推理式奖励模型:使用自然语言反馈改进强化学习效果
论文标题
Critique-GRPO: Advancing LLM Reasoning with Natural Language and Numerical Feedback
论文地址
https://arxiv.org/pdf/2506.03106
代码地址
https://github.com/zhangxy-2019/critique-GRPO
作者背景
香港中文大学,剑桥大学,上海人工智能实验室
动机
强化学习赋予了模型主动探索环境、自行寻找解决策略的能力,但当前的强化训练方法为策略模型提供的反馈信息较少 —— 通常只使用纯粹的数值奖励,甚至只有在对比最终结果后才生成这一学习信号,这导致了模型学习困难,例如迟迟探索不出解题方案、性能指标进入平台期不再提升等。这一困境显而易见,如同人类学习过程一样,如果光提供最终答案而不带过程与思路,一些难题可能始终学不会
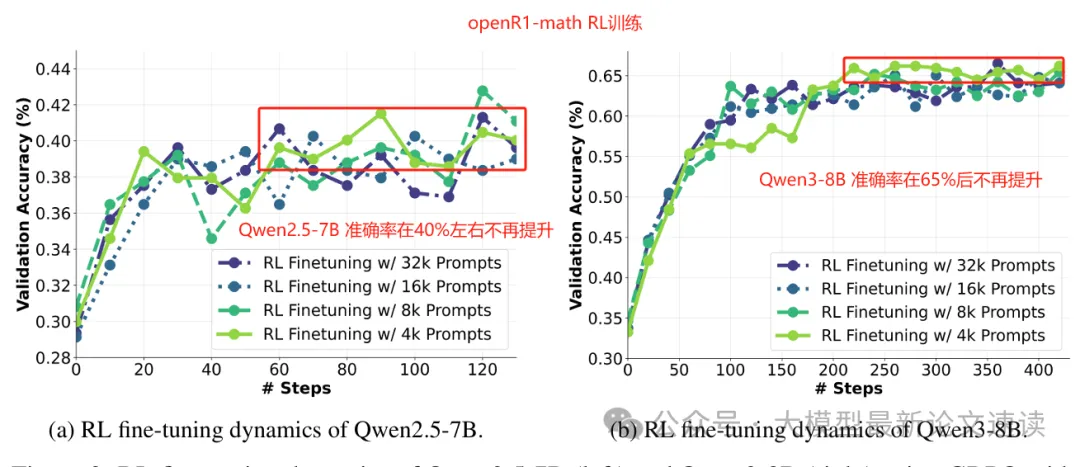
于是作者试图利用推理模型来生成奖励,这样便能在为策略模型提供标量反馈的同时,也提供自然语言格式的打分理由
此工作参考了 LUFFY(路飞): 使用DeepSeek指导Qwen强化学习
本文方法
本文提出Critique-GRPO,核心思想是在奖励模型对采样结果进行评分后,将打分的理由反馈给策略模型要求重答,由此产生更可靠的探索路径,整体流程如下图所示:
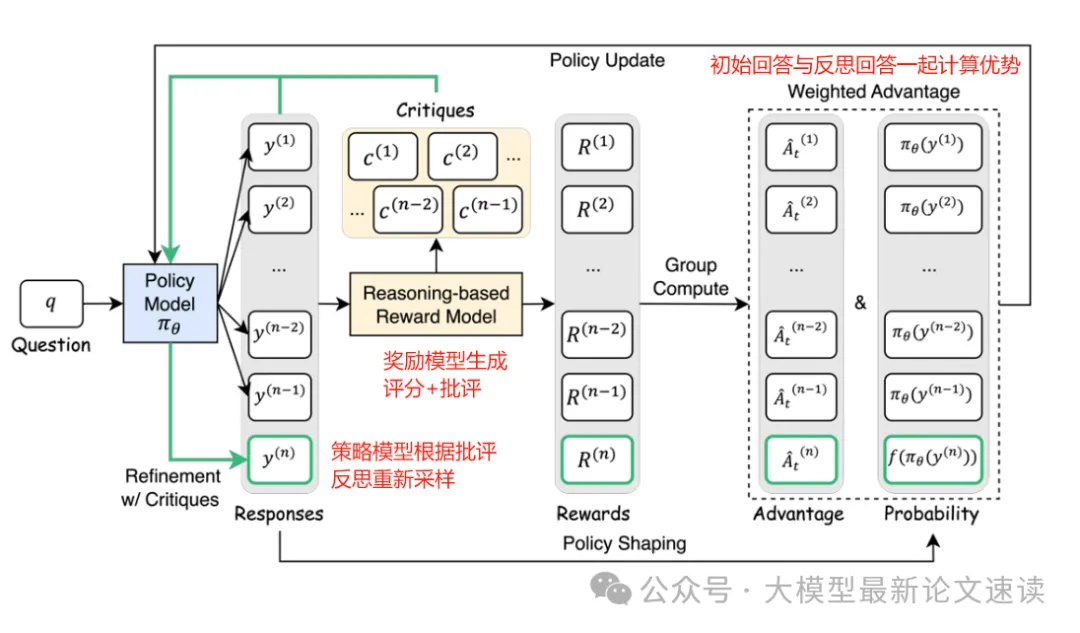
对于问题q,策略模型首先生成若干采样,送入推理式奖励模型(GPT-4o)获取标量评分结果与自然语言批评。为了确保质量,这里还会检验评分与规则验证结果是否一致,不一致时则重新生成评论。
策略模型根据自然语言批评,重新生成回答,并再次送入奖励模型获取评分结果。和 Luffy 一样,引入外部信息会造成分布偏移,需要进行平衡处理,在 Luffy 中作者使用的是重要性采样(优势加权),本文使用的是更简单的比例控制:只抽取部分重答结果加入后续训练,以控制两种分布的混合比例。为了提高重答样本的引导作用,这里有限抽取正确的重答样本

在策略优化阶段,作者使用了带“梯度塑性”的GRPO目标函数,简单来说就是赋予回答低概率词更大的权重,从而让模型更倾向于探索。具体可参见之前介绍 Luffy 的文章 LUFFY(路飞): 使用DeepSeek指导Qwen强化学习
除梯度重加权外,作者还移除了GRPO中对策略更新的限制项,包括概率比值剪切和KL散度惩罚。去掉这些限制可以让模型策略进行更大幅度的更新
实验结果
一、前置实验:CoT反馈能修正多少错误
作者探索了利用自然语言反馈帮助模型识别错误并优化的潜力,设计了三组不同类型的批评,让模型做数学推理任务,一个问题采样多次,如果某个采样回答错误,则利用批评信息让模型反思重答
- CoT 批评: 提供正确答案、评价结论(正确/错误)与CoT理由
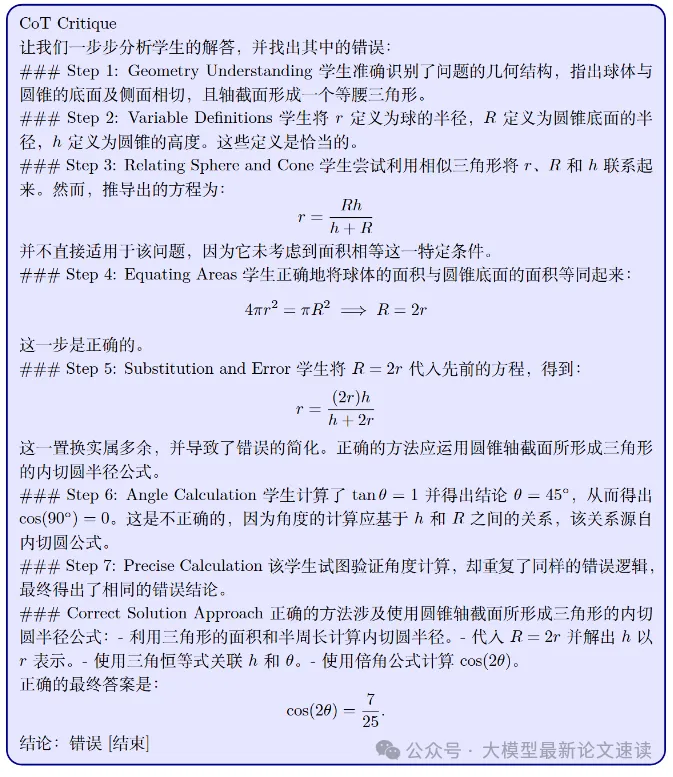
- 带答案的批评: 提供正确答案、评价结论(正确/错误)

- 无答案的批评: 只有评价结论(正确/错误)

指标
- 批评有效率: 格式正确、可用的批评占比
- 改进率: 在所有错误采样中,重答后正确的比率
- 持续失败问题的批评率: 所有采样都错误的问题中,收到有效批评占比
- 持续失败问题的改进率: 所有采样都错误的问题中,重答后正确的比率
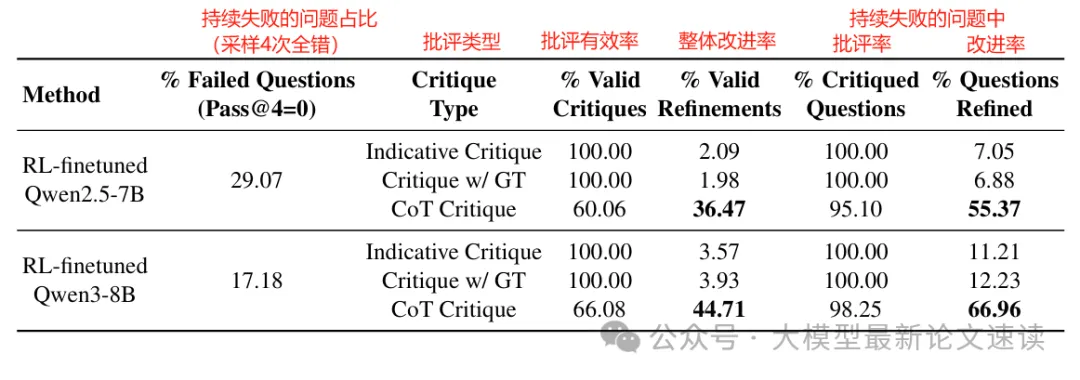
以Qwen3-8B模型为例,可见在经过数学问题的RL训练之后,仍然有17%的问题反复采样都无法解决;而利用带CoT理由的批评进行反思后,有66%的错误问题重答正确,44%的错误采样重答正确,这还是在CoT格式可能不正确的情况下得到的收益;相比之下,仅靠结果反馈很难纠正模型错误
二、Critique-GRPO实验结果
作者在8个推理基准上进行测试,包括数学推理和常识问答
对照组
- SFT/RAFT/Refinement FT/Critique FT/CITL-FT: 各种监督微调
- R1-GRPO: 使用标量奖励(错误0正确1)的 GRPO 算法微调
- LUFFY: 融入专家示范来增强 R1-GRPO,平衡模仿与探索能力
- Simple Critique: 实验组的变体,使用上述“带答案的批评”代替CoT
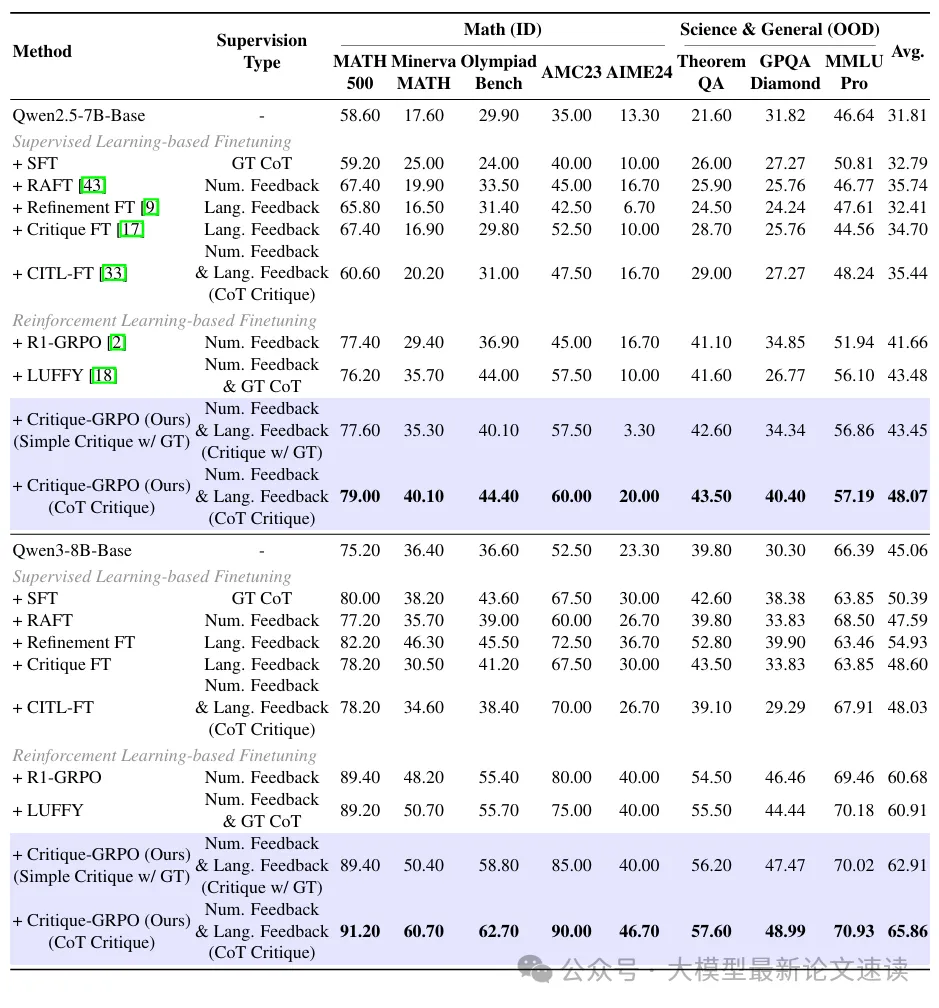
可见,在所有任务中Critique-GRPO均显著超越了现有的SOTA方法
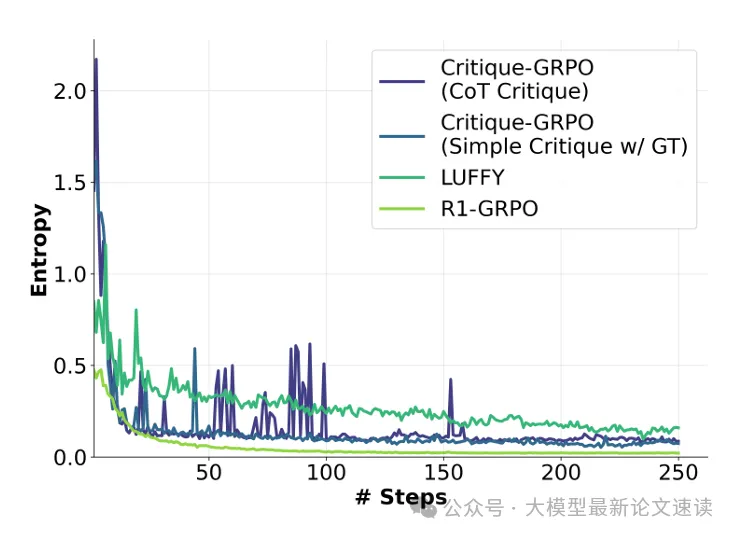
上图展示了各RL方法在训练过程中的熵变化曲线,可见Critique-GRPO方法(深蓝)通常比R1-GRPO(浅绿)的熵更高、波动更大,这是因为梯度塑性方法鼓励稀有动作,从而引起熵增,但这些稀有动作一旦导致错误,也会受到更严厉的惩罚,从而及时修正错误
值得注意的是,LUFFY(绿色)在训练过程中的熵比Critique-GRPO还要高,但表中的实验结果却表明后者效果更好,这说明了“高熵”并不总能保证通过探索实现高效学习,探索的质量比探索的频率更重要。而LUFFY中之所以会出现更高的熵,是因为它过于依赖专家示范,不如Critique-GRPO更贴近模型当前的能力,以致于策略模型更加频繁地探索新模式
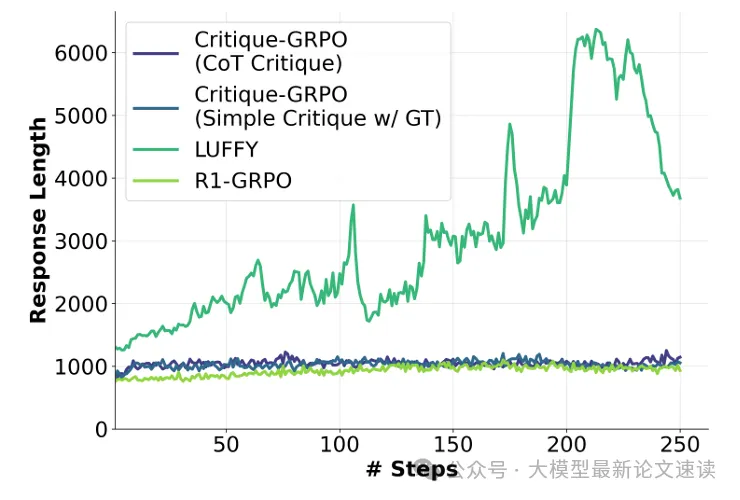
上图展示了各RL方法在训练过程中,平均响应长度的变化趋势,同样地,Critique-GRPO的响应比R1更长,但不如LUFFY,说明更长的响应并不一定意味着更有效的探索。LUFFY之所以表现更长的响应是因为它模仿了回答详细的专家,体现更频繁的探索;而Critique-GRPO在训练过程中,能更高效地识别错误并进行有针对性的改进,所以即使也倾向于探索,但不必要的自我反思更少