spring-ai入门
spring-ai入门
1、前语
hi,我是阿昌,今天记录针对目前当下ai火热的背景下,ai的主流使用语言为python,但市面上很大部分的项目是java开发的的背景下,那java就不能涉及ai领域的开发了嘛?有句调侃的话说的好,所有Java服务端开发工程师的春天都是Spring给的,这次他这次针对这场景下,他又来了,SpringAI。
Spring-AI,当时理解的比较肤浅以为这个东西就是简化下对接大模型的复杂度,制定统一的接入规范,但是没想到过几个月一看,目前的SpringAI 已经有了完全对标LangChain的能力,下面先看官方文档的几张关键图示。
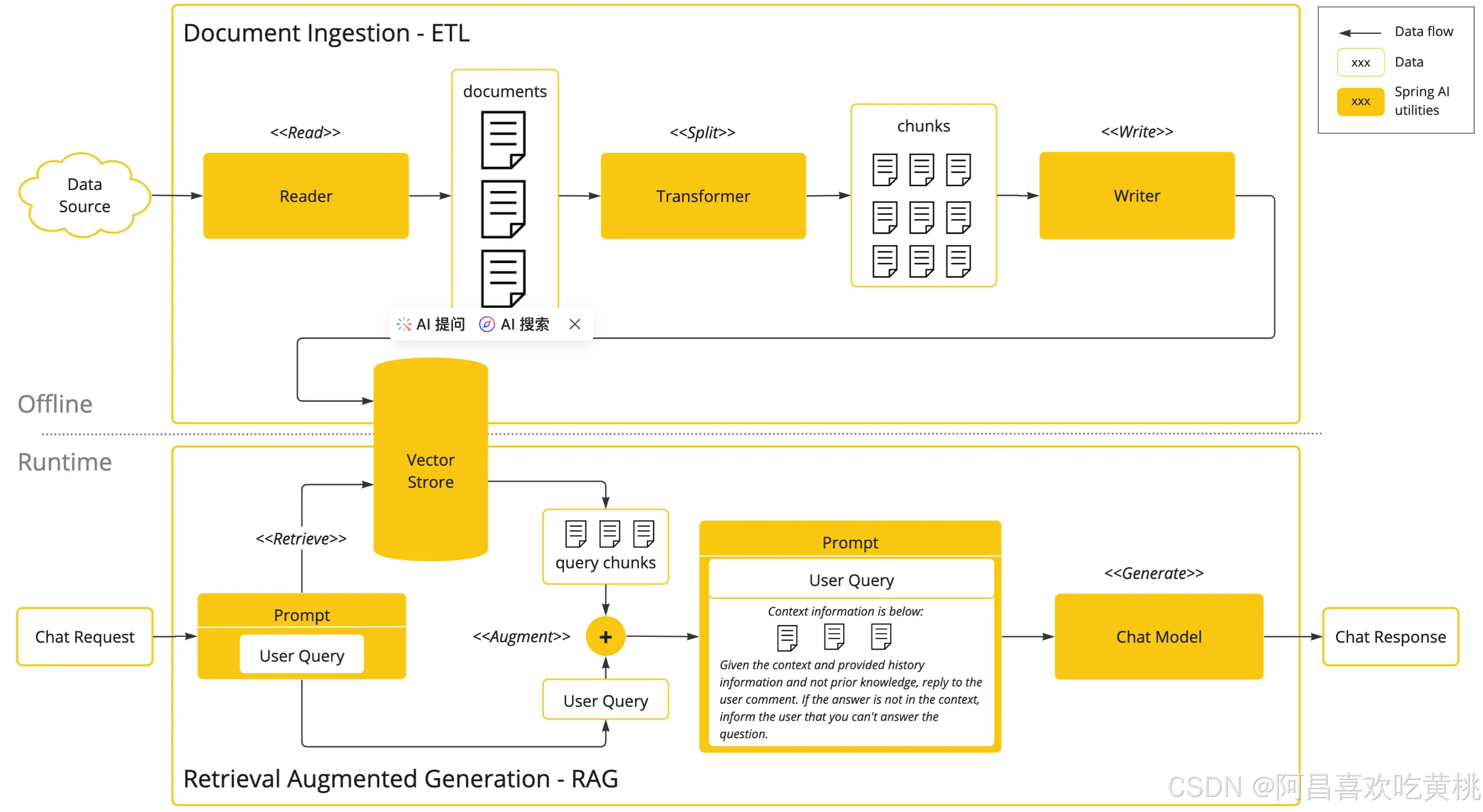
从上面这张图可以看出目前SpringAI已经有了成熟的ETL技术实现,也就是说springAI有专业的套件可以实现将原始的文档经过读取、转换(数据结构化、清理数据、数据分块)、后写入向量数据库。
正是由于有这一点支持所以SpringAI也就自然而然的支持RAG技术实现,可以支持让大模型基于已有的知识库回答问题。
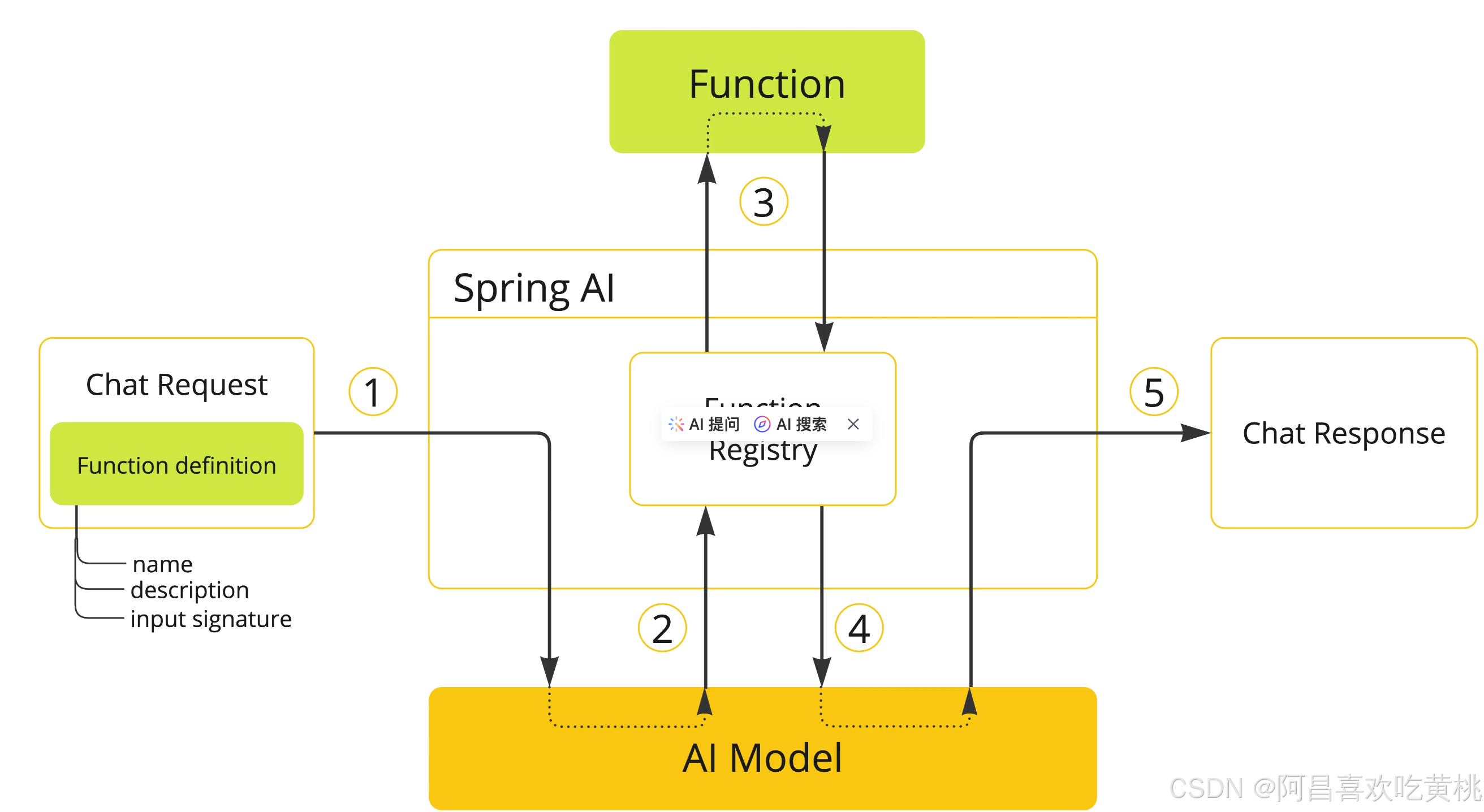
那下面这张图,表明SpringAI支持了函数调用能力,也就是说借助SpringAI支持绑定一些函数,在调用大模型之前去调用函数。
这个有什么用呢,比如注册了一个本地文件内容读取函数,可以直接发送这样的问题
C:\学习资料,这文件目录下面有多少个压缩文件?doc和ppt文件各自有多少个?
这种问题直接使用大模型是无法解决的,但是因为有了函数注册,让这一切都成为可能。
2、前置准备
按照本文提供的案例进行代码实现之前,你需要确保以下开发环境是满足的
JDK17及以上版本,因为SpringAI只能在SpringBoot3.x以上版本使用,JDK8 只能含泪说再见了docker运行环境,需要使用Docker安装RedisStack和Neo4J(建立知识图谱使用)通义千问的APIKEY
3、SpringAI使用
下面首先需要创建一个标准的SpringBoot项目并在项目的Pom文件中引入下述关键依赖:
<dependencyManagement><dependencies><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-bom</artifactId><version>${spring-ai.version}</version><type>pom</type><scope>import</scope></dependency></dependencies>
</dependencyManagement>
<dependencies><dependency><groupId>com.alibaba.cloud.ai</groupId><artifactId>spring-ai-alibaba-starter</artifactId><version>${spring-ai-alibaba.version}</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency>
</dependencies>
针对引用的版本,具体的也可以去地址去查询具体的版本,
这里SpringAI的版本和SpringAIAlibaba的版本要匹配,这里使用的版本为:
<properties><spring-ai.version>1.0.0-M5</spring-ai.version><spring-ai-alibaba.version>1.0.0-M5.1</spring-ai-alibaba.version>
</properties>
3.1模型接入
先需要在application.yaml文件中添加下述内容
spring:application:name: springboot-rocket-ai-demoai:# 阿里通义千问dash-scope:api-key: 写上你自己的ApiKeychat:options:model: qwen-maxembedding:options:model: text-embedding-v2
然后编写一个Controller开始最基础的模型对接。
@RequestMapping("/qwen")
@RestController
@AllArgsConstructor
public class QwenChatController {private final ChatModel chatModel;/*** 同步问答,直接输出结果** @param prompt 用户提问*/ @GetMapping("chat")public String chat(@RequestParam String prompt) {ChatClient chatClient = ChatClient.create(chatModel);return chatClient.prompt().user(prompt).call().content();}/*** 流式问答 (搭配前端可以实现打字机输出效果)** @param prompt 用户提问* @return 流式响应*/@GetMapping(value = "chat/stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)public Flux<ServerSentEvent<String>> chatStream(@RequestParam String prompt) {return ChatClient.create(chatModel).prompt()// 输入多条消息,消息可以分角色.messages(new SystemMessage("你是一个Spring专家帮助用户回答JavaSpring框架方面的问题"),new UserMessage(prompt))// 流式返回.stream()// 构造SSE(ServerSendEvent)格式返回结果.chatResponse().map(chatResponse -> {return ServerSentEvent.builder(JSON.toJSONString(chatResponse)).event("message").build();});}
}
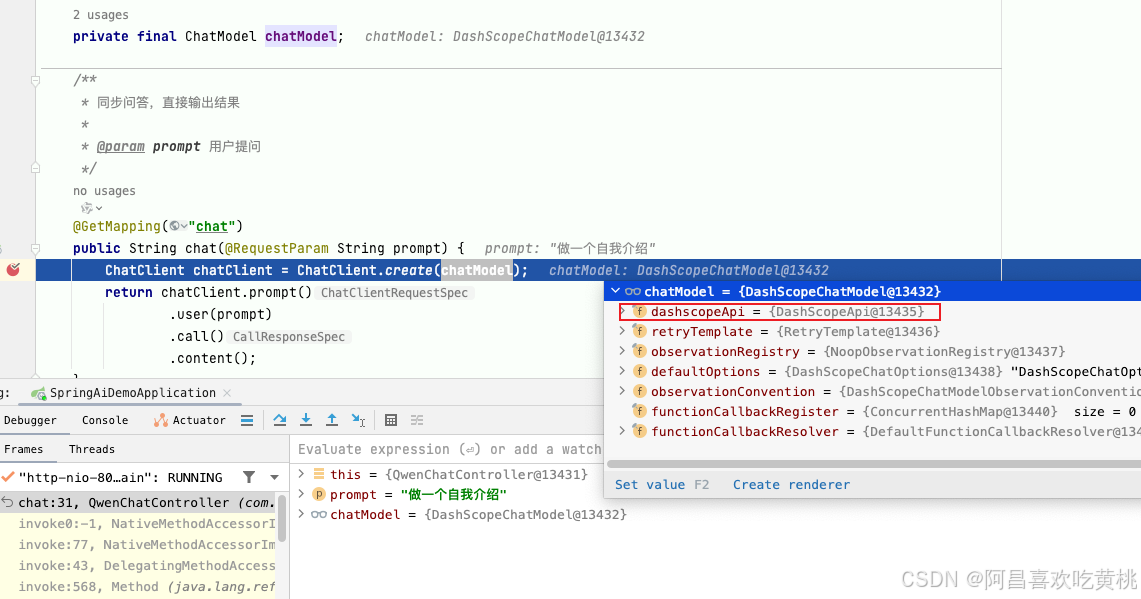
调用结果:
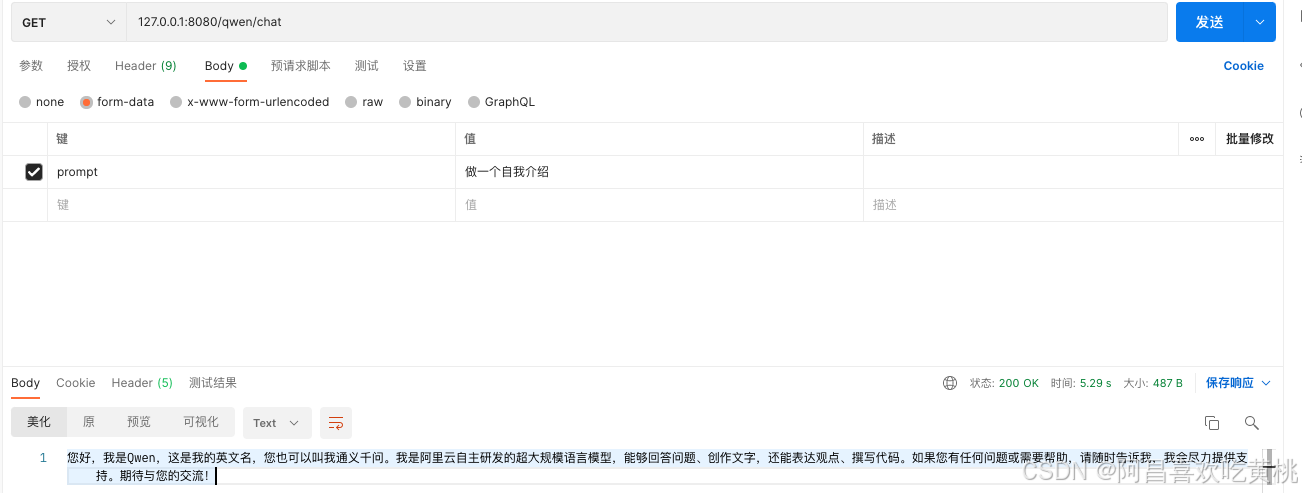
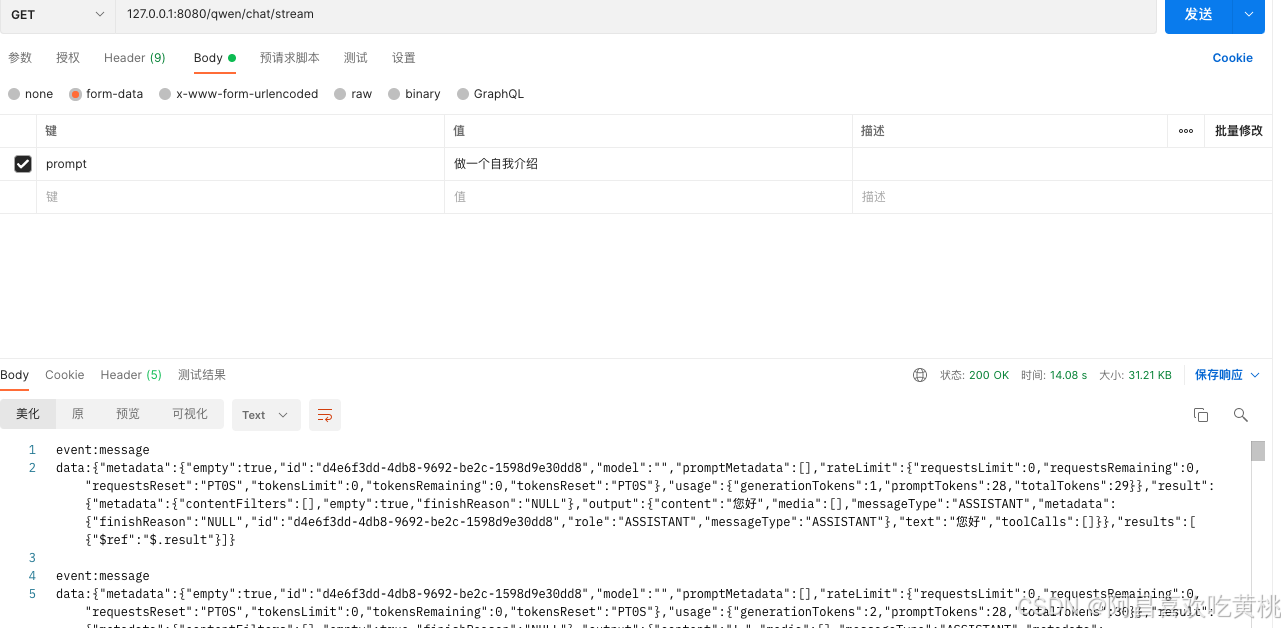
这里的ChatModel 会使用SpringBoot自动装配,打断点就可以得知为通义千问的实现,同样的如果在路径和依赖里面注入诸如“千帆”“豆包”的maven依赖并进行正确的配置,则也能转为对应大模型的实现,所以SpringAI实际上也提供了一种接入规范,不然每家大模型都搞一个接入规则,对接多个大模型的复杂度就会成倍上升。
3.2对话记忆
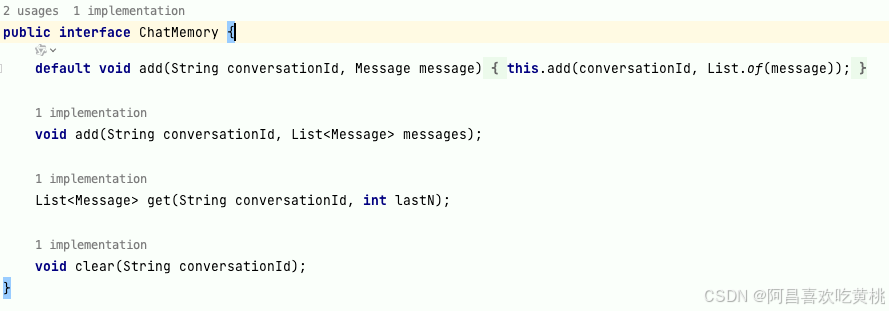
上面会发现与ai对话是没有进行记忆的,也就是说大模型记不得上次问了些什么问题,实现对话记忆的关键类就是ChatMemory接口,这个接口有个最简单的内置实现InMemoryChatMemory。
下面继续改造代码与大模型的对话增加记忆能力
private final ChatModel chatModel;// 内存记忆 这种方式是不适合分布式环境的
private final ChatMemory chatMemory = new InMemoryChatMemory();// .......@GetMapping(value = "chat/stream/memory", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<ServerSentEvent<String>> chatStreamWithMemory(@RequestParam String prompt,@RequestParam String sessionId) {var messageChatMemoryAdvisor = new MessageChatMemoryAdvisor(chatMemory, sessionId, 10);return ChatClient.create(chatModel).prompt().user(prompt).advisors(messageChatMemoryAdvisor).stream().content().map(chatResponse -> ServerSentEvent.builder(chatResponse).event("message").build());
}
MessageChatMemoryAdvisor这个熟悉SpringBoot的都应该感到比较熟悉,实际上就是一种拦截请求,会在正式发起大模型请求时进行拦截,追加会话id对应的历史会话消息。
这个构造方法接收三个参数分别是chatMemory 、会话id、以及需要从会话记忆中发送几条历史消息给大模型。

对于内存记忆,在分布式的场景下就会失效,所以正常情况下应该是自己去实现ChatMemory,把数据存储到数据库里面,根据会话id来读取历史会话内容。如下需要针对crud的方法进行db实现即可;
需要注意是大模型都有上下文限制,如果携带过多的上下文信息其实反而会影响大模型最终的回答效果,在实际开发中可以只提取3-5条上下文,这样既能节省token从而节省金额,还能保证大模型的回答效果。
3.3RAG入门
那如下的前提是,需要安装redisStack作为向量数据库,可以参考官方文档,进行安装
为什么要用向量数据库呢?因为要想让大模型回答基于提供的材料的响应结果,需要告诉大模型背景,大模型在回答你的问题的时候它需要评估材料和问答的关联性,评估关联性,实际上就是计算两个向量的夹角,所以使用的是向量数据库来存储。
redisStack实际上是redis的一种增强版,也包含了redis的全部功能。
首先需要把需要上传的资料转到向量数据库中,使用的是Spring的ETL套件,如下图所示:

核心代码如下:可以发现这里的代码步骤基本和上图是一一对应的;
引入Spring AI提供的一个文档读取器
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-tika-document-reader</artifactId><version>1.0.0-M5</version>
</dependency>
@PostMapping("embedding")
public String embedding(@RequestParam MultipartFile file) throws IOException {// 从IO流中读取文件TikaDocumentReader tikaDocumentReader = new TikaDocumentReader(new InputStreamResource(file.getInputStream()));List<Document> documentList = tikaDocumentReader.read();// 将文本内容划分成更小的块List<Document> splitDocuments = new TokenTextSplitter().apply(documentList);// 存入向量数据库,这个过程会自动调用embeddingModel,将文本变成向量再存入。redisVectorStore.add(splitDocuments);return "success";
}urn "success";
}
启动之后RedisStack会有一个管理地址(默认端口号8001),可以通过管理地址查看文档有没有正确的存储到向量数据库中。
这里实际上传了一份文档;
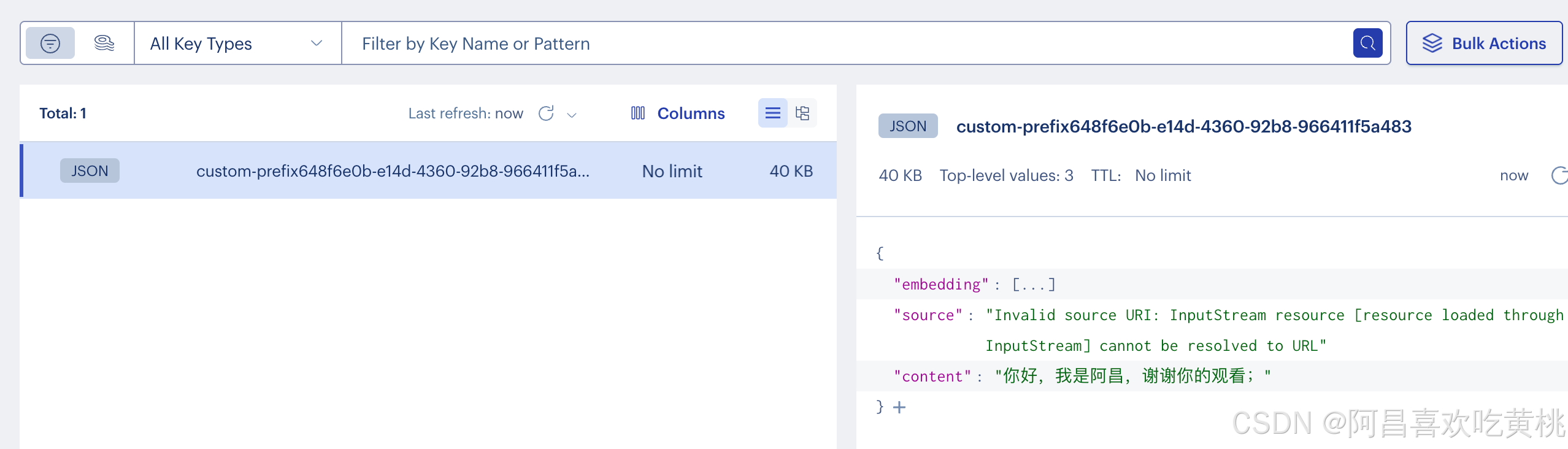
可以发现文档被存储到了向量数据库中;
存储到了向量数据库之后,需要让大模型基于向量数据库里面的内容进行问题回答,怎么实现呢?
@GetMapping(value = "chat/stream/vector", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<ServerSentEvent<String>> chatStreamWithVector(@RequestParam String prompt) {// 1. 定义提示词模板,question_answer_context会被替换成向量数据库中查询到的文档。String promptWithContext = """以下是用户提问的上下文信息---------------------{question_answer_context}---------------------给定的上下文和提供的历史信息,而不是事先的知识,回复用户的意见。如果答案不在上下文中,告诉用户你不能回答这个问题。""";return ChatClient.create(chatModel).prompt().user(prompt)// 2. QuestionAnswerAdvisor会在运行时替换模板中的占位符`question_answer_context`,替换成向量数据库中查询到的文档。此时的query=用户的提问+替换完的提示词模板;.advisors(new QuestionAnswerAdvisor(redisVectorStore, SearchRequest.defaults(), promptWithContext)).stream()// 3. query发送给大模型得到答案.content().map(chatResponse -> ServerSentEvent.builder(chatResponse).event("message").build());
}
这里发现和上面解决对话记忆一样也是有一个Advisor来解决这个问题,这个QuestionAnswerAdvisor构造方法定义如下:

这里的question_answer_context占位符有点疑问,可能会问换成其他的占位符可不可以,事实上是不可以的,简单的看下QuestionAnswerAdvisor的实现即可发现在源码org.springframework.ai.chat.client.advisor.QuestionAnswerAdvisor#before位置处,代码写死的占位符的名称。
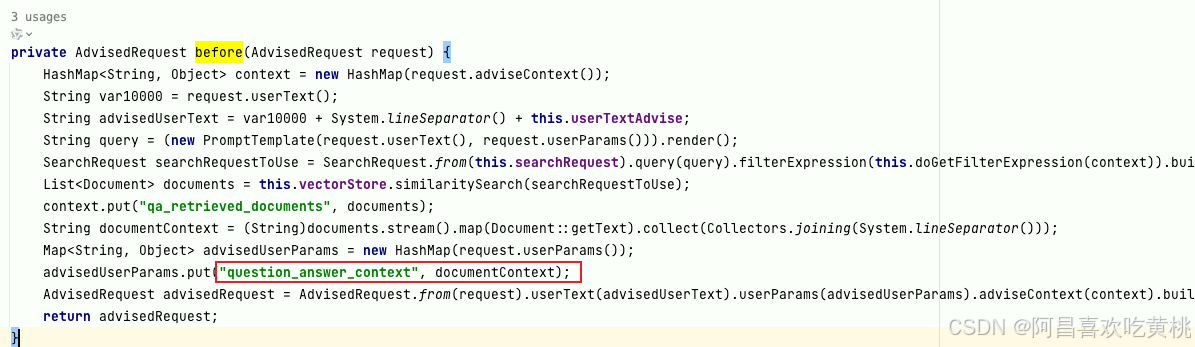
3.4函数调用
考虑一种场景我需要让大模型,读取本地目录的一个文件,然后基于这个文件回答问题,显然大模型不具备读取本地文件的能力,除了上面说的把文档通过ETL技术放到向量数据库的方式以外有没有其他办法解决这个问题呢?
实际方案是有的使用的也就是SpringAI的FunctionCall
@Description("文档解析函数")
@Component
@Slf4j
public class DocumentContentAnalyzerFunction implements Function<DocumentContentAnalyzerFunction.Request,DocumentContentAnalyzerFunction.Response> {@JsonInclude(JsonInclude.Include.NON_NULL)@JsonClassDescription("文件解析函数请求")public static class Request {@JsonProperty(required = true, value = "path")@JsonPropertyDescription(value = "需要解析的文档路径")String path;}@JsonClassDescription("根据指定路径读取出来的文件内容")public record Response(String result) {}@SneakyThrows@Overridepublic Response apply(Request request) {// ai解析用户的提问得到path参数,使用tika读取本地文件获取内容。把读取到的内容再返回给ai作为上下文去回答用户的问题。TikaDocumentReader tikaDocumentReader = new TikaDocumentReader(new FileSystemResource(request.path));return new Response(tikaDocumentReader.read().get(0).getContent());}
}
可以发现这里加了很多的注解,加这些注解的内容就是为了提供一种信息告诉大模型,如何调用,什么时候调用。
在SpringAI alibaba中也定义了很多函数实现,例如这里的天气服务函数。
可以供参考定义函数之后只需要在代码中写上函数在Spring容器中的Bean名称即可
@GetMapping(value = "chat/function")
public String chatStreamWithFunction(@RequestParam String prompt) {return ChatClient.create(chatModel).prompt().functions("documentContentAnalyzerFunction").user(prompt).call().content();
}
可以看下具体的调用效果
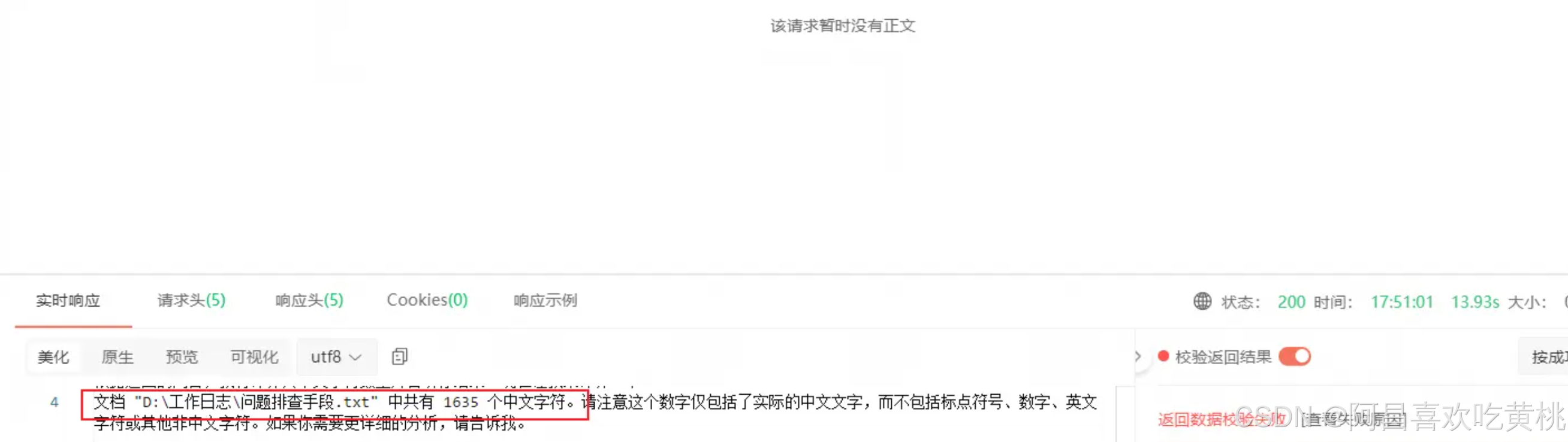
发现大模型准确回答了我本地一个文档的字符总数,这实际上是调用我们的函数来实现文档内容读取的