java复习 03
居然已经6.5了!?~~来得及来得及。。扎扎实实踏踏实实我可以的我可以的!!
1 java里面的自动装箱
在 Java 中,自动装箱(Autoboxing)是一种编译器特性,允许基本数据类型(如int、double、boolean等)与对应的包装类(如Integer、Double、Boolean等)之间进行自动转换。这一特性在 Java 5.0 版本中引入,大大简化了基本类型与对象类型之间的交互。
自动装箱的核心机制
-
基本类型 → 包装类
当需要一个包装类对象,但传入的是基本类型时,编译器会自动调用包装类的valueOf()方法进行转换。 -
包装类 → 基本类型
当需要一个基本类型,但传入的是包装类对象时,编译器会自动调用包装类的xxxValue()方法(如intValue()、doubleValue())进行转换。
常见场景示例
1. 直接赋值
java
// 自动装箱:int → Integer
Integer obj = 10; // 等价于 Integer obj = Integer.valueOf(10);// 自动拆箱:Integer → int
int primitive = obj; // 等价于 int primitive = obj.intValue();
2. 方法参数传递
java
// 自动装箱:double → Double
void printDouble(Double num) {System.out.println(num);
}printDouble(3.14); // 传入基本类型 double,自动转换为 Double 对象// 自动拆箱:Boolean → boolean
void checkStatus(boolean status) {System.out.println(status);
}checkStatus(new Boolean(true)); // 传入 Boolean 对象,自动转换为 boolean
3. 集合框架
java
import java.util.ArrayList;
import java.util.List;List<Integer> list = new ArrayList<>();
list.add(1); // 自动装箱:int → Integer
list.add(2); // 自动装箱:int → Integerint first = list.get(0); // 自动拆箱:Integer → int
4. 算术运算
java
Integer a = 5;
Integer b = 10;
int sum = a + b; // 自动拆箱:Integer → int,执行加法运算
注意事项
-
性能开销
自动装箱会创建额外的对象,频繁操作可能导致性能下降(如循环中装箱)。建议在性能敏感的场景下直接使用基本类型。 -
空指针异常(NullPointerException)
当包装类为null时,自动拆箱会触发异常。java
Integer nullable = null; int value = nullable; // 抛出 NullPointerException -
缓存机制
部分包装类(如Integer)对常用值(如-128到127)有缓存,相同值可能指向同一对象。java
Integer a = 100; Integer b = 100; System.out.println(a == b); // true,因为缓存机制Integer c = 200; Integer d = 200; System.out.println(c == d); // false,超出缓存范围
总结
自动装箱是 Java 编译器提供的语法糖,简化了基本类型与包装类之间的转换。理解其内部机制(valueOf()和xxxValue()方法)有助于编写更安全、高效的代码,避免潜在的性能问题和空指针异常。
2 语法糖。。哈哈!
“语法糖”(Syntactic Sugar)是计算机科学中的术语,指的是编程语言中添加的一种语法特性,它不会改变语言的功能或表达能力,但可以让代码更易读、更简洁或更符合人类直觉。简单来说,语法糖是对底层实现的一种 “包装”,让程序员用更少的代码完成相同的功能。
核心特点
- 不改变功能:语法糖只是语法层面的改进,不会增加语言的核心能力。
- 编译时转换:编译器会在编译阶段将语法糖转换为等价的底层代码。
- 提高可读性:让代码更符合人类思维习惯,减少冗余。
Java 中的语法糖示例
1. 自动装箱与拆箱
- 语法糖:直接将基本类型赋值给包装类,反之亦然。
- 底层实现:编译时调用
valueOf()和xxxValue()方法。
java
// 语法糖
Integer obj = 10; // 自动装箱
int primitive = obj; // 自动拆箱// 编译后等价代码
Integer obj = Integer.valueOf(10);
int primitive = obj.intValue();
2. 增强 for 循环(foreach)
- 语法糖:简化集合和数组的遍历。
- 底层实现:编译时转换为普通的
for循环或迭代器。
java
// 语法糖
List<String> list = Arrays.asList("a", "b", "c");
for (String item : list) {System.out.println(item);
}// 编译后等价代码
for (Iterator<String> it = list.iterator(); it.hasNext(); ) {String item = it.next();System.out.println(item);
}
3. 字符串拼接(+运算符)
- 语法糖:用
+拼接字符串。 - 底层实现:编译时转换为
StringBuilder或StringBuffer。
java
// 语法糖
String result = "Hello" + " " + name;// 编译后等价代码(简化版)
StringBuilder sb = new StringBuilder();
sb.append("Hello");
sb.append(" ");
sb.append(name);
String result = sb.toString();
4. 变长参数(Varargs)
- 语法糖:允许方法接受不定数量的参数。
- 底层实现:编译时转换为数组。
java
// 语法糖
void printAll(String... args) {for (String arg : args) {System.out.println(arg);}
}// 编译后等价代码
void printAll(String[] args) {for (int i = 0; i < args.length; i++) {System.out.println(args[i]);}
}
5. Lambda 表达式(Java 8+)
- 语法糖:简化匿名函数的写法。
- 底层实现:编译时转换为函数式接口的实例。
java
// 语法糖
list.forEach(item -> System.out.println(item));// 编译后等价代码(简化版)
list.forEach(new Consumer<String>() {@Overridepublic void accept(String item) {System.out.println(item);}
});
语法糖的优缺点
优点
- 提高开发效率:减少模板代码,降低出错概率。
- 代码可读性提升:更简洁的语法更符合人类思维。
- 保持向后兼容:在不破坏旧代码的前提下引入新特性。
缺点
- 隐藏实现细节:可能导致开发者对底层原理理解不足。
- 调试复杂度增加:编译后的代码与源码结构不同,调试时可能需要额外分析。
- 性能开销:部分语法糖(如字符串拼接)可能在编译后产生更多的对象创建,影响性能。
总结
语法糖是编程语言为提高开发体验而设计的 “甜蜜” 特性,它让代码更优雅,但不会改变程序的本质功能。理解语法糖的底层实现有助于写出更高效、更安全的代码,避免潜在的性能问题或逻辑错误。
3 类型转换题目
关于 Java 中的类型转换,下列说法正确的是 ABC
A byte 转 int 是自动类型提升
B int 转 byte 可能溢出
C double 转 int 会丢失小数部分
D float 转 long 更安全
解析:
A 选项:在 Java 中,byte 是 8 位整数类型,int 是 32 位整数类型,当 byte 类型向 int 类型转换时,会自动进行类型提升,将 byte 的值扩展为 int 类型(高位补符号位),所以 A 正确。
B 选项:int 是 32 位,byte 是 8 位,当 int 转 byte 时,会截取 int 的低 8 位,如果 int 的值超出了 byte 的表示范围(-128 到 127 ),就会发生溢出,结果可能不符合预期,所以 B 正确。
C 选项:double 是浮点类型,转 int 时,会舍弃小数部分,只保留整数部分,所以 C 正确。
D 选项:float 是 32 位浮点类型,long 是 64 位整数类型,float 转 long 时,由于 float 的取值范围和精度特点,可能会出现数据丢失或不准确的情况(比如 float 能表示的大数超出 long 范围,或者小数部分等处理问题 ),并不安全,所以 D 错误。
3 File相关
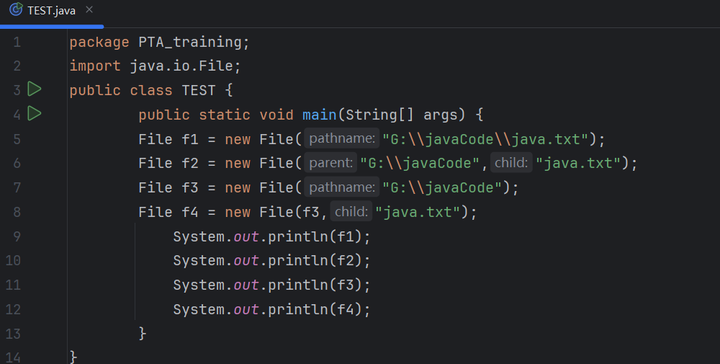
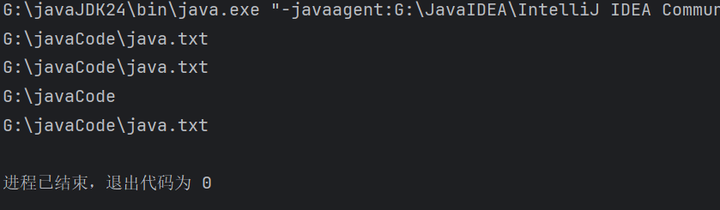
1 File 类概述和构造方法
File: 它是文件和目录路径名的抽象表示
文件和目录是可以通过 File 封装成对象的。
对于 File 而言,其封装的并不是一个真正存在的文件,仅仅是一个路径名而已。它可以是存在的,也可以是不存在的。将来是要通过具体的操作把这个路径的内容转换为具体存在的
| 方法名 | 说明 |
|---|---|
| File(String pathname) | 通过将给定的路径名字符串转换为抽象路径名来创建新的 File 实例 |
| File(String parent, String child) | 从父路径名字符串和子路径名字符串创建新的 File 实例 |
| File(File parent, String child) | 从父抽象路径名和子路径名字符串创建新的 File 实例 |
1.2 File 类创建功能
| 方法名 | 说明 |
|---|---|
| public boolean createNewFile() | 当具有该名称的文件不存在时,创建一个由该抽象路径名命名的新空文件 |
| public boolean mkdir() | 创建由此抽象路径名命名的目录 |
| public boolean mkdirs() | 创建由此抽象路径名命名的目录,包括任何必需但不存在的父目录 |
package PTA_training;
import java.io.File;
import java.io.IOException;//要抛出异常!!!public class TEST {public static void main(String[] args) throws IOException {File f1 = new File("G:\\javaCode\\java.txt");System.out.println(f1.createNewFile());/*File f2 = new File("G:\\javaCode","java.txt");File f3 = new File("G:\\javaCode");File f4 = new File(f3,"java.txt");System.out.println(f1);System.out.println(f2);System.out.println(f3);System.out.println(f4);下面的创建方法是类似的*/}
}
1.3 File 类判断和获取功能
| 方法名 | 说明 |
|---|---|
| public boolean isDirectory() | 测试此抽象路径名表示的 File 是否为目录 |
| public boolean isFile() | 测试此抽象路径名表示的 File 是否为文件 |
| public boolean exists() | 测试此抽象路径名表示的 File 是否存在 |
| public String getAbsolutePath() | 返回此抽象路径名的绝对路径名字符串 |
| public String getPath() | 将此抽象路径名转换为路径名字符串 |
| public String getName() | 返回由此抽象路径名表示的文件或目录的名称 |
| public String[] list() | 返回此抽象路径名表示的目录中的文件和目录的名称字符串数组 |
| public File[] listFiles() | 返回此抽象路径名表示的目录中的文件和目录的 File 对象数组 |
4 FileReader虽然是字符流,但它的read()方法返回的是int类型
在 Java 的 IO 流体系中,FileReader虽然是字符流,但它的read()方法返回的是 int类型,而非char或字符串。这是 Java IO 设计的一个重要特性,需要结合以下几点来理解:
1. read()方法的返回值设计
FileReader继承自Reader抽象类,而Reader的read()方法签名为:
public int read() throws IOException
- 返回值含义:返回的
int值代表字符的 Unicode 码点(范围:0~65535)。 - 特殊值:当读取到文件末尾时,返回
-1。
2. 为什么用int而不是char?
Java 使用int类型作为返回值的核心原因是!!!:
需要一个超出字符范围的值来表示文件结束。
char是无符号 16 位类型,范围是0~65535,无法表示 "文件结束" 的状态。int是 32 位类型,除了表示所有 Unicode 字符(0~65535)外,还能通过-1标识文件结束。
3. 字符编码与读取逻辑
虽然FileReader是字符流,但底层仍需通过字节流(如InputStreamReader)实现。当读取文件时:
- 字节到字符的转换:
FileReader自动将字节按照默认编码(如 UTF-8)转换为 Unicode 字符。 - 字符的 Unicode 码点:每个字符对应一个
int值(即 Unicode 码点)。例如:- 字符
'A'的 Unicode 码点是65(十六进制0x41)。 - 字符
'杭'的 Unicode 码点是26426(十六进制0x676D)。
- 字符
- 返回值处理:
read()方法直接返回这个int类型的码点。
4. 代码中的类型转换
java
int ch;
while ((ch = f.read()) != -1) {if ((char) ch == '杭') k++;
}
ch = f.read():将读取的 Unicode 码点(int)赋值给ch。(char) ch == '杭':将int类型的码点强制转换为char类型,再与字符'杭'(实际也是一个char类型的码点)比较。
5. 总结
FileReader的read()方法返回int,是为了区分字符数据和文件结束标记。int值代表字符的 Unicode 码点,通过强制类型转换可以转回char类型进行字符比较。- 这种设计保证了跨平台的字符处理能力,无论文件使用何种编码,
FileReader都会自动转换为 Unicode 字符。
补充:为什么不是字符串?
read()方法每次只读取一个字符,而非字符串。
如果需要读取一行文本,可以使用BufferedReader的readLine()方法,该方法返回String类型。
5 怎么理解Unicode码点?
Unicode 码点(Code Point)是理解字符编码的核心概念,它是字符在 Unicode 标准中的唯一数字标识。以下是对 Unicode 码点的详细解释:
1. 什么是 Unicode 码点?
- 定义:Unicode 是一个全球通用的字符编码标准,为世界上几乎所有的字符(包括字母、数字、符号、象形文字等)分配了一个唯一的数字编号,这个编号就是 码点。
- 表示方式:码点通常用
U+后跟十六进制数字表示。例如:- 字母
A的码点是U+0041(十进制为 65)。 - 汉字
杭的码点是U+676D(十进制为 26429)。 - 表情符号
😀的码点是U+1F600(十进制为 128512)。
- 字母
2. 码点与字符的关系
- 一对一映射:每个字符(或符号)在 Unicode 中都有唯一的码点,反之亦然。
- 跨平台一致性:无论在哪个操作系统、编程语言或设备上,字符
A的码点始终是U+0041,确保了全球范围内的统一表示。
3. 码点的范围
Unicode 目前定义了超过 143,000 个字符,码点范围从 U+0000 到 U+10FFFF,分为 17 个平面(Plane):
- 基本多文种平面(BMP):
U+0000到U+FFFF,包含常用字符(如 ASCII、中文、日文、韩文等)。 - 辅助平面:
U+10000到U+10FFFF,包含罕见字符、表情符号等。
4. 码点与编码格式的区别
- 码点:字符的逻辑编号(如
U+676D)。 - 编码格式:将码点转换为二进制存储的具体方式。常见的编码格式有:
- UTF-8:变长编码,用 1~4 个字节表示一个字符(如
杭的 UTF-8 编码为E6 9D AD,占 3 字节)。 - UTF-16:用 2 或 4 个字节表示一个字符(如
杭的 UTF-16 编码为67 6D,占 2 字节)。 - UTF-32:固定 4 字节表示一个字符(如
杭的 UTF-32 编码为00 00 67 6D)。
- UTF-8:变长编码,用 1~4 个字节表示一个字符(如
5. 在编程语言中的应用
- Java:
char类型存储 BMP 范围内的码点(2 字节,范围U+0000到U+FFFF)。- 超出 BMP 的字符(如表情符号)需要用两个
char(称为 代理对)表示。 int类型可以存储完整的 Unicode 码点(范围0到0x10FFFF)。
- Python:
str类型内部使用 Unicode 码点表示字符。- 可以用
ord()函数获取字符的码点,用chr()函数将码点转回字符。
示例:
python
# 获取字符的码点
print(ord('A')) # 输出: 65
print(ord('杭')) # 输出: 26429 (0x676D)
print(ord('😀')) # 输出: 128512 (0x1F600)# 将码点转回字符
print(chr(65)) # 输出: 'A'
print(chr(0x676D)) # 输出: '杭'
print(chr(128512)) # 输出: '😀'
6. 为什么需要理解码点?
- 处理多语言文本:确保程序能正确识别和处理不同语言的字符。
- 避免编码错误:理解码点与编码格式的差异,防止乱码问题(如 UTF-8 和 GBK 混用)。
- 处理特殊字符:如表情符号、数学符号等超出 ASCII 范围的字符。
总结
Unicode 码点是字符的数字身份证,是字符编码的基础。理解码点有助于正确处理文本数据,避免跨平台和跨语言的兼容性问题。在编程中,码点通常通过整数类型(如 Java 的 int、Python 的 ord() 结果)表示,而存储和传输时则需要选择合适的编码格式(如 UTF-8)。
6 File.separator是什么意思?
File file=new File("d:"+File.separator+"demo.txt");
File.separator 是 Java 中的一个系统属性,用于表示文件路径中的目录分隔符。它的作用是确保代码在不同操作系统上都能正确处理文件路径。
1. 为什么需要 File.separator?
不同操作系统使用不同的符号作为目录分隔符:
- Windows:使用反斜杠
\(例如C:\Users\file.txt)。 - Unix/Linux/macOS:使用正斜杠
/(例如/home/user/file.txt)。
直接在代码中硬编码分隔符(如 d:\demo.txt)会导致:
- Windows 代码在 Linux 上运行失败:Linux 不识别
\作为分隔符。 - Linux 代码在 Windows 上运行失败:Windows 不识别
/作为分隔符。
2. File.separator 的作用
- 自动适配系统:
File.separator会根据当前运行的操作系统自动返回对应的分隔符:- 在 Windows 上,
File.separator的值是\。 - 在 Linux/macOS 上,
File.separator的值是/。
- 在 Windows 上,
示例代码:
java
// 在 Windows 上,path 会变成 "d:\demo.txt"
// 在 Linux/macOS 上,path 会变成 "d:/demo.txt"
String path = "d:" + File.separator + "demo.txt";
File file = new File(path);
3. 等价写法:使用 File.separatorChar 或 /
File.separatorChar:返回char类型的分隔符(例如'\'或'/')。- 直接用
/:Java 的File类和Path类都支持用/作为分隔符,即使在 Windows 上也会自动转换为\。
示例:
java
// 方式1:使用 File.separator
String path1 = "d:" + File.separator + "demo.txt";// 方式2:使用 File.separatorChar
String path2 = "d:" + File.separatorChar + "demo.txt";// 方式3:直接用 /(跨平台兼容)
String path3 = "d:/demo.txt";// 三种方式在功能上完全等价
4. 更现代的替代方案:Path 类(Java 7+)
Java 7 引入的 java.nio.file.Path 类提供了更优雅的方式处理路径:
java
import java.nio.file.Path;
import java.nio.file.Paths;// 使用 Paths.get() 自动处理分隔符
Path path = Paths.get("d:", "demo.txt");
// 输出: Windows 上为 d:\demo.txt,Linux/macOS 上为 d:/demo.txt
System.out.println(path);
总结
File.separator 是 Java 提供的一个系统属性,用于动态获取当前操作系统的文件路径分隔符,避免硬编码导致的跨平台兼容性问题。在实际开发中,推荐使用 File.separator 或直接用 / 来编写跨平台的文件路径。
7 IOException
IOException 是 Java 中处理输入 / 输出(I/O)操作错误的检查型异常(Checked Exception)。它是所有 I/O 相关异常的基类,用于表示程序在读写文件、网络通信或其他 I/O 操作时可能遇到的错误。
1. IOException 的作用
- 异常分类:
IOException及其子类用于捕获和处理各种 I/O 错误,如文件不存在、网络连接中断、权限不足等。 - 强制处理:作为检查型异常,Java 编译器要求必须显式处理
IOException(通过try-catch或throws声明),否则代码无法编译。
2. 常见子类
IOException 有许多子类,用于表示更具体的错误类型:
FileNotFoundException:文件不存在或无法访问。EOFException:意外到达文件末尾(如读取空文件)。SocketException:网络套接字错误(如连接断开)。UnsupportedEncodingException:不支持的字符编码(如使用不存在的字符集)。InterruptedIOException:I/O 操作被中断。
3. 处理方式
Java 要求必须处理 IOException,有两种方式:
方式 1:使用 try-catch 捕获异常
java
try {FileReader fr = new FileReader("d:/demo.txt");// 执行 I/O 操作
} catch (IOException e) {// 处理异常e.printStackTrace();
}
方式 2:使用 throws 声明异常
java
public void readFile() throws IOException {FileReader fr = new FileReader("d:/demo.txt");// 执行 I/O 操作,不处理异常,将异常抛给调用者
}
4. 在代码中的应用
在您之前的代码中,main 方法声明了 throws IOException:
java
public static void main(String[] args) throws IOException {FileReader f = new FileReader("D:\\abc.txt");// ...
}
- 含义:该方法可能抛出
IOException或其子类(如FileNotFoundException),但不处理,而是将异常抛给 JVM。 - 缺点:调用者无法捕获并处理异常,程序可能直接崩溃。
5. 更安全的写法
推荐使用 try-catch 捕获异常,并使用 try-with-resources 自动关闭资源:
java
public static void main(String[] args) {try (FileReader f = new FileReader("D:\\abc.txt")) {int ch;int k = 0;while ((ch = f.read()) != -1) {if ((char) ch == '杭') k++;}System.out.println(k);} catch (FileNotFoundException e) {System.out.println("文件不存在:" + e.getMessage());} catch (IOException e) {System.out.println("读取文件失败:" + e.getMessage());}
}
- 优势:
- 自动关闭
FileReader(通过try-with-resources)。 - 分类处理不同类型的异常(如文件不存在和读取错误)。
- 提供友好的错误信息,避免程序崩溃。
- 自动关闭
6. 总结
IOException的本质:所有 I/O 错误的父类,用于强制程序处理可能的 I/O 异常。【在 Java 中捕获异常时,必须将子类异常(具体异常)放在前面,父类异常(通用异常)放在后面。这是因为异常处理遵循 从上到下匹配 的原则,如果父类异常在前,子类异常将永远不会被触发,导致编译错误。】- 为什么需要处理:I/O 操作依赖外部资源(如文件、网络),这些资源可能不可用或出现错误,必须通过异常机制通知程序。
- 最佳实践:优先使用
try-catch捕获异常,并通过try-with-resources确保资源释放。