消息的幂等性
幂等的定义:执行n次后最终的结果都一样

涉及两个问题,第一、为什么会多次执行
为什么他会可能有可能会接收到很多条一样的消息,是因为我们这种在比如最简单的例子,生产者他投递的时候他可能超时了,他一直重试,其实超时可能这个消息真是投递过来了对吧?这个消息队列就接收到了很多一样的消息,因为它有重试的机制对吧?可能下游消费者就可能消费到了很多一样的数据。
怎么解决?
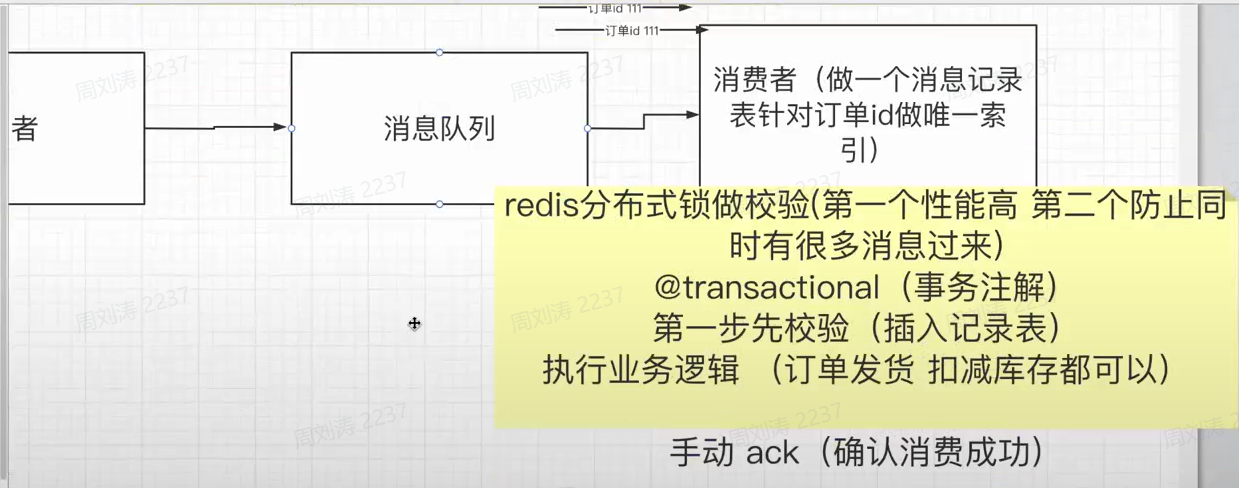
我其实就不用关心他怎么发送,看他怎么处理,一般来讲就是有一个。上游颁发。一个唯一的 ID 你,比如订单号。对吧,给这有可能我消息投递过来的时候,比如投了好几个消息,但是最重要他们的订单ID 可能都是 111 对吧。其实对消费者来说,怎么处理这种重复的消息对不对?好,我们一般怎么搞?其实也很简单,就是消费者一般来说是这么处理的。他拿到消息之后,他分三步,第1步执行业务逻辑,或者第1 步先校验。看你的执业务都无所谓。先校验。校验什么?是?我们在数据库针对 ID 建立一个唯一索引,它有一个记录表。做一个消息记录表,针对订单 ID 做唯一索引,这是消费者做的事。我们再说他怎么处理消息的逻辑。第一步拿到消息之后,订单 111 第一步先校验。怎么验?其实就直接插入记录表。如果他第一次进来,肯定就成功了,对吧?因为这里面没有数据对不对?再执行业务逻辑,可能他要去针对订单发货,什么东西都可以订单发货或者机减库存,我只是打个比方看公司的业务不一样。都可以业务处理完之后。诶,在 ACK 手动的 ACK什么意思?确认消费成功就这几步。这两步一般来讲,它是在一个本地事务里边。
如何有更好的策略
OK我们又讲。一般来说我可能为了假如你业务性能比较要求比较高,它会在前面先加个 Redis布式锁做校验是为啥?快一点,他可能就防止我同时有很多订单,假秒钟他同时来 100 个,不知道什么情况对吧?来了 100 个,可能每欠你都要去插入一下记录表,报个错,其实不太友好,性能也很差对不付?所以他在本地事务之前先价格 Redis 分布式锁防止什么?防止第一个性能高对吧?第二个防止同时有很多消息过来,但是具体什么情况下很多同时消息过来不可靠,因为上游它具体怎么样,它怎么生产的有可能它就是促进了对吧?我们一定要做好这种接口的防护,一个安全的降级的策略或者兜底的策略能理解。
redis如何做幂等?
setnx: set if not exist 如果不存在就赋值
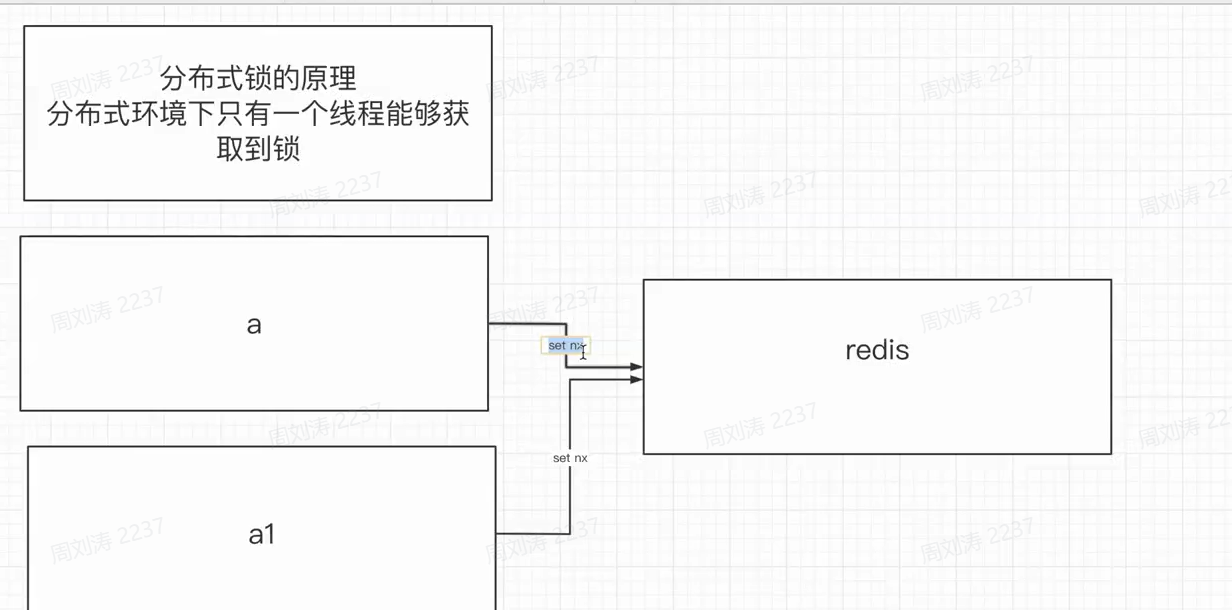
redis是单线程的
分布式锁的原理分布式环境下只有一个线程能够获取到锁
mysql其实也可以实现分布式锁,唯一索引,最后只有一个人能成功