04 64位搭建Flask流程(亲测)
cd /home 进入home盘
安装虚拟环境:
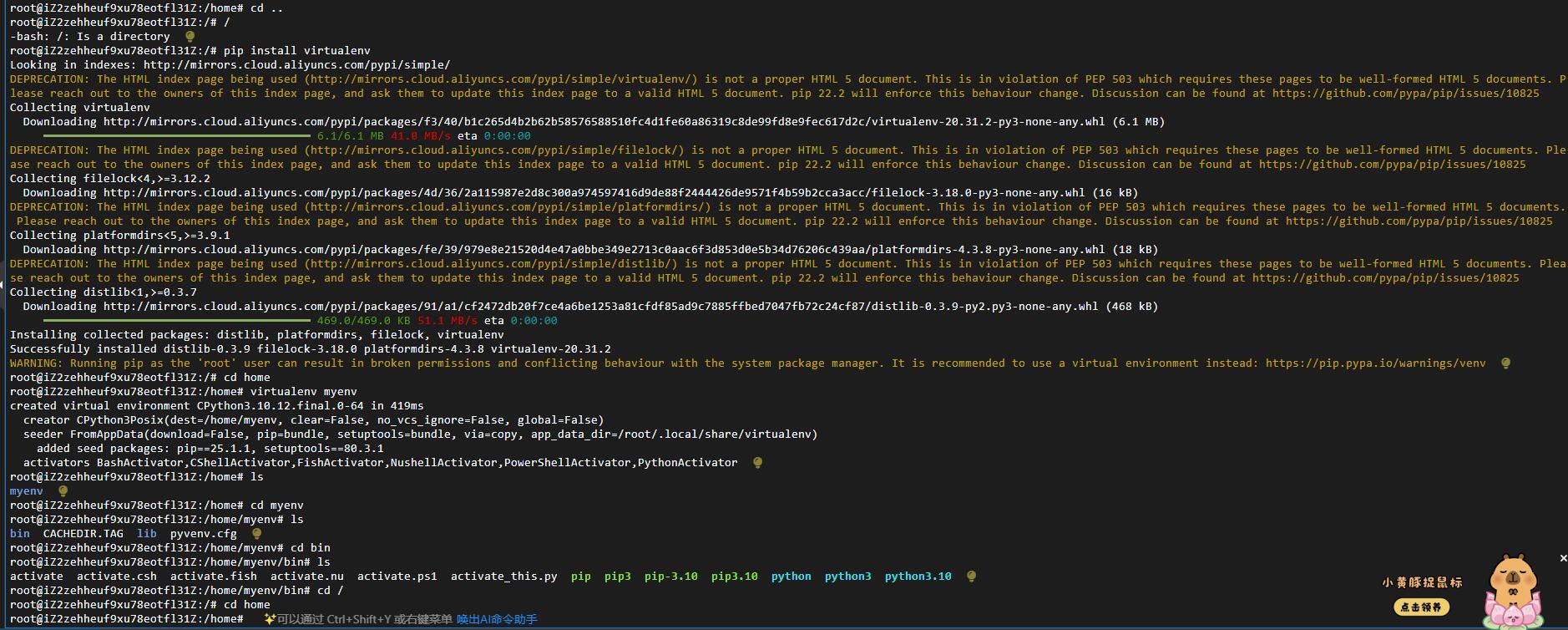
1、安装virtualenv
pip install virtualenv
2.创建新的虚拟环境:
virtualenv myenv
3、激活虚拟环境(激活环境可以在当前环境下安装包)
source myenv/bin/activate
此时,终端会更改为显示已被激活的虚拟环境名称,(myenv)
4、退出虚拟环境
deactivate
特别的为虚拟环境制定python版本
virtualenv -p=/usr/bin/python<version> path/to/new/virtualenv/
安装的过程:

创建python文件(app.py)
cd /home/myenv
touch app.py
安装flask
pip install Flask
编写app.py文件
nano app.py
from flask import Flaskapp = Flask(__name__)@app.route('/', methods=['GET'])
def hello_world():return 'Hello Flask!'if __name__ == '__main__':app.run(host='0.0.0.0', port=5000)
编写完成
ctrl+O 保存,提示然后回车
ctrl+x 退出
安装gunicorn
pip install gunicorn
gunicorn的一些使用命令:
查看gunicorn的进程数树:
pstree -ap|grep gunicorn
关闭gunicorn:
kill -9 3308
重启gunicorn;
kill -HUP 3308
然后用gunicorn启动app.py文件
gunicorn -w 4 -b 0.0.0.0:5000 app:app
参数含义
-w:工作进程数-b:绑定的地址和端口app:Flask 启动的 Python 文件名app:脚本中创建的 Flask 对象名
然后报错了,提示超时tiomeout
[2025-06-09 16:29:31 +0800] [48889] [CRITICAL] WORKER TIMEOUT (pid:48892)
[2025-06-09 16:29:31 +0800] [48892] [ERROR] Error handling request (no URI read)
Traceback (most recent call last):File "/home/myenv/lib/python3.10/site-packages/gunicorn/workers/sync.py", line 133, in handlereq = next(parser)File "/home/myenv/lib/python3.10/site-packages/gunicorn/http/parser.py", line 41, in __next__self.mesg = self.mesg_class(self.cfg, self.unreader, self.source_addr, self.req_count)File "/home/myenv/lib/python3.10/site-packages/gunicorn/http/message.py", line 259, in __init__super().__init__(cfg, unreader, peer_addr)File "/home/myenv/lib/python3.10/site-packages/gunicorn/http/message.py", line 60, in __init__unused = self.parse(self.unreader)File "/home/myenv/lib/python3.10/site-packages/gunicorn/http/message.py", line 271, in parseself.get_data(unreader, buf, stop=True)File "/home/myenv/lib/python3.10/site-packages/gunicorn/http/message.py", line 262, in get_datadata = unreader.read()File "/home/myenv/lib/python3.10/site-packages/gunicorn/http/unreader.py", line 36, in readd = self.chunk()File "/home/myenv/lib/python3.10/site-packages/gunicorn/http/unreader.py", line 63, in chunkreturn self.sock.recv(self.mxchunk)File "/home/myenv/lib/python3.10/site-packages/gunicorn/workers/base.py", line 204, in handle_abortsys.exit(1)
SystemExit: 1解决办法:
错误原因:接口返回时间超时。默认情况下,Gunicorn 超时时间为30秒。如果接口30秒内没有返回结果,Gunicorn 会弹出超时错误,并且会杀死flask服务重启。
解决方法
解决方法是在启动命令中加大超时参数--timeout。样例,设置超时时间为200秒
# 单位是秒gunicorn -w 4 -b 0.0.0.0:5000 --timeout 200 app:app
重新启动
gunicorn -w 4 -b 0.0.0.0:5000 --timeout 200 app:app
注意启动文件必须实在myenv文件夹下,否则不会成功
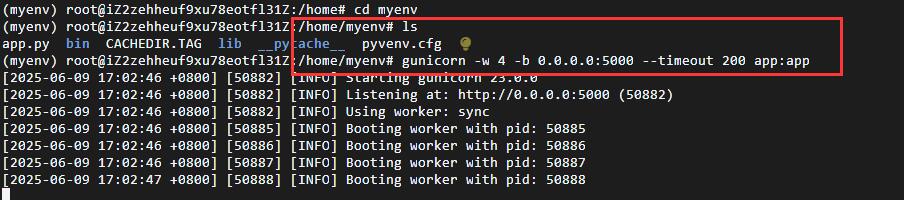
再次启动就成功了!!
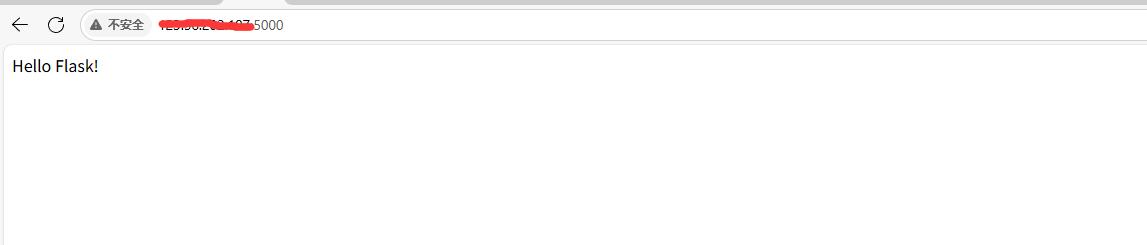
直接访问:记得使用阿里云公网ip,加端口号。(安全组添加5000端口)
文件配置 Gunicorn 参数:
myenv下创建gunconf.py
# 是否开启debug模式
debug = False
# 访问地址
bind = "0.0.0.0:5000"
# 工作进程数
workers = 4
# 工作线程数
threads = 2
# 超时时间
timeout = 200
# 输出日志级别
loglevel = 'debug'
# 存放日志路径
pidfile = "log/gunicorn.pid"
# 存放日志路径
accesslog = "log/access.log"
# 存放日志路径
errorlog = "log/debug.log"
# gunicorn + apscheduler场景下,解决多worker运行定时任务重复执行的问题
preload_app = True
myenv下分别创建"log/gunicorn.pid"、"log/access.log"、"log/debug.log"


然后用文件启动:
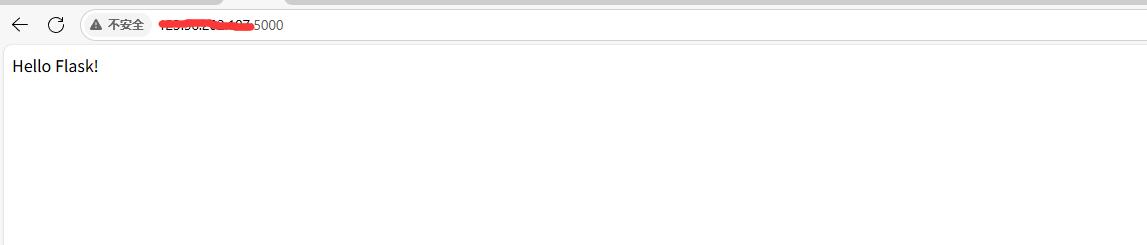
至此搭建完毕!
gunicorn的一些参考命令介绍:
https://cloud.tencent.com/developer/article/1902723
一些unbantu的命令:
复制文件:
cp example.txt /home/user/documents/
删除文件命令:
rm app.py
创建文件命令:
touch app.py
创建文件夹:
mkdir myfolder
查看端口被占用的情况:
1、查找特定端口的占用情况:如果您知道某个特定端口被占用,可以结合grep命令来查找。例如,如果您想查找80端口的使用情况,可以输入以下命令。
netstat -tln | grep 802、查找占用端口的进程:使用以下命令来查找占用特定端口的进程。例如,如果您想查找占用80端口的进程,可以输入以下命令。
lsof -i:80
3、终止进程
kill -9 80