Python Day45 学习(日志Day13-14复习)
补充:关于“数据预处理”
数据预处理包含以下部分:
-
缺失值处理
- 填补缺失值(如用均值、中位数、众数等填充)
- 删除缺失值较多的样本或特征
-
异常值处理
- 检测和剔除异常值
- 或用合理值替换异常值
-
数据类型转换
- 将字符串、日期等类型转换为合适的数值或时间类型
-
特征编码
- 标签编码(Label Encoding)
- 独热编码(One-Hot Encoding)
-
特征缩放
- 归一化(Normalization)
- 标准化(Standardization)
-
数据去重
- 删除重复的样本
-
特征构造与选择
- 新特征的生成
- 选择对模型有用的特征
为什么要进行数据预处理?
- 提高数据质量:原始数据通常存在缺失、异常、重复等问题,预处理可以提升数据的准确性和可靠性。
- 提升模型效果:很多机器学习算法对数据的分布、类型等有要求,预处理可以让模型更好地学习数据规律,提高预测准确率。
- 加快模型训练速度:经过预处理的数据更规范,能让模型更快收敛,减少训练时间。
- 避免错误和偏差:不规范的数据容易导致模型训练出错或结果偏差。
补充:关于“热力图”的阅读
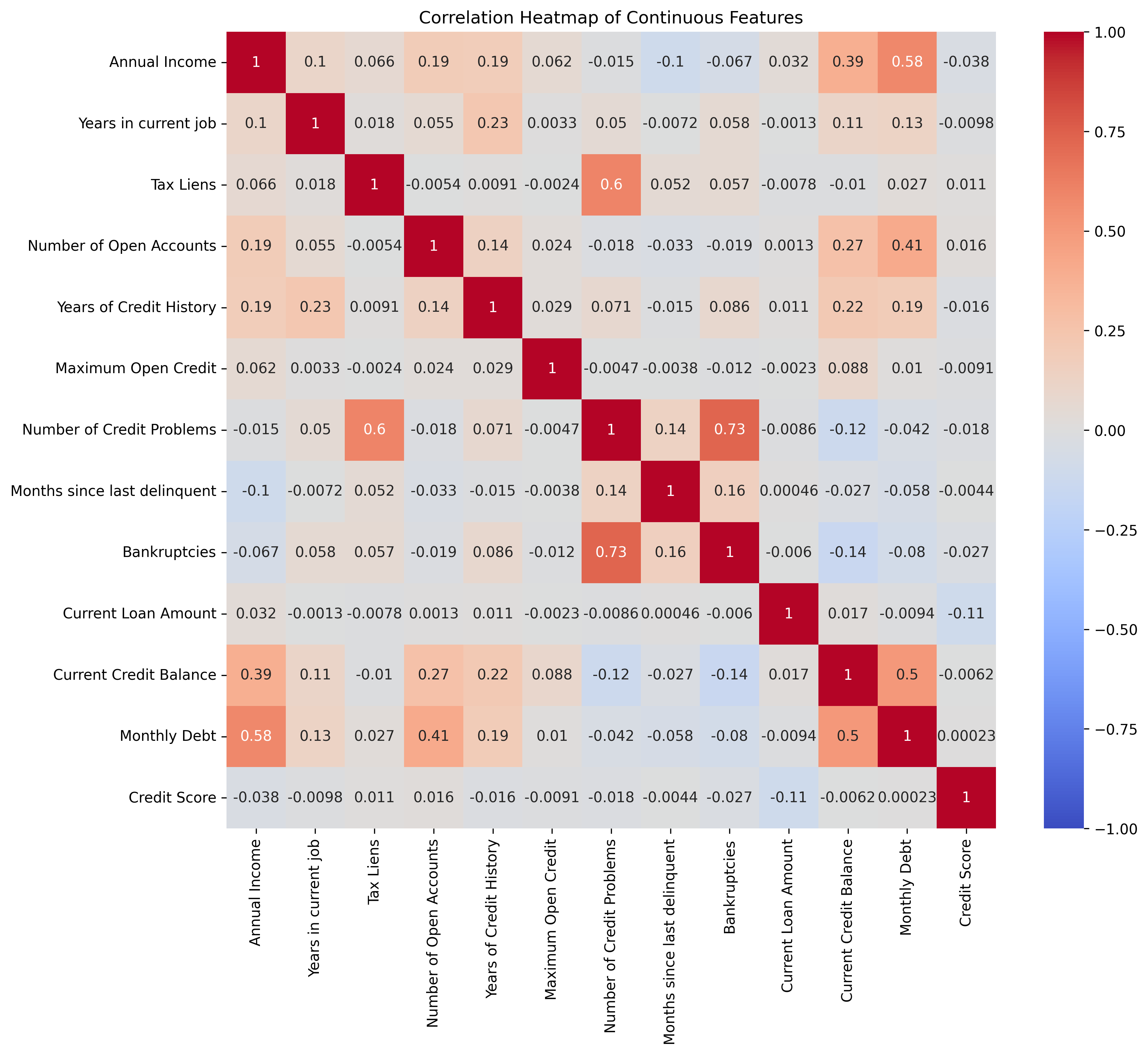
如何读这张热力图
- 对角线:从左上到右下的对角线,相关系数都是1,因为每个特征和自己完全相关。
- 非对角线格子:表示两个不同特征之间的相关性。例如,Annual Income 和 Monthly Debt 的相关系数是 0.58,说明它们正相关且相关性较强。
- 颜色条(右侧):显示颜色和相关系数数值的对应关系。1为深红,-1为深蓝,0为白色或浅色。
- 正相关:格子为红色,数值为正,说明两个特征同时增大或减小。
- 负相关:格子为蓝色,数值为负,说明一个特征增大时另一个减小。
具体解读举例
- Annual Income 和 Monthly Debt:相关系数为 0.58,格子为红色,说明年收入越高,月负债也越高,且关系较强。
- Annual Income 和 Credit Score:相关系数为 -0.038,格子接近白色,说明几乎没有相关性。
- Bankruptcies 和 Number of Credit Problems:相关系数为 0.73,格子为深红色,说明二者高度正相关。
手写笔记复习


今日复习到这里,明日复习"子图的绘制”,并用“心脏病数据集”对数据预处理部分进行学习情况检测,继续查漏补缺。比训练营的正常学习进度落后了很多,但没办法,学得卡住了。既然卡住了就说明前面的内容自己还是没有彻底掌握,那就重头再来,待前面彻底掌握再进行更深入内容的学习。一切以“掌握”为主,继续加油吧!!!@浙大疏锦行