YOLOv8 × VisDrone 全流程实战:训练你的无人机识别模型 AI(第一部分:数据集准备)

目录
数据集处理和准备
第一步:安装YOLOv8 Ultralytics 库
第二步:挂载你的Google Drive
第三步:解压你上传到 Google Drive 的 VisDrone 数据集
第四步:上传转换脚本和配置文件
dataset.yaml
第五步:创建 YOLO 格式所需目录结构
第六步:将解压后的图像放入YOLO工作目录
第七步:将原始数据集的标注转换为YOLO的格式
训练集
验证集
第八步:试看其中一张观察是否有标注的数据
训练集查看
编辑
验证集查看
编辑
可选最后一步:标签验证
想打造属于自己的无人机目标识别AI?这篇手把手教程带你从零开始上手实战!
在本篇文章中,我们将带你完整走完 YOLOv8 与 VisDrone 数据集的整合流程,涵盖从数据获取到预处理的每一个关键步骤。无论你是初学者还是有一定基础的开发者,都能轻松跟随操作,完成无人机图像数据的标准化转换。
🔧 你将学到:
- 如何从 GitHub 下载 VisDrone 数据集并高效管理至 Google Drive
- 在 Google Colab 中快速部署 YOLOv8 环境并挂载云端存储
- 解压数据并构建符合 YOLO 格式的标准目录结构
- 将原始标注文件一键转换为 YOLO 可训练格式
- 编写可视化函数,直观检查标注质量
- 使用标签验证脚本确保数据完整性,避免训练翻车
✨ 完成本文操作后,你的数据将完全准备好,随时进入模型训练阶段!下一篇文章我们将正式开始 YOLOv8 的训练之旅,记得关注更新!
📌 一站式全流程教学,专为想要掌握无人机视觉识别技术的你而准备!
数据集处理和准备
首先在这里下载好对应的数据集,分别是下载这两个。
GitHub - VisDrone/VisDrone-Dataset: The dataset for drone based detection and tracking is released, including both image/video, and annotations.
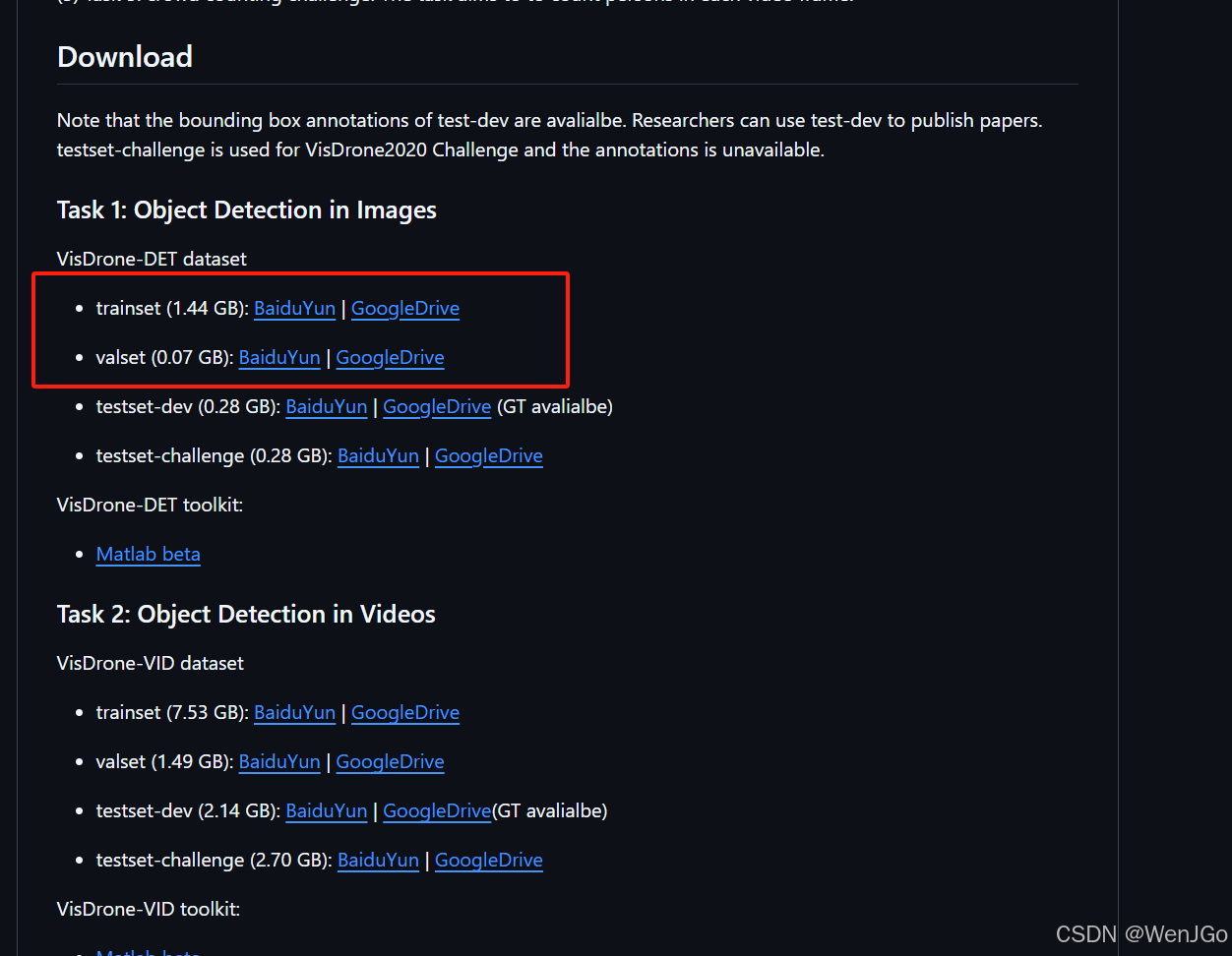
这里我们采用保存到GoogleDrive的方法,这样的话配合GoogleColab都在云端网速不是一般的快。
然后我们进入colab
第一步:安装YOLOv8 Ultralytics 库
# ✅ 安装 YOLOv8 Ultralytics 库
!pip install ultralytics
第二步:挂载你的Google Drive
# ✅ 挂载你的 Google Drive
from google.colab import drive
drive.mount('/content/drive')
第三步:解压你上传到 Google Drive 的 VisDrone 数据集
这里是怎么放到Drive中的呢,我给的GitHub中有放入Google Drive中的链接,点击就完事了。
# ✅ 解压你上传到 Google Drive 的 VisDrone 数据集
# 替换成你自己的路径,比如你放在 "MyDrive/datasets" 里
!unzip -q "/content/drive/MyDrive/VisDrone2019-DET-train.zip" -d ./data/
!unzip -q "/content/drive/MyDrive/VisDrone2019-DET-val.zip" -d ./data/第四步:上传转换脚本和配置文件
# ✅ 上传转换脚本和配置文件(你也可以从本地上传)
from google.colab import filesuploaded = files.upload()
dataset.yaml
path: /content/data/VisDrone-YOLO
train: images/train
val: images/valnames:0: pedestrian1: people2: bicycle3: car4: van5: truck6: tricycle7: awning-tricycle8: bus9: motor
第五步:创建 YOLO 格式所需目录结构
# ✅ 创建 YOLO 格式所需目录结构
import osbase_path = '/content/data/VisDrone-YOLO'os.makedirs(f'{base_path}/images/train', exist_ok=True)
os.makedirs(f'{base_path}/images/val', exist_ok=True)
os.makedirs(f'{base_path}/labels/train', exist_ok=True)
os.makedirs(f'{base_path}/labels/val', exist_ok=True)第六步:将解压后的图像放入YOLO工作目录
# 复制训练集图像
!mkdir -p /content/data/VisDrone-YOLO/images/train
!cp /content/data/VisDrone2019-DET-train/images/* /content/data/VisDrone-YOLO/images/train/# 复制验证集图像
!mkdir -p /content/data/VisDrone-YOLO/images/val
!cp /content/data/VisDrone2019-DET-val/images/* /content/data/VisDrone-YOLO/images/val/
第七步:将原始数据集的标注转换为YOLO的格式
训练集
# 转换数据标注标签import os
import cv2train_image_dir = "/content/data/VisDrone-YOLO/images/train"
train_label_dir = "/content/data/VisDrone-YOLO/labels/train"
annotation_dir = "/content/data/VisDrone2019-DET-train/annotations"os.makedirs(train_label_dir, exist_ok=True)image_names = os.listdir(train_image_dir)
print(f"共{len(image_names)}张训练图片")for img_name in image_names:base_name = os.path.splitext(img_name)[0]ann_path = os.path.join(annotation_dir, base_name + ".txt")img_path = os.path.join(train_image_dir, img_name)if not os.path.exists(ann_path):print(f"警告:没有找到标注文件:{ann_path}")continueimg = cv2.imread(img_path)if img is None:print(f"错误:无法读取图片 {img_path}")continueh, w, _ = img.shapewith open(ann_path, "r") as f:lines = f.readlines()if len(lines) == 0:print(f"标注文件为空:{ann_path}")continueyolo_lines = []for line in lines:parts = line.strip().split(",")if len(parts) < 6:print(f"异常标注行(字段数小于6):{line.strip()}")continue# VisDrone标注格式:x,y,w,h,score,class,idx, y_, bw, bh, score, cls = parts[:6]x, y_, bw, bh = map(float, (x, y_, bw, bh))cls = int(cls)# 跳过部分类别?视需求而定# 归一化坐标cx = (x + bw/2) / wcy = (y_ + bh/2) / hnw = bw / wnh = bh / h# YOLO类别映射,可根据需求调整# 假设VisDrone原始类别就是0起始的yolo_lines.append(f"{cls} {cx} {cy} {nw} {nh}")if len(yolo_lines) == 0:print(f"没有有效标注转换:{ann_path}")continuesave_path = os.path.join(train_label_dir, base_name + ".txt")with open(save_path, "w") as f:f.write("\n".join(yolo_lines))# print(f"成功转换:{save_path}")
验证集
#验证集
val_image_dir = "/content/data/VisDrone-YOLO/images/val"
val_label_dir = "/content/data/VisDrone-YOLO/labels/val"
val_annotation_dir = "/content/data/VisDrone2019-DET-val/annotations"os.makedirs(val_label_dir, exist_ok=True)val_image_names = os.listdir(val_image_dir)
print(f"共{len(val_image_names)}张验证图片")for img_name in val_image_names:base_name = os.path.splitext(img_name)[0]ann_path = os.path.join(val_annotation_dir, base_name + ".txt")img_path = os.path.join(val_image_dir, img_name)if not os.path.exists(ann_path):print(f"警告:没有找到标注文件:{ann_path}")continueimg = cv2.imread(img_path)if img is None:print(f"错误:无法读取图片 {img_path}")continueh, w, _ = img.shapewith open(ann_path, "r") as f:lines = f.readlines()if len(lines) == 0:print(f"标注文件为空:{ann_path}")continueyolo_lines = []for line in lines:parts = line.strip().split(",")if len(parts) < 6:print(f"异常标注行(字段数小于6):{line.strip()}")continuex, y_, bw, bh, score, cls = parts[:6]x, y_, bw, bh = map(float, (x, y_, bw, bh))cls = int(cls)cx = (x + bw/2) / wcy = (y_ + bh/2) / hnw = bw / wnh = bh / hyolo_lines.append(f"{cls} {cx} {cy} {nw} {nh}")if len(yolo_lines) == 0:print(f"没有有效标注转换:{ann_path}")continuesave_path = os.path.join(val_label_dir, base_name + ".txt")with open(save_path, "w") as f:f.write("\n".join(yolo_lines))# print(f"成功转换:{save_path}")
第八步:试看其中一张观察是否有标注的数据
训练集查看
import matplotlib.pyplot as plt
import cv2
import osdef plot_image_with_bbox(image_path, label_path):img = cv2.imread(image_path)img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)h, w, _ = img.shapewith open(label_path, 'r') as f:for line in f.readlines():cls, cx, cy, bw, bh = line.strip().split()cls, cx, cy, bw, bh = int(cls), float(cx), float(cy), float(bw), float(bh)x1 = int((cx - bw/2)*w)y1 = int((cy - bh/2)*h)x2 = int((cx + bw/2)*w)y2 = int((cy + bh/2)*h)cv2.rectangle(img, (x1,y1), (x2,y2), (255,0,0), 2)cv2.putText(img, str(cls), (x1, y1-10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (255,0,0), 2)plt.imshow(img)plt.axis('off')plt.show()# 试试看其中一张
img_fp = '/content/data/VisDrone-YOLO/images/train/0000002_00005_d_0000014.jpg' # 改成你有的图片文件名
label_fp = '/content/data/VisDrone-YOLO/labels/train/0000002_00005_d_0000014.txt' # 同名txt
plot_image_with_bbox(img_fp, label_fp)

验证集查看
import matplotlib.pyplot as plt
import cv2
import osdef plot_image_with_bbox(image_path, label_path):img = cv2.imread(image_path)img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)h, w, _ = img.shapewith open(label_path, 'r') as f:for line in f.readlines():cls, cx, cy, bw, bh = line.strip().split()cls, cx, cy, bw, bh = int(cls), float(cx), float(cy), float(bw), float(bh)x1 = int((cx - bw/2)*w)y1 = int((cy - bh/2)*h)x2 = int((cx + bw/2)*w)y2 = int((cy + bh/2)*h)cv2.rectangle(img, (x1,y1), (x2,y2), (255,0,0), 2)cv2.putText(img, str(cls), (x1, y1-10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (255,0,0), 2)plt.imshow(img)plt.axis('off')plt.show()# 试试看其中一张
#img_fp = '/content/data/VisDrone-YOLO/images/train/0000002_00005_d_0000014.jpg' # 改成你有的图片文件名
#label_fp = '/content/data/VisDrone-YOLO/labels/train/0000002_00005_d_0000014.txt' # 同名txtimg_fp = '/content/data/VisDrone-YOLO/images/val/0000001_02999_d_0000005.jpg' # 改成你有的图片文件名
label_fp = '/content/data/VisDrone-YOLO/labels/val/0000001_02999_d_0000005.txt' # 同名txt
plot_image_with_bbox(img_fp, label_fp)

可选最后一步:标签验证
import osdef check_labels(label_dir, image_dir, num_classes=12):label_files = [f for f in os.listdir(label_dir) if f.endswith('.txt')]image_files = set(os.listdir(image_dir))class_counts = [0] * num_classeserrors = []empty_files = []missing_images = []missing_labels = []for label_file in label_files:label_path = os.path.join(label_dir, label_file)base_name = os.path.splitext(label_file)[0]image_name_jpg = base_name + ".jpg"image_name_png = base_name + ".png"# 判断图片是否存在(支持jpg或png)if image_name_jpg not in image_files and image_name_png not in image_files:missing_images.append(base_name)with open(label_path, 'r') as f:lines = f.readlines()if len(lines) == 0:empty_files.append(label_file)continuefor i, line in enumerate(lines):parts = line.strip().split()if len(parts) < 5:errors.append(f"{label_file} line {i+1}: 字段数不足")continuetry:cls_id = int(parts[0])if cls_id < 0 or cls_id >= num_classes:errors.append(f"{label_file} line {i+1}: 类别ID {cls_id} 越界")else:class_counts[cls_id] += 1except ValueError:errors.append(f"{label_file} line {i+1}: 类别ID非整数")# 检查图片目录是否有未对应标签文件label_basenames = set(os.path.splitext(f)[0] for f in label_files)for img_file in image_files:base_name = os.path.splitext(img_file)[0]if base_name not in label_basenames:missing_labels.append(img_file)# 输出统计结果print("== 类别统计 ==")for i, count in enumerate(class_counts):print(f"类别 {i}: {count} 个标签")print(f"\n== 错误统计 ==")print(f"标签文件为空: {len(empty_files)} 个")print(f"标签格式错误或类别越界: {len(errors)} 条")print(f"缺少对应图片的标签文件数: {len(missing_images)}")print(f"缺少对应标签文件的图片数: {len(missing_labels)}")if errors:print("\n具体错误示例(最多5条):")for e in errors[:5]:print(" ", e)if empty_files:print("\n空标签文件示例(最多5个):")for f in empty_files[:5]:print(" ", f)if missing_images:print("\n缺少图片示例(最多5个):")for f in missing_images[:5]:print(" ", f)if missing_labels:print("\n缺少标签示例(最多5个):")for f in missing_labels[:5]:print(" ", f)if __name__ == "__main__":train_label_dir = "/content/data/VisDrone-YOLO/labels/train"train_image_dir = "/content/data/VisDrone-YOLO/images/train"val_label_dir = "/content/data/VisDrone-YOLO/labels/val"val_image_dir = "/content/data/VisDrone-YOLO/images/val"print("=== 检查训练集 ===")check_labels(train_label_dir, train_image_dir)print("\n=== 检查验证集 ===")check_labels(val_label_dir, val_image_dir)这段代码最后会输出标签是否对应好了,如果对应好了,就可以进入下一篇,模型训练了。
如果您觉得这篇文章对您有所帮助
欢迎点赞、转发、收藏,这将对我有非常大的帮助
感谢您的阅读,我们下篇文章再见~ 👋